SpatialFlow-GRPO: Where Spatial Credit Drives Image Editing
Pith reviewed 2026-06-26 05:35 UTC · model grok-4.3
The pith
SpatialFlow-GRPO replaces whole-image rewards with region-aligned signals to improve fine-grained image editing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
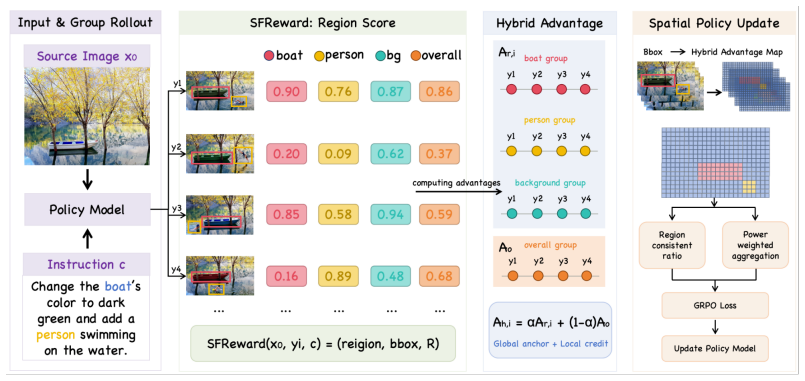
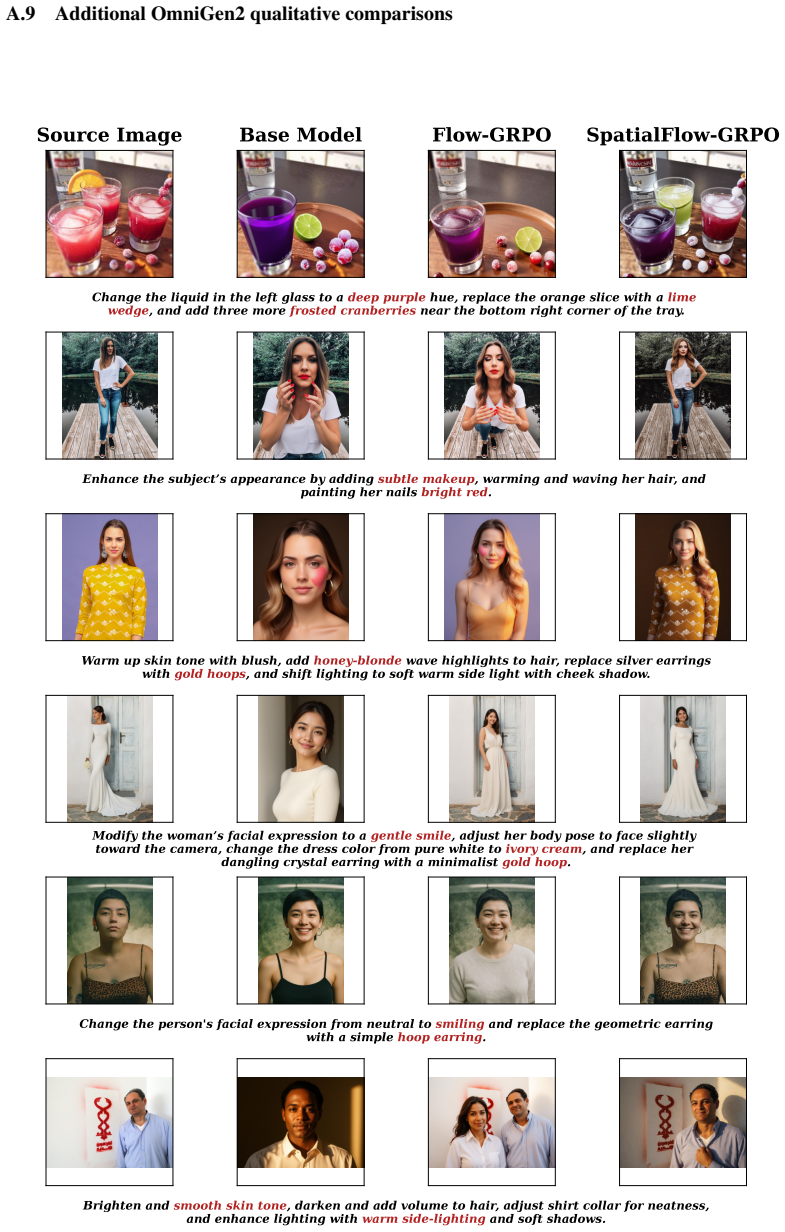
SpatialFlow-GRPO converts region-aware rewards into semantic-region-level optimization signals and aligns region advantages with the corresponding latent positions during policy updates, which removes the spatial uniformity assumption of prior whole-image reward methods and produces higher-quality edits on OmniGen2 and FLUX.2-klein-4B.
