Learning to Recover Task Experts from a Multi-Task Merged Model
Pith reviewed 2026-06-26 04:58 UTC · model grok-4.3
The pith
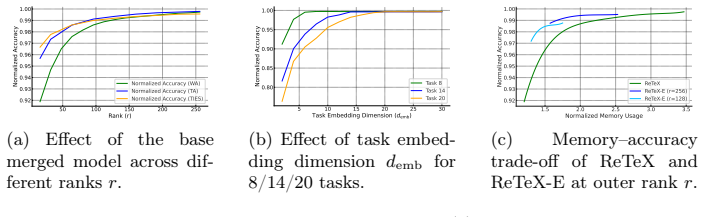
By predicting additive offsets from a merged checkpoint, ReTeX recovers over 95 percent of each task expert's original performance from a single model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
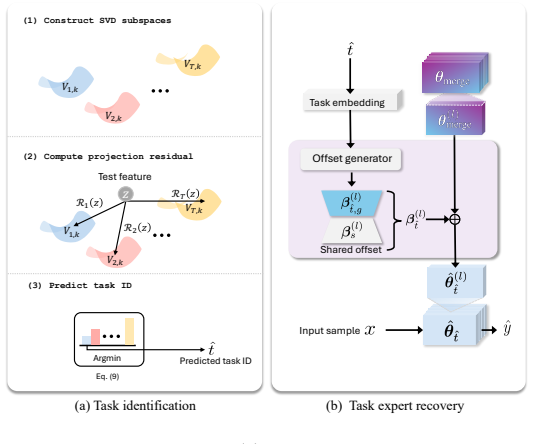
Parameter interference during merging is modeled as an affine transformation that reduces to an additive offset; a network trained to predict the offset from the merged weights alone can restore each original expert, while an offline SVD-based identifier selects the correct expert at inference without a learned router.
What carries the argument
ReTeX offset predictor that maps merged weights to task-specific additive corrections, paired with SVD subspace signatures for task identification.
If this is right
- A single merged checkpoint supports near-expert accuracy on every training task without redundant storage.
- The same checkpoint generalizes better to tasks absent from the original merge set.
- Offset prediction produces automatic interpolation among seen experts when the input lies outside the training distribution.
- Task identity at inference is obtained from projection residuals onto precomputed SVD subspaces rather than a separate router network.
Where Pith is reading between the lines
- Deployment cost for multi-task systems could drop because only one set of weights needs to be kept in memory.
- The SVD identifier might transfer to other merging algorithms that do not explicitly train routers.
- If offset prediction scales to very large models, it could serve as a lightweight post-merge adaptation step.
- The emergent interpolation behavior suggests the method might support zero-shot composition of task knowledge.
Load-bearing premise
The changes each expert undergoes when merged can be reversed by learning a simple additive correction that depends only on the final merged weights.
What would settle it
Measure whether the offset predictor still recovers 95 percent performance when the merging procedure is changed to a method whose perturbations deviate from the assumed affine form.
Figures

read the original abstract
Multi-task model merging aims to consolidate several task-specific experts into a unified model, yet static merging consistently suffers from parameter interference. While dynamic merging models aim to bridge this gap, many works rely on the costly storage and loading of redundant expert components at inference. In this work, from the perspective of task expert, we view parameter interference as parameter perturbation introduced to each expert during merging process. We show that such parameter perturbations can be modeled as affine transformation, which can be approximated as additive offsets. Motivated by these, we propose Recover Task eXpert (ReTeX), a framework that predicts those offsets, in order to undo parameter interference and recover task-expert performance from a single merged checkpoint. To recover the appropriate expert when task identity is unknown, we introduce a router-free task identifier based on SVD subspace signatures computed offline before inference. At inference, the identifier selects the task whose subspace yields the smallest projection residual for a given input. As a result, ReTeX recovers over 95% of individual-expert performance in both vision and NLP domains, while significantly improving generalization to unseen tasks. Crucially, we also show that the parameter offset prediction leads to emergent adaptive interpolation of expert knowledge for out-of-distribution (OOD) tasks. ReTeX adaptively interpolates seen expert knowledge to handle unseen tasks. Our code is available at https://github.com/BAIKLAB/ReTeX
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ReTeX, a framework that models merging-induced parameter perturbations on task experts as affine transformations approximable by additive offsets, predicts these offsets from the merged checkpoint alone to recover individual expert performance, and employs an SVD-based subspace signature method for router-free task identification at inference. It reports recovering over 95% of per-expert performance on vision and NLP tasks while achieving improved generalization to unseen tasks via emergent adaptive interpolation of expert knowledge.
