SegFold: Accelerating Sparse GEMM with a Fine-Grained Dynamic Dataflow
Pith reviewed 2026-06-26 02:07 UTC · model grok-4.3
The pith
SegFold shows that fine-grained dynamic scheduling and remapping in SpGEMM dataflows produce reuse and load-balance gains no static dataflow can match.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that extending typical SpGEMM dataflows with fine-grained dynamic scheduling to optimize reuse and reduce contention, together with dynamic remapping of partially completed work to improve load balance and parallelism, formalized as the Segment dataflow and implemented in SegFold via a memory controller that detects local reuse and a merge network that routes and remaps work, produces a geometric-mean 1.95 times speedup over state-of-the-art SpGEMM accelerators and 5.3 times over the best static dataflow.
What carries the argument
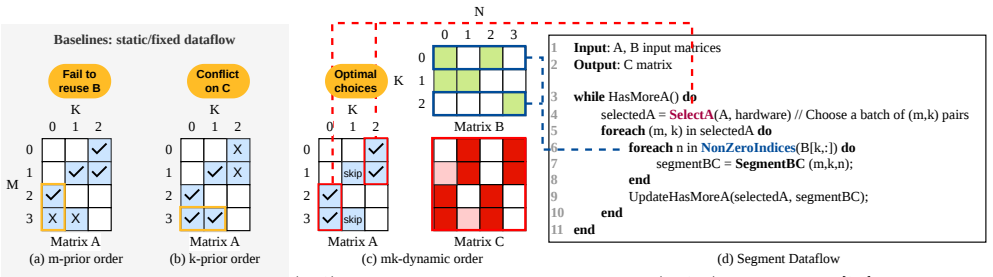
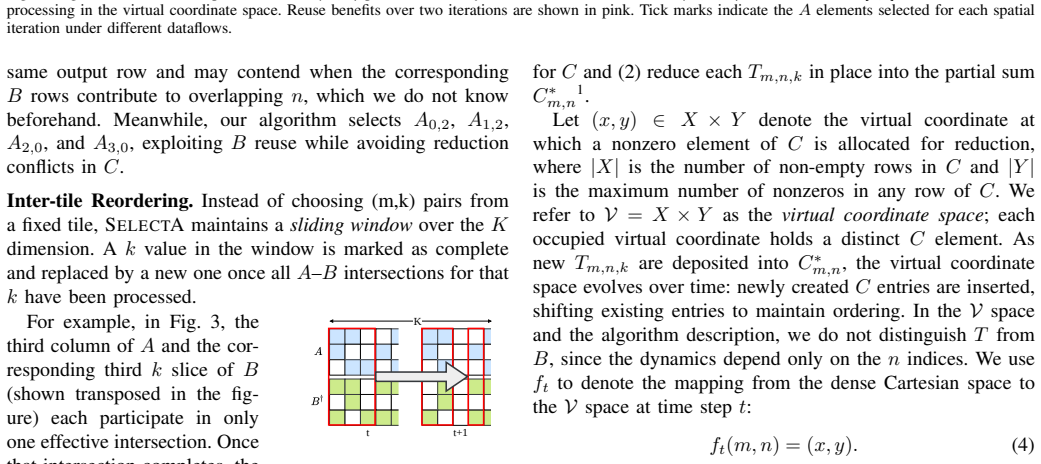
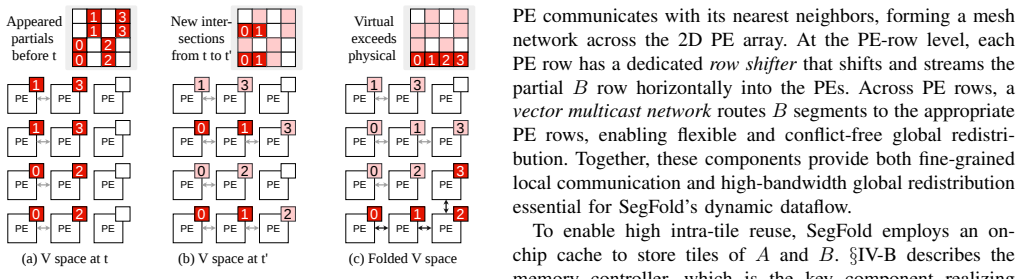
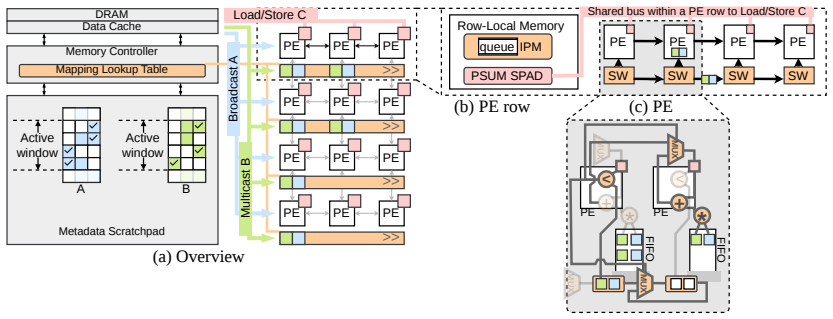
The Segment dataflow, which adds fine-grained dynamic scheduling for reuse optimization and dynamic remapping for load balance, executed by SegFold's memory controller that scans a local window of the stationary input and its merge network that routes and reassigns work across processing elements.
