Temporally Consistent Label Interpolation for Robust Surgical Multi-Task Learning under Challenging Conditions
Pith reviewed 2026-06-26 05:02 UTC · model grok-4.3
The pith
A flow-guided framework generates dense pseudo labels from sparse surgical keyframes to balance multi-task learning across temporal and spatial tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
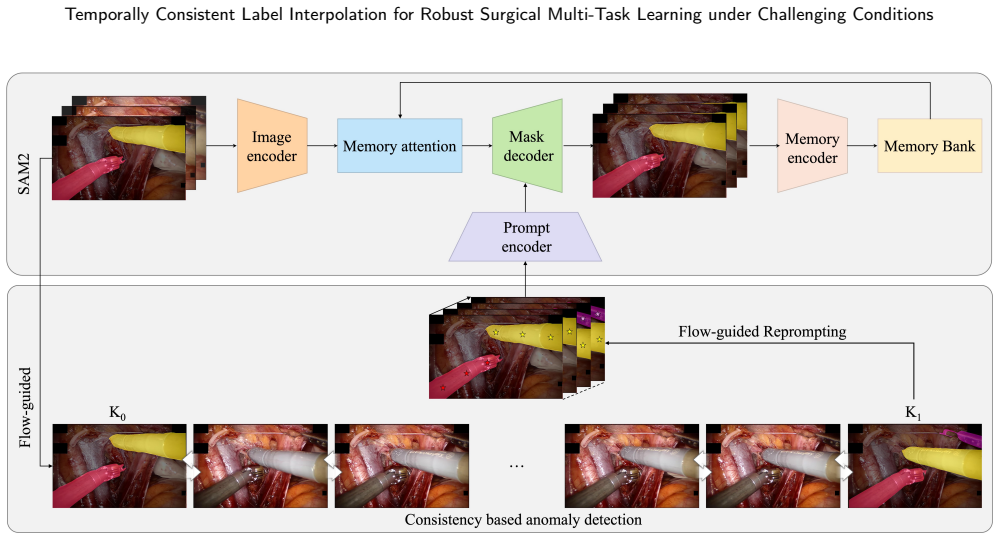
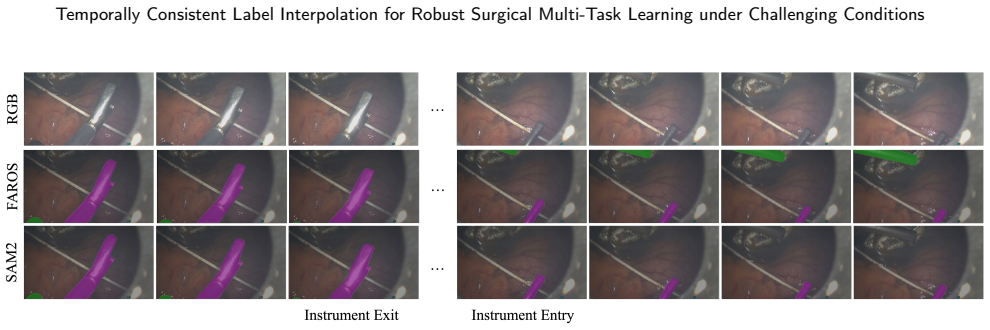
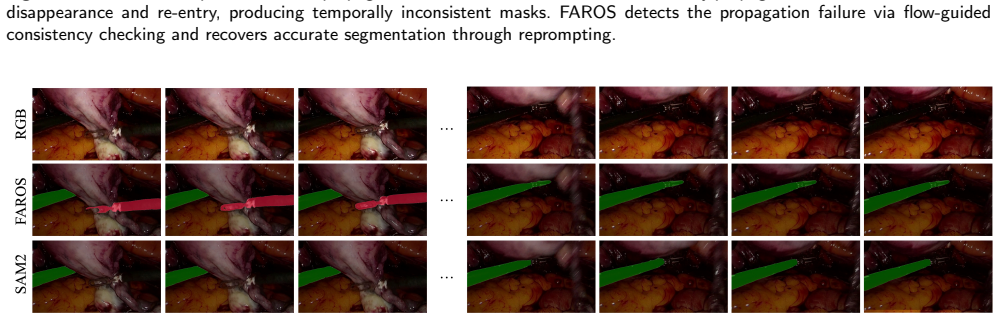
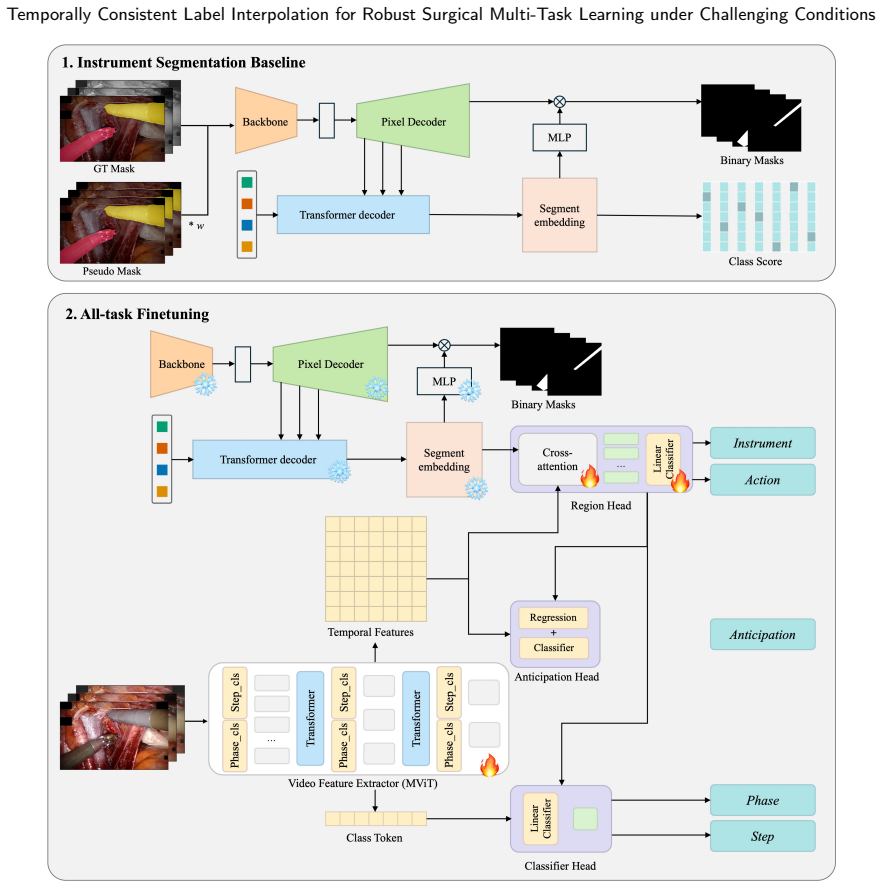
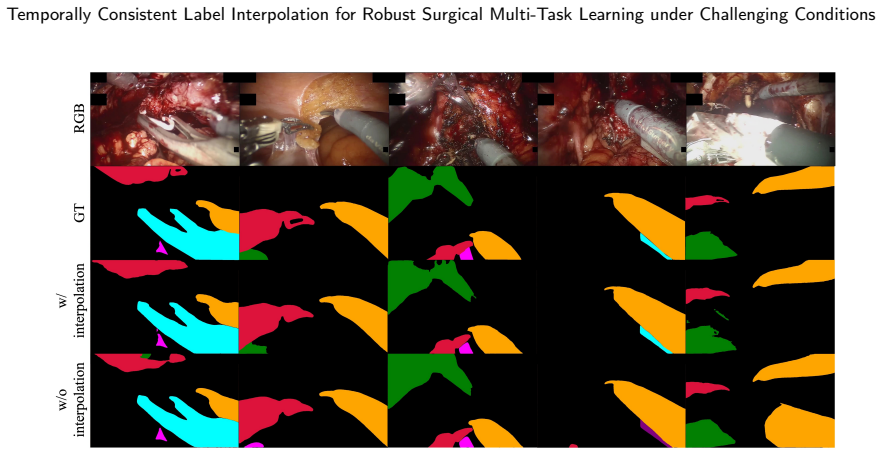
FAROS generates temporally consistent dense pseudo labels from sparse keyframe annotations by combining zero-shot segmentation-based mask propagation with optical flow estimation; these labels are then integrated into a unified Transformer-based multi-task framework that jointly learns surgical phase recognition, step recognition, anticipation, instrument segmentation, and action recognition, enabling balanced optimization between dense temporal supervision and sparse spatial supervision.
What carries the argument