Significance. If the affine-to-additive modeling assumption is validated with quantitative bounds and the recovery results prove robust across baselines and tasks, the approach would offer a practical route to high-fidelity multi-task inference from a single checkpoint, reducing the storage overhead of dynamic merging methods while providing a mechanism for OOD task handling without retraining.
major comments (3)
- [Abstract] Abstract: the central modeling claim that merging perturbations can be represented as affine maps and then approximated as additive offsets is asserted without derivation, without a quantitative bound on residual error after the best additive fit, and without empirical validation of approximation quality; this assumption is load-bearing for the recovery performance claim.
- [Abstract] Abstract: the headline result of >95% recovery of individual-expert performance is stated without reference to the number of tasks, datasets, baselines, statistical error bars, or verification protocol, preventing assessment of whether the offset predictor genuinely undoes interference or merely learns a compensatory adapter.
- [Abstract] Abstract / method description: the SVD subspace signature task identifier is introduced at a high level with no detail on subspace construction, dimensionality, or how projection residuals are computed and thresholded; because this component is required for the router-free claim, its correctness directly affects the reported inference results.
minor comments (2)
- [Abstract] The abstract would benefit from a concise statement of the number of tasks, domains, and primary baselines used to support the 95% recovery figure.
- Notation for the merged weights, expert weights, and predicted offsets should be introduced consistently and early to aid readability of the recovery equations.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on the abstract and method presentation. We will revise the manuscript to incorporate the requested derivations, quantitative details, experimental specifics, and method expansions while preserving the core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central modeling claim that merging perturbations can be represented as affine maps and then approximated as additive offsets is asserted without derivation, without a quantitative bound on residual error after the best additive fit, and without empirical validation of approximation quality; this assumption is load-bearing for the recovery performance claim.
Authors: We agree the abstract presents the claim at a high level. We will add an explicit derivation of the affine transformation model from the merging process, a quantitative bound on the residual error after the additive fit, and empirical validation of approximation quality to the revised manuscript (new subsection in Section 3), with a concise reference included in the abstract. revision: yes
-
Referee: [Abstract] Abstract: the headline result of >95% recovery of individual-expert performance is stated without reference to the number of tasks, datasets, baselines, statistical error bars, or verification protocol, preventing assessment of whether the offset predictor genuinely undoes interference or merely learns a compensatory adapter.
Authors: We will revise the abstract to specify the number of tasks and datasets, the baselines used, statistical error bars from repeated runs, and the verification protocol (performance measured against individually fine-tuned experts on held-out data). This will clarify the nature of the recovery. revision: yes
-
Referee: [Abstract] Abstract / method description: the SVD subspace signature task identifier is introduced at a high level with no detail on subspace construction, dimensionality, or how projection residuals are computed and thresholded; because this component is required for the router-free claim, its correctness directly affects the reported inference results.
