PixelU: A U-Shaped Transformer for Efficient End-to-End Pixel Diffusion
Pith reviewed 2026-06-29 04:28 UTC · model grok-4.3
The pith
Under x-prediction, complex pixel decoders are redundant for end-to-end diffusion models, as PixelU replaces them with a simple U-shaped transformer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
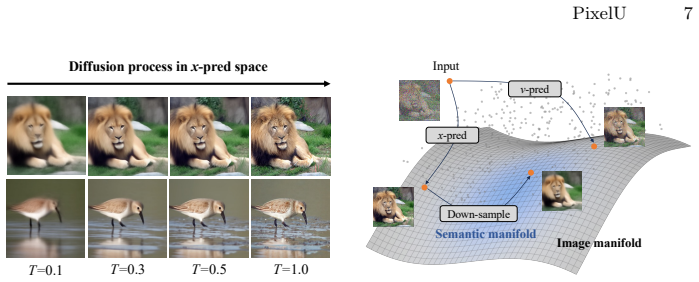
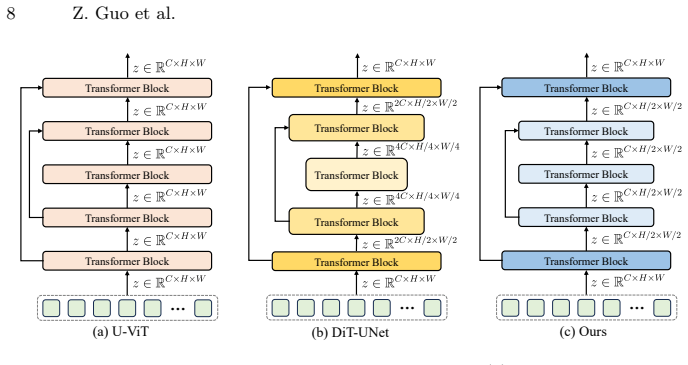
The central claim is that complex pixel decoders primarily compensate for optimization difficulties inherent to velocity prediction and become redundant under the clean data paradigm of x-prediction. PixelU therefore discards auxiliary decoders in favor of zero-cost skip connections that route uncorrupted high-frequency spatial details directly from shallow to deep layers, plus a constant-channel spatial down-sampling step that functions as a low-pass filter and compresses features into a compact low-frequency semantic manifold. This decoupling allows the backbone to focus on semantics while still recovering fine detail, yielding FID scores of 1.63 at 256×256 and 1.92 at 512×512 on ImageNet
What carries the argument
PixelU, the single-stage U-shaped Diffusion Transformer that relies on zero-cost skip connections for an information highway of high-frequency details and constant-channel spatial down-sampling as a natural low-pass filter.
If this is right
- PixelU outperforms the JiT-G baseline while using roughly one-third its computation cost.
- The model reaches FID 1.63 on ImageNet 256×256 and FID 1.92 on 512×512.
- Skip connections supply an uncorrupted high-frequency information highway without added parameters.
- Constant-channel down-sampling compresses deep features into a low-frequency semantic manifold.
- The resulting architecture supplies a simpler paradigm for end-to-end pixel diffusion.
Where Pith is reading between the lines
- The same skip-and-downsample pattern could be tested on conditional generation tasks such as text-to-image synthesis.
- Training memory and wall-clock time for full-resolution pixel diffusion would drop if the auxiliary decoder is removed.
- Similar frequency-decoupling logic might simplify other high-dimensional generative models that currently add heavy decoder heads.
Load-bearing premise
Complex pixel decoders mainly exist to solve optimization problems specific to velocity prediction and are not required once x-prediction is used instead.
What would settle it
An ablation that keeps the complex decoder while switching to x-prediction and still records substantially lower FID than PixelU would show the decoder is not redundant under that paradigm.
