Erase-then-Delta Attention: Decoupling Erase and Write Addresses in Delta-Rule Linear Attention
Pith reviewed 2026-06-26 05:27 UTC · model grok-4.3
The pith
Decoupling erase and write addresses lets delta-rule linear attention actively remove stale memory before writing new content.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that recurrent memory models benefit when the erase address is chosen independently of the write address: EDA first applies a targeted erase along a learned direction, then performs the usual delta-style correction at the write address, thereby keeping the corrective behavior intact while adding an explicit cleanup path that is most active when passive decay is weak.
What carries the argument
Erase-then-Delta Attention (EDA) update rule that performs a learned-direction erase step before the standard delta-rule corrective write.
If this is right
- EDA achieves the lowest perplexity in both dense 2.5B and MoE 25B-A2.8B pretraining.
- The advantage remains after 80B-token long-context midtraining of the MoE models.
- EDA records the best results on long-context benchmarks spanning 4k to 128k contexts.
- Memory-state probes indicate the extra erase path is used most when passive decay is weak while the delta correction stays unchanged.
Where Pith is reading between the lines
- The same decoupling idea could be tested in other recurrent state-space or linear-attention variants that currently rely only on decay or overwriting.
- Explicit erase directions might reduce reliance on learned decay rates or attention sinks in long-context settings.
- If the erase direction can be made input-dependent at inference time, the method could support on-the-fly memory editing without retraining.
Load-bearing premise
A learned erase direction can be trained to target stale memory at an address independent of the write address without interfering with the delta-rule corrective update or introducing training instability.
What would settle it
If side-by-side pretraining runs of identical 2.5B or 25B models show that EDA does not reduce validation perplexity relative to standard delta-rule attention after the same token budget, the performance claim would be falsified.
Figures
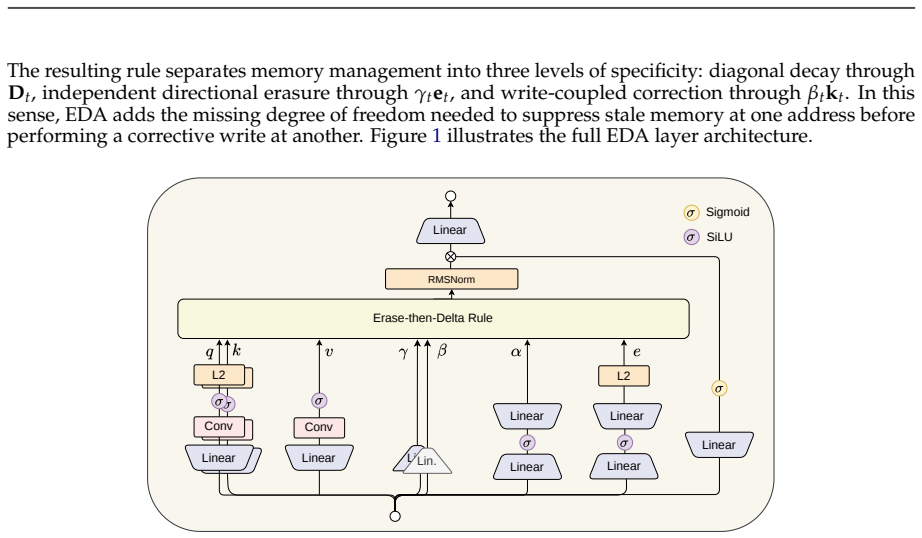
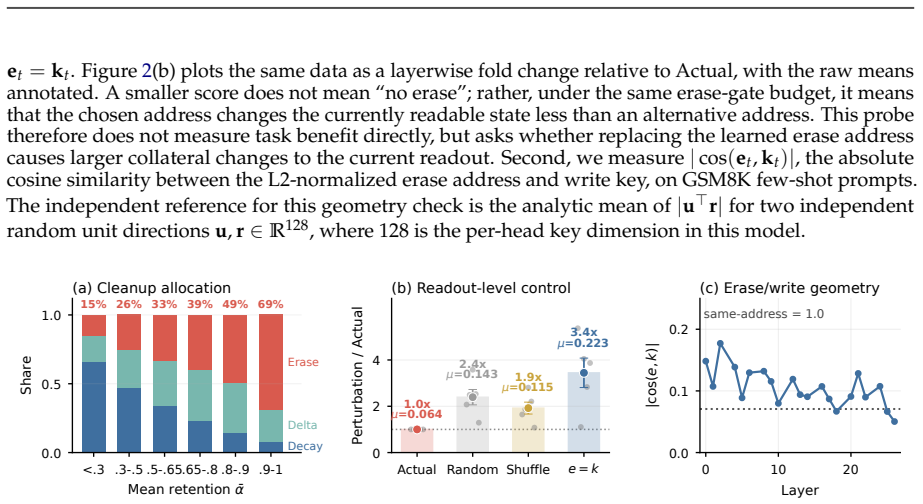
read the original abstract
Delta-rule linear attention improves recurrent memory updates by correcting what is already stored at the current write address before writing new content. However, the active correction is still anchored to that same write address. As a result, stale information stored at a different address cannot be actively removed before new content is written elsewhere. We propose Erase-then-Delta Attention (EDA), a memory update rule that decouples where to erase from where to write. The key insight is that recurrent memory models should not only correct the current write, but also selectively suppress outdated memory at an independently chosen address. Concretely, our method first applies a targeted erase step along a learned erase direction, and then performs the standard delta-style corrective write along the current write direction. This preserves the corrective behavior of delta-rule updates while expanding their memory-management capacity. Language-model pretraining experiments across dense 2.5B and MoE 25B-A2.8B model