Fast Approximate MM-Estimation for Outlier Robust Model Selection
Pith reviewed 2026-06-29 00:38 UTC · model grok-4.3
The pith
A fast approximate MM-estimator using full-data weights speeds up robust model selection while preserving performance and consistency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
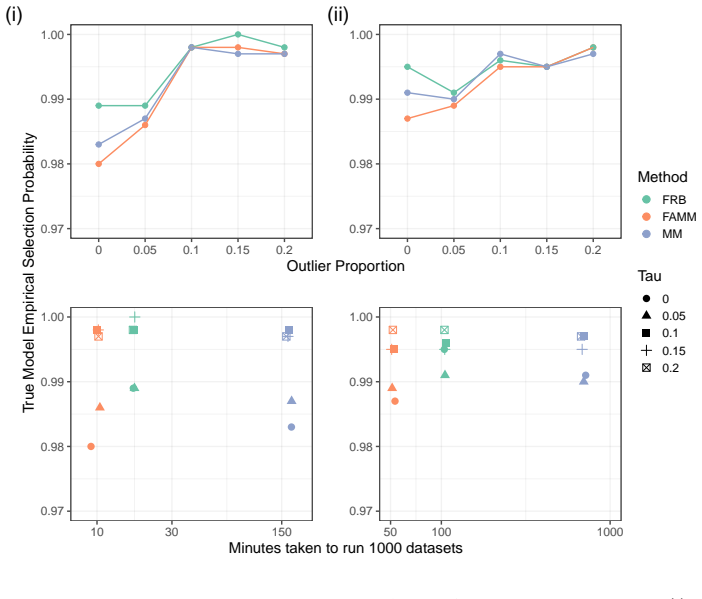
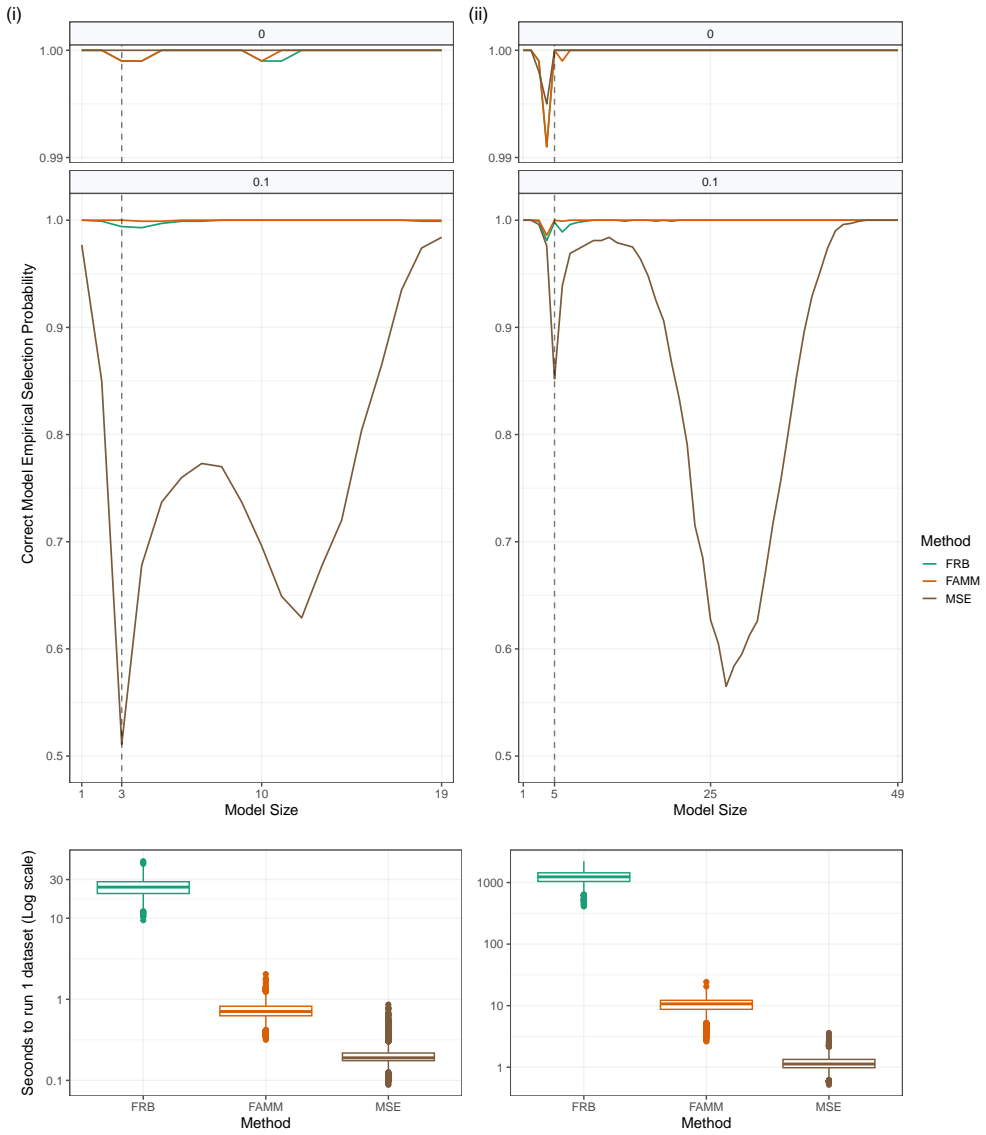
FAMM is a weighted least squares fit that uses weights derived from a single full-data MM-estimator to approximate the robust fit for every candidate model and every bootstrap sample. Substituting the full MM-estimator with FAMM preserves model selection performance, delivers a substantial computational speedup, and satisfies the conditions required for model selection consistency, as verified through extensive artificial simulations and applications to National Basketball Association data.