Figures



read the original abstract
End-to-end pixel-space diffusion models bypass the lossy compression of Latent Diffusion Models (LDMs) but struggle to jointly model low-frequency semantics and high-frequency signals in high-dimensional space. Existing works heavily rely on complex pixel decoders to alleviate this issue. In this paper, we challenge this trend by revealing that these decoders primarily compensate for the optimization difficulties inherent to velocity prediction ($v$-prediction). Under the clean data paradigm ($x$-prediction), they are redundant. Motivated by this insight, we advocate for simplicity over complexity and introduce PixelU, a minimalist, single-stage U-shaped Diffusion Transformer tailored for pixel space. PixelU abandons auxiliary decoders in favor of zero-cost skip connections, which provide an "information highway" that directly routes uncorrupted high-frequency spatial details from shallow to deep layers. To further enable the backbone to focus exclusively on modeling low-frequency semantics, we introduce a constant-channel spatial down-sampling mechanism as a natural low-pass filter, which compresses deep features into a compact, low-frequency semantic manifold. Extensive experiments demonstrate that this decoupling of frequencies could outperform the strong baseline (JiT-G) with only about 1/3 of its computation cost. On ImageNet 256$\times$256 and 512$\times$512, PixelU achieves FID of 1.63 and 1.92 respectively, surpassing recent pixel-space methods and establishing a simple yet powerful new paradigm for end-to-end diffusion models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes PixelU, a minimalist single-stage U-shaped Diffusion Transformer for end-to-end pixel-space diffusion. It argues that complex pixel decoders are redundant under the x-prediction paradigm (as they primarily compensate for optimization issues in v-prediction), and instead relies on zero-cost skip connections for high-frequency details plus constant-channel spatial downsampling as a low-pass filter for low-frequency semantics. The design is claimed to outperform the JiT-G baseline with roughly one-third the compute, achieving FID scores of 1.63 on ImageNet 256×256 and 1.92 on 512×512.
Significance. If the empirical results and the frequency-decoupling rationale hold after proper validation, the work would provide a simpler, more efficient alternative to existing pixel-space diffusion models, potentially reducing the need for auxiliary complex decoders while maintaining competitive generation quality.
major comments (2)
- [Abstract] Abstract (paragraph beginning 'we challenge this trend by revealing...'): The load-bearing claim that complex pixel decoders 'primarily compensate for the optimization difficulties inherent to velocity prediction' and are 'redundant' under x-prediction lacks isolating ablations or controlled experiments (e.g., same backbone with v- vs. x-prediction while varying decoder complexity, or reporting gradient norms/convergence metrics). The reported FID numbers demonstrate that PixelU works but do not test the causal premise used to justify abandoning auxiliary decoders.
- [Abstract] Abstract: The competitive FID scores and compute savings are presented without any details on experimental protocols, ablations, statistical significance, exact baseline implementations, or training hyperparameters, undermining the ability to confirm that the data supports the design choices and performance claims.
minor comments (1)
- [Abstract] The abstract refers to 'extensive experiments' and 'this decoupling of frequencies' but provides no table, figure, or section references for the quantitative results or ablation studies.
Simulated Author's Rebuttal
We thank the referee for the detailed review and constructive feedback on our claims and experimental reporting. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract (paragraph beginning 'we challenge this trend by revealing...'): The load-bearing claim that complex pixel decoders 'primarily compensate for the optimization difficulties inherent to velocity prediction' and are 'redundant' under x-prediction lacks isolating ablations or controlled experiments (e.g., same backbone with v- vs. x-prediction while varying decoder complexity, or reporting gradient norms/convergence metrics). The reported FID numbers demonstrate that PixelU works but do not test the causal premise used to justify abandoning auxiliary decoders.