families show that EDA performs best in both settings. The gain persists after 80B-token long-context midtraining of the MoE models, where EDA also performs best in long-context evaluations from 4k to 128k contexts. A compact update analysis and memory-state probes suggest why: EDA keeps the delta-rule corrective write intact while allocating an additional cleanup path most strongly when passive decay is weak. These results suggest that recurrent memory models should decide not only what to write, but also what stale information to erase and where.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Erase-then-Delta Attention (EDA), a memory update rule for delta-rule linear attention that first applies a targeted erase along a learned erase direction before performing the standard delta-style corrective write. This is intended to decouple erase and write addresses so that stale information at an independent address can be suppressed. Pretraining experiments on dense 2.5B and MoE 25B-A2.8B models report that EDA performs best in both settings; the advantage persists after 80B-token long-context midtraining, where EDA also leads on evaluations from 4k to 128k contexts. A compact update analysis and memory-state probes are offered to explain the behavior.
Significance. If the decoupling holds without destabilizing the delta-rule correction, the method would expand the memory-management capacity of recurrent linear attention beyond address-tied correction. The cross-scale experiments (2.5B dense and 25B MoE) and persistence through long-context midtraining constitute concrete empirical support; the memory-state probes add mechanistic insight. These elements would be strengths if the independence of the learned erase direction is rigorously verified.
major comments (2)
- [Abstract] Abstract and update-analysis paragraph: the claim that the delta-rule corrective write 'remains intact' rests on a high-level analysis that does not quantify correlation between the jointly learned erase vector and the write vector, nor bound potential interference with the corrective update; this is load-bearing for the decoupling assertion.
- [Experiments] Experiments section (performance claims): no quantitative effect sizes, ablation isolating the erase-direction contribution, or controls for training instability are reported in the abstract, and the full text must supply these to substantiate that observed gains arise from address decoupling rather than other unablated factors.
minor comments (1)
- [Method] Notation for the learned erase direction should be introduced with an explicit equation and distinguished from the write direction to avoid ambiguity in the update rule.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. We address the two major comments point by point below, offering clarifications from the manuscript and committing to targeted revisions that strengthen the evidence for decoupling without overstating current results.
read point-by-point responses
-
Referee: [Abstract] Abstract and update-analysis paragraph: the claim that the delta-rule corrective write 'remains intact' rests on a high-level analysis that does not quantify correlation between the jointly learned erase vector and the write vector, nor bound potential interference with the corrective update; this is load-bearing for the decoupling assertion.
