Discovering Millions of Interpretable Features with Sparse Autoencoders
Pith reviewed 2026-06-26 05:32 UTC · model grok-4.3
The pith
Sparse autoencoders trained on Qwen3 models extract features that causally steer those models toward refusal behavior.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
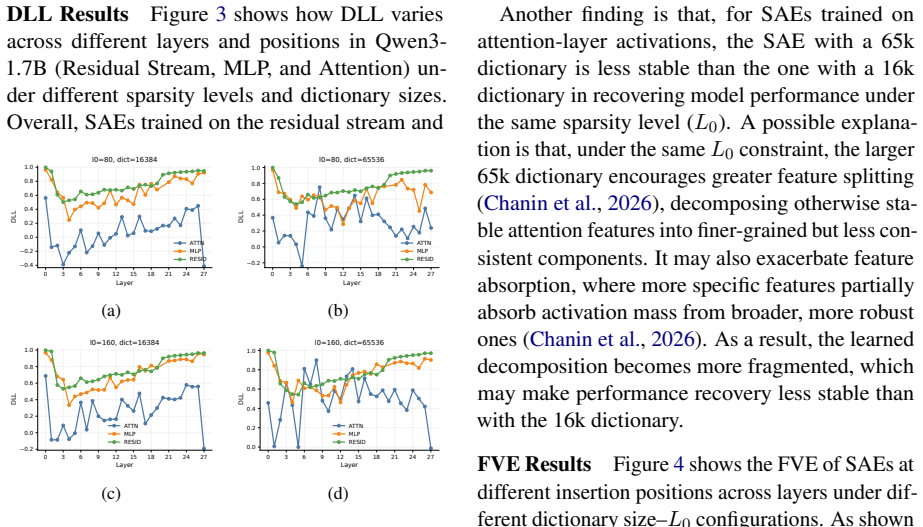
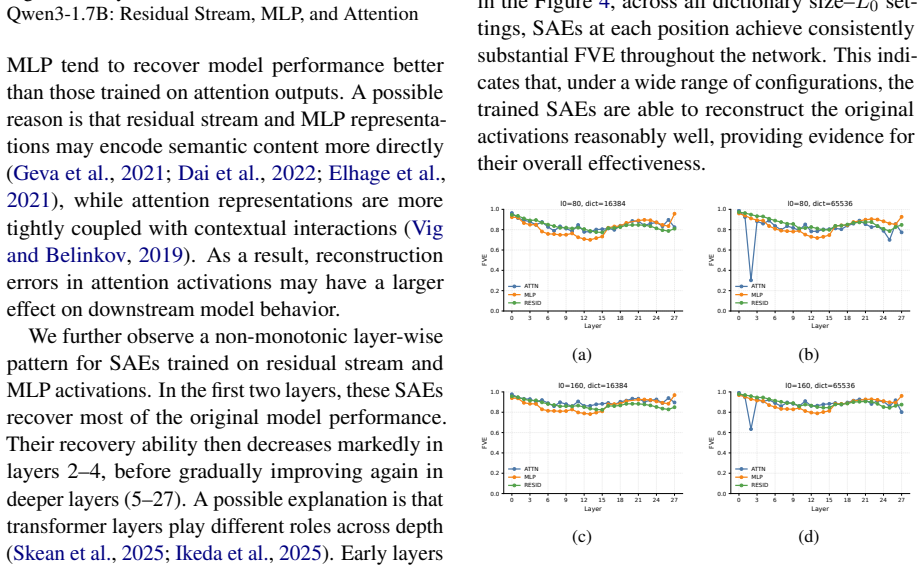
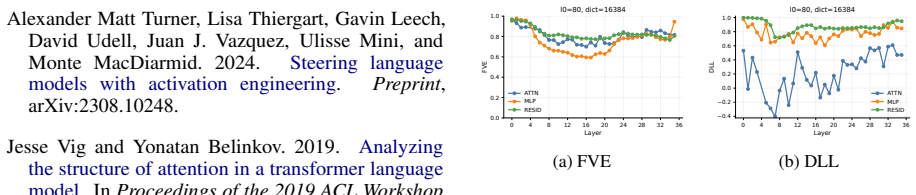
We introduce the Qwen3-Instruct SAE suite covering three model sizes, with layer-wise training at multiple activation sites for the smaller models and a subset of residual layers for the largest. Evaluation across reconstruction and recovery metrics reveals distinct sparsity-fidelity trade-offs. In the refusal-steering case study, selected SAE features are shown to causally steer the instruction-tuned Qwen3 models toward refusal behavior.