Authors: We agree that the causal premise would be more robust with isolating experiments. Our current results demonstrate that a minimalist U-shaped architecture under x-prediction achieves strong FID without auxiliary decoders, outperforming JiT-G at lower cost, but we will add controlled ablations in the revision: identical backbones trained with v-prediction versus x-prediction, varying decoder complexity, and reporting gradient norms or convergence curves where feasible to directly test the optimization-difficulty hypothesis. revision: yes
-
Referee: [Abstract] Abstract: The competitive FID scores and compute savings are presented without any details on experimental protocols, ablations, statistical significance, exact baseline implementations, or training hyperparameters, undermining the ability to confirm that the data supports the design choices and performance claims.
Authors: We acknowledge that the abstract and current experimental section lack sufficient protocol details. In the revised manuscript we will expand the experiments section to include complete training hyperparameters, exact baseline re-implementation details, full ablation tables, and any statistical significance measures, enabling direct verification of the reported FID and compute comparisons. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's load-bearing premise—that complex pixel decoders compensate for v-prediction optimization issues and become redundant under x-prediction—is presented as an empirical observation used to motivate the PixelU architecture (skip connections plus constant-channel downsampling). No equations, fitted parameters, or self-citations are shown reducing this premise or the reported FID results (1.63/1.92 on ImageNet) back to the inputs by construction. Performance claims rest on external experimental comparisons rather than self-definitional or fitted-input reductions. The design is therefore self-contained against benchmarks and receives a score of 0.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Complex pixel decoders primarily compensate for optimization difficulties inherent to v-prediction and are redundant under x-prediction
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Bao, F., Nie, S., Xue, K., Cao, Y., Li, C., Su, H., Zhu, J.: All are worth words: A vit backbone for diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 22669–22679 (2023)
2023
-
[2]
In: International Conference on Learning Representations (ICLR) (2025)
Chen, J., Cai, H., Chen, J., Xie, E., Yang, S., Tang, H., Li, M., Lu, Y., Han, S.: Deep compression autoencoder for efficient high-resolution diffusion models. In: International Conference on Learning Representations (ICLR) (2025)
2025
-
[3]
arXiv preprint arXiv:2504.07963 (2025)
Chen, S., Ge, C., Zhang, S., Sun, P., Luo, P.: Pixelflow: Pixel-space generative models with flow. arXiv preprint arXiv:2504.07963 (2025)
-
[4]
In: International Conference on Learning Represen- tations (ICLR) (2023)
Chen, Z., Duan, Y., Wang, W., He, J., Lu, T., Dai, J., Qiao, Y.: Vision transformer adapter for dense predictions. In: International Conference on Learning Represen- tations (ICLR) (2023)
2023
-
[5]
arXiv preprint arXiv:2511.18822 (2025)
Chen, Z., Zhu, J., Chen, X., Zhang, J., Hu, X., Zhao, H., Wang, C., Yang, J., Tai, Y.: Dip: Taming diffusion models in pixel space. arXiv preprint arXiv:2511.18822 (2025)
-
[6]
Vision Transformers Need Registers
Darcet, T., Oquab, M., Mairal, J., Bojanowski, P.: Vision transformers need reg- isters. arXiv preprint arXiv:2309.16588 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
In: Ad- vancesinNeuralInformationProcessingSystems(NeurIPS).vol.34,pp.8780–8794 (2021)
