Soft Token Alignment for Cross-Lingual Reasoning
Pith reviewed 2026-06-26 05:41 UTC · model grok-4.3
The pith
Aligning soft-token representations across languages during fine-tuning improves multilingual reasoning accuracy by up to 17.7 points.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
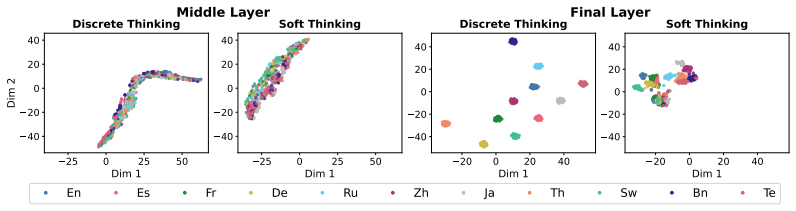
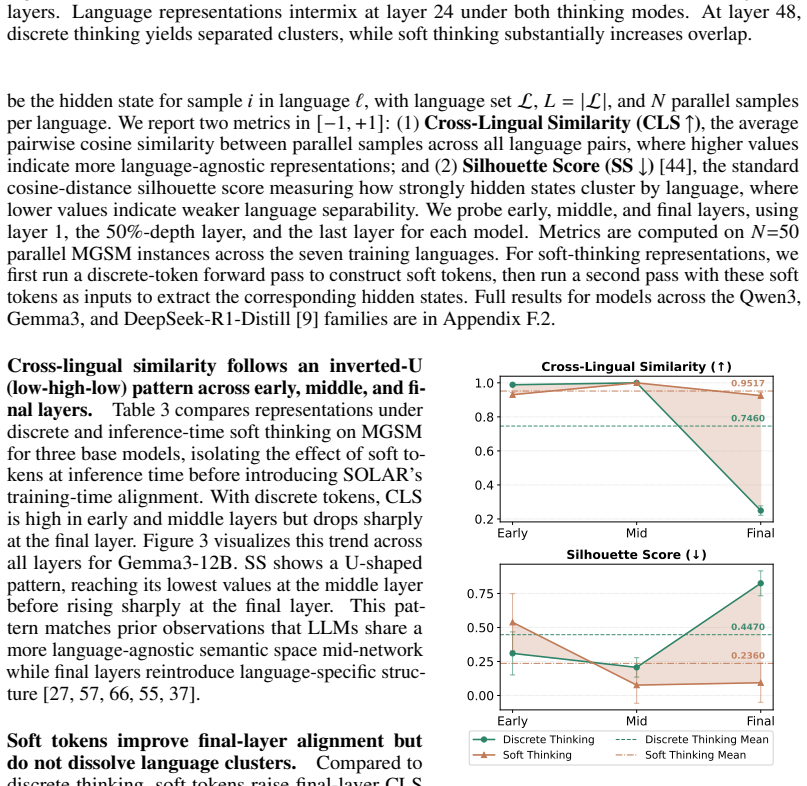
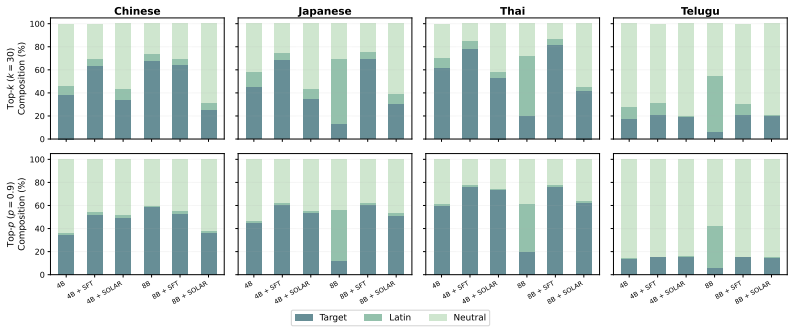
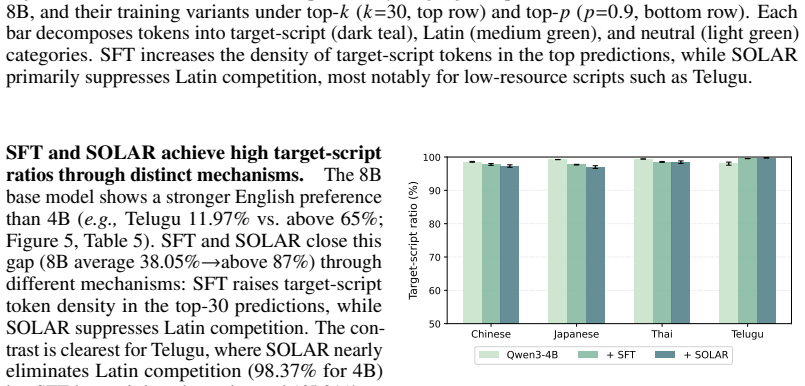
SOLAR aligns each non-English soft-token summary to its English counterpart in the shared embedding space as an auxiliary loss during supervised fine-tuning. Soft tokens are probability-weighted mixtures over the vocabulary embeddings. This produces continuous representations that aggregate information from semantically related tokens across languages. The alignment strengthens final-layer cross-lingual similarity, substantially reduces language-cluster separability, and yields accuracy gains of up to +17.7 points over the base model and +3.8 over standard supervised fine-tuning across four multilingual reasoning benchmarks, with the largest improvements on low-resource languages.