If this is right
- The same matrix set yields substantially higher throughput when dynamism is present than when any fixed static dataflow is used in isolation.
- Load imbalance and missed reuse that appear under static assignment disappear once work can be reassigned at fine granularity.
- Hardware that only supports one static schedule cannot reach the performance level demonstrated by the combined dynamic mechanisms.
- The gains hold across a wide range of matrix densities and sizes rather than being limited to particular sparsity patterns.
Where Pith is reading between the lines
- Designers of future sparse accelerators may need to allocate silicon budget to flexible controllers rather than to larger fixed-function arrays.
- The same dynamic-remapping idea could be tested on other sparse kernels such as sparse triangular solve or sparse tensor contraction.
- If matrix sizes continue to grow, the relative benefit of dynamic load balancing is likely to increase because static partitioning becomes harder to tune in advance.
Load-bearing premise
The memory controller and merge network can locate fine-grained reuse opportunities and execute dynamic remapping with overhead small enough to preserve the reported speedups.
What would settle it
Cycle-accurate hardware measurements showing that the added area, power, or latency of the dynamic memory controller and merge network exceeds the 1.95 times performance gain would falsify the claim that the dynamism is practically beneficial.
Figures






read the original abstract
Generalized sparse matrix-matrix multiplication (SpGEMM) is critical in many domains. Existing CPUs and GPUs, as well as specialized accelerators, rely on static dataflows (e.g., inner product, outer product, Gustavson, etc.). Each static dataflow sacrifices some data reuse opportunities and imposes constraints on load balance. To address this inefficiency, we extend the typical SpGEMM dataflows by considering dynamism. Specifically, we add fine-grained dynamic scheduling to optimize reuse and reduce resource contention. We also develop dynamic remapping of partially completed work to improve load balance and parallelism. These ideas are formalized into a specific dataflow called Segment. To demonstrate Segment, we codesign a SpGEMM accelerator called SegFold. SegFold includes a memory controller that identifies fine-grained reuse opportunities in a local window of the stationary input array and exploits them through dynamic work assignment. It also incorporates a merge network that routes inputs to appropriate processing elements (PEs) for computation while dynamically remapping the work assigned to each PE to balance load. Across diverse densities and matrix sizes, SegFold achieves a geometric-mean $1.95\times$ speedup over state-of-the-art SpGEMM accelerators and $5.3\times$ over the best static dataflow configuration, demonstrating that adding dynamism to the dataflow design space unlocks reuse and load-balance gains that no static scheduling choice can achieve in isolation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SegFold, a SpGEMM accelerator that implements a dynamic dataflow called Segment. Segment extends static dataflows (inner/outer product, Gustavson) with fine-grained dynamic scheduling to exploit reuse opportunities in a local window of the stationary input and with dynamic remapping of partial results via a merge network to improve load balance. The accelerator includes a specialized memory controller for reuse detection and work assignment. Across varied matrix densities and sizes, SegFold is reported to deliver 1.95× geometric-mean speedup versus prior SpGEMM accelerators and 5.3× versus the best static dataflow configuration.
