Localizing RL-Induced Tool Use to a Single Crosscoder Feature
Pith reviewed 2026-06-26 05:39 UTC · model grok-4.3
The pith
Dedicated Feature Crosscoders isolate a compact set of RL-specific features that mediate tool-calling in Qwen2.5-3B and enable runtime behavioral control.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
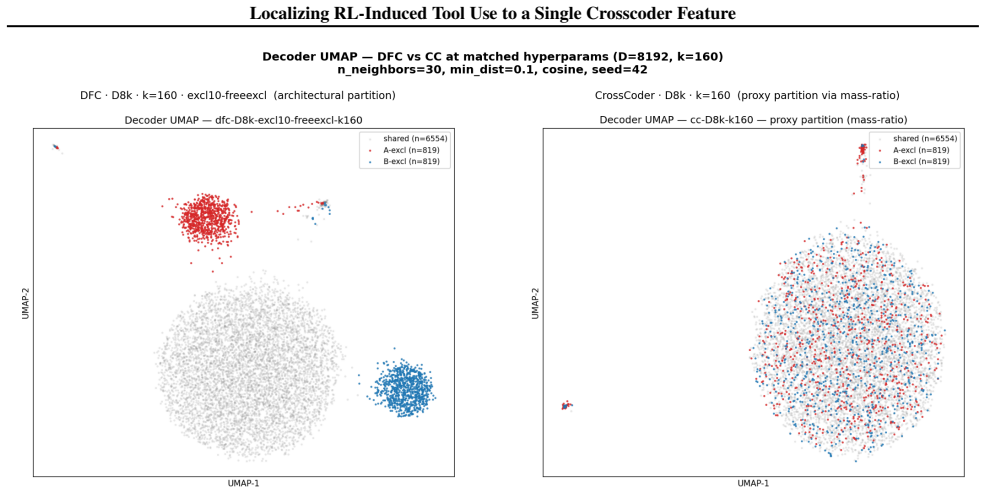
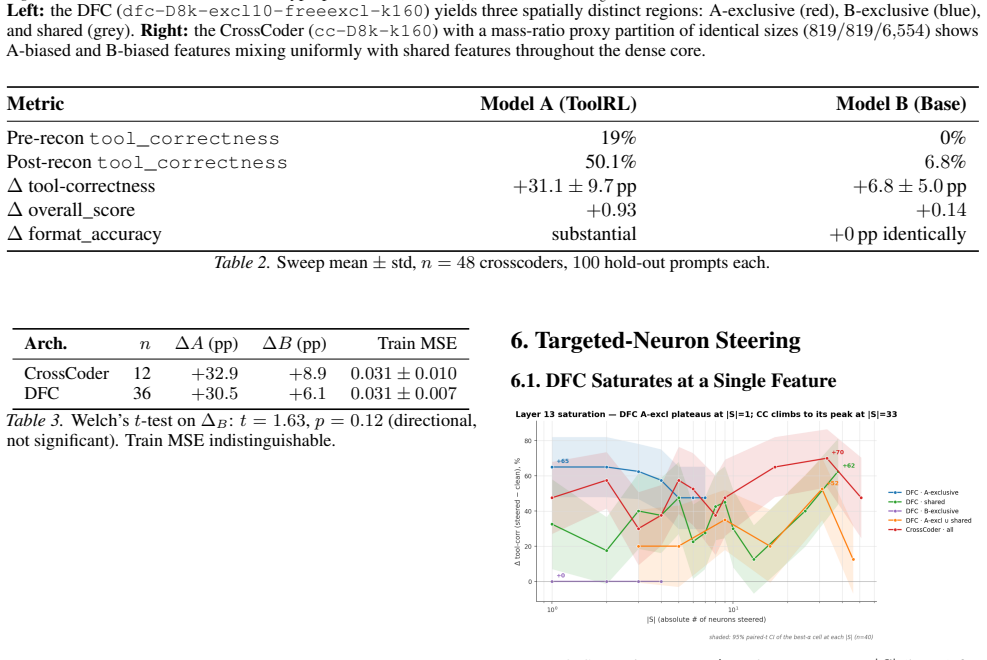
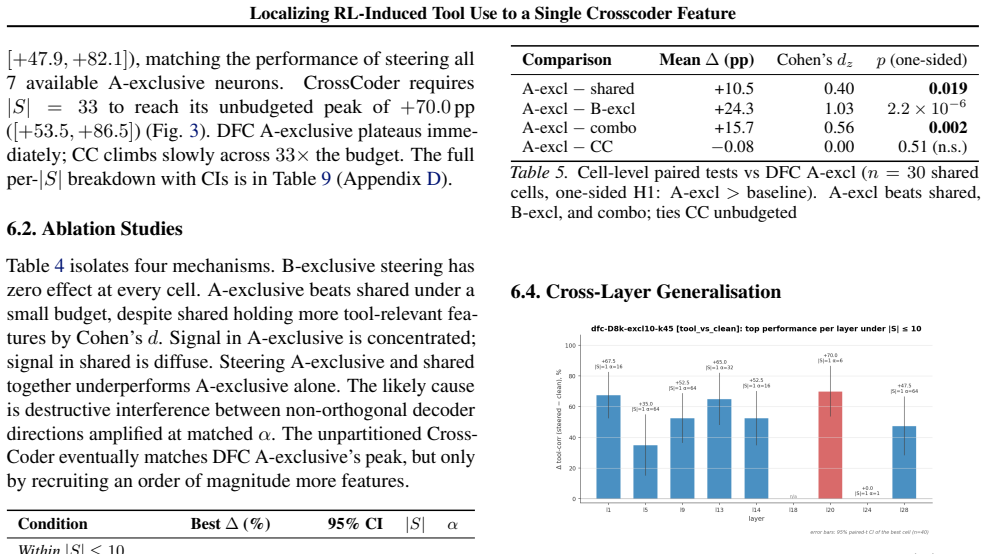
Dedicated Feature Crosscoders (DFC) isolate a compact set of RL-specific features that mediate tool-calling capability in Qwen2.5-3B. Across a 48-crosscoder hyperparameter sweep, encode-decode reconstruction improves the RL model's tool correctness by +31.1 ± 9.7 pp and passively transfers tool-calling ability to the frozen base model by +6.8 ± 5.0 pp which we call a capability spillover. Our findings show that DFC partitioning concentrates RL-introduced capability into a minimal, steerable feature set that enables runtime behavioral control of agentic LLMs.
What carries the argument
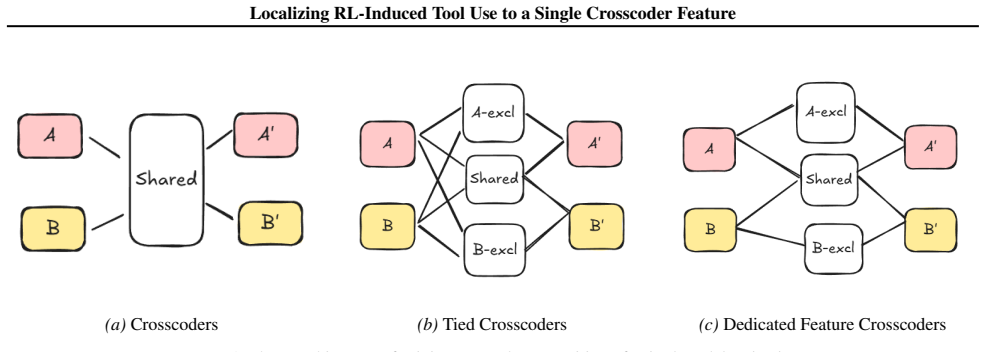
Dedicated Feature Crosscoders (DFC), a partitioning method that separates RL-introduced features from preserved base-model features to support targeted encode-decode reconstruction.
If this is right
- Encode-decode reconstruction with DFC features raises tool correctness by 31.1 percentage points on average in the RL model.
- Tool-calling ability transfers passively to the base model by 6.8 percentage points through capability spillover.
- RL-introduced capability concentrates into a minimal set of features rather than spreading diffusely.
- The isolated features support runtime behavioral control of agentic LLMs without further training.
Where Pith is reading between the lines
- If the features prove causal, targeted interventions on them could toggle tool use on or off at inference time.
- The same partitioning approach might localize other RL-induced behaviors such as multi-step planning.
- Runtime feature steering could reduce reliance on full retraining for adjusting agentic model behavior.
Load-bearing premise
The encode-decode reconstruction using the identified crosscoder features is assumed to causally mediate the observed tool-calling improvements rather than merely correlating with them or capturing unrelated variance.
What would settle it
An ablation or intervention experiment on the isolated features that fails to produce the expected change in tool-calling behavior while leaving other capabilities intact would falsify the mediation claim.