What carries the argument
The conversion of region-aware rewards from SFReward into semantic-region-level optimization signals that are explicitly aligned with latent positions during the GRPO policy update.
If this is right
- Editing quality improves on GEdit-Bench, ImgEdit-Bench, and MultiEditBench relative to Flow-GRPO.
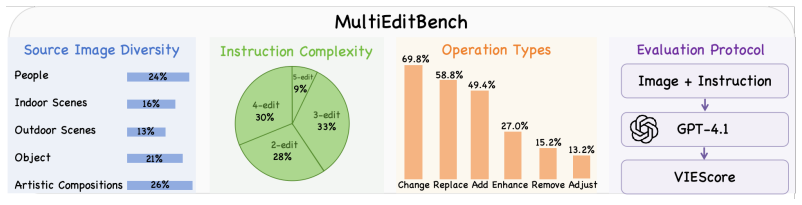
- The method supports multi-region editing evaluation via the introduced MultiEditBench.
- A region-annotated dataset SFReward-14K can be used to train further region-aware reward models.
- The same spatial-alignment step can be applied to other Flow-GRPO variants without changing the base model.
Where Pith is reading between the lines
- The same region-to-latent alignment idea could be tested on video or 3D generation where temporal or depth credit assignment is the analogous problem.
- If the alignment step is removed, performance should collapse back to the level of standard Flow-GRPO; that controlled ablation would isolate the contribution of spatial credit.
- The approach may generalize to any generative model that uses flow-matching or diffusion latents, provided a region-aware reward model can be trained.
Load-bearing premise
Region-aware rewards produced by SFReward can be turned into optimization signals that correctly match the spatial locations of the latents being updated.
What would settle it
Run the same training loop on OmniGen2 or FLUX.2-klein-4B but replace the spatial-alignment step with uniform whole-image advantages; if GEdit-Bench and MultiEditBench scores show no improvement over Flow-GRPO, the central claim is false.
Figures






read the original abstract
Recent online reinforcement learning has substantially improved image editing quality. However, existing Flow-GRPO-style methods usually rely on a single whole-image reward, which makes fine-grained editing optimization difficult. We observe that a key obstacle in image editing is this spatial uniformity assumption: a whole-image reward cannot distinguish how different spatial regions contribute to image quality. To address this issue, we propose SpatialFlow-GRPO, a training framework that introduces spatially fine-grained reward feedback. The framework converts region-aware rewards into semantic-region-level optimization signals and aligns region advantages with the corresponding latent positions during policy updates. We also train a region-aware reward model, SFReward, construct SFReward-14K with region-annotated editing samples, and introduce MultiEditBench to evaluate multi-region editing ability. On OmniGen2 and FLUX.2-klein-4B, SpatialFlow-GRPO outperforms Flow-GRPO on GEdit-Bench, ImgEdit-Bench, and MultiEditBench. The results show that SpatialFlow-GRPO converts local feedback into spatially aligned update signals and improves editing quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SpatialFlow-GRPO, an extension of Flow-GRPO for image editing that incorporates spatially fine-grained reward feedback via a new region-aware reward model SFReward (trained on the introduced SFReward-14K dataset). It converts region-aware rewards into semantic-region-level optimization signals, aligns region advantages with corresponding latent positions during policy updates, and introduces MultiEditBench to evaluate multi-region editing. Experiments claim that SpatialFlow-GRPO outperforms Flow-GRPO on GEdit-Bench, ImgEdit-Bench, and MultiEditBench using OmniGen2 and FLUX.2-klein-4B.