Authors: We will expand the method description to detail subspace construction (via SVD on task-specific parameter matrices), chosen dimensionality, projection residual computation (norm of the component orthogonal to the subspace), and thresholding procedure. These specifics will be added to Section 3 and referenced in the abstract. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper frames ReTeX as a predictive framework that learns to approximate merging-induced perturbations (modeled as affine maps and approximated by additive offsets) from the merged checkpoint alone, then uses an independent SVD-based task identifier at inference. No equations or steps reduce a claimed prediction to a fitted quantity by construction, nor does any load-bearing premise rest on self-citation chains or imported uniqueness results. The offset-prediction step is presented as a learned mapping whose success is evaluated against held-out expert performance rather than being definitionally equivalent to its inputs. The derivation therefore retains independent empirical content.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Parameter perturbations during merging can be modeled as affine transformations approximable as additive offsets
invented entities (1)
-
recoverable parameter offsets
no independent evidence
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2303.08774 (2023)
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F.L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al.: Gpt-4 technical report. arXiv preprint arXiv:2303.08774 (2023)
Pith/arXiv arXiv 2023
-
[2]
In: ICCCSP (2021)
Ahmed, M.I., Mamun, S.M., Asif, A.U.Z.: Dcnn-based vegetable image classifica- tion using transfer learning: A comparative study. In: ICCCSP (2021)
2021
-
[3]
Data in Brief (2023)
Ahmed, S.I., Ibrahim, M., Nadim, M., Rahman, M.M., Shejunti, M.M., Jabid, T., Ali, M.S.: Mangoleafbd: A comprehensive image dataset to classify diseased and healthy mango leaves. Data in Brief (2023)
2023
-
[4]
Alessio, C.: Animals-10.https : / / www . kaggle . com / datasets / alessiocorrado99/animals10
-
[5]
In: ICCV (2021)
Baik, S., Choi, J., Kim, H., Cho, D., Min, J., Lee, K.M.: Meta-learning with task-adaptive loss function for few-shot learning. In: ICCV (2021)
2021
-
[6]
In: NeurIPS (2020)
Baik, S., Choi, M., Choi, J., Kim, H., Lee, K.M.: Meta-learning with adaptive hyperparameters. In: NeurIPS (2020)
2020
-
[7]
IEEE Transactions on Pattern Analysis and Machine Intelligence (2024)
Baik, S., Choi, M., Choi, J., Kim, H., Lee, K.M.: Learning to learn task-adaptive hyperparameters for few-shot learning. IEEE Transactions on Pattern Analysis and Machine Intelligence (2024)
2024
-
[8]
In: CVPR (2020)
Baik, S., Hong, S., Lee, K.M.: Learning to forget for meta-learning. In: CVPR (2020)
2020
-
[9]
IEEE Transactions on Pattern Analysis and Machine Intelligence (2022)
Baik, S., Hong, S., Lee, K.M.: Learning to forget for meta-learning via task- and-layer-wise attenuation. IEEE Transactions on Pattern Analysis and Machine Intelligence (2022)
2022
-
[10]
Available on https://www
Bansal, P.: Intel image classification. Available on https://www. kaggle. com/puneet6060/intel-image-classification, Online (2019)
2019
-
[11]
In: WACV (2022)
Bateni, P., Barber, J., Van de Meent, J.W., Wood, F.: Enhancing few-shot image classification with unlabelled examples. In: WACV (2022)
2022
-
[12]
In: CVPR (2020)
Bateni, P., Goyal, R., Masrani, V., Wood, F., Sigal, L.: Improved few-shot visual classification. In: CVPR (2020)
2020
-
[13]
In: ECCV (2014)
Bossard, L., Guillaumin, M., Gool, L.V.: Food-101 – mining discriminative com- ponents with random forests. In: ECCV (2014)
2014
-
[14]
https://doi.org/10.34740/KAGGLE/DS/81794
CCHANG: Garbage classification.https://www.kaggle.com/ds/81794(2018). https://doi.org/10.34740/KAGGLE/DS/81794
