CORTEX: A Structured Reasoning Benchmark for Trustworthy 3D Chest CT MLLMs
Pith reviewed 2026-06-26 05:37 UTC · model grok-4.3
The pith
CORTEX adds four-stage reasoning traces to chest CT questions to support training and verification of trustworthy MLLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
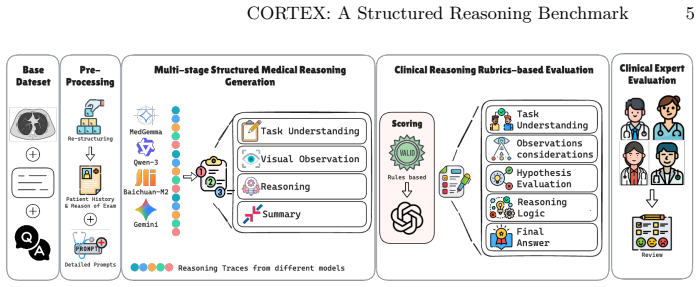
CORTEX is a structured reasoning benchmark for 3D chest CT that restores the missing reasoning to questions from an existing dataset by providing four-stage diagnostic traces mirroring a radiologist's workflow. These traces are generated using frontier large language models and then filtered and verified with a stage-level evaluation protocol that combines automated rubric scoring with expert radiologist review. The benchmark includes 76,177 validated traces across open-ended VQA, closed-ended VQA, and report generation, supplying both the structured supervision needed to train trustworthy reasoning models and the protocol needed to verify their reasoning.
What carries the argument
The four-stage diagnostic trace consisting of task understanding, visual observation, diagnostic reasoning, and answer synthesis, which structures the reasoning and supports stage-by-stage evaluation.
Load-bearing premise
Large language models with medical knowledge can produce traces that accurately reflect radiologist reasoning workflows, and the automated rubric combined with expert review can reliably validate them at this scale.
What would settle it
Independent radiologists examining a sample of the generated traces discover a substantial number that do not match real clinical reasoning or contain inaccuracies missed by the validation protocol.
Figures

read the original abstract
Reasoning in multimodal large language models (MLLMs) has shown strong promise in medical imaging. However, this reasoning is usually free-form text judged only by its final answer, making it hard to interpret and verify, especially in 3D radiology, where a diagnosis should be traceable to evidence in the scan. Existing chest CT question-answering datasets compound this by reducing expert radiology reports to answer-only pairs, dropping the reasoning that links findings to conclusions and omitting the patient history clinicians rely on. As a result, reasoning-capable 3D chest CT MLLMs remain out of reach, as neither the structured supervision needed to train them nor the protocol needed to verify their reasoning yet exists. We introduce CORTEX (Clinically Organized Reasoning and sTructured EXplanation), a structured reasoning benchmark for 3D chest CT. For each question, CORTEX restores the missing reasoning as a four-stage diagnostic trace mirroring a radiologist's workflow: task understanding, visual observation, diagnostic reasoning, and answer synthesis. We generate these traces using frontier large language models with broad medical and general-domain knowledge, then filter and verify them with a stage-level evaluation protocol combining automated rubric scoring with expert radiologist review. Crucially, both the reasoning structure and evaluation rubrics are designed in close collaboration with clinicians. Built on CT-RATE, a large, publicly available chest CT dataset without reasoning annotations, CORTEX comprises 76,177 validated reasoning traces across open-ended VQA, closed-ended VQA, and report generation, providing both the structured supervision and the stage-level evaluation protocol needed to build and evaluate trustworthy reasoning models for 3D chest CT. Our dataset and evaluation code will be made publicly available upon acceptance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CORTEX, a benchmark of 76,177 four-stage structured diagnostic reasoning traces (task understanding, visual observation, diagnostic reasoning, answer synthesis) for 3D chest CT VQA and report generation. Traces are generated by frontier LLMs on the CT-RATE dataset and filtered/validated via a clinician-designed stage-level automated rubric plus expert radiologist review, supplying both structured supervision for training and a protocol for evaluating trustworthy reasoning in medical MLLMs.