Significance. If the net speedup holds after accounting for control overhead, the result would be significant for the sparse-accelerator community: it supplies concrete empirical evidence that dynamism can extract reuse and parallelism gains unavailable to any fixed static schedule. The codesign of dataflow and hardware, together with the reported cross-density speedups, would strengthen the case for exploring dynamic scheduling in future SpGEMM designs.
major comments (1)
- [Architecture description and evaluation sections] The central performance claim (1.95× geo-mean and 5.3× over best static) is load-bearing on the assumption that the memory controller's reuse detection and the merge network's dynamic remapping incur sufficiently low area, power, and cycle overhead. No quantitative characterization of these overheads (gate count, energy per operation, or added latency) appears in the architecture description or evaluation, leaving open whether the reported speedups are net positive.
minor comments (1)
- [Abstract] The abstract states results 'across diverse densities and matrix sizes' yet supplies neither the exact benchmark matrices nor the density/size ranges used; adding this information would allow readers to assess coverage.
Simulated Author's Rebuttal
We thank the referee for highlighting the importance of quantifying control overheads in the dynamic components of SegFold. This is a substantive point that directly affects the strength of our performance claims. We will revise the manuscript to include the requested characterization.
read point-by-point responses
-
Referee: [Architecture description and evaluation sections] The central performance claim (1.95× geo-mean and 5.3× over best static) is load-bearing on the assumption that the memory controller's reuse detection and the merge network's dynamic remapping incur sufficiently low area, power, and cycle overhead. No quantitative characterization of these overheads (gate count, energy per operation, or added latency) appears in the architecture description or evaluation, leaving open whether the reported speedups are net positive.
Authors: We agree that the absence of quantitative overhead data leaves the net speedup claim open to question. The current manuscript focuses on the dataflow and high-level speedup results but does not report synthesized gate counts, energy per operation, or cycle latency for the reuse-detection logic in the memory controller or the merge network. In the revised version we will add a dedicated subsection (likely in Section 4) that presents these metrics from our RTL implementation and synthesis runs at the target process node, allowing direct assessment of whether the 1.95× and 5.3× speedups remain positive after overheads. revision: yes
Circularity Check
No circularity; empirical hardware proposal with external benchmarks
full rationale
The paper proposes a dynamic dataflow (Segment) and accelerator (SegFold) for SpGEMM, with claims resting on geometric-mean speedups from evaluation across matrix densities/sizes. No equations, fitted parameters, or self-referential derivations appear in the abstract or described structure. The central result (1.95× over SOTA, 5.3× over best static) is presented as an empirical outcome of simulation, not reduced by construction to inputs or self-citations. This is a standard self-contained architecture paper whose validity depends on external benchmarks and implementation details, not internal definitional loops.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard assumptions about sparse matrix access patterns and hardware resource constraints hold for the evaluated workloads.
invented entities (1)
-
Segment dataflow
no independent evidence
Reference graph
Works this paper leans on
-
[1]
On the representation and multiplication of hypersparse matrices,
A. Buluc ¸ and J. R. Gilbert, “On the representation and multiplication of hypersparse matrices,” in2008 IEEE International Symposium on Parallel and Distributed Processing (IPDPS), 2008, pp. 1–11
2008
-
[2]
ASAP7: A 7-nm FinFET predictive process design kit,
L. T. Clark, V . Vashishtha, L. Shifren, A. Gujja, S. Sinha, B. Cline, C. Ramamurthy, and G. Yeric, “ASAP7: A 7-nm FinFET predictive process design kit,”Microelectronics Journal, vol. 53, pp. 105–115, 2016
2016
-
[3]
NVIDIA GPU programming guide, v2.2.1, November, 2004
N. Corp, “NVIDIA GPU programming guide, v2.2.1, November, 2004.”
2004
-
[4]
PolyGraph: Exposing the value of flexibility for graph processing accelerators,
V . Dadu, S. Liu, and T. Nowatzki, “PolyGraph: Exposing the value of flexibility for graph processing accelerators,” in2021 ACM/IEEE 48th Annual International Symposium on Computer Architecture (ISCA), 2021, pp. 595–608
2021
-
[5]
Towards general purpose acceleration by exploiting common data-dependence forms,
V . Dadu, J. Weng, S. Liu, and T. Nowatzki, “Towards general purpose acceleration by exploiting common data-dependence forms,” ser. MICRO ’52. New York, NY , USA: ACM, 2019, pp. 924–939. [Online]. Available: http://doi.acm.org/10.1145/3352460.3358276
-
[6]
ZeD: A generalized accelerator for variably sparse matrix computations in ML,
P. Dangi, Z. Bai, R. Juneja, D. Wijerathne, and T. Mitra, “ZeD: A generalized accelerator for variably sparse matrix computations in ML,” inProceedings of the 2024 International Conference on Parallel Architectures and Compilation Techniques, ser. PACT ’24. New York, NY , USA: Association for Computing Machinery, 2024, p. 246–257. [Online]. Available: htt...