Figures
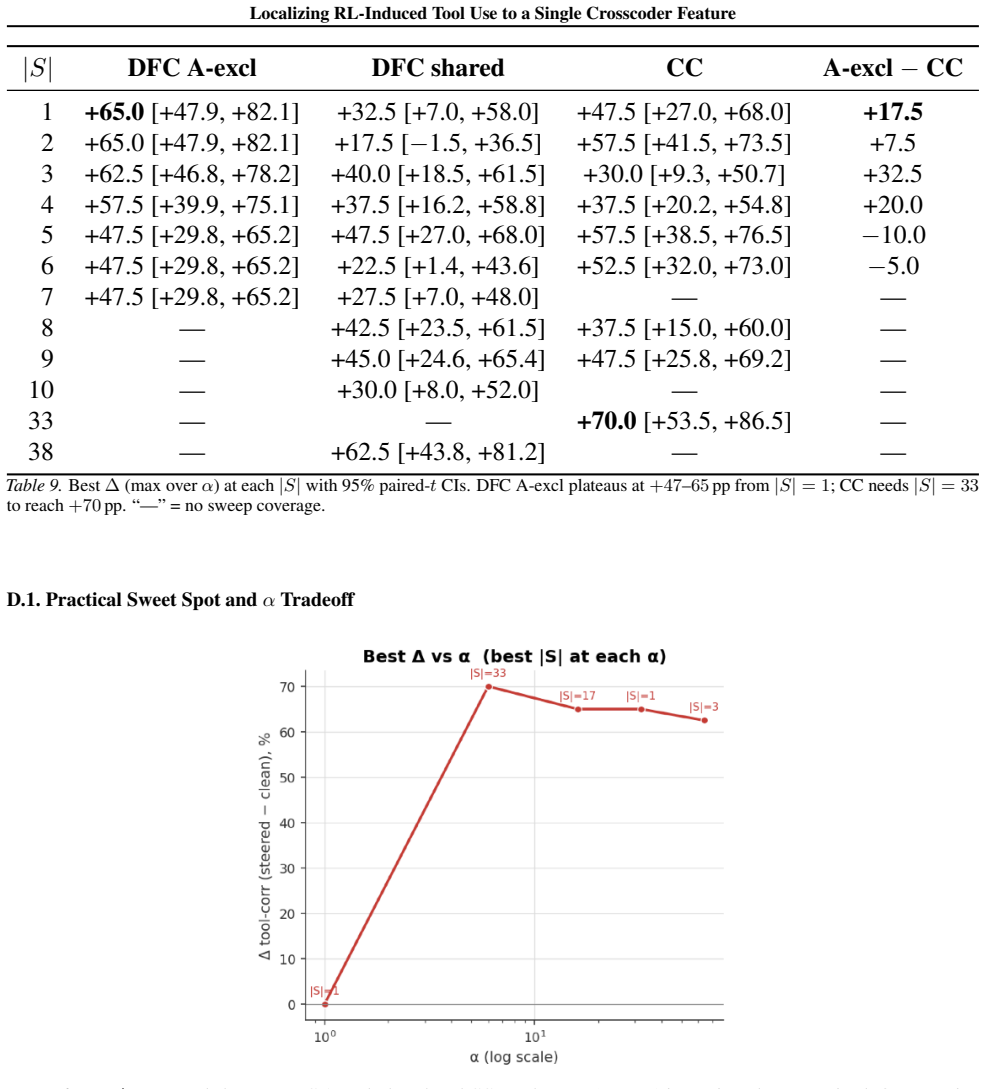

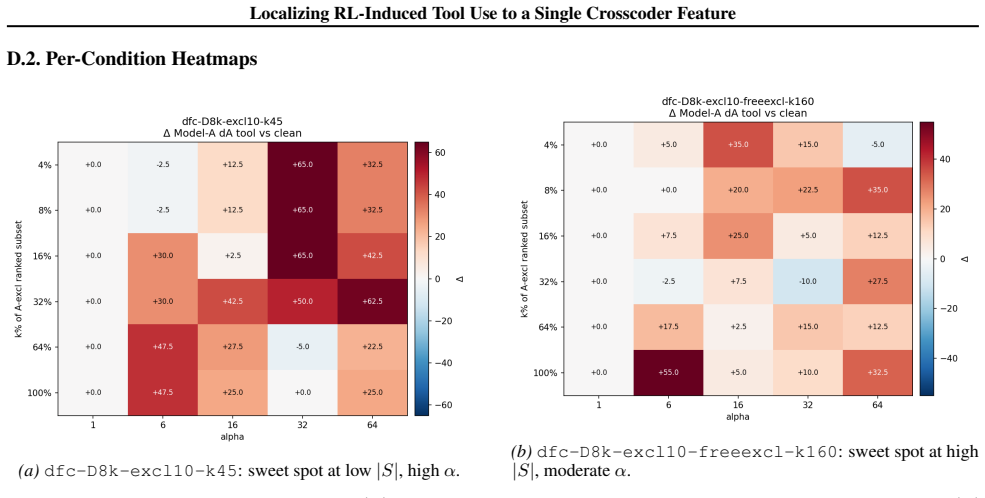
read the original abstract
Fine-tuning through RL reshapes the internal representations of language models to enable agentic behaviors such as tool use, yet the mechanistic basis of these changes remains poorly understood. While RL substantially improves structured tool-call generation, it is unclear which features emerge, which are preserved, and whether identified features can be leveraged for retraining-free behavioral control. In this work, we show that $\textit{Dedicated Feature Crosscoders (DFC)}$ isolate a compact set of RL-specific features that mediate tool-calling capability in $\texttt{Qwen2.5-3B}$. Across a $48$-crosscoder hyperparameter sweep, encode-decode reconstruction improves the RL model's tool correctness by $+31.1 \pm {9.7}$ pp and passively transfers tool-calling ability to the frozen base model by $+6.8 \pm 5.0$ pp which we call a $\textit{capability spillover}$. Our findings show that DFC partitioning concentrates RL-introduced capability into a minimal, steerable feature set that enables runtime behavioral control of agentic LLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that Dedicated Feature Crosscoders (DFC) isolate a compact set of RL-specific features mediating tool-calling capability in Qwen2.5-3B. A 48-crosscoder hyperparameter sweep shows that encode-decode reconstruction using these features raises tool correctness by +31.1 ± 9.7 pp on the RL-tuned model and produces a +6.8 ± 5.0 pp spillover on the frozen base model, enabling runtime behavioral control without retraining.
Significance. If the mediation claim is substantiated, the work would offer a practical route to localize and steer RL-induced agentic capabilities via crosscoders, advancing mechanistic interpretability of post-training changes. The scale of the hyperparameter sweep and the reported spillover effect are concrete strengths that could support falsifiable follow-up experiments on feature necessity.
major comments (2)
- [Abstract] Abstract: The central claim that the DFC-isolated features 'mediate' tool-calling capability rests on encode-decode reconstruction gains alone. No ablation, feature-knockout, path-intervention, or necessity test in the original forward pass is referenced, leaving open whether the performance lift arises from the specific features, the reconstruction operator, or correlated but non-causal variance.