FAROS, a flow-guided label interpolation framework that merges zero-shot segmentation mask propagation with optical flow estimation to produce consistent dense pseudo labels.
If this is right
- The unified Transformer model achieves higher performance on all five tasks simultaneously on GraSP, MISAW, and AutoLaparo.
- Cross-task representation learning improves because dense temporal supervision now aligns with dense spatial supervision.
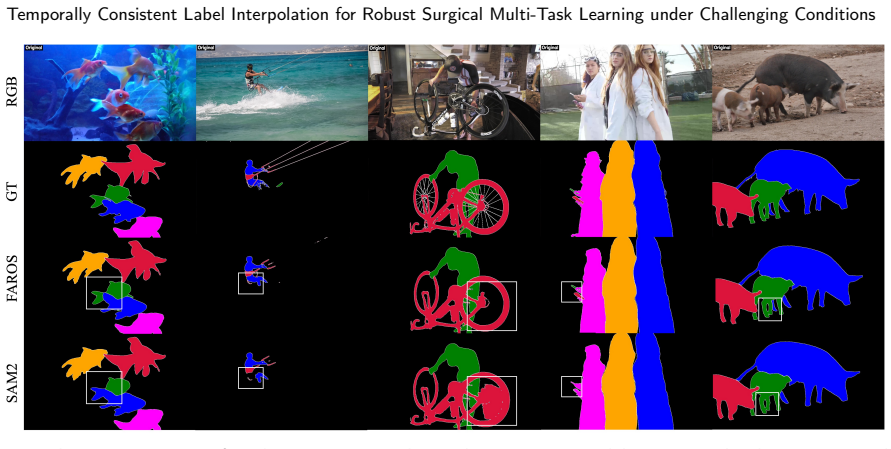
- Label interpolation quality holds on the non-surgical DAVIS 2017 benchmark under a sparse ground-truth protocol.
- Joint optimization becomes feasible without separate handling of annotation density differences.
Where Pith is reading between the lines
- The approach could lower labeling costs for new surgical datasets by requiring annotations only on keyframes.
- Similar interpolation might apply to other video domains such as autonomous driving or sports analysis where spatial labels are expensive.
- If the propagation step is made faster, the method could support online surgical assistance systems.
- The framework highlights a general pattern: using motion cues to densify supervision when tasks have mismatched annotation densities.