Authors: We agree that the current update analysis is high-level and that explicit quantification would make the independence claim more rigorous. The manuscript's compact analysis shows the erase step acts along a learned direction prior to the write, and the memory-state probes indicate differential cleanup behavior when passive decay is weak. To directly address the concern, we will add measurements of the correlation between the jointly learned erase and write vectors plus a bound on interference in the revised version. revision: yes
-
Referee: [Experiments] Experiments section (performance claims): no quantitative effect sizes, ablation isolating the erase-direction contribution, or controls for training instability are reported in the abstract, and the full text must supply these to substantiate that observed gains arise from address decoupling rather than other unablated factors.
Authors: The full manuscript already reports consistent gains on 2.5B dense and 25B MoE models that persist after long-context midtraining. We acknowledge, however, that explicit effect sizes, an ablation isolating the erase direction, and training-stability controls are needed to rule out confounding factors. In revision we will insert quantitative effect sizes (e.g., perplexity deltas), a dedicated ablation on the erase-direction term, and stability metrics across runs. revision: yes
Circularity Check
No circularity; empirical method tested independently of inputs
full rationale
The paper introduces Erase-then-Delta Attention as a novel decoupling of erase and write addresses in delta-rule linear attention, then validates it via pretraining experiments on 2.5B dense and 25B-A2.8B MoE models plus long-context midtraining. No equations, fitted parameters, or self-citations are shown that reduce the performance claims or the update analysis to a definition or prior result by construction. The compact update analysis is presented as supporting evidence rather than a load-bearing derivation that collapses into the method definition itself. The chain remains self-contained through external empirical benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- learned erase direction
axioms (1)
- domain assumption Delta-rule linear attention remains stable and corrective when an independent erase operation is inserted before the write step.
invented entities (1)
-
erase direction
no independent evidence
Reference graph
Works this paper leans on
-
[1]
The Thirteenth International Conference on Learning Representations , year=
Gated Delta Networks: Improving Mamba2 with Delta Rule , author=. The Thirteenth International Conference on Learning Representations , year=
-
[2]
2025 , eprint=
Kimi Linear: An Expressive, Efficient Attention Architecture , author=. 2025 , eprint=
2025
-
[3]
2026 , eprint=
Gated DeltaNet-2: Decoupling Erase and Write in Linear Attention , author=. 2026 , eprint=
2026
-
[4]
DeltaProduct: Improving State-Tracking in Linear
Julien Siems and Timur Carstensen and Arber Zela and Frank Hutter and Massimiliano Pontil and Riccardo Grazzi , booktitle=. DeltaProduct: Improving State-Tracking in Linear. 2026 , url=
2026
-
[5]
Improving Bilinear
Jiaxi Hu and Yongqi Pan and Jusen Du and Disen Lan and Xiaqiang Tang and Qingsong Wen and Yuxuan Liang and Weigao Sun , booktitle=. Improving Bilinear. 2026 , url=
2026
-
[6]
Neural Information Processing Systems , year=
Attention is All you Need , author=. Neural Information Processing Systems , year=
-
[7]
International Conference on Machine Learning , year=
Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention , author=. International Conference on Machine Learning , year=
-
[8]
International Conference on Learning Representations , year=
Efficiently Modeling Long Sequences with Structured State Spaces , author=. International Conference on Learning Representations , year=
-
[9]
First Conference on Language Modeling , year=
Mamba: Linear-Time Sequence Modeling with Selective State Spaces , author=. First Conference on Language Modeling , year=