Significance. If the traces are shown to faithfully mirror radiologist workflows, the dataset would address a clear gap in existing chest CT QA resources by restoring the reasoning steps and patient context that current answer-only pairs omit, thereby enabling more interpretable and verifiable 3D radiology MLLMs.
major comments (1)
- [Abstract and trace generation/verification process] The central claim that the 76k traces accurately mirror radiologist workflow (Abstract) rests on LLM generation plus automated rubric + expert review. No control arm is described in which independent radiologists author traces for the identical questions under the same four-stage protocol, so no measured concordance, inter-rater agreement, or systematic deviation between LLM and human reasoning is reported. Expert review can confirm surface plausibility but cannot establish fidelity to clinical practice.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive review. The major comment raises an important point about validation methodology that we address directly below.
read point-by-point responses
-
Referee: [Abstract and trace generation/verification process] The central claim that the 76k traces accurately mirror radiologist workflow (Abstract) rests on LLM generation plus automated rubric + expert review. No control arm is described in which independent radiologists author traces for the identical questions under the same four-stage protocol, so no measured concordance, inter-rater agreement, or systematic deviation between LLM and human reasoning is reported. Expert review can confirm surface plausibility but cannot establish fidelity to clinical practice.
Authors: We agree that the manuscript does not include a control arm in which independent radiologists author traces under the identical four-stage protocol, and therefore does not report quantitative concordance, inter-rater agreement, or systematic differences between LLM-generated and human-authored reasoning. The current validation protocol combines a clinician-designed stage-level automated rubric with expert radiologist review to assess adherence to the prescribed structure and clinical plausibility. While this approach was developed in close collaboration with clinicians to align with standard diagnostic workflows, it cannot substitute for a direct head-to-head comparison. We will revise the manuscript to (1) explicitly state this limitation in the Discussion section, (2) clarify that the traces are presented as structured supervision signals rather than as proven equivalents to radiologist reasoning, and (3) provide additional detail on the expert review process and rubric design. A full inter-rater study with radiologist-authored traces would require resources beyond the scope of the present work. revision: partial
Circularity Check
No significant circularity; dataset construction with external verification
full rationale
The paper presents a benchmark dataset construction process: LLM-generated four-stage diagnostic traces on CT-RATE images, filtered via clinician-designed automated rubrics plus expert radiologist review. No equations, parameter fitting, predictions, or derivations are claimed. No self-citations are load-bearing for any central result. The work is self-contained via external clinician collaboration and verification rather than internal reduction to its own inputs. This matches the default expectation of no circularity for non-derivational dataset papers.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Frontier LLMs possess sufficient medical and general-domain knowledge to generate clinically accurate four-stage diagnostic traces from CT-RATE data.
- domain assumption The stage-level evaluation protocol combining automated rubric scoring with expert radiologist review is adequate to produce validated traces.
Reference graph
Works this paper leans on
-
[1]
Advances in neural information processing systems33, 1877–1901 (2020)
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J.D., Dhariwal, P., Nee- lakantan, A., Shyam, P., Sastry, G., Askell, A., et al.: Language models are few-shot learners. Advances in neural information processing systems33, 1877–1901 (2020)
1901
-
[2]
arXiv preprint (2024)