What carries the argument
Soft-token alignment, in which probability-weighted mixtures over vocabulary embeddings from non-English inputs are pulled toward their English counterparts in embedding space during fine-tuning.
If this is right
- Reasoning accuracy improves most for low-resource languages where discrete token divergences are most severe.
- Final-layer representations exhibit higher cross-lingual similarity after alignment.
- Language-specific clusters become less separable in the embedding space.
- Multilingual reasoning paths remain more consistent because generation is guided by continuous rather than discrete language-specific signals.
Where Pith is reading between the lines
- The same alignment signal could be tested on generation tasks outside reasoning, such as translation or summarization, to check whether it generalizes beyond the reported benchmarks.
- If the method mainly works by encouraging English-like patterns, it might underperform when the pivot language itself has limited data.
- Combining soft-token alignment with existing discrete-token objectives could be tested to measure additive versus redundant effects on consistency.
Load-bearing premise
Aligning soft-token summaries to English counterparts in embedding space preserves shared semantic structure rather than simply encouraging the model to copy English lexical patterns or surface statistics.
What would settle it
A controlled experiment in which models fine-tuned with the soft-token alignment objective show no accuracy gains on low-resource language reasoning tasks or retain the same degree of language-cluster separability in final-layer representations as standard fine-tuning.
Figures



read the original abstract
Multilingual large language models often produce inconsistent reasoning and answers for semantically equivalent prompts in different languages. Prior work suggests that intermediate representations can be relatively language-agnostic, but generation becomes increasingly language-specific as models commit to discrete output tokens. This is problematic because language-specific lexical choices can cause semantically equivalent reasoning paths to diverge across languages. These divergences motivate searching for a cross-lingual alignment signal that is less tied to any single vocabulary item or script. We propose SOLAR, an auxiliary objective for supervised fine-tuning that aligns soft-token representations across languages, using English as a pivot. Soft tokens are probability-weighted mixtures over the vocabulary embeddings, yielding continuous representations that can aggregate information from semantically related tokens across languages. We then align each non-English soft-token summary to its English counterpart in the shared embedding space. Across four multilingual reasoning benchmarks, SOLAR improves accuracy by up to +17.7 points over the base model and +3.8 over standard supervised fine-tuning, with the largest gains on low-resource languages. SOLAR also strengthens final-layer cross-lingual similarity and substantially reduces language-cluster separability, suggesting that aligning soft-token representations helps preserve shared semantic structure during multilingual reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SOLAR, an auxiliary objective for supervised fine-tuning of multilingual LLMs that aligns soft-token representations—probability-weighted mixtures over vocabulary embeddings—of non-English inputs to their English counterparts in the shared embedding space. It reports accuracy improvements of up to +17.7 points over the base model and +3.8 over standard SFT across four multilingual reasoning benchmarks, with largest gains on low-resource languages, alongside strengthened final-layer cross-lingual similarity and reduced language-cluster separability.
Significance. If the gains are robust and the alignment demonstrably preserves semantic structure (rather than lexical copying), SOLAR could provide a practical technique for improving cross-lingual reasoning consistency by operating on continuous representations instead of discrete tokens.
major comments (2)
- [Proposed method (abstract)] The central claim that aligning soft-token summaries preserves shared semantic structure for reasoning (rather than driving the model to copy English lexical patterns or surface statistics) is not supported by any ablation that decouples semantic equivalence from lexical matching, such as alignment to English tokens with mismatched semantics. This is load-bearing for interpreting the accuracy gains and similarity metrics reported in the abstract, especially for low-resource languages where the base model may already favor English-like outputs.
- [Experiments] No implementation details, hyperparameter settings, training procedures, or error analysis are supplied, preventing assessment of whether the reported improvements are robust or sensitive to post-hoc choices.
minor comments (3)
- The abstract does not name the four multilingual reasoning benchmarks or cite prior work on them.