What carries the argument
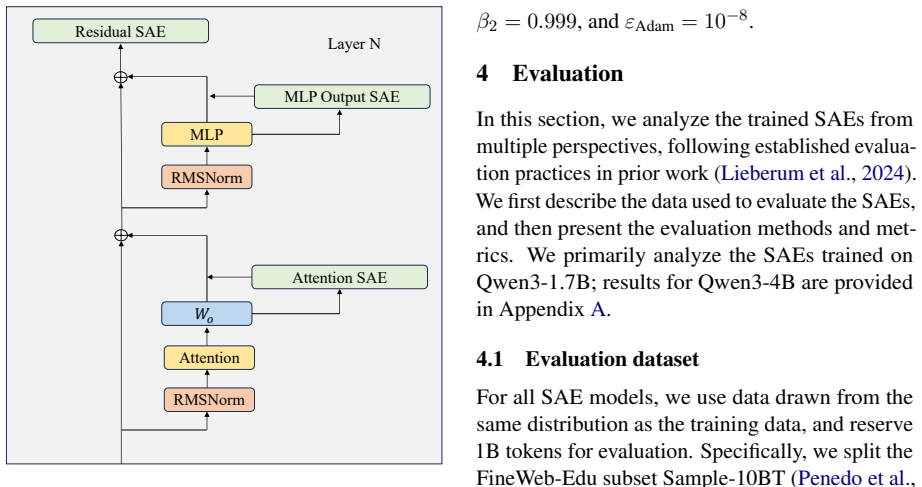
Sparse autoencoders that decompose superposed language-model activations into sparse, interpretable features, applied layer-wise to residual streams, MLP outputs, and attention outputs of Qwen3 models.
If this is right
- Model-level recovery metrics provide a practical way to judge SAE quality beyond pure activation reconstruction.
- Feature-level activation enables targeted behavioral interventions on instruction-tuned models without full retraining.
- The observed sparsity-fidelity trade-offs across layers and components guide where future SAEs should be placed for highest utility.
Where Pith is reading between the lines
- The same training and selection pipeline could be applied to steer other behaviors such as truth-telling or topic avoidance.
- Releasing the full suite lowers the barrier for independent researchers to test whether the same features appear across different model families.
- If the causal features generalize across prompt variations, they could serve as stable handles for auditing refusal circuits at scale.
Load-bearing premise
The selected features identified in the refusal case study are causally responsible for the observed steering rather than merely correlated with other effects introduced by inserting or activating the autoencoder.
What would settle it
An experiment in which the identified features are ablated or replaced with random features while the rest of the SAE remains active, and refusal rates return to baseline, would falsify the causal claim.
Figures






read the original abstract
Sparse autoencoders (SAEs) have emerged as a powerful tool for decomposing superposed language model representations into sparse and interpretable features. However, training SAEs is computationally expensive, and available open-source SAE models remain limited. In this work, we introduce \textbf{Qwen3-Instruct SAE}, a comprehensive suite of SAEs trained on the Qwen3 instruction-tuned model family, covering Qwen3-1.7B, Qwen3-4B, and Qwen3-8B. For Qwen3-1.7B and Qwen3-4B, we train layer-wise SAEs at three key activation sites: residual streams, MLP outputs, and attention outputs. For Qwen3-8B, we train SAEs on a subset of residual stream layers. We systematically evaluate these SAEs using both activation-level reconstruction metrics and model-level recovery metrics, revealing distinct sparsity--fidelity trade-offs across layers and components. Finally, we demonstrate the utility of Qwen3-Instruct SAE through a refusal-steering case study, showing that selected SAE features can causally steer instruction-tuned Qwen3 models toward refusal behavior. Our release provides a practical resource for studying sparse representations, feature-level mechanisms, and behavioral interventions in instruction-tuned language models
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Qwen3-Instruct SAE suite of sparse autoencoders trained on the Qwen3-1.7B, Qwen3-4B, and Qwen3-8B instruction-tuned models. Layer-wise SAEs are trained at residual stream, MLP output, and attention output sites (with a subset for the 8B model). The work evaluates the SAEs via activation-level reconstruction metrics and model-level recovery metrics, identifies sparsity-fidelity trade-offs, and presents a refusal-steering case study claiming that selected SAE features can causally steer the models toward refusal behavior.