Chen, H., et al.: 3d-ct-gpt++: Enhancing 3d radiology report generation with direct preference optimization and large vision-language models. arXiv preprint (2024)
2024
-
[3]
arXiv preprint arXiv:2509.19003 (2025)
Chen, H., Lou, X., Feng, X., Huang, K., Wang, X.: Unveiling chain of step reasoning for vision-language models with fine-grained rewards. arXiv preprint arXiv:2509.19003 (2025)
arXiv 2025
-
[4]
arXiv preprint arXiv:2510.10052 (2025)
Chen, K., Rui, S., Jiang, Y., Wu, J., Zheng, Q., Song, C., Wang, X., Zhou, M., Liu, M.: Think twice to see more: Iterative visual reasoning in medical vlms. arXiv preprint arXiv:2510.10052 (2025)
arXiv 2025
-
[5]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Chen, Q., Zhou, X., Liu, C., Chen, H., Li, W., Jiang, Z., Huang, Z., Zhao, Y., Yu, D., He, J., et al.: Scaling tumor segmentation: Best lessons from real and synthetic data. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 24001–24013 (2025)
2025
-
[6]
Harvard University Press (1978)
Elstein, A.S., Shulman, L.S., Sprafka, S.A.: Medical problem solving: An analysis of clinical reasoning. Harvard University Press (1978)
1978
-
[7]
In: International Conference on Medical Image Computing and Computer-Assisted Intervention
Hamamci, I.E., Er, S., Menze, B.: Ct2rep: Automated radiology report generation for 3d medical imaging. In: International Conference on Medical Image Computing and Computer-Assisted Intervention. pp. 476–486. Springer (2024)
2024
-
[8]
Advances in Neural Information Processing Systems (2025)
Hamamci, I.E., Er, S., Shit, S., Reynaud, H., Yang, D., Guo, P., Edgar, M., Xu, D., Kainz, B., Menze, B.: Better tokens for better 3d: Advancing vision-language mod- eling in 3d medical imaging. Advances in Neural Information Processing Systems (2025)
2025
-
[9]
arXiv preprint arXiv:2403.17834 (2024)
Hamamci, I.E., Er, S., Wang, C., Almas, F., Simsek, A.G., Esirgun, S.N., Do- gan, I., Durugol, O.F., Hou, B., Shit, S., et al.: Developing generalist foundation models from a multimodal dataset for 3d computed tomography. arXiv preprint arXiv:2403.17834 (2024)
arXiv 2024
-
[10]
In: Findings of the Association for Computational Linguistics: ACL 2023
Hsieh, C.Y., Li, C.L., Yeh, C.K., Nakhost, H., Fujii, Y., Ratner, A., Krishna, R., Lee,C.Y.,Pfister,T.:Distillingstep-by-step!outperforminglargerlanguagemodels with less training data and smaller model sizes. In: Findings of the Association for Computational Linguistics: ACL 2023. pp. 8003–8017 (2023)
2023
-
[11]
arXiv preprint arXiv:2508.17298 (2025)
Ke, F., Hsu, J., Cai, Z., Ma, Z., Zheng, X., Wu, X., Huang, S., Wang, W., Haghighi, P.D., Haffari, G., et al.: Explain before you answer: A survey on compositional visual reasoning. arXiv preprint arXiv:2508.17298 (2025)
arXiv 2025
-
[12]
arXiv preprint arXiv:2602.01200 (2026) 10 Malik and Hashmi et al
Lai, H., Jiang, Z., Zhang, K., Yao, Q., Wang, R., He, Z., Tao, X., Wei, W., Zhou, S.K.:Med3d-r1:Incentivizingclinicalreasoningin3dmedicalvision-languagemod- els for abnormality diagnosis. arXiv preprint arXiv:2602.01200 (2026) 10 Malik and Hashmi et al
arXiv 2026
-
[13]
Nature Communications16(1), 2258 (2025)
Li,C.Y.,Chang,K.J.,Yang,C.F.,Wu,H.Y.,Chen,W.,Bansal,H.,Chen,L.,Yang, Y.P., Chen, Y.C., Chen, S.P., et al.: Towards a holistic framework for multimodal llm in 3d brain ct radiology report generation. Nature Communications16(1), 2258 (2025)
2025
-
[14]
Advances in Neural In- formation Processing Systems36(2024)
Li, C., Wong, C., Zhang, S., Usuyama, N., et al.: Llava-med: Training a large language-and-vision assistant for biomedicine in one day. Advances in Neural In- formation Processing Systems36(2024)
2024
-
[15]
In: arXiv preprint arXiv:2506.17939 (2025)
Liu, B., et al.: Gemex-rmcot: An enhanced med-vqa dataset for region-aware mul- timodal chain-of-thought reasoning. In: arXiv preprint arXiv:2506.17939 (2025)
arXiv 2025
-
[16]
In: Findings of the Association for Computational Linguistics: ACL 2025
Liu, C., Wan, Z., Wang, Y., Shen, H., Wang, H., Zheng, K., Zhang, M., Arcucci, R.: Argus: benchmarking and enhancing vision-language models for 3d radiology report generation. In: Findings of the Association for Computational Linguistics: ACL 2025. pp. 16448–16460 (2025)
2025
-
[17]
Advances in neural information processing systems36, 34892–34916 (2023)
Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual instruction tuning. Advances in neural information processing systems36, 34892–34916 (2023)
2023
-
[18]
arXiv preprint arXiv:2605.08787 (2026)
Monon, M., Rahman, U., Hanif, A., Saeed, N., Yaqub, M.: Lost in volume: The ct- spatialvqa benchmark for evaluating semantic-spatial understanding of 3d medical vision-language models. arXiv preprint arXiv:2605.08787 (2026)
Pith/arXiv arXiv 2026
-
[19]
arXiv preprint arXiv:2605.10002 (2026)
Nguyen, M.K., Le, D.L., Jafari, A.R., Nguyen, T.D., Son, M.H., Thong, M.H., Nguyen, Q.H., Nguyen, T.T., Farahbakhsh, R., Crespi, N., et al.: Med-stepbench: A hierarchical reasoning framework for evaluating hallucinations in medical vision- language models. arXiv preprint arXiv:2605.10002 (2026)
Pith/arXiv arXiv 2026
-
[20]
arXiv preprint arXiv:2604.06756 (2026)
Tu, M., Ni, S., Bi, K.: How long reasoning chains influence llms’ judgment of answer factuality. arXiv preprint arXiv:2604.06756 (2026)
Pith/arXiv arXiv 2026
-
[21]
Nejm Ai1(3), AIoa2300138 (2024)
Tu, T., Azizi, S., Driess, D., Schaekermann, M., Amin, M., Chang, P.C., Carroll, A., Lau, C., Tanno, R., Ktena, I., et al.: Towards generalist biomedical ai. Nejm Ai1(3), AIoa2300138 (2024)
2024
-
[22]
arXiv preprint arXiv:2510.15042 (2025)
Wald, T., Hamamci, I.E., Gao, Y., Bond-Taylor, S., Sharma, H., Ilse, M., Lo, C., Melnichenko, O., Schwaighofer, A., Codella, N.C., et al.: Comprehensive language-image pre-training for 3d medical image understanding. arXiv preprint arXiv:2510.15042 (2025)
arXiv 2025
-
[23]
arXiv preprint arXiv:2604.10437 (2026)
Wang, C., Dai, W., Liu, H., Li, W., Batmanghelich, K.: Enhancing fine-grained spatial grounding in 3d ct report generation via discriminative guidance. arXiv preprint arXiv:2604.10437 (2026)
Pith/arXiv arXiv 2026
-
[24]
arXiv preprint arXiv:2509.19090 (2025)
Wang, G., et al.: Citrus-v: Advancing medical foundation models with unified med- ical image grounding for clinical reasoning. arXiv preprint arXiv:2509.19090 (2025)
arXiv 2025
-
[25]
arXiv preprint arXiv:2508.12455 (2025)
Wang, Z., et al.: X-ray-cot: Interpretable chest x-ray diagnosis with vision-language models via chain-of-thought reasoning. arXiv preprint arXiv:2508.12455 (2025)
arXiv 2025
-
[26]
Advances in neural information processing systems35, 24824–24837 (2022)
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Xia, F., Chi, E., Le, Q.V., Zhou, D., et al.: Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems35, 24824–24837 (2022)
2022
-
[27]
Nature Communications16(1), 7866 (2025)
Wu, C., Zhang, X., Zhang, Y., Hui, H., Wang, Y., Xie, W.: Towards generalist foun- dation model for radiology by leveraging web-scale 2d&3d medical data. Nature Communications16(1), 7866 (2025)
2025
-
[28]
In: Proceedings of the IEEE/CVF Interna- tional Conference on Computer Vision
Xu, G., Jin, P., Wu, Z., Li, H., Song, Y., Sun, L., Yuan, L.: Llava-cot: Let vision language models reason step-by-step. In: Proceedings of the IEEE/CVF Interna- tional Conference on Computer Vision. pp. 2087–2098 (2025)
2087
-
[29]
National Science Review11(12), nwae403 (2024)
Yin, S., Fu, C., Zhao, S., Li, K., Sun, X., Xu, T., Chen, E.: A survey on multimodal large language models. National Science Review11(12), nwae403 (2024)
2024
-
[30]
arXiv preprint arXiv:2510.20967 (2025) CORTEX: A Structured Reasoning Benchmark 11
Zhang, S., et al.: 3dreasonknee: Advancing grounded reasoning in medical vision language models. arXiv preprint arXiv:2510.20967 (2025) CORTEX: A Structured Reasoning Benchmark 11
arXiv 2025
-
[31]
arXiv preprint arXiv:2404.16754 (2024)
Zhang, X., Wu, C., Zhao, Z., Lei, J., Zhang, Y., Wang, Y., Xie, W.: Radgenome- chest ct: A grounded vision-language dataset for chest ct analysis. arXiv preprint arXiv:2404.16754 (2024)
arXiv 2024
-
[32]
Transactions on Machine Learning Research (2023)
Zhang, Z., Zhang, A., Li, M., Smola, A.: Multimodal chain-of-thought reasoning in language models. Transactions on Machine Learning Research (2023)
2023
-
[33]
Zhou, T., Zhu, Y., Xiao, C., Bian, H., Wei, L., Zhang, X., et al.: Drvd-bench: Do vision-language models reason like human doctors in medical image diagnosis? Advances in Neural Information Processing Systems38(2026)
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.