HandMade: Spatial Prompting for Generative 3D Creation with Part-Labeled VR Sketches
Pith reviewed 2026-06-29 03:28 UTC · model grok-4.3
The pith
HandMade converts part-labeled VR sketches into multi-view guidance that steers generative 3D models while language supplies identity and details.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
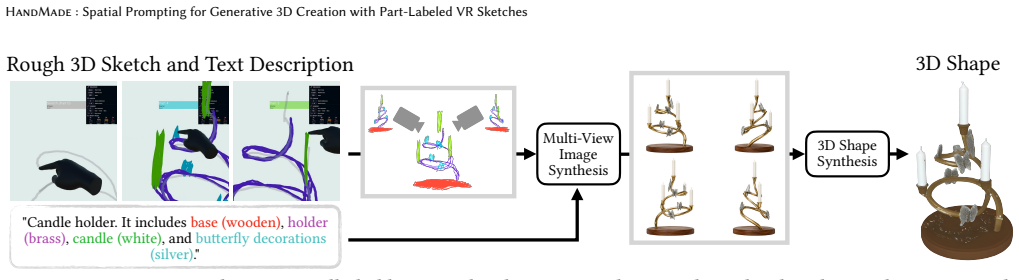
HandMade treats coarse, part-labeled 3D sketches not as incomplete geometry to reconstruct directly, but as spatial prompts for existing generative models. It converts segmented VR strokes into multi-view part guidance and structured prompts, allowing users to specify object layout and part relationships through 3D sketching while using language for identity, material, style, and local details. A technical evaluation shows that HandMade better preserves user-authored spatial scaffolds than text-only and sketch-based baselines on 20 varied examples.
What carries the argument
Conversion of segmented VR strokes into multi-view part guidance and structured prompts that existing generative models can read.
If this is right
- Users can specify object layout and part relationships via 3D sketching.
- Language is reserved for identity, material, style, and local details.
- Spatial scaffolds are preserved better than text-only or sketch-based baselines across 20 varied examples.
- Users split sketching for spatial layout and language for other attributes during both initial authoring and revision.
Where Pith is reading between the lines
- The same prompting pattern could be tested on other generative back-ends to see whether preservation gains hold when the underlying model changes.
- Extending the stroke-to-guidance step to accept live corrections might shorten the revision loop observed in the user study.
- The workflow could be compared against direct 3D reconstruction methods to quantify the trade-off between flexibility and geometric fidelity.
Load-bearing premise
Converting segmented VR strokes into multi-view part guidance produces signals that existing generative models can reliably interpret without losing the intended spatial relationships.
What would settle it
Re-running the technical evaluation on the same 20 examples and finding that spatial-scaffold preservation is no better than the text-only or sketch-based baselines would falsify the central claim.
Figures



read the original abstract
Text-to-3D generation lowers the barrier to 3D content creation, but text alone is a weak interface for specifying spatial intent: where parts should be placed, how they relate, and how an object should be organized in 3D. We present HandMade, a workflow that combines VR 3D sketching and language for open-domain 3D asset generation. HandMade treats coarse, part-labeled 3D sketches not as incomplete geometry to reconstruct directly, but as spatial prompts for existing generative models. It converts segmented VR strokes into multi-view part guidance and structured prompts, allowing users to specify object layout and part relationships through 3D sketching while using language for identity, material, style, and local details. A technical evaluation shows that HandMade better preserves user-authored spatial scaffolds than text-only and sketch-based baselines on 20 varied examples. A user study with eight participants characterizes how users make use of 3D sketching for spatial layout and language for identity, materials, and details across initial authoring and subsequent revision. HandMade contributes an interaction paradigm and interface-to-generation pipeline for spatially guided 3D creation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents HandMade, a workflow combining VR 3D sketching with language for open-domain 3D asset generation. Coarse, part-labeled VR sketches are treated as spatial prompts: segmented strokes are converted into multi-view part guidance and structured prompts, with language handling identity, material, style, and local details. A technical evaluation on 20 varied examples claims HandMade better preserves user-authored spatial scaffolds than text-only and sketch-based baselines; a user study with eight participants characterizes usage patterns for layout versus details across authoring and revision.