Significance. If the spatial alignment mechanism is robust and the mapping from pixel-space regions to latent positions is accurate, the approach could meaningfully advance fine-grained credit assignment in RL for generative image editing by overcoming the spatial uniformity of whole-image rewards. The new dataset and benchmark for multi-region editing are constructive additions to the field.
major comments (1)
- [Abstract / Method] Abstract and Method description of the alignment step: the central claim that the framework 'converts region-aware rewards into semantic-region-level optimization signals and aligns region advantages with the corresponding latent positions' rests on an untested correspondence assumption. Flow-model latents are downsampled and potentially entangled; without an explicit mapping procedure (coordinate scaling, attention, etc.), ablation on spatial distortions, or visualization confirming that advantages are not misaligned or globally averaged, the 'spatially aligned update signals' may not differ from standard Flow-GRPO in a load-bearing way.
minor comments (1)
- [Abstract] Abstract: multiple new terms (SFReward, SFReward-14K, MultiEditBench) are introduced without a brief definitional clause or forward reference, reducing immediate clarity for readers.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract / Method] Abstract and Method description of the alignment step: the central claim that the framework 'converts region-aware rewards into semantic-region-level optimization signals and aligns region advantages with the corresponding latent positions' rests on an untested correspondence assumption. Flow-model latents are downsampled and potentially entangled; without an explicit mapping procedure (coordinate scaling, attention, etc.), ablation on spatial distortions, or visualization confirming that advantages are not misaligned or globally averaged, the 'spatially aligned update signals' may not differ from standard Flow-GRPO in a load-bearing way.
Authors: We agree that the current manuscript description of the alignment step is insufficiently detailed and that the correspondence between pixel-space regions and latent positions requires explicit justification and validation. The referee's concern is valid: without a documented mapping, ablation, or visualization, it is difficult to confirm that the proposed signals are spatially localized rather than effectively global. In the revised manuscript we will (1) add a precise description of the mapping procedure (coordinate scaling by the model's downsampling factor with bilinear interpolation for non-grid alignment, followed by token-level masking in the GRPO objective), (2) include an ablation that intentionally perturbs the spatial mapping to quantify performance drop, and (3) add visualizations of per-region advantage maps overlaid on both pixel and latent grids. These additions will be placed in Section 3 and the supplementary material. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The abstract and described method introduce SpatialFlow-GRPO as an extension of Flow-GRPO that adds an independent spatial alignment step, a new region-aware reward model (SFReward), a new dataset (SFReward-14K), and a new benchmark (MultiEditBench). No equations or steps are shown that reduce the central claim (conversion of region rewards to aligned latent advantages) to a self-definition, a fitted parameter renamed as prediction, or a load-bearing self-citation chain. The mapping assumption is stated explicitly as a modeling choice rather than derived from prior inputs by construction. This is the normal case of an incremental method with external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A whole-image reward cannot distinguish how different spatial regions contribute to image quality.
invented entities (4)
-
SpatialFlow-GRPO
no independent evidence
-
SFReward
no independent evidence
-
SFReward-14K
no independent evidence
-
MultiEditBench
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Qwen3-vl technical report, 2025
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
Pith/arXiv arXiv 2025
-
[2]
Training diffusion models with reinforcement learning, 2024
Kevin Black, Michael Janner, Yilun Du, Ilya Kostrikov, and Sergey Levine. Training diffusion models with reinforcement learning, 2024. URLhttps://arxiv.org/abs/2305.13301
Pith/arXiv arXiv 2024
-
[3]
FLUX.2 [klein] 4b base
Black Forest Labs. FLUX.2 [klein] 4b base. Hugging Face model card, 2026. URLhttps: //huggingface.co/black-forest-labs/FLUX.2-klein-base-4B
2026
-
[4]
Tim Brooks, Aleksander Holynski, and Alexei A. Efros. Instructpix2pix: Learning to follow image editing instructions. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 18392–18402, June 2023
2023
-
[5]
Diffedit: Diffusion-based semantic image editing with mask guidance, 2022
Guillaume Couairon, Jakob Verbeek, Holger Schwenk, and Matthieu Cord. Diffedit: Diffusion-based semantic image editing with mask guidance, 2022. URLhttps://arxiv. org/abs/2210.11427
arXiv 2022
-
[6]
Scaling rectified flow transformers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, Dustin Podell, Tim Dockhorn, Zion English, and Robin Rombach. Scaling rectified flow transformers for high-resolution image synthesis. InForty-first International Conference on Machine Learning, 2024. URLhttps: ...