Load-bearing premise
Combining zero-shot segmentation-based mask propagation with optical flow estimation reliably overcomes the limits of appearance-based methods under occlusion, smoke, and motion blur.
What would settle it
A test set of surgical videos with heavy smoke or motion blur where the generated dense pseudo labels show lower accuracy than a ground-truth dense annotation baseline when measured by segmentation or action label metrics.
Figures









read the original abstract
Effective multi-task learning for surgical scene understanding is fundamentally hindered by annotation granularity mismatch; temporal workflow tasks such as phase recognition, step recognition and anticipation benefit from dense frame-level supervision, whereas pixel-level spatial tasks including instrument segmentation and action recognition are only sparsely annotated on selected keyframes due to prohibitive labeling costs. This supervision imbalance undermines shared representation learning and limits joint optimization across heterogeneous surgical tasks. To address this, we propose Flow-guided Annotation for Robust Operating Scenes (FAROS), a flow-guided label interpolation framework, that combines zero-shot segmentation-based mask propagation with optical flow estimation to overcome the limitations of appearance-based propagation under challenging surgical conditions such as occlusion, smoke, and motion blur, generating temporally consistent dense pseudo labels from sparse keyframe annotations. The densified instrument masks and action labels are integrated into a unified Transformer-based multi-task framework that jointly learns surgical phase recognition, step recognition, anticipation, instrument segmentation, and action recognition, enabling balanced optimization between dense temporal supervision and sparse spatial supervision. The label interpolation quality of FAROS is first validated on the DAVIS 2017 benchmark under a sparse ground-truth protocol, confirming robust propagation beyond the surgical domain. Extensive experiments on GraSP, MISAW, and AutoLaparo benchmarks further demonstrate that FAROS significantly improves cross-task representation learning and enhances holistic surgical scene understanding performance across spatio-temporal tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes FAROS (Flow-guided Annotation for Robust Operating Scenes), a framework that combines zero-shot segmentation-based mask propagation with optical flow estimation to generate temporally consistent dense pseudo labels from sparse keyframe annotations. These densified labels are integrated into a unified Transformer-based multi-task framework for joint learning of phase recognition, step recognition, anticipation, instrument segmentation, and action recognition. The interpolation quality is validated on DAVIS 2017 under a sparse ground-truth protocol, with claims of significant performance improvements on the GraSP, MISAW, and AutoLaparo surgical benchmarks under challenging conditions.
Significance. If the central claims hold, the work addresses a practical annotation imbalance in surgical scene understanding and could improve cross-task representation learning by providing dense supervision for temporal tasks while leveraging sparse spatial annotations. The cross-domain validation on DAVIS 2017 and the focus on robustness to occlusion, smoke, and motion blur represent potential strengths for generalizability.
major comments (3)
- Abstract: The abstract asserts that FAROS 'significantly improves cross-task representation learning and enhances holistic surgical scene understanding performance across spatio-temporal tasks' on GraSP, MISAW, and AutoLaparo, yet provides no quantitative results, error bars, ablation details, or specific metrics to support these claims, preventing any assessment of the magnitude or reliability of the reported gains.
- Abstract: The core claim that the zero-shot segmentation + optical flow combination produces accurate, temporally consistent dense pseudo labels specifically under surgical challenges (occlusion, smoke, motion blur) is not supported by direct label-quality metrics or ablations on the target surgical datasets; validation is restricted to DAVIS 2017, leaving open the possibility that any end-task gains arise from the unified Transformer or joint optimization rather than the interpolation mechanism.
- Abstract and methods description: No details are given on the unified Transformer architecture, the joint loss formulation, training protocol, or ablation studies isolating the contribution of the FAROS-generated labels versus baseline multi-task learning, which are load-bearing for attributing improvements to the proposed interpolation.
minor comments (1)
- The expansion of the FAROS acronym appears only after its first use; including it in the title or abstract opening sentence would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting areas where the abstract could better support the claims. We will revise the abstract to incorporate quantitative results and clarify the validation approach. We address each major comment below.
read point-by-point responses
-
Referee: Abstract: The abstract asserts that FAROS 'significantly improves cross-task representation learning and enhances holistic surgical scene understanding performance across spatio-temporal tasks' on GraSP, MISAW, and AutoLaparo, yet provides no quantitative results, error bars, ablation details, or specific metrics to support these claims, preventing any assessment of the magnitude or reliability of the reported gains.
Authors: We agree that including key quantitative metrics in the abstract would strengthen the summary. In the revision, we will add specific results such as accuracy improvements on phase recognition (e.g., +X% on GraSP) and mIoU gains on instrument segmentation, along with references to ablation studies, while keeping the abstract concise. revision: yes
-
Referee: Abstract: The core claim that the zero-shot segmentation + optical flow combination produces accurate, temporally consistent dense pseudo labels specifically under surgical challenges (occlusion, smoke, motion blur) is not supported by direct label-quality metrics or ablations on the target surgical datasets; validation is restricted to DAVIS 2017, leaving open the possibility that any end-task gains arise from the unified Transformer or joint optimization rather than the interpolation mechanism.