Significance. If the quantitative evaluations and causal attribution hold, the release of these SAEs for popular open instruction-tuned models would provide a substantial public resource for mechanistic interpretability, enabling scaled studies of sparse features and feature-level behavioral interventions. The systematic coverage across model sizes and activation sites is a positive aspect of the resource contribution.
major comments (2)
- [Abstract] Abstract: The central claim that 'selected SAE features can causally steer instruction-tuned Qwen3 models toward refusal behavior' is load-bearing for the utility demonstration, yet the abstract provides no quantitative results, error bars, or controls. This prevents assessment of whether the observed behavioral shift is attributable to the specific features.
- [Refusal-steering case study] Refusal-steering case study: The causal attribution requires isolation from confounds such as SAE reconstruction error at the insertion site, the act of replacing activations, or non-specific activation statistics changes. No indication is given of the necessary controls (random-feature baselines, SAE-bypass runs, or matched-magnitude interventions), which directly undermines the strongest claim.
minor comments (1)
- [Abstract] Abstract: Key numerical results from the reconstruction/recovery metrics and the steering case study (e.g., effect sizes or success rates) should be included to allow readers to gauge the strength of the reported findings without needing the full text.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and for recognizing the value of the released SAE suite. We agree that the abstract and case study require additional quantitative detail and controls to support the causal claims, and we will revise accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'selected SAE features can causally steer instruction-tuned Qwen3 models toward refusal behavior' is load-bearing for the utility demonstration, yet the abstract provides no quantitative results, error bars, or controls. This prevents assessment of whether the observed behavioral shift is attributable to the specific features.
Authors: We agree that the abstract should include quantitative support. In the revision we will add the key refusal-rate change (with error bars) and a concise reference to the controls performed in the case study. revision: yes
-
Referee: [Refusal-steering case study] Refusal-steering case study: The causal attribution requires isolation from confounds such as SAE reconstruction error at the insertion site, the act of replacing activations, or non-specific activation statistics changes. No indication is given of the necessary controls (random-feature baselines, SAE-bypass runs, or matched-magnitude interventions), which directly undermines the strongest claim.
Authors: The referee correctly identifies that stronger isolation from confounds is needed. We will add random-feature baselines, SAE-bypass runs, and matched-magnitude interventions to the revised case study (main text or appendix) to better support causal attribution. revision: yes
Circularity Check
No derivation chain present; empirical resource release with case study
full rationale
The paper describes training and releasing SAEs on Qwen3 models, evaluating them with activation-level reconstruction and model-level recovery metrics, and demonstrating utility via a refusal-steering case study. No equations, first-principles derivations, or closed-form predictions are claimed anywhere in the provided text. The work is self-contained as an empirical contribution and does not reduce any result to fitted inputs or self-citations by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[2]
Andy Arditi, Oscar Obeso, Aaquib Syed, Daniel Paleka, Nina Panickssery, Wes Gurnee, and Neel Nanda. 2024. https://arxiv.org/abs/2406.11717 Refusal in language models is mediated by a single direction . Preprint, arXiv:2406.11717