-
[7]
Hardware acceleration of sparse and irregular tensor computa- tions of ML models: A survey and insights,
S. Dave, R. Baghdadi, T. Nowatzki, S. Avancha, A. Shrivastava, and B. Li, “Hardware acceleration of sparse and irregular tensor computa- tions of ML models: A survey and insights,”Proceedings of the IEEE, vol. 109, no. 10, pp. 1706–1752, 2021
2021
-
[8]
The university of florida sparse matrix collection,
T. A. Davis and Y . Hu, “The university of florida sparse matrix collection,”ACM Transactions on Mathematical Software, vol. 38, no. 1, pp. 1:1–1:25, 2011
2011
-
[9]
Recent advances in artificial intelligence via machine learning and the implications for computer system design,
J. Dean, “Recent advances in artificial intelligence via machine learning and the implications for computer system design,” in2017 IEEE Hot Chips 29 Symposium, 2017
2017
-
[10]
A systematic survey of general sparse Matrix-Matrix multiplication,
J. Gao, W. Ji, F. Chang, S. Han, B. Wei, Z. Liu, and Y . Wang, “A systematic survey of general sparse Matrix-Matrix multiplication,” ACM Comput. Surv., vol. 55, no. 12, Mar. 2023. [Online]. Available: https://doi.org/10.1145/3571157
-
[11]
H. N. Genc, H. Kim, P. Ganesh, and Y . S. Shao, “Stellar: An automated design framework for dense and sparse spatial accelerators,” inProceedings of the 2024 57th IEEE/ACM International Symposium on Microarchitecture, ser. MICRO ’24. IEEE Press, 2024, p. 409–422. [Online]. Available: https://doi.org/10.1109/MICRO61859.2024.00038
-
[12]
AWB-GCN: A graph convolutional network accelerator with runtime workload rebalancing,
T. Geng, A. Li, R. Shi, C. Wu, T. Wang, Y . Li, P. Haghi, A. Tumeo, S. Che, S. Reinhardt, and M. C. Herbordt, “AWB-GCN: A graph convolutional network accelerator with runtime workload rebalancing,” in2020 53rd Annual IEEE/ACM International Symposium on Microar- chitecture (MICRO), 2020, pp. 922–936
2020
-
[13]
RipTide: A programmable, energy-minimal dataflow compiler and architecture,
G. Gobieski, S. Ghosh, M. Heule, T. Mowry, T. Nowatzki, N. Beckmann, and B. Lucia, “RipTide: A programmable, energy-minimal dataflow compiler and architecture,” in2022 55th IEEE/ACM International Sym- posium on Microarchitecture (MICRO), 2022, pp. 546–564
2022
-
[14]
SparTen: A sparse tensor accelerator for convolutional neural networks,
A. Gondimalla, N. Chesnut, M. Thottethodi, and T. N. Vijaykumar, “SparTen: A sparse tensor accelerator for convolutional neural networks,” inProceedings of the 52nd Annual IEEE/ACM International Symposium on Microarchitecture, ser. MICRO ’52. New York, NY , USA: Association for Computing Machinery, 2019, p. 151–165. [Online]. Available: https://doi.org/10...
-
[15]
Eie: efficient inference engine on compressed deep neural network,
S. Han, X. Liu, H. Mao, J. Pu, A. Pedram, M. A. Horowitz, and W. J. Dally, “Eie: efficient inference engine on compressed deep neural network,” inProceedings of the 43rd International Symposium on Computer Architecture, ser. ISCA ’16. IEEE Press, 2016, p. 243–254. [Online]. Available: https://doi.org/10.1109/ISCA.2016.30
-
[16]
Sparse-TPU: Adapting systolic arrays for sparse matrices,
X. He, S. Pal, A. Amarnath, S. Feng, D.-H. Park, A. Rovinski, H. Ye, Y . Chen, R. Dreslinski, and T. Mudge, “Sparse-TPU: Adapting systolic arrays for sparse matrices,” inProceedings of the 34th ACM interna- tional conference on supercomputing, 2020, pp. 1–12
2020
-
[17]
Towards general purpose acceleration by exploiting common data-dependence forms,
K. Hegde, H. Asghari-Moghaddam, M. Pellauer, N. Crago, A. Jaleel, E. Solomonik, J. Emer, and C. W. Fletcher, “ExTensor: An accelerator for sparse tensor algebra,” inProceedings of the 52nd Annual IEEE/ACM International Symposium on Microarchitecture, ser. MICRO-52. New York, NY , USA: Association for Computing Machinery, 2019, p. 319–333. [Online]. Availa...