Authors: The DAVIS 2017 evaluation under sparse annotation protocol establishes the interpolation robustness in challenging conditions analogous to surgery. On surgical benchmarks, the contribution of FAROS labels is isolated via ablations comparing against baseline multi-task learning without densified labels. We will revise the abstract to explicitly note that downstream task gains on GraSP/MISAW/AutoLaparo serve as the primary validation for surgical applicability. revision: partial
-
Referee: Abstract and methods description: No details are given on the unified Transformer architecture, the joint loss formulation, training protocol, or ablation studies isolating the contribution of the FAROS-generated labels versus baseline multi-task learning, which are load-bearing for attributing improvements to the proposed interpolation.
Authors: Section 3 details the shared Transformer encoder with task-specific decoders, the joint loss as a weighted combination of cross-entropy (temporal tasks) and segmentation losses, the training protocol (AdamW optimizer, specific schedules, augmentations), and Section 4.3 presents ablations isolating FAROS label contributions. We will update the abstract with a brief reference to these elements for clarity. revision: yes
Circularity Check
No circularity; framework is self-contained
full rationale
The paper introduces FAROS as a new combination of zero-shot segmentation-based mask propagation and optical flow estimation to densify sparse keyframe labels, then integrates the results into a unified Transformer multi-task model. Validation occurs on DAVIS 2017 under sparse GT protocol, with end-task metrics reported on GraSP/MISAW/AutoLaparo. No equations, fitted parameters, self-definitional reductions, or load-bearing self-citations appear in the text; the method is presented as an independent engineering solution to annotation imbalance rather than deriving from or renaming prior fitted quantities.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Optical flow and zero-shot segmentation remain reliable under surgical occlusions, smoke, and motion blur
invented entities (1)
-
FAROS framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Deeplearningforsurgicalinstrumentrecognitionandsegmentationin robotic-assistedsurgeries:asystematicreview
Ahmed,F.A.,Yousef,M.,Ahmed,M.A.,Ali,H.O.,Mahboob,A.,Ali, H.,Shah,Z.,Aboumarzouk,O.,AlAnsari,A.,Balakrishnan,S.,2024. Deeplearningforsurgicalinstrumentrecognitionandsegmentationin robotic-assistedsurgeries:asystematicreview. ArtificialIntelligence Review 58, 1
2024
-
[2]
Multitask learning in minimallyinvasivesurgicalvision:Areview.MedicalImageAnalysis 101, 103480
Alabi, O., Vercauteren, T., Shi, M., 2025. Multitask learning in minimallyinvasivesurgicalvision:Areview.MedicalImageAnalysis 101, 103480
2025
-
[3]
2018 robotic scene segmentation challenge
Allan, M., Kondo, S., Bodenstedt, S., Leger, S., Kadkhodamoham- madi, R., Luengo, I., Fuentes, F., Flouty, E., Mohammed, A., Ped- ersen, M., et al., 2020. 2018 robotic scene segmentation challenge. arXiv preprint arXiv:2001.11190
arXiv 2020
-
[4]
Themedicalsegmentationdecathlon
Antonelli, M., Reinke, A., Bakas, S., Farahani, K., Kopp-Schneider, A., Landman, B.A., Litjens, G., Menze, B., Ronneberger, O., Sum- mers,R.M.,etal.,2022. Themedicalsegmentationdecathlon. Nature communications 13, 4128
2022
-
[5]
Pixel-wise recognition for holistic surgical scene under- standing
Ayobi, N., Rodríguez, S., Pérez, A., Hernández, I., Aparicio, N., Dessevres, E., Peña, S., Santander, J., Caicedo, J.I., Fernández, N., et al., 2024. Pixel-wise recognition for holistic surgical scene under- standing. arXiv preprint arXiv:2401.11174
arXiv 2024
-
[6]
Baghbaderani, R.K., Li, Y., Wang, S., Qi, H., 2024. Temporally- consistentvideosemanticsegmentationwithbidirectionalocclusion- guidedfeaturepropagation,in:ProceedingsoftheIEEE/CVFWinter Conference on Applications of Computer Vision, pp. 685–695
2024
-
[7]
Semi- supervised learning for network-based cardiac mr image segmenta- tion, in: International Conference on Medical Image Computing and Computer-Assisted Intervention, Springer
Bai, W., Oktay, O., Sinclair, M., Suzuki, H., Rajchl, M., Tarroni, G., Glocker, B., King, A., Matthews, P.M., Rueckert, D., 2017. Semi- supervised learning for network-based cardiac mr image segmenta- tion, in: International Conference on Medical Image Computing and Computer-Assisted Intervention, Springer. pp. 253–260
2017
-
[8]
Multitask learning
Caruana, R., 1997. Multitask learning. Machine learning 28, 41–75
1997
-
[9]
Scientific Reports 12, 19721
Chen,Q.,Poullis,C.,2022.Motionestimationforlargedisplacements and deformations. Scientific Reports 12, 19721
2022
-
[10]
Masked-attention mask transformer for universal image segmenta- tion,in:ProceedingsoftheIEEE/CVFconferenceoncomputervision and pattern recognition, pp