- The soft-token computation and alignment objective are described only in prose; formal equations would improve clarity and reproducibility.
- Secondary metrics (cross-lingual similarity, language-cluster separability) are mentioned without details on how they are computed or which layers are analyzed.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight important aspects of evidence strength and reproducibility. We respond to each major comment below.
read point-by-point responses
-
Referee: [Proposed method (abstract)] The central claim that aligning soft-token summaries preserves shared semantic structure for reasoning (rather than driving the model to copy English lexical patterns or surface statistics) is not supported by any ablation that decouples semantic equivalence from lexical matching, such as alignment to English tokens with mismatched semantics. This is load-bearing for interpreting the accuracy gains and similarity metrics reported in the abstract, especially for low-resource languages where the base model may already favor English-like outputs.
Authors: We agree that an explicit ablation aligning to semantically mismatched English tokens would provide stronger causal evidence. However, the SOLAR objective operates on soft tokens defined as probability-weighted mixtures over the full vocabulary embeddings; this continuous representation aggregates semantically related tokens rather than committing to specific lexical items. The largest gains occur on low-resource languages (where lexical copying is least viable due to script and vocabulary divergence), and the reported final-layer similarity increases plus reduced language-cluster separability are consistent with semantic rather than surface-level alignment. We will add an expanded discussion of this distinction and the limitations of the current evidence in the revised manuscript. revision: partial
-
Referee: [Experiments] No implementation details, hyperparameter settings, training procedures, or error analysis are supplied, preventing assessment of whether the reported improvements are robust or sensitive to post-hoc choices.
Authors: We apologize for insufficient visibility of these elements. Implementation details, hyperparameter settings, and training procedures are provided in Section 4.2 and Appendix B; error analysis appears in Section 5.3. In the revision we will insert a concise hyperparameter summary table in the main text and add explicit forward references from the experimental results section to ensure all information is readily accessible. revision: yes
Circularity Check
No circularity: empirical gains on external benchmarks
full rationale
The paper introduces SOLAR as an auxiliary alignment objective during supervised fine-tuning and validates it via accuracy improvements on four external multilingual reasoning benchmarks. These reported gains (+17.7 over base, +3.8 over standard SFT) are measured on held-out test sets and do not reduce by construction to any fitted parameter or self-defined quantity within the method. No equations, derivations, or predictions are presented that equate outputs to inputs; the central claims rest on observable benchmark performance and similarity metrics rather than self-referential fitting or self-citation chains. The approach is therefore self-contained against external evaluation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Long chain-of-thought reasoning across languages
Josh Barua, Seun Eisape, Kayo Yin, and Alane Suhr. Long chain-of-thought reasoning across languages. InThe Fourteenth International Conference on Learning Representations, 2026. URLhttps://openreview.net/forum?id=2kKXbsRhYI
2026
-
[2]
AlignX: Advancing multilingual large language models with multilingual representation alignment
Mengyu Bu, Shaolei Zhang, Zhongjun He, Hua Wu, and Yang Feng. AlignX: Advancing multilingual large language models with multilingual representation alignment. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 6460– 6489, S...
-
[3]
Align once, benefit multilingually: Enforcing multilingual consistency for LLM safety alignment
Yuyan Bu, Xiaohao Liu, ZhaoXing Ren, Yaodong Yang, and Juntao Dai. Align once, benefit multilingually: Enforcing multilingual consistency for LLM safety alignment. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview. net/forum?id=ueknOG1wXL
2026
-
[4]
Soft tokens, hard truths, 2025
Natasha Butt, Ariel Kwiatkowski, Ismail Labiad, Julia Kempe, and Yann Ollivier. Soft tokens, hard truths, 2025. URLhttps://arxiv.org/abs/2509.19170
arXiv 2025
-
[5]
Less data less tokens: Multilingual unification learning for efficient test-time reasoning in llms, 2025
Kang Chen, Mengdi Zhang, and Yixin Cao. Less data less tokens: Multilingual unification learning for efficient test-time reasoning in llms, 2025. URLhttps://arxiv.org/abs/2506. 18341
2025
-
[6]
Reasoning beyond language: A comprehensive survey on latent chain-of-thought reasoning, 2025
Xinghao Chen, Anhao Zhao, Heming Xia, Xuan Lu, Hanlin Wang, Yanjun Chen, Wei Zhang, Jian Wang, Wenjie Li, and Xiaoyu Shen. Reasoning beyond language: A comprehensive survey on latent chain-of-thought reasoning, 2025. URLhttps://arxiv.org/abs/2505.16782
arXiv 2025
-
[7]
Translation and fusion improves cross-lingual infor- mation extraction
Yang Chen, Vedaant Shah, and Alan Ritter. Translation and fusion improves cross-lingual infor- mation extraction. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 7744–7764, Vienna, Austria, July 202...