Significance. If the preservation claim is substantiated with explicit metrics and protocols, the work would contribute a practical interaction paradigm bridging direct 3D spatial input and generative models, addressing a known weakness of text-only interfaces for part relationships and layout.
major comments (1)
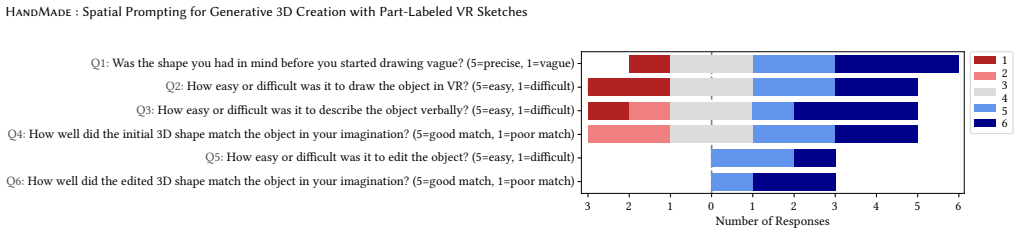
- [Abstract] Abstract (technical evaluation paragraph): the central claim that HandMade 'better preserves user-authored spatial scaffolds' than baselines on 20 examples is unsupported by any described protocol, metric (e.g., part-position distance, relational overlap, or 3D consistency score), blinding method, or statistical test. The evaluation therefore cannot be assessed and does not yet substantiate the strongest empirical result.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for greater transparency in the abstract's description of the technical evaluation. We address this point directly below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract (technical evaluation paragraph): the central claim that HandMade 'better preserves user-authored spatial scaffolds' than baselines on 20 examples is unsupported by any described protocol, metric (e.g., part-position distance, relational overlap, or 3D consistency score), blinding method, or statistical test. The evaluation therefore cannot be assessed and does not yet substantiate the strongest empirical result.
Authors: We acknowledge that the abstract paragraph makes a comparative claim without enumerating the supporting protocol or metrics. The full manuscript (Section 5) details the evaluation on the 20 examples, including the specific spatial preservation metrics, baseline implementations, and comparison procedure. However, the abstract itself does not convey this information, which limits immediate assessment of the claim. We will revise the abstract to include a concise statement of the evaluation protocol and metrics used, ensuring the central result is better substantiated at the summary level. revision: yes
Circularity Check
No circularity: empirical system description with independent evaluation
full rationale
The paper describes an interaction workflow and pipeline for converting VR sketches into prompts for existing generative models, then reports comparative results on 20 examples. No equations, fitted parameters, predictions derived from inputs, or self-citation chains appear in the provided text. The central claim rests on external comparison to baselines rather than any definitional reduction or imported uniqueness result. This is a standard non-circular empirical HCI/systems paper.