-
[15]
Proceedings of the IEEE (2017)
Cheng, G., Han, J., Lu, X.: Remote sensing image scene classification: Benchmark and state of the art. Proceedings of the IEEE (2017)
2017
-
[16]
In: CVPR
Chi, Y., Porikli, F.: Connecting the dots in multi-class classification: From nearest subspace to collaborative representation. In: CVPR. pp. 3602–3609 (2012)
2012
-
[17]
IEEE Access (2022)
Choi, J., Baik, S., Choi, M., Kwon, J., Lee, K.M.: Visual tracking by adaptive continual meta-learning. IEEE Access (2022)
2022
-
[18]
In: CVPR (2020)
Choi, M., Choi, J., Baik, S., Kim, T.H., Lee, K.M.: Scene-adaptive video frame interpolation via meta-learning. In: CVPR (2020)
2020
-
[19]
IEEE Transactions on Pattern Analysis and Machine Intelligence (2022)
Choi, M., Choi, J., Baik, S., Kim, T.H., Lee, K.M.: Test-time adaptation for video frame interpolation via meta-learning. IEEE Transactions on Pattern Analysis and Machine Intelligence (2022)
2022
-
[20]
In: CVPR (2020)
Choi, Y., Uh, Y., Yoo, J., Ha, J.W.: Stargan v2: Diverse image synthesis for multiple domains. In: CVPR (2020)
2020
-
[21]
In: CVPR (2014)
Cimpoi, M., Maji, S., Kokkinos, I., Mohamed, S., Vedaldi, A.: Describing textures in the wild. In: CVPR (2014)
2014
-
[22]
In: NeurIPS (2018)
Clanuwat, T., Bober-Irizar, M., Kitamoto, A., Lamb, A., Yamamoto, K., Ha, D.: Deep learning for classical japanese literature. In: NeurIPS (2018)
2018
-
[23]
In: AISTATS (2011)
Coates, A., Ng, A., Lee, H.: An analysis of single-layer networks in unsupervised feature learning. In: AISTATS (2011)
2011
-
[24]
In: IJCNN (2017)
Cohen, G., Afshar, S., Tapson, J., van Schaik, A.: Emnist: Extending mnist to handwritten letters. In: IJCNN (2017)
2017
-
[25]
Journal of Diabetes Science and Technology (2009)
Cuadros, J., Bresnick, G.: Eyepacs: An adaptable telemedicine system for diabetic retinopathy screening. Journal of Diabetes Science and Technology (2009)
2009
-
[26]
cats, 2013
Cukierski, W.: Dogs vs. cats, 2013. URL https://kaggle.com/competitions/dogs- vs-cats
2013
-
[27]
In: ECCV (2024)
Davari, M., Belilovsky, E.: Model breadcrumbs: Scaling multi-task model merging with sparse masks. In: ECCV (2024)
2024
-
[28]
DeepNets: Landscape recognition.https : / / www . kaggle . com / datasets / utkarshsaxenadn/landscape-recognition-image-dataset-12k-images
-
[29]
IEEE signal processing magazine (2012)
Deng, L.: The mnist database of handwritten digit images for machine learning research [best of the web]. IEEE signal processing magazine (2012)
2012
-
[30]
Nature Machine Intelligence (2023)
Ding, N., Qin, Y., Yang, G., Wei, F., Yang, Z., Su, Y., Hu, S., Chen, Y., Chan, C.M., Chen, W., et al.: Parameter-efficient fine-tuning of large-scale pre-trained language models. Nature Machine Intelligence (2023)
2023
-
[31]
Computer Vision and Image Understanding (2007)
Fei-Fei, L., Fergus, R., Perona, P.: Learning generative visual models from few training examples: An incremental bayesian approach tested on 101 object cate- gories. Computer Vision and Image Understanding (2007)
2007
-
[32]
In: ICLR (2017)
Finn, C., Abbeel, P., Levine, S.: Model-agnostic meta-learning for fast adaptation of deep networks. In: ICLR (2017)
2017
-
[33]
In: CVPR (2025)
Gargiulo, A.A., Crisostomi, D., Bucarelli, M.S., Scardapane, S., Silvestri, F., Rodolà, E.: Task singular vectors: Reducing task interference in model merging. In: CVPR (2025)
2025
-
[34]
In: ICONIP (2013)
Goodfellow, I.J., Erhan, D., Carrier, P.L., Courville, A., Mirza, M., Hamner, B., Cukierski, W., Tang, Y., Thaler, D., Lee, D.H., Zhou, Y., Ramaiah, C., Feng, F., Li, R., Wang, X., Athanasakis, D., Shawe-Taylor, J., Milakov, M., Park, J., Ionescu, R., Popescu, M., Grozea, C., Bergstra, J., Xie, J., Romaszko, L., Xu, B., Chuang, Z., Bengio, Y.: Challenges ...