Cheng, B., Misra, I., Schwing, A.G., Kirillov, A., Girdhar, R., 2022. Masked-attention mask transformer for universal image segmenta- tion,in:ProceedingsoftheIEEE/CVFconferenceoncomputervision and pattern recognition, pp. 1290–1299
2022
-
[11]
Xmem: Long-term video object segmentation with an atkinson-shiffrin memory model, in: European conference on computer vision, Springer
Cheng, H.K., Schwing, A.G., 2022. Xmem: Long-term video object segmentation with an atkinson-shiffrin memory model, in: European conference on computer vision, Springer. pp. 640–658
2022
-
[12]
Rethinking space-time networks with improved memory coverage for efficient video object segmentation
Cheng, H.K., Tai, Y.W., Tang, C.K., 2021. Rethinking space-time networks with improved memory coverage for efficient video object segmentation. Advancesinneuralinformationprocessingsystems34, 11781–11794
2021
-
[13]
Isrobotic-assistedsurgerybetter? AMA Journal of Ethics 25, 598–604
Chuchulo,A.,Ali,A.,2023. Isrobotic-assistedsurgerybetter? AMA Journal of Ethics 25, 598–604
2023
-
[14]
Multi-tasklearningwithdeepneuralnetworks: A survey
Crawshaw,M.,2020. Multi-tasklearningwithdeepneuralnetworks: A survey. arXiv preprint arXiv:2009.09796
arXiv 2020
-
[15]
Tecno: Surgical phase recognition with multi-stage temporal convolutional networks, in: International conferenceonmedicalimagecomputingandcomputer-assistedinter- vention, Springer
Czempiel, T., Paschali, M., Keicher, M., Simson, W., Feussner, H., Kim, S.T., Navab, N., 2020. Tecno: Surgical phase recognition with multi-stage temporal convolutional networks, in: International conferenceonmedicalimagecomputingandcomputer-assistedinter- vention, Springer. pp. 343–352
2020
-
[16]
Deep learning in surgical workflow analysis: a review of phase and step recognition
Demir, K.C., Schieber, H., Weise, T., Roth, D., May, M., Maier, A., Yang, S.H., 2023. Deep learning in surgical workflow analysis: a review of phase and step recognition. IEEE Journal of Biomedical and Health Informatics 27, 5405–5417. Page 15 of 17 Temporally Consistent Label Interpolation for Robust Surgical Multi-Task Learning under Challenging Conditions
2023
-
[17]
Thepascalvisualobjectclasseschallenge:A retrospective
Everingham, M., Eslami, S.A., Van Gool, L., Williams, C.K., Winn, J.,Zisserman,A.,2015. Thepascalvisualobjectclasseschallenge:A retrospective. International journal of computer vision 111, 98–136
2015
-
[18]
Fan,H.,Xiong,B.,Mangalam,K.,Li,Y.,Yan,Z.,Malik,J.,Feichten- hofer,C.,2021.Multiscalevisiontransformers,in:IEEEInternational Conference on Computer Vision. doi:10.1109/ICCV48922.2021.00675
-
[19]
Gao, X., Jin, Y., Long, Y., Dou, Q., Heng, P.A., 2021. Trans-svnet: Accurate phase recognition from surgical videos via hybrid embed- dingaggregationtransformer,in:Internationalconferenceonmedical image computing and computer-assisted intervention, Springer. pp. 593–603
2021
-
[20]
Gu, C., Sun, C., Vijayanarasimhan, S., Pantofaru, C., Ross, D.A., Toderici, G., Li, Y., Ricco, S., Sukthankar, R., Schmid, C., Malik, J., 2017. Ava: A video dataset of spatio-temporally localized atomic visual actions, in: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. doi:10.1109/CVPR.2018.00633
-
[21]
Role of robotic- assisted surgery in public health: its advantages and challenges
Handa, A., Gaidhane, A., Choudhari, S.G., 2024. Role of robotic- assisted surgery in public health: its advantages and challenges. Cureus 16
2024
-
[22]
Micro-surgical anastomose workflow recognition challenge report
Huaulmé, A., Sarikaya, D., Le Mut, K., Despinoy, F., Long, Y., Dou, Q., Chng, C.B., Lin, W., Kondo, S., Bravo-Sánchez, L., et al., 2021. Micro-surgical anastomose workflow recognition challenge report. Computer Methods and Programs in Biomedicine 212, 106452
2021
-
[23]
Microsurgical instru- ment segmentation for robot-assisted surgery
Jeong, T.K., Kim, G., Park, J., 2025. Microsurgical instru- ment segmentation for robot-assisted surgery. arXiv preprint arXiv:2509.11727
arXiv 2025
-
[24]
Jin,Y.,Cheng,K.,Dou,Q.,Heng,P.A.,2019. Incorporatingtemporal prior from motion flow for instrument segmentation in minimally invasivesurgeryvideo,in:Internationalconferenceonmedicalimage computing and computer-assisted intervention, Springer. pp. 440– 448
2019
-
[25]
Sv-rcnet: workflow recognition from surgical videos using recurrent convolutional network
Jin,Y.,Dou,Q.,Chen,H.,Yu,L.,Qin,J.,Fu,C.W.,Heng,P.A.,2017. Sv-rcnet: workflow recognition from surgical videos using recurrent convolutional network. IEEE transactions on medical imaging 37, 1114–1126
2017
-
[26]
Multi-task recurrent convolutional network with correlation loss for surgical video analysis
Jin,Y.,Li,H.,Dou,Q.,Chen,H.,Qin,J.,Fu,C.W.,Heng,P.A.,2020. Multi-task recurrent convolutional network with correlation loss for surgical video analysis. Medical image analysis 59, 101572
2020
-
[27]
Segment anything, in: Proceedings of the IEEE/CVF international conference on computer vision, pp