Pith/arXiv arXiv 2024
-
[3]
Samaksh Bhargav and Zining Zhu. 2025. https://openreview.net/forum?id=Yz1gZJFRvT Feature-guided SAE steering for refusal-rate control using contrasting prompts . In Mechanistic Interpretability Workshop at NeurIPS 2025
2025
-
[4]
Bart Bussmann, Patrick Leask, and Neel Nanda. 2024. https://openreview.net/forum?id=d4dpOCqybL Batchtopk sparse autoencoders . In NeurIPS 2024 Workshop on Scientific Methods for Understanding Deep Learning
2024
-
[5]
Bart Bussmann, Noa Nabeshima, Adam Karvonen, and Neel Nanda. 2025. https://openreview.net/forum?id=m25T5rAy43 Learning multi-level features with matryoshka sparse autoencoders . In Forty-second International Conference on Machine Learning
2025
-
[6]
David Chanin and Adrià Garriga-Alonso. 2026. https://arxiv.org/abs/2602.14687 Synthsaebench: Evaluating sparse autoencoders on scalable realistic synthetic data . Preprint, arXiv:2602.14687
arXiv 2026
-
[7]
David Chanin, James Wilken-Smith, Tom \'a s Dulka, Hardik Bhatnagar, Satvik Golechha, and Joseph Isaac Bloom. 2026. https://openreview.net/forum?id=R73ybUciQF A is for absorption: Studying feature splitting and absorption in sparse autoencoders . In The Thirty-ninth Annual Conference on Neural Information Processing Systems
2026
-
[8]
Zhongtian Chen, Edmund Lau, Jake Mendel, Susan Wei, and Daniel Murfet. 2023. https://arxiv.org/abs/2310.06301 Dynamical versus bayesian phase transitions in a toy model of superposition . Preprint, arXiv:2310.06301
arXiv 2023
-
[9]
Mavor-Parker, Aengus Lynch, Stefan Heimersheim, and Adri \`a Garriga-Alonso
Arthur Conmy, Augustine N. Mavor-Parker, Aengus Lynch, Stefan Heimersheim, and Adri \`a Garriga-Alonso. 2023. https://openreview.net/forum?id=89ia77nZ8u Towards automated circuit discovery for mechanistic interpretability . In Thirty-seventh Conference on Neural Information Processing Systems
2023
-
[11]
Boyi Deng, Xu Wang, Yaoning Wang, Yu Wan, Yubo Ma, Baosong Yang, Haoran Wei, Jialong Tang, Huan Lin, Ruize Gao, Tianhao Li, Qian Cao, Xuancheng Ren, Xiaodong Deng, An Yang, Fei Huang, Dayiheng Liu, and Jingren Zhou. 2026. https://arxiv.org/abs/2605.11887 Qwen-scope: Turning sparse features into development tools for large language models . Preprint, arXiv...
Pith/arXiv arXiv 2026
-
[12]
Nelson Elhage, Tristan Hume, Catherine Olsson, Nicholas Schiefer, Tom Henighan, Shauna Kravec, Zac Hatfield-Dodds, Robert Lasenby, Dawn Drain, Carol Chen, Roger Grosse, Sam McCandlish, Jared Kaplan, Dario Amodei, Martin Wattenberg, and Christopher Olah. 2022. Toy models of superposition. Transformer Circuits Thread. Https://transformer-circuits.pub/2022/t...
2022
-
[13]
Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Nova DasSarma, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, and 6 others. 2021. A mathematical framework for transformer circuits. Transformer C...
2021
-
[14]
Siqi Fan, Xin Jiang, Xiang Li, Xuying Meng, Peng Han, Shuo Shang, Aixin Sun, Yequan Wang, and Zhongyuan Wang. 2024. https://arxiv.org/abs/2403.02181 Not all layers of llms are necessary during inference . Preprint, arXiv:2403.02181
arXiv 2024
-
[15]
Yi Fang, Wenjie Wang, Mingfeng Xue, Boyi Deng, Fengli Xu, Dayiheng Liu, and Fuli Feng. 2026. https://arxiv.org/abs/2601.03595 Controllable llm reasoning via sparse autoencoder-based steering . Preprint, arXiv:2601.03595
arXiv 2026
-
[16]
Leo Gao, Tom Dupre la Tour, Henk Tillman, Gabriel Goh, Rajan Troll, Alec Radford, Ilya Sutskever, Jan Leike, and Jeffrey Wu. 2025. https://openreview.net/forum?id=tcsZt9ZNKD Scaling and evaluating sparse autoencoders . In The Thirteenth International Conference on Learning Representations
2025
-
[19]
Wes Gurnee, Neel Nanda, Matthew Pauly, Katherine Harvey, Dmitrii Troitskii, and Dimitris Bertsimas. 2023. https://openreview.net/forum?id=JYs1R9IMJr Finding neurons in a haystack: Case studies with sparse probing . Transactions on Machine Learning Research