Axiom & Free-Parameter Ledger
invented entities (1)
-
HandMade workflow and conversion pipeline
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Rahul Arora, Rubaiat Habib Kazi, Fraser Anderson, Tovi Grossman, Karan Singh, and George Fitzmaurice. 2017. Experimental Evaluation of Sketching on Surfaces in VR. InProceedings of the 2017 CHI Conference on Human Factors in Computing Systems. 5643–5654. doi:10.1145/3025453.3025474
-
[2]
Seok-Hyung Bae, Ravin Balakrishnan, and Karan Singh. 2008. ILoveSketch: As-natural-as-possible Sketching System for Creating 3D Curve Models. InPro- ceedings of the 21st Annual ACM Symposium on User Interface Software and Technology. 151–160. doi:10.1145/1449715.1449740
-
[3]
Hmrishav Bandyopadhyay, Subhadeep Koley, Ayan Das, Ayan Kumar Bhunia, Aneeshan Sain, Pinaki Nath Chowdhury, Tao Xiang, and Yi-Zhe Song. 2024. Doodle Your 3D: From Abstract Freehand Sketches to Precise 3D Shapes. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 9795–9805. doi:10.1109/CVPR52733.2024.00935
-
[4]
Video-bench: Human-aligned video generation benchmark
Amir Barda, Matheus Gadelha, Vladimir G. Kim, Noam Aigerman, Amit H. Bermano, and Thibault Groueix. 2025. Instant3dit: Multiview Inpainting for Fast Editing of 3D Objects. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 16273–16282. doi:10.1109/CVPR52734.2025.01517
-
[5]
Barrera Machuca, Paul Asente, Jingwan Lu, Byungmoon Kim, and Wolfgang Stuerzlinger
Mayra D. Barrera Machuca, Paul Asente, Jingwan Lu, Byungmoon Kim, and Wolfgang Stuerzlinger. 2018. Multiplanes: Assisted Freehand VR Sketching. In Proceedings of the ACM Symposium on Spatial User Interaction. 36–47. doi:10. 1145/3267782.3267786
arXiv 2018
-
[6]
Mark Boss, Zixuan Huang, Aaryaman Vasishta, and Varun Jampani. 2025. SF3D: Stable Fast 3D Mesh Reconstruction with UV-unwrapping and Illumination Disentanglement. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. doi:10.1109/CVPR52734.2025.01514
-
[7]
Minglin Chen, Longguang Wang, Weihao Yuan, Yukun Wang, Zhe Sheng, Yisheng He, Zilong Dong, Liefeng Bo, and Yulan Guo. 2024. Sketch2NeRF: Multi-view Sketch-guided Text-to-3D Generation. arXiv:2401.14257 [cs.CV] https://arxiv.org/abs/2401.14257
arXiv 2024
-
[8]
Qimin Chen, Yuezhi Yang, Yifan Wang, Vladimir Kim, Siddhartha Chaudhuri, Hao Zhang, and Zhiqin Chen. 2025. ART-DECO: Arbitrary Text Guidance for 3D Detailizer Construction. InProceedings of the SIGGRAPH Asia 2025 Conference Pa- pers. Association for Computing Machinery, 1–12. doi:10.1145/3757377.3763877
-
[9]
Rui Chen, Yongwei Chen, Ningxin Jiao, and Kui Jia. 2023. Fantasia3D: Dis- entangling Geometry and Appearance for High-quality Text-to-3D Content Creation. InProceedings of the IEEE/CVF International Conference on Computer Vision. doi:10.1109/ICCV51070.2023.02033
-
[10]
Yang Chen, Yingwei Pan, Yehao Li, Ting Yao, and Tao Mei. 2023. Control3D: Towards Controllable Text-to-3D Generation. InProceedings of the 31st ACM International Conference on Multimedia. Association for Computing Machinery, 1148–1156. doi:10.1145/3581783.3612489
-
[11]
Yizi Chen, Sidi Wu, Tianyi Xiao, Nina Wiedemann, and Loic Landrieu
-
[12]
arXiv:2512.04761 [cs.CV] doi:10.48550/arXiv.2512.04761
Order Matters: 3D Shape Generation from Sequential VR Sketches. arXiv:2512.04761 [cs.CV] doi:10.48550/arXiv.2512.04761
-
[13]
10 TRACER: Persistent Regularization for Robust Multimodal Finetuning Fang, A., Jose, A
Yen-Chi Cheng, Hsin-Ying Lee, Sergey Tulyakov, Alexander G. Schwing, and Liang-Yan Gui. 2023. SDFusion: Multimodal 3D Shape Completion, Reconstruc- tion, and Generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 4456–4465. doi:10.1109/CVPR52729.2023.00433
-
[14]