What carries the argument
FAMM, the Fast Approximate MM-estimator, which performs a weighted least squares regression using weights taken from one full-data MM-estimator to approximate the robust solution for each subproblem.
If this is right
- Model selection performance stays equivalent to the full MM-estimator across simulated and real data.
- Computational time drops substantially because each candidate model and bootstrap replicate avoids iterative robust fitting.
- FAMM meets the formal conditions needed for model selection consistency.
- The method directly addresses the computational barrier in stratified robust selection that down-weights large residuals and overrepresented outliers.
Where Pith is reading between the lines
- The same weighting trick could be tried on other iteratively solved robust estimators that currently limit bootstrap-based selection.
- In very high-dimensional or streaming data settings the speedup might allow exhaustive model searches that full MM-estimation currently rules out.
- The single full-data fit assumes the outlier structure is stable enough that subset-specific re-fitting is unnecessary; this may break when contamination patterns change sharply across models.
Load-bearing premise
Weights computed once on the full data remain accurate enough to approximate the robust fit for every candidate model and every bootstrap sample without changing the selected model or violating consistency.
What would settle it
A simulation study or real dataset in which the models chosen by FAMM differ from those chosen by the full MM-estimator in a non-negligible fraction of replications, or in which the theoretical consistency conditions fail to hold for FAMM.
Figures


read the original abstract
Stratified robust model selection reduces the impact of large residuals and overrepresented outliers in bootstrap samples but is computationally intensive when fitting iteratively-solved robust estimators across many candidate models. We propose FAMM, a Fast Approximate MM-estimator, implemented as a weighted least squares fit with weights derived from a full-data MM-estimator, to reduce this computational cost. Using extensive artificial simulations and applications to National Basketball Association data, we show that substituting the MM-estimator with FAMM preserves model selection performance while achieving a substantial computational speedup. Furthermore, we demonstrate that FAMM satisfies the required conditions for model selection consistency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes FAMM, a fast approximate MM-estimator implemented as a single weighted least-squares step whose weights are computed once from a full-data MM fit. It claims that replacing the iterative MM-estimator with FAMM in a stratified bootstrap model-selection procedure preserves selection performance, yields substantial computational speedup (demonstrated via artificial simulations and NBA data), and satisfies the regularity conditions needed for model-selection consistency.
Significance. If the fixed-weight approximation is shown to be sufficiently accurate across candidate models and bootstrap replicates, the approach would make outlier-robust model selection practical in settings where repeated iterative MM fits are prohibitive, while retaining the theoretical guarantees of the underlying MM procedure.
major comments (2)
- [§2] §2 (FAMM construction): The central performance-preservation and consistency claims rest on the assertion that weights derived from a single full-data MM-estimator remain adequate for every candidate submodel and every bootstrap replicate. No bound on the approximation error or explicit verification that the weighted LS solution recovers the iterative MM solution under resampling is supplied; this assumption is load-bearing because bootstrap resampling alters the outlier configuration and different submodels assign different leverage to the same observations.