-
[8]
Training verifiers to solve math word problems, 2021
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems, 2021. URL https://arxiv.org/ abs/2110.14168
Pith/arXiv arXiv 2021
-
[9]
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning, 2025
DeepSeek-AI. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning, 2025. URLhttps://arxiv.org/abs/2501.12948. 11
Pith/arXiv arXiv 2025
-
[10]
Aligning multilingual reasoning with verifiable semantics from a high-resource expert model, 2025
Fahim Faisal, Kaiqiang Song, Song Wang, Simin Ma, Shujian Liu, Haoyun Deng, and Sathish Reddy Indurthi. Aligning multilingual reasoning with verifiable semantics from a high-resource expert model, 2025. URLhttps://arxiv.org/abs/2509.25543
arXiv 2025
-
[11]
Revisiting multi- lingual data mixtures in language model pretraining, 2025
Negar Foroutan, Paul Teiletche, Ayush Kumar Tarun, and Antoine Bosselut. Revisiting multi- lingual data mixtures in language model pretraining, 2025. URL https://arxiv.org/abs/ 2510.25947
arXiv 2025
-
[13]
URLhttps://aclanthology.org/2025.emnlp-main.1416/
2025
-
[14]
Shengxiang Gao, Fang Nan, Yongbing Zhang, Yuxin Huang, Kaiwen Tan, and Zhengtao Yu. A mixed-language multi-document news summarization dataset and a graphs-based extract- generate model. In Luis Chiruzzo, Alan Ritter, and Lu Wang, editors,Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguis...
-
[15]
A Survey of Multilingual Reasoning in Language Models
Akash Ghosh, Debayan Datta, Sriparna Saha, and Chirag Agarwal. A survey of multilingual reasoning in language models. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Findings of the Association for Computational Linguistics: EMNLP 2025, pages 8920–8936, Suzhou, China, November 2025. Association for Computa- tiona...
-
[16]
Gemini 2.0 Flash Model Card, 2025
Google DeepMind. Gemini 2.0 Flash Model Card, 2025. URL https://storage. googleapis.com/model-cards/documents/gemini-2-flash.pdf
2025
-
[17]
Continuous chain of thought enables parallel exploration and reasoning
Halil Alperen Gozeten, Muhammed Emrullah Ildiz, Xuechen Zhang, Hrayr Harutyunyan, Ankit Singh Rawat, and Samet Oymak. Continuous chain of thought enables parallel exploration and reasoning. InICML 2025 Workshop on Methods and Opportunities at Small Scale, 2025. URLhttps://openreview.net/forum?id=1ORJaYuMJc
2025
-
[18]
Ping Guo, Yubing Ren, Yue Hu, Yanan Cao, Yunpeng Li, and Heyan Huang. Steering large language models for cross-lingual information retrieval. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Re- trieval, SIGIR ’24, page 585–596, New York, NY , USA, 2024. Association for Comput- ing Machinery. ISBN 979...
-
[19]
Training large language models to reason in a continuous latent space
Shibo Hao, Sainbayar Sukhbaatar, DiJia Su, Xian Li, Zhiting Hu, Jason E Weston, and Yuandong Tian. Training large language models to reason in a continuous latent space. InWorkshop on Reasoning and Planning for Large Language Models, 2025. URL https://openreview. net/forum?id=KrWSrrYGpT
2025
-
[20]
Beyond english-centric training: How reinforcement learning improves cross-lingual reasoning in LLMs
Shulin Huang, Yiran Ding, Junshu Pan, and Yue Zhang. Beyond english-centric training: How reinforcement learning improves cross-lingual reasoning in LLMs. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview. net/forum?id=hdrG6SaTcA
2026
-
[21]
Tapo: Translation augmented policy optimization for multilingual mathematical reasoning, 2026
Xu Huang, Zhejian Lai, Zixian Huang, Jiajun Chen, and Shujian Huang. Tapo: Translation augmented policy optimization for multilingual mathematical reasoning, 2026. URL https: //arxiv.org/abs/2603.25419
arXiv 2026
-
[22]
Learn globally, speak locally: Bridging the gaps in multilingual reasoning, 2025
Jaedong Hwang, Kumar Tanmay, Seok-Jin Lee, Ayush Agrawal, Hamid Palangi, Kumar Ayush, Ila Fiete, and Paul Pu Liang. Learn globally, speak locally: Bridging the gaps in multilingual reasoning, 2025. URLhttps://arxiv.org/abs/2507.05418. 12
arXiv 2025
-
[23]
AIME-2025 Dataset, 2025
Kaggle. AIME-2025 Dataset, 2025. URL https://www.kaggle.com/datasets/ hengck23/hengck23-aime-2025
2025
-
[24]
Tannon Kew, Florian Schottmann, and Rico Sennrich. Turning English-centric LLMs into polyglots: How much multilinguality is needed? In Yaser Al-Onaizan, Mohit Bansal, and Yun- Nung Chen, editors,Findings of the Association for Computational Linguistics: EMNLP 2024, pages 13097–13124, Miami, Florida, USA, November 2024. Association for Computational Lingui...