2024
-
[7]
Dpok: Reinforce- ment learning for fine-tuning text-to-image diffusion models
Ying Fan, Olivia Watkins, Yuqing Du, Hao Liu, Moonkyung Ryu, Craig Boutilier, Pieter Abbeel, Mohammad Ghavamzadeh, Kangwook Lee, and Kimin Lee. Dpok: Reinforce- ment learning for fine-tuning text-to-image diffusion models. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural In- formation Processing Systems, v...
-
[8]
URLhttps://proceedings.neurips.cc/paper_files/paper/2023/file/ fc65fab891d83433bd3c8d966edde311-Paper-Conference.pdf
2023
-
[9]
Guiding instruction-based image editing via multimodal large language models, 2024
Tsu-Jui Fu, Wenze Hu, Xianzhi Du, William Yang Wang, Yinfei Yang, and Zhe Gan. Guiding instruction-based image editing via multimodal large language models, 2024. URLhttps: //arxiv.org/abs/2309.17102
arXiv 2024
-
[10]
Gemini 3 pro model card, 2025
Google DeepMind. Gemini 3 pro model card, 2025. URLhttps://storage.googleapis. com/deepmind-media/Model-Cards/Gemini-3-Pro-Model-Card.pdf
2025
-
[11]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, Bing Xue, Bingxuan Wang, Bochao Wu, Bei Feng, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chong Ruan, Damai Dai, Deli Chen, Dongjie Ji, ...
-
[12]
Imagedoctor: Diagnosing text-to-image generation via grounded image reasoning, 2025
Yuxiang Guo, Jiang Liu, Ze Wang, Hao Chen, Ximeng Sun, Yang Zhao, Jialian Wu, Xiaodong Yu, Zicheng Liu, and Emad Barsoum. Imagedoctor: Diagnosing text-to-image generation via grounded image reasoning, 2025. URLhttps://arxiv.org/abs/2510.01010
arXiv 2025
-
[13]
Prompt-to-prompt image editing with cross attention control, 2022
Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Prompt-to-prompt image editing with cross attention control, 2022. URLhttps://arxiv. org/abs/2208.01626
Pith/arXiv arXiv 2022
-
[14]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. In H. Larochelle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin, editors,Advances in Neural Information Processing Systems, volume 33, pages 6840–6851. Curran As- sociates, Inc., 2020. URLhttps://proceedings.neurips.cc/paper_files/paper/ 2020/file/4c5bcfec8584af0d967f1a...
2020
-
[15]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models, 2021. URLhttps://arxiv.org/abs/2106.09685
Pith/arXiv arXiv 2021
-
[16]
Multimodal rewardbench 2: Evaluating omni reward models for interleaved text and image, 2026
Yushi Hu, Reyhane Askari-Hemmat, Melissa Hall, Emily Dinan, Luke Zettlemoyer, and Mar- jan Ghazvininejad. Multimodal rewardbench 2: Evaluating omni reward models for interleaved text and image, 2026. URLhttps://arxiv.org/abs/2512.16899
arXiv 2026
-
[17]
Towards better alignment: Training diffusion models with reinforce- ment learning against sparse rewards
Zijing Hu, Fengda Zhang, Long Chen, Kun Kuang, Jiahui Li, Kaifeng Gao, Jun Xiao, Xin Wang, and Wenwu Zhu. Towards better alignment: Training diffusion models with reinforce- ment learning against sparse rewards. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), pages 23604–23614, June 2025
2025
-
[18]
Paralleledits: Efficient multi-object image editing, 2025
Mingzhen Huang, Jialing Cai, Shan Jia, Vishnu Suresh Lokhande, and Siwei Lyu. Paralleledits: Efficient multi-object image editing, 2025. URLhttps://arxiv.org/abs/2406.00985
arXiv 2025
-
[19]
Smartedit: Exploring complex instruction-based image editing with multimodal large language models
Yuzhou Huang, Liangbin Xie, Xintao Wang, Ziyang Yuan, Xiaodong Cun, Yixiao Ge, Jiantao Zhou, Chao Dong, Rui Huang, Ruimao Zhang, and Ying Shan. Smartedit: Exploring complex instruction-based image editing with multimodal large language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 8362– 8371, June 2024
2024
-
[20]
Hq-edit: A high-quality dataset for instruction-based image editing, 2024
Mude Hui, Siwei Yang, Bingchen Zhao, Yichun Shi, Heng Wang, Peng Wang, Yuyin Zhou, and Cihang Xie. Hq-edit: A high-quality dataset for instruction-based image editing, 2024. URLhttps://arxiv.org/abs/2404.09990
arXiv 2024
-
[21]
Pick-a-pic: An open dataset of user preferences for text-to-image generation
Yuval Kirstain, Adam Polyak, Uriel Singer, Shahbuland Matiana, Joe Penna, and Omer Levy. Pick-a-pic: An open dataset of user preferences for text-to-image generation. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Ad- vances in Neural Information Processing Systems, volume 36, pages 36652–36663. Curran Associates, Inc., 20...