Runlin Duan, Yuzhao Chen, Yichen Hu, Ziyi Liu, Chenfei Zhu, Xiyun Hu, Dizhi Ma, Xinyi Wang, and Karthik Ramani. 2026. JustShape: Exploring Co-Speech Gestures for Multimodal LLM-Powered 3D Parametric Modeling. InProceedings of the 2026 CHI Conference on Human Factors in Computing Systems. 1–31
2026
-
[15]
Elisabetta Fedele, Francis Engelmann, Ian Huang, Or Litany, Marc Pollefeys, and Leonidas J. Guibas. 2026. SpaceControl: Introducing Test-Time Spatial Control to 3D Generative Modeling. InInternational Conference on Learning Representations. arXiv:2512.05343 [cs.CV] doi:10.48550/arXiv.2512.05343
-
[16]
Michael Garland and Paul S. Heckbert. 1997. Surface simplification using quadric error metrics. InProceedings of the 24th Annual Conference on Computer Graphics and Interactive Techniques (SIGGRAPH ’97). ACM Press/Addison-Wesley Publish- ing Co., USA, 209–216. doi:10.1145/258734.258849
-
[17]
Songen Gu, Haoxuan Song, Binjie Liu, Qian Yu, Sanyi Zhang, Haiyong Jiang, Jin Huang, and Feng Tian. 2025. VRsketch2Gaussian: 3D VR Sketch Guided 3D Object Generation with Gaussian Splatting. arXiv:2503.12383 [cs.CV] doi:10. 48550/arXiv.2503.12383
arXiv 2025
-
[18]
Benoit Guillard, Edoardo Remelli, Pierre Yvernay, and Pascal Fua. 2021. Sketch2Mesh: Reconstructing and Editing 3D Shapes from Sketches. InPro- ceedings of the IEEE/CVF International Conference on Computer Vision. doi:10. 1109/ICCV48922.2021.01278
arXiv 2021
-
[19]
Yicong Hong, Kai Zhang, Jiuxiang Gu, Sai Bi, Yang Zhou, Difan Liu, Feng Liu, Kalyan Sunkavalli, Trung Bui, and Hao Tan. 2024. LRM: Large Recon- struction Model for Single Image to 3D. InInternational Conference on Learn- ing Representations. https://proceedings.iclr.cc/paper_files/paper/2024/hash/ dcad3425f5c8c36b5b3885c091bf1257-Abstract-Conference.html
2024
-
[20]
Video-bench: Human-aligned video generation benchmark
Zixuan Huang, Mark Boss, Aaryaman Vasishta, James M. Rehg, and Varun Jampani. 2025. SPAR3D: Stable Point-Aware Reconstruction of 3D Objects from Single Images. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 16860–16870. doi:10.1109/CVPR52734.2025.01571
-
[21]
Zeyuan Huang, Cangjun Gao, Yaxian Shan, Haoxiang Hu, Qingkun Li, Xiaoming Deng, Cuixia Ma, Yu-Kun Lai, Yong-Jin Liu, Feng Tian, Guozhong Dai, and Hongan Wang. 2025. SketchGPT: A Sketch-based Multimodal Interface for Application-Agnostic LLM Interaction. InProceedings of the 38th Annual ACM Symposium on User Interface Software and Technology. Association f...
-
[22]
Takeo Igarashi, Satoshi Matsuoka, and Hidehiko Tanaka. 1999. Teddy: A Sketching Interface for 3D Freeform Design. InProceedings of the 26th An- nual Conference on Computer Graphics and Interactive Techniques. 409–416. doi:10.1145/311535.311602
-
[23]
Bret Jackson and Daniel F. Keefe. 2016. Lift-Off: Using Reference Imagery and Freehand Sketching to Create 3D Models in VR.IEEE Transactions on Visualization and Computer Graphics22, 4 (2016), 1442–1451. doi:10.1109/TVCG.2016.2518099 12 HandMade: Spatial Prompting for Generative 3D Creation with Part-Labeled VR Sketches
-
[24]
Seung-Jun Lee, Jeongche Yoon, Sang-Hyun Lee, Joon Hyub Lee, and Seok-Hyung Bae. 2025. 3D Sketching + 2D Generative AI for Car Exterior Design. InProceed- ings of the 38th Annual ACM Symposium on User Interface Software and Technology. Association for Computing Machinery, 1–14. doi:10.1145/3746059.3747609
-
[25]
Haoxuan Li, Ziya Erkoç, Lei Li, Daniele Sirigatti, Vladislav Rosov, Angela Dai, and Matthias Nießner. 2025. MeshPad: Interactive Sketch-Conditioned Artist- Reminiscent Mesh Generation and Editing. InProceedings of the IEEE/CVF Inter- national Conference on Computer Vision. 16227–16237. https://openaccess.thecvf. com/content/ICCV2025/html/Li_MeshPad_Intera...