2023
-
[20]
Wes Gurnee and Max Tegmark. 2024. https://openreview.net/forum?id=jE8xbmvFin Language models represent space and time . In The Twelfth International Conference on Learning Representations
2024
-
[21]
Seungju Han, Kavel Rao, Allyson Ettinger, Liwei Jiang, Bill Yuchen Lin, Nathan Lambert, Yejin Choi, and Nouha Dziri. 2024. https://openreview.net/forum?id=Ich4tv4202 Wildguard: Open one-stop moderation tools for safety risks, jailbreaks, and refusals of LLM s . In The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track
2024
-
[22]
Zhengfu He, Wentao Shu, Xuyang Ge, Lingjie Chen, Junxuan Wang, Yunhua Zhou, Frances Liu, Qipeng Guo, Xuanjing Huang, Zuxuan Wu, Yu-Gang Jiang, and Xipeng Qiu. 2024. https://arxiv.org/abs/2410.20526 Llama scope: Extracting millions of features from llama-3.1-8b with sparse autoencoders . Preprint, arXiv:2410.20526
arXiv 2024
-
[24]
Robert Huben, Hoagy Cunningham, Logan Riggs Smith, Aidan Ewart, and Lee Sharkey. 2024. https://openreview.net/forum?id=F76bwRSLeK Sparse autoencoders find highly interpretable features in language models . In The Twelfth International Conference on Learning Representations
2024
-
[25]
Kaarel Hänni, Jake Mendel, Dmitry Vaintrob, and Lawrence Chan. 2024. https://arxiv.org/abs/2408.05451 Mathematical models of computation in superposition . Preprint, arXiv:2408.05451
arXiv 2024
-
[26]
Wataru Ikeda, Kazuki Yano, Ryosuke Takahashi, Jaesung Lee, Keigo Shibata, and Jun Suzuki. 2025. https://arxiv.org/abs/2508.17734 Layerwise importance analysis of feed-forward networks in transformer-based language models . Preprint, arXiv:2508.17734
arXiv 2025
-
[27]
Mingyu Jin, Qinkai Yu, Jingyuan Huang, Qingcheng Zeng, Zhenting Wang, Wenyue Hua, Haiyan Zhao, Kai Mei, Yanda Meng, Kaize Ding, Fan Yang, Mengnan Du, and Yongfeng Zhang. 2025. https://aclanthology.org/2025.coling-main.37/ Exploring concept depth: How large language models acquire knowledge and concept at different layers? In Proceedings of the 31st Intern...
2025
-
[28]
Adam Karvonen, Can Rager, Johnny Lin, Curt Tigges, Joseph Isaac Bloom, David Chanin, Yeu-Tong Lau, Eoin Farrell, Callum Stuart McDougall, Kola Ayonrinde, Demian Till, Matthew Wearden, Arthur Conmy, Samuel Marks, and Neel Nanda. 2025. https://openreview.net/forum?id=qrU3yNfX0d SAEB ench: A comprehensive benchmark for sparse autoencoders in language model i...
2025
-
[29]
Simon Lermen, Charlie Rogers-Smith, and Jeffrey Ladish. 2024. https://arxiv.org/abs/2310.20624 Lora fine-tuning efficiently undoes safety training in llama 2-chat 70b . Preprint, arXiv:2310.20624
arXiv 2024
-
[30]
Shen Li, Liuyi Yao, Lan Zhang, and Yaliang Li. 2025. https://openreview.net/forum?id=kUH1yPMAn7 Safety layers in aligned large language models: The key to LLM security . In The Thirteenth International Conference on Learning Representations
2025
-
[32]
Xiaogeng Liu, Nan Xu, Muhao Chen, and Chaowei Xiao. 2024. https://openreview.net/forum?id=7Jwpw4qKkb Auto DAN : Generating stealthy jailbreak prompts on aligned large language models . In The Twelfth International Conference on Learning Representations
2024
-
[33]
Samuel Marks, Can Rager, Eric J Michaud, Yonatan Belinkov, David Bau, and Aaron Mueller. 2025. https://openreview.net/forum?id=I4e82CIDxv Sparse feature circuits: Discovering and editing interpretable causal graphs in language models . In The Thirteenth International Conference on Learning Representations
2025
-
[34]
Samuel Marks and Max Tegmark. 2024. https://openreview.net/forum?id=aajyHYjjsk The geometry of truth: Emergent linear structure in large language model representations of true/false datasets . In First Conference on Language Modeling
2024
-
[35]