2013
-
[35]
Griffin, G., Holub, A., Perona, P.: Caltech-256 object category dataset. Tech. rep., California Institute of Technology (2007)
2007
-
[36]
In: ICLR (2017)
Ha, D., Dai, A.M., Le, Q.V.: Hypernetworks. In: ICLR (2017)
2017
-
[37]
IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing (2019)
Helber, P., Bischke, B., Dengel, A., Borth, D.: Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing (2019)
2019
-
[38]
In: CVPR (2015)
Horn, G.V., Branson, S., Farrell, R., Haber, S., Barry, J., Ipeirotis, P., Perona, P., Belongie, S.: Building a bird recognition app and large scale dataset with citizen scientists: The fine print in fine-grained dataset collection. In: CVPR (2015)
2015
-
[39]
Howard, J.: Imagenette: A smaller subset of 10 easily classified classes from ima- genet.https://github.com/fastai/imagenette(2019)
2019
-
[40]
In: ICLR (2022)
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W.: Lora: Low-rank adaptation of large language models. In: ICLR (2022)
2022
-
[41]
In: NeurIPS (2024)
Huang, C., Ye, P., Chen, T., He, T., Yue, X., Ouyang, W.: Emr-merging: Tuning- free high-performance model merging. In: NeurIPS (2024)
2024
-
[42]
In: ICLR (2023)
Ilharco, G., Ribeiro, M.T., Wortsman, M., Schmidt, L., Hajishirzi, H., Farhadi, A.: Editing models with task arithmetic. In: ICLR (2023)
2023
-
[43]
In: ICLR (2025)
Iurada, L., Ciccone, M., Tommasi, T.: Efficient model editing with task-localized sparse fine-tuning. In: ICLR (2025)
2025
-
[44]
In: ICLR (2023)
Jin, X., Ren, X., Preotiuc-Pietro, D., Cheng, P.: Dataless knowledge fusion by merging weights of language models. In: ICLR (2023)
2023
-
[45]
In: ICLR (2025)
Kang, J., Karlinsky, L., Luo, H., Wang, Z., Hansen, J., Glass, J., Cox, D., Panda, R., Feris, R., Ritter, A.: Self-moe: Towards compositional large language models with self-specialized experts. In: ICLR (2025)
2025
-
[46]
Cell (2018)
Kermany,D.S.,Goldbaum,M.,Cai,W.,Valentim,C.C.S.,Liang,H.,Baxter,S.L., McKeown, A., Yang, G., Wu, X., Yan, F., Dong, J., Prasadha, M., Pei, J., Ting, M., Zhu, J., Li, C., Hewett, S., Dong, J., Ziyar, I., Shi, A., Zhang, R., Gupta, K., Wong, R.M.Y., Lam, L.A.T.C., Cheung, J., Tsoi, M., Wu, V., Yan, C., Huang, C., Lee, D.H., Zhang, Y., Wong, J.W., Li, K.M., ...