- [Abstract] Abstract: The reported improvements (+31.1 pp and +6.8 pp) are presented without description of baselines, control conditions, statistical tests, data exclusion criteria, or variance across seeds, making it impossible to assess whether the numbers support the causal mediation interpretation.
Simulated Author's Rebuttal
We thank the referee for the constructive comments regarding the interpretation of our results as mediation and the completeness of experimental reporting in the abstract. We respond to each point below, indicating planned revisions where the manuscript can be strengthened without overstating the current evidence.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the DFC-isolated features 'mediate' tool-calling capability rests on encode-decode reconstruction gains alone. No ablation, feature-knockout, path-intervention, or necessity test in the original forward pass is referenced, leaving open whether the performance lift arises from the specific features, the reconstruction operator, or correlated but non-causal variance.
Authors: We agree that the primary evidence consists of encode-decode reconstruction gains rather than direct necessity tests such as feature knockouts or path interventions performed in the unmodified forward pass of the original model. The 48-crosscoder sweep provides some robustness by demonstrating that gains are configuration-dependent and concentrated in particular DFC features. Nevertheless, this leaves open the possibility that the lift could partly reflect properties of the reconstruction operator itself. We will revise the abstract and discussion sections to replace 'mediate' with language such as 'localize' or 'are sufficient to recover' and to explicitly note the absence of forward-pass necessity tests as a limitation of the current work. revision: yes
-
Referee: [Abstract] Abstract: The reported improvements (+31.1 pp and +6.8 pp) are presented without description of baselines, control conditions, statistical tests, data exclusion criteria, or variance across seeds, making it impossible to assess whether the numbers support the causal mediation interpretation.