Mantas Mazeika, Long Phan, Xuwang Yin, Andy Zou, Zifan Wang, Norman Mu, Elham Sakhaee, Nathaniel Li, Steven Basart, Bo Li, David Forsyth, and Dan Hendrycks. 2024. https://arxiv.org/abs/2402.04249 Harmbench: A standardized evaluation framework for automated red teaming and robust refusal . Preprint, arXiv:2402.04249
Pith/arXiv arXiv 2024
-
[36]
Mantas Mazeika, Andy Zou, Norman Mu, Long Phan, Zifan Wang, Chunru Yu, Adam Khoja, Fengqing Jiang, Aidan O'Gara, Ellie Sakhaee, Zhen Xiang, Arezoo Rajabi, Dan Hendrycks, Radha Poovendran, Bo Li, and David Forsyth. 2023. Tdc 2023 (llm edition): The trojan detection challenge. In NeurIPS Competition Track
2023
-
[37]
Tom \' a s Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. 2013. http://arxiv.org/abs/1301.3781 Efficient estimation of word representations in vector space . In 1st International Conference on Learning Representations, ICLR 2013, Scottsdale, Arizona, USA, May 2-4, 2013, Workshop Track Proceedings
Pith/arXiv arXiv 2013
-
[38]
Edgar, Blake Bullwinkel, Jingya Chen, Harsha Nori, Dean Carignan, Eric Horvitz, and Forough Poursabzi-Sangdeh
Kyle O'Brien, David Majercak, Xavier Fernandes, Richard G. Edgar, Blake Bullwinkel, Jingya Chen, Harsha Nori, Dean Carignan, Eric Horvitz, and Forough Poursabzi-Sangdeh. 2025. https://openreview.net/forum?id=PMK1jdGQoc Steering language model refusal with sparse autoencoders . In ICML 2025 Workshop on Reliable and Responsible Foundation Models
2025
-
[39]
Roma Patel and Ellie Pavlick. 2022. https://openreview.net/forum?id=gJcEM8sxHK Mapping language models to grounded conceptual spaces . In International Conference on Learning Representations
2022
-
[40]
Guilherme Penedo, Hynek Kydl \' c ek, Loubna Ben allal, Anton Lozhkov, Margaret Mitchell, Colin Raffel, Leandro Von Werra, and Thomas Wolf. 2024. https://openreview.net/forum?id=n6SCkn2QaG The fineweb datasets: Decanting the web for the finest text data at scale . In The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchma...
2024
-
[41]
Senthooran Rajamanoharan, Arthur Conmy, Lewis Smith, Tom Lieberum, Vikrant Varma, Janos Kramar, Rohin Shah, and Neel Nanda. 2024. https://openreview.net/forum?id=zLBlin2zvW Improving sparse decomposition of language model activations with gated sparse autoencoders . In The Thirty-eighth Annual Conference on Neural Information Processing Systems
2024
-
[42]
Senthooran Rajamanoharan, Tom Lieberum, Nicolas Sonnerat, Arthur Conmy, Vikrant Varma, Janos Kramar, and Neel Nanda. 2025. https://openreview.net/forum?id=mMPaQzgzAN Jumping ahead: Improving reconstruction fidelity with jumpre LU sparse autoencoders
2025
-
[43]
Alexander Robey, Eric Wong, Hamed Hassani, and George J. Pappas. 2024. https://arxiv.org/abs/2310.03684 Smoothllm: Defending large language models against jailbreaking attacks . Preprint, arXiv:2310.03684
Pith/arXiv arXiv 2024
-
[45]
Ning Shang, Yifei Liu, Yi Zhu, Li Lyna Zhang, Weijiang Xu, Xinyu Guan, Buze Zhang, Bingcheng Dong, Xudong Zhou, Bowen Zhang, Ying Xin, Ziming Miao, Scarlett Li, Fan Yang, and Mao Yang. 2025. https://arxiv.org/abs/2508.20722 rstar2-agent: Agentic reasoning technical report . Preprint, arXiv:2508.20722
arXiv 2025
-
[46]
Oscar Skean, Md Rifat Arefin, Dan Zhao, Niket Nikul Patel, Jalal Naghiyev, Yann LeCun, and Ravid Shwartz-Ziv. 2025. https://openreview.net/forum?id=WGXb7UdvTX Layer by layer: Uncovering hidden representations in language models . In Forty-second International Conference on Machine Learning
2025
-
[48]
Hashimoto
Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. 2023. Stanford alpaca: An instruction-following llama model. https://github.com/tatsu-lab/stanford_alpaca
2023
-
[49]
Daniel Freeman, Theodore R
Adly Templeton, Tom Conerly, Jonathan Marcus, Jack Lindsey, Trenton Bricken, Brian Chen, Adam Pearce, Craig Citro, Emmanuel Ameisen, Andy Jones, Hoagy Cunningham, Nicholas L Turner, Callum McDougall, Monte MacDiarmid, C. Daniel Freeman, Theodore R. Sumers, Edward Rees, Joshua Batson, Adam Jermyn, and 3 others. 2024. https://transformer-circuits.pub/2024/s...