2018
-
[47]
In: CVPR (2011)
Khosla, A., Jayadevaprakash, N., Yao, B., Fei-Fei, L.: Novel dataset for fine- grained image categorization. In: CVPR (2011)
2011
-
[48]
In: AAAI (2020)
Khot, T., Clark, P., Guerquin, M., Jansen, P., Sabharwal, A.: Qasc: A dataset for question answering via sentence composition. In: AAAI (2020)
2020
-
[49]
In: ICLR (2015)
Kingma, D.P.: Adam: A method for stochastic optimization. In: ICLR (2015)
2015
-
[50]
In: ICCV Workshop (2013)
Krause, J., Stark, M., Deng, J., Fei-Fei, L.: 3d object representations for fine- grained categorization. In: ICCV Workshop (2013)
2013
-
[51]
Krizhevsky, A., Hinton, G., et al.: Learning multiple layers of features from tiny images (2009)
2009
-
[52]
In: ECCV (2012)
Kumar, N., Belhumeur, P.N., Biswas, A., Jacobs, D.W., Kress, W.J., Lopez, I.C., Soares, J.V.B.: Leafsnap: A computer vision system for automatic plant species identification. In: ECCV (2012)
2012
-
[53]
com / AI - Lab - Makerere/ibean/
Lab, M.A.: Bean disease dataset (2020),https : / / github . com / AI - Lab - Makerere/ibean/
2020
-
[54]
In: ICLR (2025)
Lee, Y., Jung, J., Baik, S.: Mitigating parameter interference in model merging via sharpness-aware fine-tuning. In: ICLR (2025)
2025
-
[55]
In: KR (2012)
Levesque, H., Davis, E., Morgenstern, L.: The winograd schema challenge. In: KR (2012)
2012
-
[56]
In: ICLR (2024)
Li, P., Zhang, Z., Yadav, P., Sung, Y.L., Cheng, Y., Bansal, M., Chen, T.: Merge, then compress: Demystify efficient smoe with hints from its routing policy. In: ICLR (2024)
2024
-
[57]
In: CVPR (2017)
Li, S., Deng, W., Du, J.: Reliable crowdsourcing and deep locality-preserving learning for expression recognition in the wild. In: CVPR (2017)
2017
-
[58]
In: CVPR (2022)
Li, W.H., Liu, X., Bilen, H.: Cross-domain few-shot learning with task-specific adapters. In: CVPR (2022)
2022
-
[59]
arXiv preprint arXiv:2206.11404 (2022)
Liao, P., Li, X., Liu, X., Keutzer, K.: The artbench dataset: Benchmarking gen- erative models with artworks. arXiv preprint arXiv:2206.11404 (2022)
arXiv 2022
-
[60]
In: NeurIPS (2024)
Lu, Z., Fan, C., Wei, W., Qu, X., Chen, D., Cheng, Y.: Twin-merging: Dynamic integration of modular expertise in model merging. In: NeurIPS (2024)
2024
-
[61]
arXiv preprint arXiv:1306.5151 (2013)
Maji, S., Rahtu, E., Kannala, J., Blaschko, M., Vedaldi, A.: Fine-grained visual classification of aircraft. arXiv preprint arXiv:1306.5151 (2013)
Pith/arXiv arXiv 2013
-
[62]
and Raffel, C.A.: Merging models with fisher-weighted aver- aging
Matena, Michael S. and Raffel, C.A.: Merging models with fisher-weighted aver- aging. In: NeurIPS (2022)
2022
-
[63]
Frontiers in Plant Science (2016)
Mohanty, S.P., Hughes, D.P., Salathé, M.: Using deep learning for image-based plant disease detection. Frontiers in Plant Science (2016)
2016
-
[64]
Transactions on Machine Learning Research (2023)
Muqeeth, M., Liu, H., Raffel, C.: Soft merging of experts with adaptive routing. Transactions on Machine Learning Research (2023)