-
[18]
Stardust: Compiling sparse tensor algebra to a reconfigurable dataflow architecture,
O. Hsu, A. Rucker, T. Zhao, V . Desai, K. Olukotun, and F. Kjolstad, “Stardust: Compiling sparse tensor algebra to a reconfigurable dataflow architecture,” inProceedings of the 23rd ACM/IEEE International Symposium on Code Generation and Optimization, ser. CGO ’25. New York, NY , USA: Association for Computing Machinery, 2025, p. 628–643. [Online]. Availa...
-
[19]
H. Huang, P. Yao, Z. An, Y . Sun, A. Hu, P. Xu, L. Zheng, X. Liao, and H. Jin, “SpaHet: A software/hardware co-design for accelerating heterogeneous-sparsity based sparse matrix multiplication,” inProceedings of the 61st ACM/IEEE Design Automation Conference, ser. DAC ’24. New York, NY , USA: Association for Computing Machinery, 2024. [Online]. Available:...
-
[20]
Cerberus: Triple mode acceleration of sparse matrix and vector multiplication,
S. Hwang, D. Baek, J. Park, and J. Huh, “Cerberus: Triple mode acceleration of sparse matrix and vector multiplication,”ACM Trans. Archit. Code Optim., vol. 21, no. 2, May 2024. [Online]. Available: https://doi.org/10.1145/3653020
-
[21]
N. P. Jouppi, C. Young, N. Patil, D. Patterson, G. Agrawal, R. Bajwa, S. Bates, S. Bhatia, N. Boden, A. Borchers, R. Boyle, P.-l. Cantin, C. Chao, C. Clark, J. Coriell, M. Daley, M. Dau, J. Dean, B. Gelb, T. V . Ghaemmaghami, R. Gottipati, W. Gulland, R. Hagmann, C. R. Ho, D. Hogberg, J. Hu, R. Hundt, D. Hurt, J. Ibarz, A. Jaffey, A. Jaworski, A. Kaplan, ...
-
[22]
Zena: Zero-aware neural network accel- erator,
D. Kim, J. Ahn, and S. Yoo, “Zena: Zero-aware neural network accel- erator,”IEEE Design & Test, vol. 35, no. 1, pp. 39–46, 2017
2017
-
[23]
Onyx: A programmable accelerator for sparse tensor algebra,
K. Koul, M. Strange, J. Melchert, A. Carsello, Y . Mei, O. Hsu, T. Kong, P.-H. Chen, H. Ke, K. Zhanget al., “Onyx: A programmable accelerator for sparse tensor algebra,” in2024 IEEE Hot Chips 36 Symposium (HCS). IEEE Computer Society, 2024, pp. 1–91
2024
-
[24]
Spada: Accelerating sparse matrix multiplication with adaptive dataflow,
Z. Li, J. Li, T. Chen, D. Niu, H. Zheng, Y . Xie, and M. Gao, “Spada: Accelerating sparse matrix multiplication with adaptive dataflow,” inProceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2, ser. ASPLOS 2023. New York, NY , USA: Association for Computing Machinery, 2023, ...
-
[25]
Ramulator 2.0: A modern, modular, and extensible DRAM simulator,
H. Luo, Y . C. Tu ˘grul, F. N. Bostancı, A. Olgun, A. G. Ya ˘glıkc ¸ı, and O. Mutlu, “Ramulator 2.0: A modern, modular, and extensible DRAM simulator,” 2023. [Online]. Available: https://arxiv.org/abs/2308.11030
arXiv 2023
-
[26]
Sparm: A sparse matrix multiplication accelerator supporting multiple dataflows,
S. Luo, B. Wang, Y . Shi, X. Zhang, Q. Xue, and S. Ma, “Sparm: A sparse matrix multiplication accelerator supporting multiple dataflows,” in2024 IEEE 35th International Conference on Application-specific Systems, Architectures and Processors (ASAP), 2024, pp. 122–130
2024
-
[27]
Mosaic: Processing a trillion-edge graph on a single machine,
S. Maass, C. Min, S. Kashyap, W. Kang, M. Kumar, and T. Kim, “Mosaic: Processing a trillion-edge graph on a single machine,” inProceedings of the Twelfth European Conference on Computer Systems, ser. EuroSys ’17. New York, NY , USA: Association for Computing Machinery, 2017, p. 527–543. [Online]. Available: https://doi.org/10.1145/3064176.3064191
-
[28]
F. Mu ˜noz Mart ´ınez, R. Garg, M. Pellauer, J. L. Abell ´an, M. E. Acacio, and T. Krishna, “Flexagon: A multi-dataflow sparse-sparse matrix multiplication accelerator for efficient DNN processing,” inProceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 3, ser. ASPLOS 2023. N...