2025
-
[26]
Jiahao Li, Hao Tan, Kai Zhang, Zexiang Xu, Fujun Luan, Yinghao Xu, Yicong Hong, Kalyan Sunkavalli, Greg Shakhnarovich, and Sai Bi
-
[27]
InInternational Conference on Learning Representations
Instant3D: Fast Text-to-3D with Sparse-view Generation and Large Reconstruction Model. InInternational Conference on Learning Representations. https://proceedings.iclr.cc/paper_files/paper/2024/hash/ 5e8309c9ca683e11672e3dbcd4b87776-Abstract-Conference.html
2024
-
[28]
Chen-Hsuan Lin, Jun Gao, Luming Tang, Towaki Takikawa, Xiaohui Zeng, Xun Huang, Karsten Kreis, Sanja Fidler, Ming-Yu Liu, and Tsung-Yi Lin. 2023. Magic3D: High-Resolution Text-to-3D Content Creation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 300–309. doi:10.1109/ CVPR52729.2023.00037
arXiv 2023
-
[29]
Feng-Lin Liu, Hongbo Fu, Yu-Kun Lai, and Lin Gao. 2024. SketchDream: Sketch- based Text-to-3D Generation and Editing.ACM Transactions on Graphics43, 4, Article 44 (2024). doi:10.1145/3658120
-
[30]
Ruoshi Liu, Rundi Wu, Basile Van Hoorick, Pavel Tokmakov, Sergey Zakharov, and Carl Vondrick. 2023. Zero-1-to-3: Zero-shot One Image to 3D Object. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 9298–
2023
-
[31]
doi:10.1109/ICCV51070.2023.00853
-
[32]
Yuan Liu, Cheng Lin, Zijiao Zeng, Xiaoxiao Long, Lingjie Liu, Taku Komura, and Wenping Wang. 2024. SyncDreamer: Generating Multiview-consistent Images from a Single-view Image. InInternational Conference on Learn- ing Representations. https://proceedings.iclr.cc/paper_files/paper/2024/hash/ 753d9584b57ba01a10482f1ea7734a89-Abstract-Conference.html
2024
-
[33]
Xiaoxiao Long, Yuan-Chen Guo, Cheng Lin, Yuan Liu, Zhiyang Dou, Lingjie Liu, Yuexin Ma, Song-Hai Zhang, Marc Habermann, Christian Theobalt, and Wenping Wang. 2024. Wonder3D: Single Image to 3D using Cross-Domain Diffusion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 9970–9980. doi:10.1109/CVPR52733.2024.00951
-
[34]
Sining Lu, Guan Chen, Nam Anh Dinh, Itai Lang, Ari Holtzman, and Rana Hanocka. 2025. LL3M: Large Language 3D Modelers. arXiv:2508.08228 [cs.GR] https://arxiv.org/abs/2508.08228
arXiv 2025
-
[35]
Ling Luo, Pinaki Nath Chowdhury, Tao Xiang, Yi-Zhe Song, and Yulia Gryadit- skaya. 2023. 3D VR Sketch Guided 3D Shape Prototyping and Exploration. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 9267–
2023
-
[36]
doi:10.1109/ICCV51070.2023.00850
-
[37]
Meta. 2026. Get Started with Passthrough. https://developers.meta.com/horizon/ documentation/unreal/unreal-passthrough-overview-gs/ Accessed 2026-06-07
2026
-
[38]
Aryan Mikaeili, Or Perel, Mehdi Safaee, Daniel Cohen-Or, and Ali Mahdavi-Amiri
-
[39]
Adaptive frequency filters as efficient global token mixers
SKED: Sketch-guided Text-based 3D Editing. InProceedings of the IEEE/CVF International Conference on Computer Vision. doi:10.1109/ICCV51070.2023.01343
-
[40]
Karla Felix Navarro, Eugene Syriani, and Ian Arawjo. 2026. Reporting and Reviewing LLM-Integrated Systems in HCI: Challenges and Considerations. In Proceedings of the 2026 CHI Conference on Human Factors in Computing Systems. Association for Computing Machinery. doi:10.1145/3772318.3790439