Kirillov,A.,Mintun,E.,Ravi,N.,Mao,H.,Rolland,C.,Gustafson,L., Xiao, T., Whitehead, S., Berg, A.C., Lo, W.Y., et al., 2023. Segment anything, in: Proceedings of the IEEE/CVF international conference on computer vision, pp. 4015–4026
2023
-
[28]
Concurrentsegmentationandlocaliza- tion for tracking of surgical instruments, in: International conference on medical image computing and computer-assisted intervention, Springer
Laina, I., Rieke, N., Rupprecht, C., Vizcaíno, J.P., Eslami, A., Tombari,F.,Navab,N.,2017. Concurrentsegmentationandlocaliza- tion for tracking of surgical instruments, in: International conference on medical image computing and computer-assisted intervention, Springer. pp. 664–672
2017
-
[29]
Surgical process modelling: a review
Lalys, F., Jannin, P., 2014. Surgical process modelling: a review. International journal of computer assisted radiology and surgery 9, 495–511
2014
-
[30]
Pseudo-label: The simple and efficient semi- supervised learning method for deep neural networks, in: Workshop on challenges in representation learning, ICML, Atlanta
Lee, D.H., et al., 2013. Pseudo-label: The simple and efficient semi- supervised learning method for deep neural networks, in: Workshop on challenges in representation learning, ICML, Atlanta. p. 896
2013
-
[31]
Recurrent dynamicembeddingforvideoobjectsegmentation,in:Proceedingsof theIEEE/CVFConferenceonComputerVisionandPatternRecogni- tion, pp
Li,M.,Hu,L.,Xiong,Z.,Zhang,B.,Pan,P.,Liu,D.,2022. Recurrent dynamicembeddingforvideoobjectsegmentation,in:Proceedingsof theIEEE/CVFConferenceonComputerVisionandPatternRecogni- tion, pp. 1332–1341
2022
-
[32]
Drift robust non-rigid optical flowenhancementforlongsequences
Li, W., Cosker, D., Brown, M., 2016. Drift robust non-rigid optical flowenhancementforlongsequences. JournalofIntelligent&Fuzzy Systems 31, 2583–2595
2016
-
[33]
Deep learning for surgical workflow analysis: a survey of progresses, limitations, and trends
Li, Y., Zhao, Z., Li, R., Li, F., 2024. Deep learning for surgical workflow analysis: a survey of progresses, limitations, and trends. Artificial Intelligence Review 57, 291
2024
-
[34]
Surgical sam 2: Real-time segment anything in surgical video by efficient frame pruning
Liu, H., Zhang, E., Wu, J., Hong, M., Jin, Y., 2024. Surgical sam 2: Real-time segment anything in surgical video by efficient frame pruning. arXiv preprint arXiv:2408.07931
arXiv 2024
-
[35]
Liu,Z.,Lin,Y.,Cao,Y.,Hu,H.,Wei,Y.,Zhang,Z.,Lin,S.,Guo,B.,
-
[36]
10012–10022
Swintransformer:Hierarchicalvisiontransformerusingshifted windows, in: Proceedings of the IEEE/CVF international conference on computer vision, pp. 10012–10022
-
[37]
Semi-supervised medical image segmentation via uncertainty rectified pyramid consistency
Luo, X., Wang, G., Liao, W., Chen, J., Song, T., Chen, Y., Zhang, S., Metaxas, D.N., Zhang, S., 2022. Semi-supervised medical image segmentation via uncertainty rectified pyramid consistency. Medical Image Analysis 80, 102517
2022
-
[38]
Maier-Hein,L.,Vedula,S.S.,Speidel,S.,Navab,N.,Kikinis,R.,Park, A., Eisenmann, M., Feussner, H., Forestier, G., Giannarou, S., et al.,
-
[39]
Nature Biomedical Engineering 1, 691–696
Surgicaldatasciencefornext-generationinterventions. Nature Biomedical Engineering 1, 691–696
-
[40]
Robotic surgery: applications, limitations, and impact on surgical education
Morris, B., 2005. Robotic surgery: applications, limitations, and impact on surgical education. Medscape General Medicine 7, 72
2005
-
[41]
Joint-task regulariza- tion for partially labeled multi-task learning, in: Proceedings of the IEEE/CVFConferenceonComputerVisionandPatternRecognition, pp
Nishi, K., Kim, J., Li, W., Pfister, H., 2024. Joint-task regulariza- tion for partially labeled multi-task learning, in: Proceedings of the IEEE/CVFConferenceonComputerVisionandPatternRecognition, pp. 16152–16162
2024
-
[42]
Nwoye, C.I., Gonzalez, C., Yu, T., Mascagni, P., Mutter, D., Marescaux, J., Padoy, N., 2020. Recognition of instrument-tissue interactions in endoscopic videos via action triplets, in: International conferenceonmedicalimagecomputingandcomputer-assistedinter- vention, Springer. pp. 364–374
2020
-
[43]
Video object seg- mentationusingspace-timememorynetworks,in:Proceedingsofthe IEEE/CVF international conference on computer vision, pp
Oh, S.W., Lee, J.Y., Xu, N., Kim, S.J., 2019. Video object seg- mentationusingspace-timememorynetworks,in:Proceedingsofthe IEEE/CVF international conference on computer vision, pp. 9226– 9235
2019
-
[44]
The 2017 davis challenge on video object segmentation
Pont-Tuset,J.,Perazzi,F.,Caelles,S.,Arbeláez,P.,Sorkine-Hornung, A., Van Gool, L., 2017. The 2017 davis challenge on video object segmentation. arXiv preprint arXiv:1704.00675
Pith/arXiv arXiv 2017
-
[45]
Robust in- stancetrackingviauncertaintyflow.arXivpreprintarXiv:2010.04367