Authors: The reported ± values are the standard deviations computed across the 48 hyperparameter configurations in the sweep; this is the variability measure used in the study. The full manuscript describes the baseline (tool correctness of the unreconstructed RL model) and the control condition (spillover measured on the frozen base model). We will expand the abstract to briefly reference these baselines and controls. Data exclusion followed the standard protocol of the tool-use benchmark. However, the experiments did not include multiple random seeds independent of the hyperparameter sweep, so variance across seeds cannot be added; we will note this as a limitation in the revised manuscript. revision: partial
Circularity Check
No circularity: empirical outcomes from hyperparameter sweep
full rationale
The paper reports results from a 48-crosscoder hyperparameter sweep in which encode-decode reconstruction using DFC features produces measured gains in tool correctness (+31.1 pp on the RL model, +6.8 pp spillover on the base model). These are presented as direct experimental outcomes rather than quantities derived from the inputs by definition, fitted parameters renamed as predictions, or load-bearing self-citations. No equations, uniqueness theorems, or ansatzes are shown that reduce the central claim to its own inputs; the derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Transformer Circuits Thread , year=
Toy Models of Superposition , author=. Transformer Circuits Thread , year=
-
[2]
Transformer Circuits Thread , year=
Towards Monosemanticity: Decomposing Language Models With Dictionary Learning , author=. Transformer Circuits Thread , year=
-
[3]
arXiv preprint arXiv:2309.08600 , year=
Sparse Autoencoders Find Highly Interpretable Features in Language Models , author=. arXiv preprint arXiv:2309.08600 , year=
-
[4]
Scaling Monosemanticity: Extracting Interpretable Features from
Templeton, Adly and Conerly, Tom and Marcus, Jonathan and others , journal=. Scaling Monosemanticity: Extracting Interpretable Features from. 2024 , url=
2024
-
[5]
Transformer Circuits Thread , year=
Sparse Crosscoders for Cross-Layer Features and Model Diffing , author=. Transformer Circuits Thread , year=
-
[6]
Mechanistic Interpretability Workshop at NeurIPS 2025 , year=
Cross-Architecture Model Diffing with Crosscoders: Unsupervised Discovery of Differences Between LLMs , author=. Mechanistic Interpretability Workshop at NeurIPS 2025 , year=
2025
-
[7]
2025 , eprint=
ToolRL: Reward is All Tool Learning Needs , author=. 2025 , eprint=
2025
-
[8]
Acikgoz, Emrecan and others , year=
-
[9]
arXiv preprint arXiv:2412.15115 , year=
-
[10]
Advances in Neural Information Processing Systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in Neural Information Processing Systems , volume=
-
[11]
arXiv preprint arXiv:2502.04382 , year=
Validation Methods for Neural Network Interpretability , author=. arXiv preprint arXiv:2502.04382 , year=
-
[12]
User-Assistant Bias in
Pan, Xu and Fan, Jingxuan and Xiong, Zidi and Hahami, Ely and Overwiening, Jorin and Xie, Ziqian , journal =. User-Assistant Bias in
-
[13]
Locating and Editing Factual Associations in
Meng, Kevin and Bau, David and Andonian, Alex and Belinkov, Yonatan , booktitle=. Locating and Editing Factual Associations in
-
[14]
Representation Engineering: A Top-Down Approach to
Zou, Andy and Phan, Long and Chen, Sarah and others , journal=. Representation Engineering: A Top-Down Approach to
-
[15]
2025 , howpublished =
Aranguri, Santiago , title =. 2025 , howpublished =
2025
-
[16]
OpenAI Blog , year=
Language Models Can Explain Neurons in Language Models , author=. OpenAI Blog , year=
-
[17]
Penedo, Guilherme and Kydl. The. Advances in Neural Information Processing Systems , year =
-
[18]
2026 , eprint=
Delta-Crosscoder: Robust Crosscoder Model Diffing in Narrow Fine-Tuning Regimes , author=. 2026 , eprint=
2026
-
[19]
Knowledge Boundary of Large Language Models: A Survey
Li, Moxin and Zhao, Yong and Zhang, Wenxuan and Li, Shuaiyi and Xie, Wenya and Ng, See-Kiong and Chua, Tat-Seng and Deng, Yang. Knowledge Boundary of Large Language Models: A Survey. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.256
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.