-
[25]
mCoT: Multilingual instruction tuning for reasoning consistency in language models
Huiyuan Lai and Malvina Nissim. mCoT: Multilingual instruction tuning for reasoning consistency in language models. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, ed- itors,Proceedings of the 62nd Annual Meeting of the Association for Computational Lin- guistics (Volume 1: Long Papers), pages 12012–12026, Bangkok, Thailand, August 2024. Association for...
-
[26]
Cross-lingual optimization for language transfer in large language models
Jungseob Lee, Seongtae Hong, Hyeonseok Moon, and Heuiseok Lim. Cross-lingual optimization for language transfer in large language models. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 15100– 15119...
-
[27]
Steering merged LLMs for multilingual rea- soning with coefficient optimization, 2025
Zhuoran Li, Rui Xu, Xiaojie Wang, Junnan Liu, Zhijun Chen, Qianren Mao, Jian Yang, Hongcheng Guo, Likang Xiao, and MING LI. Steering merged LLMs for multilingual rea- soning with coefficient optimization, 2025. URL https://openreview.net/forum?id= TQjGGTnotA
2025
-
[28]
Zheng Wei Lim, Alham Fikri Aji, and Trevor Cohn. Language-specific latent process hinders cross-lingual performance.arXiv preprint arXiv:2505.13141, 2025. URL https://arxiv. org/abs/2505.13141
arXiv 2025
-
[29]
From translation to multilinguality: Revisit the role of parallel data in multilingual LLM pretraining, 2025
Haobin Lin, Yan Zhao, Wenhan Han, Ping Guo, BINBINLIU, Yifan Zhang, Bingni Zhang, Taifeng Wang, and Yin Zheng. From translation to multilinguality: Revisit the role of parallel data in multilingual LLM pretraining, 2025. URL https://openreview.net/forum?id= 1gbJ8euERb
2025
-
[30]
Danni Liu and Jan Niehues. Middle-layer representation alignment for cross-lingual transfer in fine-tuned LLMs. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 15979–15996, Vienna, Austria, July 202...
-
[31]
URLhttps://aclanthology.org/2025.acl-long.778/
2025
-
[32]
Optimizing language models for crosslingual knowledge consistency, 2026
Tianyu Liu, Jirui Qi, Mrinmaya Sachan, Ryan Cotterell, Raquel Fernández, and Arianna Bisazza. Optimizing language models for crosslingual knowledge consistency, 2026. URL https://openreview.net/forum?id=nupbCYlmEE
2026
-
[33]
Focusing on language: Revealing and exploiting language attention heads in multilingual large language models
Xin Liu, Qiyang Song, Qihang Zhou, Haichao Du, Shaowen Xu, Wenbo Jiang, Weijuan Zhang, and Xiaoqi Jia. Focusing on language: Revealing and exploiting language attention heads in multilingual large language models. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 32195–32203, 2026
2026
-
[34]
Decoupled weight decay regularization, 2019
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization, 2019. URL https: //arxiv.org/abs/1711.05101
Pith/arXiv arXiv 2019
-
[36]
URLhttps://aclanthology.org/2025.emnlp-main.1025/
2025
-
[37]
Aka, Folafunmi Omofoye, Foutse Yuehgoh, Timothy Faniran, Bonaventure F
Charles Nimo, Tobi Olatunji, Abraham Toluwase Owodunni, Tassallah Abdullahi, Emmanuel Ayodele, Mardhiyah Sanni, Ezinwanne C. Aka, Folafunmi Omofoye, Foutse Yuehgoh, Timothy Faniran, Bonaventure F. P. Dossou, Moshood O. Yekini, Jonas Kemp, Katherine A Heller, Jude Chidubem Omeke, Chidi Asuzu Md, Naome A Etori, Aïmérou Ndiaye, Ifeoma Okoh, Evans Doe Ocansey...
-
[38]
Qiwei Peng, Guimin Hu, Yekun Chai, and Anders Søgaard. Debiasing multilingual LLMs in cross-lingual latent space. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 22582–22593, Suzhou, China, November 2025. Association for...