Qian, J., Nan, J., Ancha, S., Okorn, B., Held, D., 2020. Robust in- stancetrackingviauncertaintyflow.arXivpreprintarXiv:2010.04367
arXiv 2020
-
[46]
Weakly supervised temporal convolutional networks for fine-grained surgical activity recognition
Ramesh,S.,Dall’Alba,D.,Gonzalez,C.,Yu,T.,Mascagni,P.,Mutter, D., Marescaux, J., Fiorini, P., Padoy, N., 2023. Weakly supervised temporal convolutional networks for fine-grained surgical activity recognition. IEEE Transactions on Medical Imaging 42, 2592–2602
2023
-
[47]
Sam 2: Segmentanythinginimagesandvideos,in:InternationalConference on Learning Representations, pp
Ravi, N., Gabeur, V., Hu, Y.T., Hu, R., Ryali, C., Ma, T., Khedr, H., Rädle, R., Rolland, C., Gustafson, L., et al., 2025. Sam 2: Segmentanythinginimagesandvideos,in:InternationalConference on Learning Representations, pp. 28085–28128
2025
-
[48]
Unsupervised learningofopticalflowwithpatchconsistencyandocclusionestima- tion
Ren, Z., Yan, J., Yang, X., Yuille, A., Zha, H., 2020. Unsupervised learningofopticalflowwithpatchconsistencyandocclusionestima- tion. Pattern Recognition 103, 107191
2020
-
[49]
Rivoir, D., Bodenstedt, S., Funke, I., von Bechtolsheim, F., Distler, M., Weitz, J., Speidel, S., 2020. Rethinking anticipation tasks: Uncertainty-aware anticipation of sparse surgical instrument usage for context-aware assistance, in: International conference on medical image computing and computer-assisted intervention, Springer. pp. 752–762
2020
-
[50]
U-net: Convolutional networks for biomedical image segmentation, in: International Con- ferenceonMedicalimagecomputingandcomputer-assistedinterven- tion, Springer
Ronneberger, O., Fischer, P., Brox, T., 2015. U-net: Convolutional networks for biomedical image segmentation, in: International Con- ferenceonMedicalimagecomputingandcomputer-assistedinterven- tion, Springer. pp. 234–241
2015
-
[51]
An overview of multi-task learning in deep neural networks
Ruder, S., 2017. An overview of multi-task learning in deep neural networks. arXiv preprint arXiv:1706.05098
Pith/arXiv arXiv 2017
-
[52]
Evaluation of extra pixel interpolation with maskprocessingformedicalimagesegmentationwithdeeplearning
Rukundo, O., 2024. Evaluation of extra pixel interpolation with maskprocessingformedicalimagesegmentationwithdeeplearning. Signal, Image and Video Processing 18, 7703–7710
2024
-
[53]
Robotic surgery
Schreuder, H., Verheijen, R., 2009. Robotic surgery. BJOG: An International Journal of Obstetrics & Gynaecology 116, 198–213
2009
-
[54]
Fun-sis: A fully unsupervised approach for surgical instrument seg- mentation
Sestini, L., Rosa, B., De Momi, E., Ferrigno, G., Padoy, N., 2023. Fun-sis: A fully unsupervised approach for surgical instrument seg- mentation. Medical Image Analysis 85, 102751
2023
-
[55]
Hierarchical image saliency detection on extended cssd
Shi, J., Yan, Q., Xu, L., Jia, J., 2015. Hierarchical image saliency detection on extended cssd. IEEE transactions on pattern analysis and machine intelligence 38, 717–729
2015
-
[56]
Semi-supervisedlearning withprogressiveunlabeleddataexcavationforlabel-efficientsurgical workflow recognition
Shi,X.,Jin,Y.,Dou,Q.,Heng,P.A.,2021. Semi-supervisedlearning withprogressiveunlabeleddataexcavationforlabel-efficientsurgical workflow recognition. Medical Image Analysis 73, 102158. Page 16 of 17 Temporally Consistent Label Interpolation for Robust Surgical Multi-Task Learning under Challenging Conditions
2021
-
[57]
Auto- matic instrument segmentation in robot-assisted surgery using deep learning, in: 2018 17th IEEE international conference on machine learning and applications (ICMLA), IEEE
Shvets,A.A.,Rakhlin,A.,Kalinin,A.A.,Iglovikov,V.I.,2018. Auto- matic instrument segmentation in robot-assisted surgery using deep learning, in: 2018 17th IEEE international conference on machine learning and applications (ICMLA), IEEE. pp. 624–628
2018
-
[58]
Mean teachers are better role mod- els: Weight-averaged consistency targets improve semi-supervised deep learning results
Tarvainen, A., Valpola, H., 2017. Mean teachers are better role mod- els: Weight-averaged consistency targets improve semi-supervised deep learning results. Advances in neural information processing systems 30
2017
-
[59]
Raft:Recurrentall-pairsfieldtransformsfor optical flow, in: European conference on computer vision, Springer
Teed,Z.,Deng,J.,2020. Raft:Recurrentall-pairsfieldtransformsfor optical flow, in: European conference on computer vision, Springer. pp. 402–419
2020
-
[60]
Is learning the n-th thing any easier than learning the first? Advances in neural information processing systems 8
Thrun, S., 1995. Is learning the n-th thing any easier than learning the first? Advances in neural information processing systems 8
1995
-
[61]
Endonet: A deep architecture for recognition tasks on laparoscopic videos
Twinanda, A.P., Shehata, S., Mutter, D., Marescaux, J., De Mathelin, M., Padoy, N., 2016. Endonet: A deep architecture for recognition tasks on laparoscopic videos. IEEE transactions on medical imaging 36, 86–97