- [§4] §4 (Simulation results): The manuscript states that FAMM 'preserves model selection performance' but does not report the quantitative metric (e.g., fraction of replicates in which the selected model differs between exact MM and FAMM, or the distribution of selection frequencies) needed to assess whether the approximation materially alters outcomes; without these numbers the claim that performance is preserved cannot be evaluated.
minor comments (2)
- [Abstract] The abstract and introduction should cite the specific theorem or proposition number that establishes the consistency conditions satisfied by FAMM.
- [§2] Notation for the weight vector w and the resulting weighted LS estimator should be introduced once and used consistently; currently the same symbol appears to be reused for the full-data and submodel fits.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [§2] §2 (FAMM construction): The central performance-preservation and consistency claims rest on the assertion that weights derived from a single full-data MM-estimator remain adequate for every candidate submodel and every bootstrap replicate. No bound on the approximation error or explicit verification that the weighted LS solution recovers the iterative MM solution under resampling is supplied; this assumption is load-bearing because bootstrap resampling alters the outlier configuration and different submodels assign different leverage to the same observations.
Authors: We acknowledge that the manuscript does not supply an explicit theoretical bound on the approximation error or a formal proof that the single weighted LS step recovers the iterative MM solution under resampling. The paper's justification rests on the robustness of the full-data MM weights (which identify outliers once) combined with the stratified bootstrap preserving outlier proportions, together with empirical evidence that selection outcomes remain comparable. We will revise §2 to include a clearer discussion of the approximation's scope and its dependence on the full-data fit being representative across submodels. revision: partial
-
Referee: [§4] §4 (Simulation results): The manuscript states that FAMM 'preserves model selection performance' but does not report the quantitative metric (e.g., fraction of replicates in which the selected model differs between exact MM and FAMM, or the distribution of selection frequencies) needed to assess whether the approximation materially alters outcomes; without these numbers the claim that performance is preserved cannot be evaluated.
Authors: The referee correctly notes the absence of these specific quantitative metrics. The current simulations compare overall selected models and report computational gains, but do not tabulate the fraction of replicates with differing selections or the distribution of selection frequencies. We will revise §4 to add these metrics, including the proportion of bootstrap replicates where FAMM and exact MM differ in the selected model and tables or figures summarizing selection frequencies. revision: yes
Circularity Check
No significant circularity detected in derivation or consistency claims
full rationale
The paper defines FAMM explicitly as a one-step weighted least-squares approximation using fixed weights computed once from the full-data MM-estimator. Performance preservation is assessed via simulation comparisons rather than by definitional equivalence. The consistency claim is presented as a separate demonstration that FAMM meets external required conditions for model selection consistency; no equations or self-citations are shown reducing this demonstration to the approximation itself or to fitted quantities by construction. No self-definitional loops, fitted-input-as-prediction, or load-bearing self-citation chains appear in the provided abstract and description. The central claims therefore remain independent of the inputs they are evaluated against.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Proceedings of the Second International Symposium of Information Theory , pages =
Akaike, Hirotugu , title =. Proceedings of the Second International Symposium of Information Theory , pages =
-
[2]
Journal of Computational and Graphical Statistics , pages =
Anthony-Alexander Christidis and Gabriela Cohen Freue , title =. Journal of Computational and Graphical Statistics , pages =. 2026 , publisher =. doi:10.1080/10618600.2025.2596057 , URL =
-
[3]
Furnival and Robert W
George M. Furnival and Robert W. Wilson , journal =. Regressions by Leaps and Bounds , urldate =
-
[4]
David Kepplinger and Siqi Wei , title =. Technometrics , volume =. 2026 , publisher =. doi:10.1080/00401706.2025.2540970 , URL =
-
[5]
Journal of Computational and Applied Mathematics , author =