-
[39]
URLhttps://aclanthology.org/2025.emnlp-main.1149/
2025
-
[40]
Multimodal chain of continuous thought for latent-space reasoning in vision-language models
Tan-Hanh Pham and Chris Ngo. Multimodal chain of continuous thought for latent-space reasoning in vision-language models. InNeurIPS 2025 Workshop on Efficient Reasoning, 2025. URLhttps://openreview.net/forum?id=PXFTV1O2WJ
2025
-
[41]
Cross-lingual activation steering for multilingual language models, 2026
Rhitabrat Pokharel, Ameeta Agrawal, and Tanay Nagar. Cross-lingual activation steering for multilingual language models, 2026. URLhttps://arxiv.org/abs/2601.16390
arXiv 2026
-
[42]
In: Proceedings of EMNLP 2023, pp 10650 to 10666
Jirui Qi, Raquel Fernández, and Arianna Bisazza. Cross-lingual consistency of factual knowl- edge in multilingual language models. In Houda Bouamor, Juan Pino, and Kalika Bali, editors, Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 10650–10666, Singapore, December 2023. Association for Computational Linguis-...
-
[43]
When Models Reason in Your Language: Controlling Thinking Language Comes at the Cost of Accuracy
Jirui Qi, Shan Chen, Zidi Xiong, Raquel Fernández, Danielle Bitterman, and Arianna Bisazza. When models reason in your language: Controlling thinking language comes at the cost of accuracy. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Findings of the Association for Computational Linguistics: EMNLP 2025, pages...
-
[44]
Just go parallel: Improving the multi- lingual capabilities of large language models
Muhammad Reza Qorib, Junyi Li, and Hwee Tou Ng. Just go parallel: Improving the multi- lingual capabilities of large language models. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 33411–33424, Vi-...
-
[45]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Information Processing Systems, volume 36, pages 53728–53741. Curran Associ...
2023
-
[46]
Generalized Slow Roll for Tensors
Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He. Zero: Memory opti- mizations toward training trillion parameter models. InSC20: International Conference for 14 High Performance Computing, Networking, Storage and Analysis, pages 1–16, 2020. doi: 10.1109/SC41405.2020.00024
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1109/sc41405.2020.00024 2020
-
[47]
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. GPQA: A graduate-level google- proof q&a benchmark. InFirst Conference on Language Modeling, 2024. URL https: //openreview.net/forum?id=Ti67584b98
2024
-
[48]
Journal of Computational and Applied Mathematics , author =
Peter J. Rousseeuw. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis.Journal of Computational and Applied Mathematics, 20:53–65, 1987. ISSN 0377-0427. doi: https://doi.org/10.1016/0377-0427(87)90125-7. URL https://www.sciencedirect. com/science/article/pii/0377042787901257
-
[49]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models, 2024. URL https://arxiv.org/abs/ 2402.03300
Pith/arXiv arXiv 2024
-
[50]
MAPO : Advancing Multilingual Reasoning through Multilingual-Alignment-as-Preference Optimization
Shuaijie She, Wei Zou, Shujian Huang, Wenhao Zhu, Xiang Liu, Xiang Geng, and Jiajun Chen. MAPO: Advancing multilingual reasoning through multilingual-alignment-as-preference optimization. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)...
-
[51]
InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing
Zhenyi Shen, Hanqi Yan, Linhai Zhang, Zhanghao Hu, Yali Du, and Yulan He. CODI: Compress- ing chain-of-thought into continuous space via self-distillation. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Proceedings of the 2025 Confer- ence on Empirical Methods in Natural Language Processing, pages 677–693, Suzho...
-
[52]
Language models are multilingual chain-of-thought reasoners
Freda Shi, Mirac Suzgun, Markus Freitag, Xuezhi Wang, Suraj Srivats, Soroush V osoughi, Hyung Won Chung, Yi Tay, Sebastian Ruder, Denny Zhou, Dipanjan Das, and Jason Wei. Language models are multilingual chain-of-thought reasoners. InThe Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum? id=fR3wGCk-IXp
2023
-
[53]
Linguistic generalizability of test-time scaling in mathematical reasoning
Guijin Son, Jiwoo Hong, Hyunwoo Ko, and James Thorne. Linguistic generalizability of test-time scaling in mathematical reasoning. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 14333– 14368, Vienna...
-
[54]
Pushing on multilingual reasoning models with language-mixed chain-of-thought
Guijin Son, Donghun Yang, Hitesh Laxmichand Patel, Amit Agarwal, Hyunwoo Ko, Chanuk lim, Srikant Panda, Minhyuk Kim, Nikunj drolia, Dasol Choi, Kyong-Ha Lee, and Youngjae Yu. Pushing on multilingual reasoning models with language-mixed chain-of-thought. In The Fourteenth International Conference on Learning Representations, 2026. URL https: //openreview.n...