2023
-
[22]
Viescore: Towards explain- able metrics for conditional image synthesis evaluation, 2024
Max Ku, Dongfu Jiang, Cong Wei, Xiang Yue, and Wenhu Chen. Viescore: Towards explain- able metrics for conditional image synthesis evaluation, 2024. URLhttps://arxiv.org/ abs/2312.14867
arXiv 2024
-
[23]
Hp-edit: A human- preference post-training framework for image editing, 2026
Fan Li, Chonghuinan Wang, Lina Lei, Yuping Qiu, Jiaqi Xu, Jiaxiu Jiang, Xinran Qin, Zhikai Chen, Fenglong Song, Zhixin Wang, Renjing Pei, and Wangmeng Zuo. Hp-edit: A human- preference post-training framework for image editing, 2026. URLhttps://arxiv.org/ abs/2604.19406
Pith/arXiv arXiv 2026
-
[24]
Instructrl4pix: Training diffusion for im- age editing by reinforcement learning, 2024
Tiancheng Li, Jinxiu Liu, Huajun Chen, and Qi Liu. Instructrl4pix: Training diffusion for im- age editing by reinforcement learning, 2024. URLhttps://arxiv.org/abs/2406.09973
arXiv 2024
-
[25]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling, 2023. URLhttps://arxiv.org/abs/2210.02747
Pith/arXiv arXiv 2023
-
[26]
Flow-grpo: Training flow matching models via online rl, 2025
Jie Liu, Gongye Liu, Jiajun Liang, Yangguang Li, Jiaheng Liu, Xintao Wang, Pengfei Wan, Di Zhang, and Wanli Ouyang. Flow-grpo: Training flow matching models via online rl, 2025. URLhttps://arxiv.org/abs/2505.05470
Pith/arXiv arXiv 2025
-
[27]
Step1x-edit: A practical framework for general image editing,
Shiyu Liu, Yucheng Han, Peng Xing, Fukun Yin, Rui Wang, Wei Cheng, Jiaqi Liao, Yingming Wang, Honghao Fu, Chunrui Han, Guopeng Li, Yuang Peng, Quan Sun, Jingwei Wu, Yan Cai, Zheng Ge, Ranchen Ming, Lei Xia, Xianfang Zeng, Yibo Zhu, Binxing Jiao, Xiangyu Zhang, Gang Yu, and Daxin Jiang. Step1x-edit: A practical framework for general image editing,
-
[28]
URLhttps://arxiv.org/abs/2504.17761
-
[29]
Yancheng Long, Yankai Yang, Hongyang Wei, Wei Chen, Tianke Zhang, Haonan fan, Changyi Liu, Kaiyu Jiang, Jiankang Chen, Kaiyu Tang, Bin Wen, Fan Yang, Tingting Gao, Han Li, and Shuo Yang. Spatialreward: Bridging the perception gap in online rl for image editing via explicit spatial reasoning, 2026. URLhttps://arxiv.org/abs/2602.07458
Pith/arXiv arXiv 2026
-
[30]
Editscore: Unlocking online rl for image editing via high-fidelity reward modeling, 2026
Xin Luo, Jiahao Wang, Chenyuan Wu, Shitao Xiao, Xiyan Jiang, Defu Lian, Jiajun Zhang, Dong Liu, and Zheng liu. Editscore: Unlocking online rl for image editing via high-fidelity reward modeling, 2026. URLhttps://arxiv.org/abs/2509.23909
arXiv 2026
-
[31]
I2ebench: A comprehensive benchmark for instruction- based image editing
Yiwei Ma, Jiayi Ji, Ke Ye, Weihuang Lin, Zhibin Wang, Yonghan Zheng, Qiang Zhou, Xi- aoshuai Sun, and Rongrong Ji. I2ebench: A comprehensive benchmark for instruction- based image editing. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors,Advances in Neural Information Processing Sys- tems, volume 37, pages 4149...