-
[29]
Exploiting locality in graph analytics through hardware-accelerated traversal scheduling,
A. Mukkara, N. Beckmann, M. Abeydeera, X. Ma, and D. Sanchez, “Exploiting locality in graph analytics through hardware-accelerated traversal scheduling,” inMICRO. IEEE, 2018, pp. 1–14
2018
-
[30]
STONNE: Enabling cycle-level microarchitectural simulation for DNN inference accelerators,
F. Mu ˜noz-Mart´ınez, J. L. Abell ´an, M. E. Acacio, and T. Krishna, “STONNE: Enabling cycle-level microarchitectural simulation for DNN inference accelerators,” in2021 IEEE International Symposium on Workload Characterization (IISWC), 2021, pp. 201–213
2021
-
[31]
TeAAL: A declarative framework for modeling sparse tensor accelerators,
N. Nayak, T. O. Odemuyiwa, S. Ugare, C. Fletcher, M. Pellauer, and J. Emer, “TeAAL: A declarative framework for modeling sparse tensor accelerators,” inProceedings of the 56th Annual IEEE/ACM International Symposium on Microarchitecture, ser. MICRO ’23. New York, NY , USA: Association for Computing Machinery, 2023, p. 1255–1270. [Online]. Available: https...
-
[32]
A sparse matrix vector multiply accelerator for support vector machine,
E. Nurvitadhi, A. Mishra, and D. Marr, “A sparse matrix vector multiply accelerator for support vector machine,” in2015 International Confer- ence on Compilers, Architecture and Synthesis for Embedded Systems (CASES), Oct 2015, pp. 109–116
2015
-
[33]
OuterSPACE: An outer product based sparse matrix multiplication accelerator,
S. Pal, J. Beaumont, D. Park, A. Amarnath, S. Feng, C. Chakrabarti, H. Kim, D. Blaauw, T. Mudge, and R. Dreslinski, “OuterSPACE: An outer product based sparse matrix multiplication accelerator,” in 2018 IEEE International Symposium on High Performance Computer Architecture (HPCA), Feb 2018, pp. 724–736
2018
-
[34]
SparseAdapt: Runtime control for sparse linear algebra on a reconfigurable accelerator,
S. Pal, A. Amarnath, S. Feng, M. O’Boyle, R. Dreslinski, and C. Dubach, “SparseAdapt: Runtime control for sparse linear algebra on a reconfigurable accelerator,” inMICRO-54: 54th Annual IEEE/ACM International Symposium on Microarchitecture, ser. MICRO ’21. New York, NY , USA: Association for Computing Machinery, 2021, p. 1005–1021. [Online]. Available: ht...
-
[35]
Transmuter: Bridging the efficiency gap using memory and dataflow reconfiguration,
S. Pal, S. Feng, D.-h. Park, S. Kim, A. Amarnath, C.-S. Yang, X. He, J. Beaumont, K. May, Y . Xiong, K. Kaszyk, J. M. Morton, J. Sun, M. O’Boyle, M. Cole, C. Chakrabarti, D. Blaauw, H.-S. Kim, T. Mudge, and R. Dreslinski, “Transmuter: Bridging the efficiency gap using memory and dataflow reconfiguration,” inProceedings of the ACM International Conference ...