Dhariwal, P., Nichol, A.: Diffusion models beat gans on image synthesis. In: Ad- vancesinNeuralInformationProcessingSystems(NeurIPS).vol.34,pp.8780–8794 (2021)
2021
-
[8]
In: Forty-first international conference on machine learning (2024)
Esser, P., Kulal, S., Blattmann, A., Entezari, R., Müller, J., Saini, H., Levi, Y., Lorenz, D., Sauer, A., Boesel, F., et al.: Scaling rectified flow transformers for high-resolution image synthesis. In: Forty-first international conference on machine learning (2024)
2024
-
[9]
Journal of the Optical Society of America A4(12), 2379–2394 (1987)
Field, D.J.: Relations between the statistics of natural images and the response properties of cortical cells. Journal of the Optical Society of America A4(12), 2379–2394 (1987)
1987
-
[10]
Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour
Goyal, P., Dollár, P., Girshick, R., Noordhuis, P., Wesolowski, L., Kyrola, A., Tul- loch, A., Jia, Y., He, K.: Accurate, large minibatch sgd: Training imagenet in 1 hour. arXiv preprint arXiv:1706.02677 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[11]
HyperDiT: Hyper-Connected Transformers for High-Fidelity Pixel-Space Diffusion
He, Y., Ma, L., Guo, Z., Shan, X., Fu, J., Chen, D., Huang, J., Li, Y.: Hyperdit: Hyper-connected transformers for high-fidelity pixel-space diffusion. arXiv preprint arXiv:2605.15741 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[12]
Advances in neural information processing systems33, 6840–6851 (2020)
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. Advances in neural information processing systems33, 6840–6851 (2020)
2020
-
[13]
Journal of Machine Learning Research (JMLR)23, 1–33 (2022)
Ho, J., Saharia, C., Chan, W., Fleet, D.J., Norouzi, M., Tim, S.: Cascaded diffusion models for high fidelity image generation. Journal of Machine Learning Research (JMLR)23, 1–33 (2022)
2022
-
[14]
Classifier-Free Diffusion Guidance
Ho, J., Salimans, T.: Classifier-free diffusion guidance. arXiv preprint arXiv:2207.12598 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[15]
In: International Conference on Machine Learning (ICML)
Hoogeboom, E., Heek, J., Salimans, T.: simple diffusion: End-to-end diffusion for high resolution images. In: International Conference on Machine Learning (ICML). pp. 13213–13232. PMLR (2023)
2023
-
[16]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Hoogeboom, E., Mensink, T., Heek, J., Lamerigts, K., Gao, R., Salimans, T.: Sim- pler diffusion: 1.5 fid on imagenet512 with pixel-space diffusion. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 18062–18071 (2025)
2025
-
[17]
arXiv preprint arXiv:2212.11972 (2022) 26 Z
Jabri, A., Fleet, D., Chen, T.: Scalable adaptive computation for iterative genera- tion. arXiv preprint arXiv:2212.11972 (2022) 26 Z. Guo et al
-
[18]
In: Advances in Neural Information Processing Systems (NeurIPS)
Kingma, D., Gao, R.: Understanding diffusion objectives as the elbo with sim- ple data augmentation. In: Advances in Neural Information Processing Systems (NeurIPS). vol. 36, pp. 65484–65516 (2023)
2023
-
[19]
Adam: A Method for Stochastic Optimization
Kingma, D.P., Ba, J.: Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014)
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[20]
Advances in Neural Information Processing Systems37, 122458– 122483 (2024)
Kynkäänniemi, T., Aittala, M., Karras, T., Laine, S., Aila, T., Lehtinen, J.: Ap- plying guidance in a limited interval improves sample and distribution quality in diffusion models. Advances in Neural Information Processing Systems37, 122458– 122483 (2024)
2024
-
[21]
In: In- ternational Conference on Learning Representations (ICLR) (2025)