2024
-
[50]
Vazquez, Ulisse Mini, and Monte MacDiarmid
Alexander Matt Turner, Lisa Thiergart, Gavin Leech, David Udell, Juan J. Vazquez, Ulisse Mini, and Monte MacDiarmid. 2024. https://arxiv.org/abs/2308.10248 Steering language models with activation engineering . Preprint, arXiv:2308.10248
Pith/arXiv arXiv 2024
-
[52]
Zhengxuan Wu, Aryaman Arora, Atticus Geiger, Zheng Wang, Jing Huang, Dan Jurafsky, Christopher D Manning, and Christopher Potts. 2025. https://openreview.net/forum?id=K2CckZjNy0 Axbench: Steering LLM s? even simple baselines outperform sparse autoencoders . In Forty-second International Conference on Machine Learning
2025
-
[53]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, and 41 others. 2025. https://arxiv.org/abs/2505.09388 Qwen3 technical report . Preprint, arXiv:2505.09388
Pith/arXiv arXiv 2025
-
[55]
Fred Zhang and Neel Nanda. 2024. https://arxiv.org/abs/2309.16042 Towards best practices of activation patching in language models: Metrics and methods . Preprint, arXiv:2309.16042
Pith/arXiv arXiv 2024
-
[56]
Zico Kolter, and Matt Fredrikson
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J. Zico Kolter, and Matt Fredrikson. 2023. https://arxiv.org/abs/2307.15043 Universal and transferable adversarial attacks on aligned language models . Preprint, arXiv:2307.15043
Pith/arXiv arXiv 2023
-
[57]
Guo, Daya and Yang, Dejian and Zhang, Haowei and Song, Junxiao and Wang, Peiyi and Zhu, Qihao åand Xu, Runxin and Zhang, Ruoyu and Ma, Shirong and Bi, Xiao and Zhang, Xiaokang and Yu, Xingkai and Wu, Yu and Wu, Z. F. and Gou, Zhibin and Shao, Zhihong and Li, Zhuoshu and Gao, Ziyi and Liu, Aixin and Xue, Bing and Wang, Bingxuan and Wu, Bochao and Feng, Bei...
-
[58]
Marco-o1 v2: Towards Widening The Distillation Bottleneck for Reasoning Models
Yin, Huifeng and Zhao, Yu and Wu, Minghao and Ni, Xuanfan and Zeng, Bo and Wang, Hao and Shi, Tianqi and Shao, Liangying and Lyu, Chenyang and Wang, Longyue and Luo, Weihua and Zhang, Kaifu. Marco-o1 v2: Towards Widening The Distillation Bottleneck for Reasoning Models. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistic...
-
[59]
2025 , eprint=
rStar2-Agent: Agentic Reasoning Technical Report , author=. 2025 , eprint=
2025
-
[60]
2024 , eprint=
Towards Best Practices of Activation Patching in Language Models: Metrics and Methods , author=. 2024 , eprint=
2024
-
[61]
The Twelfth International Conference on Learning Representations , year=
Sparse Autoencoders Find Highly Interpretable Features in Language Models , author=. The Twelfth International Conference on Learning Representations , year=
-
[62]
Stolfo, Alessandro and Belinkov, Yonatan and Sachan, Mrinmaya. A Mechanistic Interpretation of Arithmetic Reasoning in Language Models using Causal Mediation Analysis. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.435
-
[63]
International Conference on Learning Representations , year=
Mapping Language Models to Grounded Conceptual Spaces , author=. International Conference on Learning Representations , year=
-
[64]
2023 , eprint=
Dynamical versus Bayesian Phase Transitions in a Toy Model of Superposition , author=. 2023 , eprint=
2023
-
[65]
2022 , journal=
Toy Models of Superposition , author=. 2022 , journal=
2022
-
[66]
2024 , eprint=
Mathematical Models of Computation in Superposition , author=. 2024 , eprint=
2024
-
[67]
Efficient Estimation of Word Representations in Vector Space , booktitle =
Tom. Efficient Estimation of Word Representations in Vector Space , booktitle =. 2013 , url =
2013
-
[68]
Transactions on Machine Learning Research , issn=
Finding Neurons in a Haystack: Case Studies with Sparse Probing , author=. Transactions on Machine Learning Research , issn=. 2023 , url=
2023
-
[69]
Gemma Scope: Open Sparse Autoencoders Everywhere All At Once on Gemma 2
Lieberum, Tom and Rajamanoharan, Senthooran and Conmy, Arthur and Smith, Lewis and Sonnerat, Nicolas and Varma, Vikrant and Kramar, Janos and Dragan, Anca and Shah, Rohin and Nanda, Neel. Gemma Scope: Open Sparse Autoencoders Everywhere All At Once on Gemma 2. Proceedings of the 7th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP....