-
[36]
SCNN: An accelerator for compressed-sparse convolutional neural networks,
A. Parashar, M. Rhu, A. Mukkara, A. Puglielli, R. Venkatesan, B. Khailany, J. Emer, S. W. Keckler, and W. J. Dally, “SCNN: An accelerator for compressed-sparse convolutional neural networks,” in Proceedings of the 44th Annual International Symposium on Computer Architecture, ser. ISCA ’17. New York, NY , USA: ACM, 2017, pp. 27–
2017
-
[37]
Available: http://doi.acm.org/10.1145/3079856.3080254
[Online]. Available: http://doi.acm.org/10.1145/3079856.3080254
-
[38]
Available: http://doi.acm.org/10.1145/3079856.3080254
R. Prabhakar, Y . Zhang, D. Koeplinger, M. Feldman, T. Zhao, S. Hadjis, A. Pedram, C. Kozyrakis, and K. Olukotun, “Plasticine: A reconfigurable architecture for parallel paterns,” ser. ISCA ’17. New York, NY , USA: ACM, 2017, pp. 389–402. [Online]. Available: http://doi.acm.org/10.1145/3079856.3080256
-
[39]
Extending sparse tensor accelerators to support multiple compression formats,
E. Qin, G. Jeong, W. Won, S.-C. Kao, H. Kwon, S. Srinivasan, D. Das, G. E. Moon, S. Rajamanickam, and T. Krishna, “Extending sparse tensor accelerators to support multiple compression formats,” in2021 IEEE International Parallel and Distributed Processing Symposium (IPDPS). IEEE, 2021, pp. 1014–1024
2021
-
[40]
SIGMA: A sparse and irregular GEMM accelerator with flexible interconnects for DNN training,
E. Qin, A. Samajdar, H. Kwon, V . Nadella, S. Srinivasan, D. Das, B. Kaul, and T. Krishna, “SIGMA: A sparse and irregular GEMM accelerator with flexible interconnects for DNN training,” in2020 IEEE International Symposium on High Performance Computer Architecture (HPCA), 2020, pp. 58–70
2020
-
[41]
Capstan: A vector RDA for sparsity,
A. Rucker, M. Vilim, T. Zhao, Y . Zhang, R. Prabhakar, and K. Olukotun, “Capstan: A vector RDA for sparsity,” 2021
2021
-
[42]
Serpens: A high bandwidth memory based accelerator for general-purpose sparse matrix-vector mul- tiplication,
L. Song, Y . Chi, L. Guo, and J. Cong, “Serpens: A high bandwidth memory based accelerator for general-purpose sparse matrix-vector mul- tiplication,” inProceedings of the 59th ACM/IEEE design automation conference, 2022, pp. 211–216
2022
-
[43]
Sextans: A streaming accelerator for general-purpose sparse-matrix dense-matrix multiplication,
L. Song, Y . Chi, A. Sohrabizadeh, Y .-k. Choi, J. Lau, and J. Cong, “Sextans: A streaming accelerator for general-purpose sparse-matrix dense-matrix multiplication,” inProceedings of the 2022 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, 2022, pp. 65–77
2022
-
[44]
MatRaptor: A sparse-sparse matrix multiplication accelerator based on row-wise product,
N. Srivastava, H. Jin, J. Liu, D. Albonesi, and Z. Zhang, “MatRaptor: A sparse-sparse matrix multiplication accelerator based on row-wise product,” in2020 53rd Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), 2020, pp. 766–780
2020
-
[45]
Tensaurus: A versatile accelerator for mixed sparse-dense tensor com- putations,
N. Srivastava, H. Jin, S. Smith, H. Rong, D. Albonesi, and Z. Zhang, “Tensaurus: A versatile accelerator for mixed sparse-dense tensor com- putations,” in2020 IEEE International Symposium on High Performance Computer Architecture (HPCA). IEEE, 2020, pp. 689–702
2020
-
[46]
SparGD: A sparse GEMM accelerator with dynamic dataflow,
B. Wang, S. Ma, S. Luo, L. Wu, J. Zhang, C. Zhang, and T. Li, “SparGD: A sparse GEMM accelerator with dynamic dataflow,”ACM Trans. Des. Autom. Electron. Syst., vol. 29, no. 2, Jan. 2024. [Online]. Available: https://doi.org/10.1145/3634703
-
[47]
B. Wang, S. Ma, Y . Zhao, S. Luo, L. Wu, J. Zhang, D. Li, T. Li, and Z. Chen, “SpMARD: A sparse-sparse matrix multiplication accelerator with reconfigurable dataflow for DNN workloads,”ACM Trans. Archit. Code Optim., Aug. 2025, just Accepted. [Online]. Available: https://doi.org/10.1145/3747847
-
[48]