-
[10]
ArXiv , year=
Linformer: Self-Attention with Linear Complexity , author=. ArXiv , year=
-
[11]
ArXiv , year=
Retentive Network: A Successor to Transformer for Large Language Models , author=. ArXiv , year=
-
[12]
Forty-first International Conference on Machine Learning , year=
Gated Linear Attention Transformers with Hardware-Efficient Training , author=. Forty-first International Conference on Machine Learning , year=
-
[13]
Transformers are
Tri Dao and Albert Gu , booktitle=. Transformers are. 2024 , url=
2024
-
[14]
Maximilian Beck and Korbinian P. x. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[15]
International Conference on Machine Learning , year=
Linear Transformers Are Secretly Fast Weight Programmers , author=. International Conference on Machine Learning , year=
-
[16]
2025 , eprint=
RWKV-7 "Goose" with Expressive Dynamic State Evolution , author=. 2025 , eprint=
2025
-
[17]
HiPPO: Recurrent Memory with Optimal Polynomial Projections , url =
Gu, Albert and Dao, Tri and Ermon, Stefano and Rudra, Atri and R\'. HiPPO: Recurrent Memory with Optimal Polynomial Projections , url =. Advances in Neural Information Processing Systems , editor =
-
[18]
Songlin Yang and Yikang Shen and Kaiyue Wen and Shawn Tan and Mayank Mishra and Liliang Ren and Rameswar Panda and Yoon Kim , booktitle=. Pa. 2025 , url=
2025
-
[19]
2024 , eprint=
Jamba: A Hybrid Transformer-Mamba Language Model , author=. 2024 , eprint=
2024
-
[20]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Jet-Nemotron: Efficient Language Model with Post Neural Architecture Search , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[21]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[22]
Learning to (Learn at Test Time):
Yu Sun and Xinhao Li and Karan Dalal and Jiarui Xu and Arjun Vikram and Genghan Zhang and Yann Dubois and Xinlei Chen and Xiaolong Wang and Sanmi Koyejo and Tatsunori Hashimoto and Carlos Guestrin , booktitle=. Learning to (Learn at Test Time):. 2025 , url=
2025
-
[23]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Titans: Learning to Memorize at Test Time , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[24]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Parallelizing Linear Transformers with the Delta Rule over Sequence Length , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[25]
FLA: A Triton-Based Library for Hardware-Efficient Implementations of Linear Attention Mechanism , author =
-
[26]
ArXiv , year=
Measuring Massive Multitask Language Understanding , author=. ArXiv , year=
-
[27]
2024 , url=
Yubo Wang and Xueguang Ma and Ge Zhang and Yuansheng Ni and Abhranil Chandra and Shiguang Guo and Weiming Ren and Aaran Arulraj and Xuan He and Ziyan Jiang and Tianle Li and Max Ku and Kai Wang and Alex Zhuang and Rongqi Fan and Xiang Yue and Wenhu Chen , booktitle=. 2024 , url=
2024
-
[28]
ArXiv , year=
Training Verifiers to Solve Math Word Problems , author=. ArXiv , year=
-
[29]
Measuring Mathematical Problem Solving With the
Dan Hendrycks and Collin Burns and Saurav Kadavath and Akul Arora and Steven Basart and Eric Tang and Dawn Song and Jacob Steinhardt , booktitle=. Measuring Mathematical Problem Solving With the. 2021 , url=
2021
-
[30]
Challenging BIG - Bench Tasks and Whether Chain -of- Thought Can Solve Them
Suzgun, Mirac and Scales, Nathan and Sch. Challenging BIG -Bench Tasks and Whether Chain-of-Thought Can Solve Them. Findings of the Association for Computational Linguistics: ACL 2023. 2023. doi:10.18653/v1/2023.findings-acl.824
-
[31]
Is Your Code Generated by Chat
Jiawei Liu and Chunqiu Steven Xia and Yuyao Wang and Lingming Zhang , booktitle=. Is Your Code Generated by Chat. 2023 , url=
2023
-
[32]
2024 , url=
Cheng-Ping Hsieh and Simeng Sun and Samuel Kriman and Shantanu Acharya and Dima Rekesh and Fei Jia and Boris Ginsburg , booktitle=. 2024 , url=
2024
-
[33]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Free , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.