2023
-
[65]
Acta Universitatis Sapientiae, Informatica (2018)
Muresan, H., Oltean, M.: Fruit recognition from images using deep learning. Acta Universitatis Sapientiae, Informatica (2018)
2018
-
[66]
Nagaraj, A.: Asl alphabet.https://www.kaggle.com/datasets/grassknoted/ asl-alphabet
-
[67]
In: NIPS Workshop (2011)
Netzer, Y., Wang, T., Coates, A., Bissacco, A., Wu, B., Ng, A.Y., et al.: Reading digits in natural images with unsupervised feature learning. In: NIPS Workshop (2011)
2011
-
[68]
In: ICVGIP (2008)
Nilsback, M.E., Zisserman, A.: Automated flower classification over a large num- ber of classes. In: ICVGIP (2008)
2008
-
[69]
In: ICLR (2025)
Oh, C., Li, Y., Song, K., Yun, S., Han, D.: Dawin: Training-free dynamic weight interpolation for robust adaptation. In: ICLR (2025)
2025
-
[70]
Scientific Reports (2019)
Olsen, A., Konovalov, D.A., Philippa, B., Ridd, P., Wood, J.C., Johns, J., Banks, W.,Girgenti,B.,Kenny,O.,Whinney,J.,Calvert,B.,RahimiAzghadi,M.,White, R.D.: Deepweeds: A multiclass weed species image dataset for deep learning. Scientific Reports (2019)
2019
-
[71]
In: NeurIPS (2023)
Ortiz-Jimenez, G., Favero, A., Frossard, P.: Task arithmetic in the tangent space: Improved editing of pre-trained models. In: NeurIPS (2023)
2023
-
[72]
In: CVPR (2012)
Parkhi, O.M., Vedaldi, A., Zisserman, A., Jawahar, C.V.: Cats and dogs. In: CVPR (2012)
2012
-
[73]
In: AAAI (2018)
Perez, E., Strub, F., De Vries, H., Dumoulin, V., Courville, A.: Film: Visual reasoning with a general conditioning layer. In: AAAI (2018)
2018
-
[74]
In: ACM MMSys (2017)
Pogorelov, K., Randel, K.R., Griwodz, C., Eskeland, S.L., de Lange, T., Johansen, D., Spampinato, C., Dang-Nguyen, D.T., Lux, M., Schmidt, P.T., et al.: Kvasir: A multi-class image dataset for computer aided gastrointestinal disease detection. In: ACM MMSys (2017)
2017
-
[75]
In: CVPR (2009)
Quattoni, A., Torralba, A.: Recognizing indoor scenes. In: CVPR (2009)
2009
-
[76]
In: ICML (2021)
Radford,A.,Kim,J.W.,Hallacy,C.,Ramesh,A.,Goh,G.,Agarwal,S.,Sastry,G., Askell, A., Mishkin, P., Clark, J., Krueger, G., Sutskever, I.: Learning transferable visual models from natural language supervision. In: ICML (2021)
2021
-
[77]
In: NeurIPS (2019)
Requeima, J., Gordon, J., Bronskill, J., Nowozin, S., Turner, R.E.: Fast and flexible multi-task classification using conditional neural adaptive processes. In: NeurIPS (2019)
2019
-
[78]
arXiv preprint arXiv:2404.18416 (2024)
Saab, K., Tu, T., Weng, W.H., Tanno, R., Stutz, D., Wulczyn, E., Zhang, F., Strother,T.,Park,C.,Vedadi,E.,etal.:Capabilitiesofgeminimodelsinmedicine. arXiv preprint arXiv:2404.18416 (2024)
Pith/arXiv arXiv 2024
-
[79]
In: AAAI (2020)
Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. In: AAAI (2020)
2020
-
[80]
In: ACL (2018)
Sharma, R., Allen, J., Bakhshandeh, O., Mostafazadeh, N.: Tackling the story ending biases in the story cloze test. In: ACL (2018)
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.