-
[70]
The Thirteenth International Conference on Learning Representations , year=
Scaling and evaluating sparse autoencoders , author=. The Thirteenth International Conference on Learning Representations , year=
-
[71]
2024 , journal=
Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet , author=. 2024 , journal=
2024
-
[72]
2024 , eprint=
Llama Scope: Extracting Millions of Features from Llama-3.1-8B with Sparse Autoencoders , author=. 2024 , eprint=
2024
-
[73]
Safety Layers in Aligned Large Language Models: The Key to
Shen Li and Liuyi Yao and Lan Zhang and Yaliang Li , booktitle=. Safety Layers in Aligned Large Language Models: The Key to. 2025 , url=
2025
-
[74]
Thirty-seventh Conference on Neural Information Processing Systems , year=
Towards Automated Circuit Discovery for Mechanistic Interpretability , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[75]
The Thirteenth International Conference on Learning Representations , year=
Sparse Feature Circuits: Discovering and Editing Interpretable Causal Graphs in Language Models , author=. The Thirteenth International Conference on Learning Representations , year=
-
[76]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[77]
ICML 2025 Workshop on Reliable and Responsible Foundation Models , year=
Steering Language Model Refusal with Sparse Autoencoders , author=. ICML 2025 Workshop on Reliable and Responsible Foundation Models , year=
2025
-
[78]
Forty-second International Conference on Machine Learning , year=
Learning Multi-Level Features with Matryoshka Sparse Autoencoders , author=. Forty-second International Conference on Machine Learning , year=
-
[79]
NeurIPS 2024 Workshop on Scientific Methods for Understanding Deep Learning , year=
BatchTopK Sparse Autoencoders , author=. NeurIPS 2024 Workshop on Scientific Methods for Understanding Deep Learning , year=
2024
-
[80]
2025 , url=
Adam Karvonen and Can Rager and Johnny Lin and Curt Tigges and Joseph Isaac Bloom and David Chanin and Yeu-Tong Lau and Eoin Farrell and Callum Stuart McDougall and Kola Ayonrinde and Demian Till and Matthew Wearden and Arthur Conmy and Samuel Marks and Neel Nanda , booktitle=. 2025 , url=
2025
-
[81]
Jumping Ahead: Improving Reconstruction Fidelity with JumpRe
Senthooran Rajamanoharan and Tom Lieberum and Nicolas Sonnerat and Arthur Conmy and Vikrant Varma and Janos Kramar and Neel Nanda , year=. Jumping Ahead: Improving Reconstruction Fidelity with JumpRe
-
[82]
2026 , eprint=
SynthSAEBench: Evaluating Sparse Autoencoders on Scalable Realistic Synthetic Data , author=. 2026 , eprint=
2026
-
[83]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Improving Sparse Decomposition of Language Model Activations with Gated Sparse Autoencoders , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[84]
The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale , author=. The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
-
[85]
Transformer Feed-Forward Layers Are Key-Value Memories
Geva, Mor and Schuster, Roei and Berant, Jonathan and Levy, Omer. Transformer Feed-Forward Layers Are Key-Value Memories. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021. doi:10.18653/v1/2021.emnlp-main.446
work page internal anchor Pith review doi:10.18653/v1/2021.emnlp-main.446 2021
-
[86]
Analyzing the Structure of Attention in a Transformer Language Model
Vig, Jesse and Belinkov, Yonatan. Analyzing the Structure of Attention in a Transformer Language Model. Proceedings of the 2019 ACL Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP. 2019. doi:10.18653/v1/W19-4808
-
[87]
Knowledge Neurons in Pretrained Transformers
Dai, Damai and Dong, Li and Hao, Yaru and Sui, Zhifang and Chang, Baobao and Wei, Furu. Knowledge Neurons in Pretrained Transformers. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022. doi:10.18653/v1/2022.acl-long.581
-
[88]
2021 , journal=
A Mathematical Framework for Transformer Circuits , author=. 2021 , journal=
2021
-
[89]
Forty-second International Conference on Machine Learning , year=
Layer by Layer: Uncovering Hidden Representations in Language Models , author=. Forty-second International Conference on Machine Learning , year=
-
[90]
2025 , eprint=
Layerwise Importance Analysis of Feed-Forward Networks in Transformer-based Language Models , author=. 2025 , eprint=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.