Lei, J., Liu, K., Berner, J., HoiM, Y., Zheng, H., Wu, J., Chu, X.: Advancing end-to-end pixel-space generative modeling via self-supervised pre-training. In: In- ternational Conference on Learning Representations (ICLR) (2025)
2025
-
[22]
Back to Basics: Let Denoising Generative Models Denoise
Li, T., He, K.: Back to basics: Let denoising generative models denoise. arXiv preprint arXiv:2511.13720 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
arXiv preprint arXiv:2502.17437 (2025)
Li, T., Sun, Q., Fan, L., He, K.: Fractal generative models. arXiv preprint arXiv:2502.17437 (2025)
-
[24]
Advances in Neural Information Processing Systems37, 56424–56445 (2024)
Li, T., Tian, Y., Li, H., Deng, M., He, K.: Autoregressive image generation with- out vector quantization. Advances in Neural Information Processing Systems37, 56424–56445 (2024)
2024
-
[25]
Flow Matching for Generative Modeling
Lipman, Y., Chen, R.T., Ben-Hamu, H., Nickel, M., Le, M.: Flow matching for generative modeling. arXiv preprint arXiv:2210.02747 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[26]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Liu, X., Gong, C., Liu, Q.: Flow straight and fast: Learning to generate and transfer data with rectified flow. arXiv preprint arXiv:2209.03003 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[27]
FrequencyBooster: Full-Frequency Modeling for High-Fidelity Pixel Diffusion
Ma, L., Guo, Z., He, Y., Fu, X., Liu, L., Fu, J., Huang, J., Li, Y.: Frequency- booster: Full-frequency modeling for high-fidelity pixel diffusion. arXiv preprint arXiv:2605.17759 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[28]
arXiv preprint arXiv:2401.08740 (2024)
Ma, N., Goldstein, M., Albergo, M.S., Boffi, N.M., Vanden-Eijnden, E., Xie, S.: Sit: Exploring flow and diffusion-based generative models with scalable interpolant transformers. arXiv preprint arXiv:2401.08740 (2024)
-
[29]
DeCo: Frequency-Decoupled Pixel Diffusion for End-to-End Image Generation
Ma, Z., Wei, L., Wang, S., Zhang, S., Tian, Q.: Deco: Frequency-decoupled pixel diffusion for end-to-end image generation. arXiv preprint arXiv:2511.19365 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
PixelGen: Improving Pixel Diffusion with Perceptual Supervision
Ma, Z., Xu, R., Zhang, S.: Pixelgen: Pixel diffusion beats latent diffusion with perceptual loss. arXiv preprint arXiv:2602.02493 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[31]
Park, N., Kim, S.: How do vision transformers work? In: International Conference on Learning Representations (ICLR) (2022)
2022
-
[32]
Peebles,W.,Xie,S.:Scalablediffusionmodelswithtransformers.In:Proceedingsof the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 4195– 4205 (2023)
2023
-
[33]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10684–10695 (2022)
2022
-
[34]
In: International Conference on Medical image computing and computer-assisted intervention
Ronneberger, O., Fischer, P., Brox, T.: U-net: Convolutional networks for biomedi- cal image segmentation. In: International Conference on Medical image computing and computer-assisted intervention. pp. 234–241. Springer (2015)
2015
-
[35]
International journal of computer vision115(3), 211–252 (2015)
Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., Huang, Z., Karpathy, A., Khosla, A., Bernstein, M., et al.: Imagenet large scale visual recog- nition challenge. International journal of computer vision115(3), 211–252 (2015)
2015
-
[36]
In: ACM SIGGRAPH 2022 conference proceedings
Sauer, A., Schwarz, K., Geiger, A.: Stylegan-xl: Scaling stylegan to large diverse datasets. In: ACM SIGGRAPH 2022 conference proceedings. pp. 1–10 (2022) PixelU 27
2022
-
[37]
arXiv preprint arXiv:2510.15301 (2025)
Shi, M., Wang, H., Zheng, W., Yuan, Z., Wu, X., Wang, X., Wan, P., Zhou, J., Lu, J.: Latent diffusion model without variational autoencoder. arXiv preprint arXiv:2510.15301 (2025)