2026
-
[55]
Think silently, think fast: Dynamic latent compression of LLM reasoning chains
Wenhui Tan, Jiaze Li, Jianzhong Ju, Zhenbo Luo, Ruihua Song, and Jian Luan. Think silently, think fast: Dynamic latent compression of LLM reasoning chains. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URL https://openreview. net/forum?id=AQsko3PPUe
2025
-
[56]
Multilingual LLM s are Better Cross-lingual In-context Learners with Alignment
Eshaan Tanwar, Subhabrata Dutta, Manish Borthakur, and Tanmoy Chakraborty. Multilingual LLMs are better cross-lingual in-context learners with alignment. In Anna Rogers, Jordan Boyd- Graber, and Naoaki Okazaki, editors,Proceedings of the 61st Annual Meeting of the Association 15 for Computational Linguistics (Volume 1: Long Papers), pages 6292–6307, Toron...
-
[57]
Gemma Team, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ramé, Morgane Rivière, Louis Rouillard, Thomas Mesnard, Geoffrey Cideron, Jean bastien Grill, Sabela Ramos, Edouard Yvinec, Michelle Casbon, Etienne Pot, Ivo Penchev, Gaël Liu, Francesco Visin, Kathleen Kenealy, Lucas Bey...
Pith/arXiv arXiv 2025
-
[58]
NLLB Team, Marta R. Costa-jussà, James Cross, Onur Çelebi, Maha Elbayad, Kenneth Heafield, Kevin Heffernan, Elahe Kalbassi, Janice Lam, Daniel Licht, Jean Maillard, Anna Sun, Skyler Wang, Guillaume Wenzek, Al Youngblood, Bapi Akula, Loic Barrault, Gabriel Mejia Gonzalez, Prangthip Hansanti, John Hoffman, Semarley Jarrett, Kaushik Ram Sadagopan, Dirk Rowe,...
Pith/arXiv arXiv 2022
-
[59]
The transfer neurons hypothesis: An underlying mechanism for language latent space transitions in multilingual LLMs
Hinata Tezuka and Naoya Inoue. The transfer neurons hypothesis: An underlying mechanism for language latent space transitions in multilingual LLMs. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 31742–31792, Suzhou, Chi...
2025
-
[60]
Aime problem set 1983-2024, 2024
Hemish Veeraboina. Aime problem set 1983-2024, 2024. URL https://www.kaggle.com/ datasets/hemishveeraboina/aime-problem-set-1983-2024
1983
-
[61]
Lost in multilinguality: Dissecting cross-lingual factual inconsistency in transformer language models
Mingyang Wang, Heike Adel, Lukas Lange, Yihong Liu, Ercong Nie, Jannik Strötgen, and Hinrich Schuetze. Lost in multilinguality: Dissecting cross-lingual factual inconsistency in transformer language models. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Proceedings of the 63rd Annual Meeting of the Association for ...
2025
-
[62]
Bridging the Language Gaps in Large Language Models with Inference-Time Cross-Lingual Intervention
Weixuan Wang, Minghao Wu, Barry Haddow, and Alexandra Birch. Bridging the language gaps in large language models with inference-time cross-lingual intervention. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Pape...
-
[63]
Yumeng Wang, Zhiyuan Fan, Qingyun Wang, Yi R. Fung, and Heng Ji. CALM: Unleashing the cross-lingual self-aligning ability of language model question answering. In Luis Chiruzzo, Alan Ritter, and Lu Wang, editors,Findings of the Association for Computational Linguistics: NAACL 2025, pages 2809–2817, Albuquerque, New Mexico, April 2025. Association for Comp...
-
[64]
Cross-lingual data scaling for large language models, 2026
Zhihao Wang, Junjie Huang, Jianheng Huang, Tong Sun, Yaoxiang Wang, dingqi, Hongjian Zou, YiXuan Liao, Xiaoxin Chen, Junfeng Yao, Yidong Chen, and Jinsong Su. Cross-lingual data scaling for large language models, 2026. URL https://openreview.net/forum?id= yuRO2wZ8su
2026
-
[65]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, brian ichter, Fei Xia, Ed Chi, Quoc V Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors, Advances in Neural Information Processing Systems, volume 35, pages 24824–24837. Curran Assoc...