2024
-
[32]
Sdedit: Guided image synthesis and editing with stochastic differential equations,
Chenlin Meng, Yutong He, Yang Song, Jiaming Song, Jiajun Wu, Jun-Yan Zhu, and Stefano Ermon. Sdedit: Guided image synthesis and editing with stochastic differential equations,
-
[33]
URLhttps://arxiv.org/abs/2108.01073
-
[34]
Introducing GPT-4.1 in the API, 2025
OpenAI. Introducing GPT-4.1 in the API, 2025. URLhttps://openai.com/index/ gpt-4-1/
2025
-
[35]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 4195–4205, October 2023
2023
-
[36]
High-resolution image synthesis with latent diffusion models, 2022
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models, 2022. URLhttps://arxiv. org/abs/2112.10752
Pith/arXiv arXiv 2022
-
[37]
Proximal policy optimization algorithms, 2017
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms, 2017. URLhttps://arxiv.org/abs/1707.06347
Pith/arXiv arXiv 2017
-
[38]
High- dimensional continuous control using generalized advantage estimation, 2018
John Schulman, Philipp Moritz, Sergey Levine, Michael Jordan, and Pieter Abbeel. High- dimensional continuous control using generalized advantage estimation, 2018. URLhttps: //arxiv.org/abs/1506.02438. 12
Pith/arXiv arXiv 2018
-
[39]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models, 2024. URLhttps://arxiv.org/abs/ 2402.03300
Pith/arXiv arXiv 2024
-
[40]
Emu edit: Precise image editing via recognition and generation tasks
Shelly Sheynin, Adam Polyak, Uriel Singer, Yuval Kirstain, Amit Zohar, Oron Ashual, Devi Parikh, and Yaniv Taigman. Emu edit: Precise image editing via recognition and generation tasks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion (CVPR), pages 8871–8879, June 2024
2024
-
[41]
Seededit: Align image re-generation to image editing, 2024
Yichun Shi, Peng Wang, and Weilin Huang. Seededit: Align image re-generation to image editing, 2024. URLhttps://arxiv.org/abs/2411.06686
arXiv 2024
-
[42]
Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole
Yang Song, Jascha Sohl-Dickstein, Diederik P. Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations, 2021. URLhttps://arxiv.org/abs/2011.13456
Pith/arXiv arXiv 2021
-
[43]
Diffusion model alignment us- ing direct preference optimization
Bram Wallace, Meihua Dang, Rafael Rafailov, Linqi Zhou, Aaron Lou, Senthil Purushwalkam, Stefano Ermon, Caiming Xiong, Shafiq Joty, and Nikhil Naik. Diffusion model alignment us- ing direct preference optimization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 8228–8238, June 2024
2024
-
[44]
Omniedit: Building image editing generalist models through specialist supervision
Cong Wei, Zheyang Xiong, Weiming Ren, Xeron Du, Ge Zhang, and Wenhu Chen. Omniedit: Building image editing generalist models through specialist supervision. InThe Thirteenth International Conference on Learning Representations, 2025. URLhttps://openreview. net/forum?id=Hlm0cga0sv
2025
-
[45]
Omnigen2: Towards instruction-aligned multimodal generation, 2026
Chenyuan Wu, Pengfei Zheng, Ruiran Yan, Shitao Xiao, Xin Luo, Yueze Wang, Wanli Li, Xiyan Jiang, Yexin Liu, Junjie Zhou, Ze Liu, Ziyi Xia, Chaofan Li, Haoge Deng, Jiahao Wang, Kun Luo, Bo Zhang, Defu Lian, Xinlong Wang, Zhongyuan Wang, Tiejun Huang, and Zheng Liu. Omnigen2: Towards instruction-aligned multimodal generation, 2026. URLhttps: //arxiv.org/abs...