2016
-
[62]
Towards holistic surgical scene understanding, in: International con- ferenceonmedicalimagecomputingandcomputer-assistedinterven- tion, Springer
Valderrama, N., Ruiz Puentes, P., Hernández, I., Ayobi, N., Verlyck, M., Santander, J., Caicedo, J., Fernández, N., Arbeláez, P., 2022. Towards holistic surgical scene understanding, in: International con- ferenceonmedicalimagecomputingandcomputer-assistedinterven- tion, Springer. pp. 442–452
2022
-
[63]
Look before you match: Instance understanding matters in video object segmentation, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition, pp
Wang,J.,Chen,D.,Wu,Z.,Luo,C.,Tang,C.,Dai,X.,Zhao,Y.,Xie, Y., Yuan, L., Jiang, Y.G., 2023. Look before you match: Instance understanding matters in video object segmentation, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition, pp. 2268–2278
2023
-
[64]
Wang, Z., Lu, B., Long, Y., Zhong, F., Cheung, T.H., Dou, Q., Liu, Y., 2022. Autolaparo: A new dataset of integrated multi-tasks for image-guided surgical automation in laparoscopic hysterectomy, in: Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Springer. pp. 486– 496
2022
-
[65]
Segmatch: semi-supervised surgical instrument segmentation
Wei, M., Budd, C., Garcia-Peraza-Herrera, L.C., Dorent, R., Shi, M., Vercauteren, T., 2025. Segmatch: semi-supervised surgical instrument segmentation. Scientific Reports 15, 14042
2025
-
[66]
Accflow: Backward accumulation for long- range optical flow, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp
Wu, G., Liu, X., Luo, K., Liu, X., Zheng, Q., Liu, S., Jiang, X., Zhai, G., Wang, W., 2023. Accflow: Backward accumulation for long- range optical flow, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 12119–12128
2023
-
[67]
Appearance-based refinement for object-centric motion segmentation, in: European Conference on Computer Vision, Springer
Xie, J., Xie, W., Zisserman, A., 2024. Appearance-based refinement for object-centric motion segmentation, in: European Conference on Computer Vision, Springer. pp. 238–256
2024
-
[68]
Gmflow: Learning optical flow via global matching, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp
Xu, H., Zhang, J., Cai, J., Rezatofighi, H., Tao, D., 2022. Gmflow: Learning optical flow via global matching, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 8121–8130
2022
-
[69]
Hard frame detection and online mapping for surgical phase recognition, in: International Conference on Medical ImageComputingandComputer-AssistedIntervention,Springer.pp
Yi, F., Jiang, T., 2019. Hard frame detection and online mapping for surgical phase recognition, in: International Conference on Medical ImageComputingandComputer-AssistedIntervention,Springer.pp. 449–457
2019
-
[70]
Memory- augmentedsam2fortraining-freesurgicalvideosegmentation,in:In- ternationalConferenceonMedicalImageComputingandComputer- Assisted Intervention, Springer
Yin, M., Wang, F., Ye, X., Meng, Y., Fu, Z., 2025. Memory- augmentedsam2fortraining-freesurgicalvideosegmentation,in:In- ternationalConferenceonMedicalImageComputingandComputer- Assisted Intervention, Springer. pp. 328–337
2025
-
[71]
Yu, J., Wang, A., Dong, W., Xu, M., Islam, M., Wang, J., Bai, L., Ren, H., 2025. Sam 2 in robotic surgery: An empirical evaluation for robustness and generalization in surgical video segmentation, in: International Workshop on Efficient Medical Artificial Intelligence, Springer. pp. 174–183
2025
-
[72]
Yu, Y., Zhao, Z., Jin, Y., Chen, G., Dou, Q., Heng, P.A., 2022. Pseudo-label guided cross-video pixel contrast for robotic surgical scene segmentation with limited annotations, in: 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), IEEE. pp. 10857–10864
2022
-
[73]
Semisam+: rethinking semi-supervised medical image segmentation in the era of foundation models
Zhang, Y., Lv, B., Xue, L., Zhang, W., Liu, Y., Fu, Y., Cheng, Y., Qi, Y., 2025. Semisam+: rethinking semi-supervised medical image segmentation in the era of foundation models. Medical Image Analysis , 103733
2025
-
[74]
Nasalseg: A dataset for automatic segmentationofnasalcavityandparanasalsinusesfrom3dctimages
Zhang, Y., Wang, J., Pan, T., Jiang, Q., Ge, J., Guo, X., Jiang, C., Lu, J., Zhang, J., Liu, X., et al., 2024. Nasalseg: A dataset for automatic segmentationofnasalcavityandparanasalsinusesfrom3dctimages. Scientific Data 11, 1329
2024
-
[75]
A survey on multi-task learning
Zhang, Y., Yang, Q., 2021. A survey on multi-task learning. IEEE transactions on knowledge and data engineering 34, 5586–5609
2021
-
[76]
Zhao, Z., Jin, Y., Gao, X., Dou, Q., Heng, P.A., 2020. Learn- ing motion flows for semi-supervised instrument segmentation from roboticsurgicalvideo,in:InternationalConferenceonMedicalImage Computing and Computer-Assisted Intervention, Springer. pp. 679– 689. Page 17 of 17
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.