2022
-
[66]
Llms are single-threaded reasoners: Demystifying the working mechanism of soft thinking, 2025
Junhong Wu, Jinliang Lu, Zixuan Ren, Gangqiang Hu, Zhi Wu, Dai Dai, and Hua Wu. Llms are single-threaded reasoners: Demystifying the working mechanism of soft thinking, 2025. URL https://arxiv.org/abs/2508.03440
arXiv 2025
-
[67]
mGRPO: Unlocking LLM reasoning through multilingual thinking,
Linjuan Wu, Hao-Ran Wei, Jialong Tang, Shuang Luo, Baosong Yang, Fei Huang, Yongliang Shen, and Weiming Lu. mGRPO: Unlocking LLM reasoning through multilingual thinking,
-
[68]
URLhttps://openreview.net/forum?id=QtfALPluAj
-
[69]
A formal comparison between chain of thought and latent thought,
Kevin Xu and Issei Sato. A formal comparison between chain of thought and latent thought,
-
[70]
URLhttps://arxiv.org/abs/2509.25239
-
[71]
SoftCoT: Soft chain-of-thought for efficient reasoning with LLMs
Yige Xu, Xu Guo, Zhiwei Zeng, and Chunyan Miao. SoftCoT: Soft chain-of-thought for efficient reasoning with LLMs. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 23336–23351, Vienna, Austria, July 2...
2025
-
[72]
Linguistic neuron overlap patterns to facilitate cross-lingual transfer on low-resource languages
Yuemei Xu, Kexin Xu, Jian Zhou, Ling Hu, and Lin Gui. Linguistic neuron overlap patterns to facilitate cross-lingual transfer on low-resource languages. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Proceedings of the 2025 Con- ference on Empirical Methods in Natural Language Processing, pages 27658–27673, Suzh...
2025
-
[73]
URL https://aclanthology.org/2025
doi: 10.18653/v1/2025.emnlp-main.1407. URL https://aclanthology.org/2025. emnlp-main.1407/. 17
-
[74]
MMLU - P ro X : A Multilingual Benchmark for Advanced Large Language Model Evaluation
Weihao Xuan, Rui Yang, Heli Qi, Qingcheng Zeng, Yunze Xiao, Aosong Feng, Dairui Liu, Yun Xing, Junjue Wang, Fan Gao, Jinghui Lu, Yuang Jiang, Huitao Li, Xin Li, Kunyu Yu, Ruihai Dong, Shangding Gu, Yuekang Li, Xiaofei Xie, Felix Juefei-Xu, Foutse Khomh, Osamu Yoshie, Qingyu Chen, Douglas Teodoro, Nan Liu, Randy Goebel, Lei Ma, Edi- son Marrese-Taylor, Shi...
-
[75]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
Pith/arXiv arXiv 2025
-
[76]
Wen Yang, Junhong Wu, Chong Li, Chengqing Zong, and Jiajun Zhang. Parallel scaling law: Unveiling reasoning generalization through a cross-linguistic perspective, 2025. URL https://arxiv.org/abs/2510.02272
arXiv 2025
-
[77]
Zheng-Xin Yong, M. Farid Adilazuarda, Jonibek Mansurov, Ruochen Zhang, Niklas Muen- nighoff, Carsten Eickhoff, Genta Indra Winata, Julia Kreutzer, Stephen H. Bach, and Al- ham Fikri Aji. Crosslingual reasoning through test-time scaling, 2025. URL https: //arxiv.org/abs/2505.05408
arXiv 2025
-
[78]
Code-switching in-context learning for cross-lingual transfer of large language models, 2025
Haneul Yoo, Jiho Jin, Kyunghyun Cho, and Alice Oh. Code-switching in-context learning for cross-lingual transfer of large language models, 2025. URL https://arxiv.org/abs/2510. 05678
2025
-
[79]
Xue Zhang, Yunlong Liang, Fandong Meng, Songming Zhang, Kaiyu Huang, Yufeng Chen, Jinan Xu, and Jie Zhou. Think natively: Unlocking multilingual reasoning with consistency- enhanced reinforcement learning, 2026. URLhttps://arxiv.org/abs/2510.07300
arXiv 2026
-
[80]
Soft thinking: Unlocking the reasoning potential of LLMs in continuous concept space
Zhen Zhang, Xuehai He, Weixiang Yan, Ao Shen, Chenyang Zhao, and Xin Eric Wang. Soft thinking: Unlocking the reasoning potential of LLMs in continuous concept space. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URL https://openreview.net/forum?id=ByQdHPGKgU
2025
-
[81]
Align to the pivot: Dual alignment with self-feedback for multilingual math reasoning, 2026
Chunxu Zhao, Xin Huang, Xue Han, Shujian Huang, Chao Deng, and Junlan Feng. Align to the pivot: Dual alignment with self-feedback for multilingual math reasoning, 2026. URL https://arxiv.org/abs/2601.17671
arXiv 2026
- [82]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.