-
[41]
Andrew Nealen, Takeo Igarashi, Olga Sorkine, and Marc Alexa. 2007. FiberMesh: Designing Freeform Surfaces with 3D Curves.ACM Transactions on Graphics26, 3, Article 41 (2007). doi:10.1145/1276377.1276429
-
[42]
OpenAI. 2026. ChatGPT Images 2.0. https://openai.com/index/introducing- chatgpt-images-2-0/ Accessed 2026-06-07
2026
-
[43]
Sharon Oviatt. 1999. Ten Myths of Multimodal Interaction.Commun. ACM42, 11 (1999), 74–81. doi:10.1145/319382.319398
-
[44]
Sharon Oviatt, Antonella DeAngeli, and Karen Kuhn. 1997. Integration and synchronization of input modes during multimodal human-computer interaction. InProceedings of the ACM SIGCHI Conference on Human factors in computing systems (CHI ’97). Association for Computing Machinery, New York, NY, USA, 415–422. doi:10.1145/258549.258821
-
[45]
DreamFusion: Text-to-3D using 2D Diffusion
Ben Poole, Ajay Jain, Jonathan T. Barron, and Ben Mildenhall. 2023. Dream- Fusion: Text-to-3D using 2D Diffusion. InInternational Conference on Learning Representations. arXiv:2209.14988 [cs.CV] doi:10.48550/arXiv.2209.14988
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2209.14988 2023
-
[46]
Karl Toby Rosenberg, Rubaiat Habib Kazi, Li-Yi Wei, Haijun Xia, and Ken Perlin
-
[47]
In Proceedings of the 37th Annual ACM Symposium on User Interface Software and Technology
Drawtalking: Building interactive worlds by sketching and speaking. In Proceedings of the 37th Annual ACM Symposium on User Interface Software and Technology. 1–25. doi:10.1145/3654777.3676334
-
[48]
Aditya Sanghi, Pradeep Kumar Jayaraman, Arianna Rampini, Joseph Lambourne, Hooman Shayani, Evan Atherton, and Saeid Asgari Taghanaki. 2023. Sketch-A- Shape: Zero-Shot Sketch-to-3D Shape Generation. InProceedings of the IEEE/CVF International Conference on Computer Vision. https://www.research.autodesk. com/publications/sketch-a-shape/
2023
-
[49]
Yichun Shi, Peng Wang, Jianglong Ye, Mai Long, Kejie Li, and Xiao Yang. 2024. MVDream: Multi-view Diffusion for 3D Generation. InInternational Conference on Learning Representations. https://proceedings.iclr.cc/paper_files/paper/2024/ hash/adbe936993aa7cf41e45054d8b72f183-Abstract-Conference.html
2024
-
[50]
Shivam Ashok Shukla, Raghav Mittal, Lokender Tiwari, and Brojeshwar Bhowmick. 2025. SketchTo3DGen: GenAI Powered Articulation Ready 3D Asset Ideation using 3D Sketches and Audio Descriptions. InProceedings of the 31st ACM Symposium on Virtual Reality Software and Technology. Association for Computing Machinery, Article 119, 3 pages. doi:10.1145/3756884.3770540
-
[51]
Habib Slim, Shariq Farooq Bhat, Mohamed Elhoseiny, Yifan Wang, and Mike Roberts. 2026. CompoSE: Compositional Synthesis and Editing of 3D Shapes via Part-Aware Control. arXiv:2605.19350 [cs.GR] doi:10.48550/arXiv.2605.19350
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2605.19350 2026
-
[52]