Pith/arXiv arXiv 2026
-
[46]
Editreward: A human-aligned reward model for instruction-guided image editing, 2026
Keming Wu, Sicong Jiang, Max Ku, Ping Nie, Minghao Liu, and Wenhu Chen. Editreward: A human-aligned reward model for instruction-guided image editing, 2026. URLhttps: //arxiv.org/abs/2509.26346
arXiv 2026
-
[47]
Xiaoshi Wu, Yiming Hao, Keqiang Sun, Yixiong Chen, Feng Zhu, Rui Zhao, and Hongsheng Li. Human preference score v2: A solid benchmark for evaluating human preferences of text- to-image synthesis, 2023. URLhttps://arxiv.org/abs/2306.09341
Pith/arXiv arXiv 2023
-
[48]
Imagereward: Learning and evaluating human preferences for text-to-image gen- eration
Jiazheng Xu, Xiao Liu, Yuchen Wu, Yuxuan Tong, Qinkai Li, Ming Ding, Jie Tang, and Yux- iao Dong. Imagereward: Learning and evaluating human preferences for text-to-image gen- eration. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors, Advances in Neural Information Processing Systems, volume 36, pages 15903–15935. Curran Ass...
2023
-
[49]
Dancegrpo: Unleashing grpo on visual generation, 2025
Zeyue Xue, Jie Wu, Yu Gao, Fangyuan Kong, Lingting Zhu, Mengzhao Chen, Zhiheng Liu, Wei Liu, Qiushan Guo, Weilin Huang, and Ping Luo. Dancegrpo: Unleashing grpo on visual generation, 2025. URLhttps://arxiv.org/abs/2505.07818
Pith/arXiv arXiv 2025
-
[50]
Joint reward modeling: Internalizing chain-of-thought for efficient visual reward models, 2026
Yankai Yang, Yancheng Long, Hongyang Wei, Wei Chen, Tianke Zhang, Kaiyu Jiang, Haonan Fan, Changyi Liu, Jiankang Chen, Kaiyu Tang, Bin Wen, Fan Yang, Tingting Gao, Han Li, and Shuo Yang. Joint reward modeling: Internalizing chain-of-thought for efficient visual reward models, 2026. URLhttps://arxiv.org/abs/2602.07533
Pith/arXiv arXiv 2026
-
[51]
Imgedit: A unified image editing dataset and benchmark, 2025
Yang Ye, Xianyi He, Zongjian Li, Bin Lin, Shenghai Yuan, Zhiyuan Yan, Bohan Hou, and Li Yuan. Imgedit: A unified image editing dataset and benchmark, 2025. URLhttps:// arxiv.org/abs/2505.20275. 13
Pith/arXiv arXiv 2025
-
[52]
Dapo: An open-source llm reinforcement learning system at scale, 2025
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Wang Zhang, Hang Zhu, Jinhua Zhu, Jiaze Chen, Jiangjie Chen, Chengyi Wang, Hongli Yu, Yuxuan Song, Xiangpeng Wei, Hao Zhou, Jingjing Liu, W...
Pith/arXiv arXiv 2025
-
[53]
Magicbrush: A man- ually annotated dataset for instruction-guided image editing
Kai Zhang, Lingbo Mo, Wenhu Chen, Huan Sun, and Yu Su. Magicbrush: A man- ually annotated dataset for instruction-guided image editing. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural In- formation Processing Systems, volume 36, pages 31428–31449. Curran Associates, Inc.,
-
[54]
URLhttps://proceedings.neurips.cc/paper_files/paper/2023/file/ 64008fa30cba9b4d1ab1bd3bd3d57d61-Paper-Datasets_and_Benchmarks.pdf
2023
-
[55]
Haozhe Zhao, Xiaojian Ma, Liang Chen, Shuzheng Si, Rujie Wu, Kaikai An, Peiyu Yu, Minjia Zhang, Qing Li, and Baobao Chang. Ultraedit: Instruction-based fine- grained image editing at scale. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors,Advances in Neural Information Pro- cessing Systems, volume 37, pages 305...
-
[56]
score_success: how well the edit follows the instruction (0=no change, 25=perfect)
-
[57]
Change the man’s shirt to red and add a tree in the background
score_preserve: degree of preservation within the region (0=completely different, 25=minimal effective edit). BACKGROUND (0–25): Rate how well non-edited areas are preserved. Penalize unexpected edits, layout changes, artifacts outside editing regions. OVERALL (0–25): Overall success score and overall overediting score. The prompt has three key design ele...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.