Robust model selection in linear regression models using information complexity , volume =. Journal of Computational and Applied Mathematics , author =. 2021 , keywords =. doi:10.1016/j.cam.2021.113679 , urldate =
-
[6]
The Annals of Mathematical Statistics , author =
Robust Estimation of a Location Parameter , volume =. The Annals of Mathematical Statistics , author =. 1964 , pages =. doi:10.1214/aoms/1177703732 , number =
-
[7]
C. L. Mallows , journal =. Some Comments on
-
[8]
2006 , publisher =
Robust Statistics: Theory and Methods , author =. 2006 , publisher =
2006
-
[9]
Meinshausen, N. and B. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume =. 2010 , title =
2010
-
[10]
2024 , pages =
Statistics and Computing , author =. 2024 , pages =
2024
-
[11]
A weighted network clustering approach in the
Muniz, Megan and Flamand, Tulay , year =. A weighted network clustering approach in the. Journal of Sports Analytics , doi =
-
[12]
Samuel Müller and A. H Welsh , title =. Journal of the American Statistical Association , volume =. 2005 , publisher =. doi:10.1198/016214505000000529 , URL =
-
[13]
2026 , url =
R: A Language and Environment for Statistical Computing , author =. 2026 , url =
2026
-
[14]
Tino Werner , title =. Machine Learning , year =. doi:10.1007/s10994-023-06384-z , url =
-
[15]
Manuel Koller and Werner A. Stahel , title =. Computational Statistics , year =. doi:10.1007/s00180-016-0679-x , url =
-
[16]
Robust and sparse estimators for linear regression models , journal =. 2017 , issn =. doi:https://doi.org/10.1016/j.csda.2017.02.002 , url =
-
[17]
Journal of Statistical Computation and Simulation , volume =
Olivier Thas and Stijn Jaspers , title =. Journal of Statistical Computation and Simulation , volume =. 2026 , publisher =. doi:10.1080/00949655.2025.2558863 , URL =
-
[18]
Robust model selection in regression , journal =. 1985 , issn =. doi:https://doi.org/10.1016/0167-7152(85)90006-9 , author =
-
[19]
Journal of the American Statistical Association , volume =
Elvezio Ronchetti and Christopher Field and Wade Blanchard , title =. Journal of the American Statistical Association , volume =. 1997 , publisher =. doi:10.1080/01621459.1997.10474057 , URL =
-
[20]
Robust Regression by Means of
Rousseeuw, Peter and Yohai, Victor , year =. Robust Regression by Means of. Springer Lecture Notes in Statistics , doi =
-
[21]
Detecting Deviating Data Cells , volume =. Technometrics , author =. 2018 , pages =. doi:10.1080/00401706.2017.1340909 , number =
-
[22]
Robust model selection using fast and robust bootstrap , journal =
Matias Salibian-Barrera and Stefan. Robust model selection using fast and robust bootstrap , journal =. 2008 , issn =. doi:https://doi.org/10.1016/j.csda.2008.05.007 , url =
-
[23]
Zamar , journal =
Matias Salibian-Barrera and Ruben H. Zamar , journal =. Bootstrapping Robust Estimates of Regression , urldate =
-
[24]
Statistical Methods and Applications , author =
Fast and robust bootstrap , volume =. Statistical Methods and Applications , author =. 2008 , keywords =. doi:10.1007/s10260-007-0048-6 , language =
-
[25]
Estimating the Dimension of a Model , urldate =
Gideon Schwarz , journal =. Estimating the Dimension of a Model , urldate =
-
[26]
Journal of the American Statistical Association , volume =
Jun Shao , title =. Journal of the American Statistical Association , volume =. 1996 , publisher =. doi:10.1080/01621459.1996.10476934 , URL =
-
[27]
Huggins , journal =
Suzanne Sommer and Richard M. Huggins , journal =. Variables Selection Using the
-
[28]
Journal of Quantitative Analysis in Sports , author=
A basketball paradox: exploring. Journal of Quantitative Analysis in Sports , author=. 2025 , pages=. doi:10.1515/jqas-2024-0010 , url=
-
[29]
, year =
Tibshirani, R. , year =. Regression shrinkage and selection via the lasso , journal =
-
[30]
Venables, W. N. and Ripley, B. D. , year =. Modern
-
[31]
Annals of Operations Research , author =
Will more skills become a burden?. Annals of Operations Research , author =. 2023 , pages =. doi:10.1007/s10479-022-04588-5 , number =
-
[32]
Yohai , journal =
Victor J. Yohai , journal =. High Breakdown-Point and High Efficiency Robust Estimates for Regression , urldate =
-
[33]
Extending
Dirk Eddelbuettel and James Joseph Balamuta , journal =. Extending. 2018 , volume =
2018
-
[34]
Journal of Sports Sciences , volume =
Shaoliang Zhang and Alberto Lorenzo and Miguel-Angel Gómez and Nuno Mateus and Bruno Gonçalves and Jaime Sampaio , title =. Journal of Sports Sciences , volume =. 2018 , publisher =
2018
-
[35]
, title =
Maronna, Ricardo A. , title =. 2011 , journal =
2011
-
[36]
Hampel , journal =
Frank R. Hampel , journal =. The Influence Curve and Its Role in Robust Estimation , volume =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.