Xinbin Sun, Zhentong Xu, Guodong Wang, Fuqing Duan, Junli Zhao, Zhenkuan Pan, and Mingquan Zhou. 2026. OmniSketch: Sketch-Guided Text-to-3D Gener- ation with High-Fidelity Geometry and Texture.IEEE Computer Graphics and ApplicationsPP (2026). doi:10.1109/MCG.2026.3667017
-
[53]
Lev Tankelevitch, Viktor Kewenig, Auste Simkute, Ava Elizabeth Scott, Advait Sarkar, Abigail Sellen, and Sean Rintel. 2024. The Metacognitive Demands and Opportunities of Generative AI. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems. Association for Computing Machinery. doi:10.1145/3613904.3642902
-
[54]
Tencent Hunyuan3D Team. 2025. Hunyuan3D 2.0: Scaling Diffusion Models for High Resolution Textured 3D Assets Generation. arXiv:2501.12202 [cs.CV] https://arxiv.org/abs/2501.12202
Pith/arXiv arXiv 2025
-
[55]
Dmitry Tochilkin, David Pankratz, Zexiang Liu, Zixuan Huang, Adam Letts, Yangguang Li, Ding Liang, Christian Laforte, Varun Jampani, and Yan-Pei Cao. 2024. TripoSR: Fast 3D Object Reconstruction from a Single Image. arXiv:2403.02151 [cs.CV] https://arxiv.org/abs/2403.02151
Pith/arXiv arXiv 2024
-
[56]
Barbara Tversky and Kathleen Hemenway. 1984. Objects, Parts, and Categories. Journal of Experimental Psychology: General113, 2 (1984), 169–193. doi:10.1037/ 0096-3445.113.2.169
1984
-
[57]
Zhijie Wang, Yuheng Huang, Da Song, Lei Ma, and Tianyi Zhang. 2024. PromptCharm: Text-to-Image Generation through Multi-modal Prompting and Refinement. InProceedings of the 2024 CHI Conference on Human Factors in Com- puting Systems. Association for Computing Machinery. doi:10.1145/3613904. 3642803
-
[58]
Zhengyi Wang, Cheng Lu, Yikai Wang, Fan Bao, Chongxuan Li, Hang Su, and Jun Zhu. 2023. ProlificDreamer: High-Fidelity and Diverse Text-to-3D Generation with Variational Score Distillation. InAdvances in Neural Information Processing Systems, Vol. 36. https://proceedings.neurips.cc/paper_files/paper/2023/hash/ 1a87980b9853e84dfb295855b425c262-Abstract-Conf...
2023
-
[59]
Zhengyi Wang, Yikai Wang, Yifei Chen, Chendong Xiang, Shuo Chen, Dajiang Yu, Chongxuan Li, Hang Su, and Jun Zhu. 2024. CRM: Single Image to 3D Textured Mesh with Convolutional Reconstruction Model. InComputer Vision – ECCV 2024. Springer, 57–74. doi:10.1007/978-3-031-72751-1_4
-
[60]
Weisz, Jessica He, Michael Muller, Gabriela Hoefer, Rachel Miles, and Werner Geyer
Justin D. Weisz, Jessica He, Michael Muller, Gabriela Hoefer, Rachel Miles, and Werner Geyer. 2024. Design Principles for Generative AI Applications. InPro- ceedings of the 2024 CHI Conference on Human Factors in Computing Systems. Association for Computing Machinery. doi:10.1145/3613904.3642466
-
[61]
Suibi Che-Chuan Weng, Shih-Yu Ma, Sawyer Reinig, Pritalee Kadam, Ada Yi Zhao, Amy Banić, Ryo Suzuki, and Ellen Yi-Luen Do. 2026. Editing Reality: Designing In-Situ Co-Creation with Generative AI in Mixed Reality. InProceedings of the 2026 ACM Designing Interactive Systems Conference. Association for Computing Machinery. doi:10.1145/3800645.3813087
-
[62]