Sparseloop: An analytical approach to sparse tensor accelerator modeling,
Y . N. Wu, P.-A. Tsai, A. Parashar, V . Sze, and J. S. Emer, “Sparseloop: An analytical approach to sparse tensor accelerator modeling,” in Proceedings of the 55th Annual IEEE/ACM International Symposium on Microarchitecture, ser. MICRO ’22. IEEE Press, 2023, p. 1377–1395. [Online]. Available: https://doi.org/10.1109/MICRO56248.2022.00096
-
[49]
DynaFlow: An ML framework for dynamic dataflow selection in SpGEMM accelerators,
S. Yadav and B. Asgari, “DynaFlow: An ML framework for dynamic dataflow selection in SpGEMM accelerators,”IEEE Computer Architec- ture Letters, vol. 24, no. 1, pp. 189–192, 2025
2025
-
[50]
Trapezoid: A versatile accelerator for dense and sparse matrix multiplications,
Y . Yang, J. S. Emer, and D. Sanchez, “Trapezoid: A versatile accelerator for dense and sparse matrix multiplications,” in2024 ACM/IEEE 51st Annual International Symposium on Computer Architecture (ISCA), 2024, pp. 931–945
2024
-
[51]
ScalaGraph: A scalable accelerator for massively parallel graph processing,
P. Yao, L. Zheng, Y . Huang, Q. Wang, C. Gui, Z. Zeng, X. Liao, H. Jin, and J. Xue, “ScalaGraph: A scalable accelerator for massively parallel graph processing,” in2022 IEEE International Symposium on High- Performance Computer Architecture (HPCA), 2022, pp. 199–212
2022
-
[52]
Gamma: Leveraging Gustavson’s algorithm to accelerate sparse matrix multiplication,
G. Zhang, N. Attaluri, J. S. Emer, and D. Sanchez, “Gamma: Leveraging Gustavson’s algorithm to accelerate sparse matrix multiplication,” ser. ASPLOS 2021. New York, NY , USA: Association for Computing Machinery, 2021. [Online]. Available: https://doi.org/10.1145/3445814. 3446702
-
[53]
Exploring the hidden dimension in graph processing,
M. Zhang, Y . Wu, K. Chen, X. Qian, X. Li, and W. Zheng, “Exploring the hidden dimension in graph processing,” inProceedings of the 12th USENIX Conference on Operating Systems Design and Implementation, ser. OSDI’16. USA: USENIX Association, 2016, p. 285–300
2016
-
[54]
Cambricon-X: An accelerator for sparse neural networks,
S. Zhang, Z. Du, L. Zhang, H. Lan, S. Liu, L. Li, Q. Guo, T. Chen, and Y . Chen, “Cambricon-X: An accelerator for sparse neural networks,” in 2016 49th Annual IEEE/ACM International Symposium on Microarchi- tecture (MICRO), 2016, pp. 1–12
2016
-
[55]
Sparch: Efficient architecture for sparse matrix multiplication,
Z. Zhang, H. Wang, S. Han, and W. J. Dally, “Sparch: Efficient architecture for sparse matrix multiplication,” in2020 IEEE Interna- tional Symposium on High Performance Computer Architecture (HPCA). IEEE, 2020, pp. 261–274
2020
-
[56]
Feasta: A flexible and efficient accelerator for sparse tensor algebra in machine learning,
K. Zhong, Z. Zhu, G. Dai, H. Wang, X. Yang, H. Zhang, J. Si, Q. Mao, S. Zeng, K. Honget al., “Feasta: A flexible and efficient accelerator for sparse tensor algebra in machine learning,” inProceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 3, 2024, pp. 349–366
2024
-
[57]
X. Zhou, Z. Du, Q. Guo, S. Liu, C. Liu, C. Wang, X. Zhou, L. Li, T. Chen, and Y . Chen, “Cambricon-S: Addressing irregularity in sparse neural networks through a cooperative software/hardware approach,” in 2018 51st Annual IEEE/ACM International Symposium on Microarchi- tecture (MICRO), 2018, pp. 15–28. APPENDIX Abstract We release the complete SegFold ar...
-
[58]
Build the simulator and run a smoke test: ./scripts/setup.sh
-
[59]
Download benchmark matrices: python3 scripts/download_matrices.py Docker (alternative).A pre-configured container is also avail- able: docker compose build docker compose run artifact \ ./scripts/run_all.sh Experiment Workflow A single command reproduces every experiment: ./scripts/run_all.sh Outputs are placed inoutput/ae_<timestamp>/. Each figure or tab...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.