Kailu Wu, Fangfu Liu, Zhihan Cai, Runjie Yan, Hanyang Wang, Yating Hu, Yueqi Duan, and Kaisheng Ma. 2024. Unique3D: High-Quality and Efficient 3D Mesh Generation from a Single Image. InAdvances in Neural Information Processing Systems, Vol. 37. doi:10.52202/079017-3974
-
[63]
Yingbin Wu, Fubo Wang, Peng Zhao, Mingquan Zhou, Shengling Geng, and Dan Zhang. 2026. High-Fidelity 3D Mesh Generation from a Single Sketch Using Shape Constraints.Scientific Reports16, Article 1127 (2026). doi:10.1038/s41598- 025-30843-3
-
[64]
Jiatong Xia, Zicheng Duan, Anton van den Hengel, and Lingqiao Liu
-
[65]
arXiv:2603.18782 [cs.CV] doi:10.48550/arXiv.2603.18782 Accepted to CVPR 2026
Points-to-3D: Structure-Aware 3D Generation with Point Cloud Priors. arXiv:2603.18782 [cs.CV] doi:10.48550/arXiv.2603.18782 Accepted to CVPR 2026
-
[66]
Jiale Xu, Weihao Cheng, Yiming Gao, Xintao Wang, Shenghua Gao, and Ying Shan. 2024. InstantMesh: Efficient 3D Mesh Generation from a Single Image with Sparse-view Large Reconstruction Models. arXiv:2404.07191 [cs.CV] https: //arxiv.org/abs/2404.07191
Pith/arXiv arXiv 2024
-
[67]
Hyejeong Yoon, Wonjong Jang, Yoonha Hwang, and Seungyong Lee. 2026. 3D Character Reconstruction from Hand-Drawn Model Sheets.Computer Graphics Forum(2026). doi:10.1111/cgf.70323 Eurographics 2026
-
[68]
Xue Yu, Stephen DiVerdi, Akshay Sharma, and Yotam Gingold. 2021. ScaffoldS- ketch: Accurate Industrial Design Drawing in VR. InProceedings of the 34th Annual ACM Symposium on User Interface Software and Technology. 372–384. doi:10.1145/3472749.3474756
-
[69]
Ying Zang, Yidong Han, Chaotao Ding, Jianqi Zhang, and Tianrun Chen. 2026. Magic3DSketch: Create Colorful 3D Models from Sketch-Based 3D Modeling 13 Jialin Huang, Rana Hanocka, Ariel Shamir, and Yotam Gingold Guided by Text and Language-Image Pre-Training.Neurocomputing661 (2026), 131925. doi:10.1016/j.neucom.2025.131925
-
[70]
Ying Zang, Chunan Yu, Jiahao Zhang, Jing Li, Shengyuan Zhang, Lanyun Zhu, Chaotao Ding, Renjun Xu, and Tianrun Chen. 2026. From Sketch to Reality: Enabling High-Quality, Cross-Category 3D Model Generation from Free-Hand Sketches with Minimal Data.IEEE Transactions on Visualization and Computer GraphicsPP (2026). doi:10.1109/TVCG.2026.3661544
-
[71]
Song-Hai Zhang, Yuan-Chen Guo, and Qing-Wen Gu. 2021. Sketch2Model: View-Aware 3D Modeling from Single Free-Hand Sketches. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 6012–6021. doi:10.1109/CVPR46437.2021.00595
-
[72]
Yuxiao Zhang, Jin Wang, Yang Zhou, Senyun Jia, Zhi Zheng, Dongliang Zhang, and Guodong Lu. 2026. 3D Modeling from a Single Sketch with Multifaceted Semantic Understanding.Expert Systems with Applications298 (2026), 129748. doi:10.1016/j.eswa.2025.129748
-
[73]
Xin-Yang Zheng, Hao Pan, Peng-Shuai Wang, Xin Tong, Yang Liu, and Heung- Yeung Shum. 2023. Locally Attentional SDF Diffusion for Controllable 3D Shape Generation.ACM Transactions on Graphics42, 4, Article 91 (2023). doi:10.1145/ 3592103 14 HandMade: Spatial Prompting for Generative 3D Creation with Part-Labeled VR Sketches Figure 5: Representative technic...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.