-
[38]
In: Advances in Neural Information Processing Systems (NeurIPS)
Si, C., Yu, W., Zhou, P., Zhou, Y., Wang, X., Yan, S.: Inception transformer. In: Advances in Neural Information Processing Systems (NeurIPS). vol. 35, pp. 23495–23509 (2022)
2022
- [39]
-
[40]
Denoising Diffusion Implicit Models
Song, J., Meng, C., Ermon, S.: Denoising diffusion implicit models. arXiv preprint arXiv:2010.02502 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[41]
In: Interna- tional Conference on Learning Representations (ICLR) (2021)
Song, Y., Sohl-Dickstein, J., Kingma, D.P., Kumar, A., Ermon, S., Poole, B.: Score- based generative modeling through stochastic differential equations. In: Interna- tional Conference on Learning Representations (ICLR) (2021)
2021
-
[42]
arXiv preprint arXiv:2309.03350 (2023)
Teng, J., Zheng, W., Ding, M., Hong, W., Wangni, J., Yang, Z., Tang, J.: Relay diffusion: Unifying diffusion process across resolutions for image synthesis. arXiv preprint arXiv:2309.03350 (2023)
-
[43]
arXiv preprint arXiv:2503.18414 (2025)
Tian, Y., Chen, H., Zheng, M., Liang, Y., Xu, C., Wang, Y.: U-repa: Aligning diffusion u-nets to vits. arXiv preprint arXiv:2503.18414 (2025)
-
[45]
Advances in Neural Information Processing Systems37, 51994–52013 (2024)
Tian, Y., Tu, Z., Chen, H., Hu, J., Xu, C., Wang, Y.: U-dits: Downsample tokens in u-shaped diffusion transformers. Advances in Neural Information Processing Systems37, 51994–52013 (2024)
2024
-
[46]
Network: computa- tion in neural systems14(3), 391 (2003)
Torralba, A., Oliva, A.: Statistics of natural image categories. Network: computa- tion in neural systems14(3), 391 (2003)
2003
-
[47]
arXiv preprint arXiv:2411.19722 (2024)
Tschannen, M., Pinto, A.S., Kolesnikov, A.: Jetformer: An autoregressive genera- tive model of raw images and text. arXiv preprint arXiv:2411.19722 (2024)
-
[48]
arXiv preprint arXiv:2507.23268 (2025)
Wang, S., Gao, Z., Zhu, C., Huang, W., Wang, L.: Pixnerd: Pixel neural field diffusion. arXiv preprint arXiv:2507.23268 (2025)
-
[49]
arXiv preprint arXiv:2504.05741 (2025)
Wang, S., Tian, Z., Huang, W., Wang, L.: Ddt: Decoupled diffusion transformer. arXiv preprint arXiv:2504.05741 (2025)
-
[50]
Advances in Neural Information Processing Systems36, 27745–27782 (2023)
Williams, C., Falck, F., Deligiannidis, G., Holmes, C.C., Doucet, A., Syed, S.: A unified framework for u-net design and analysis. Advances in Neural Information Processing Systems36, 27745–27782 (2023)
2023
-
[51]
generation: Taming optimization dilemma in latent diffusion models
Yao, J., Yang, B., Wang, X.: Reconstruction vs. generation: Taming optimization dilemma in latent diffusion models. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 15703–15712 (2025)
2025
-
[52]
In: International Conference on Learning Representations (ICLR) (2025)
Yu, S., Kwak, S., Jang, H., Jeong, J., Huang, J., Shin, J., Xie, S.: Representation alignment for generation: Training diffusion transformers is easier than you think. In: International Conference on Learning Representations (ICLR) (2025)
2025
-
[53]
PixelDiT: Pixel Diffusion Transformers for Image Generation
Yu, Y., Xiong, W., Nie, W., Sheng, Y., Liu, S., Luo, J.: Pixeldit: Pixel diffusion transformers for image generation. arXiv preprint arXiv:2511.20645 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[54]
arXiv preprint arXiv:2412.06329 (2024)
Zhai, S., Zhang, R., Nakkiran, P., Berthelot, D., Gu, J., Zheng, H., Chen, T., Bautista, M.A., Jaitly, N., Susskind, J.: Normalizing flows are capable generative models. arXiv preprint arXiv:2412.06329 (2024)
-
[55]
Diffusion Transformers with Representation Autoencoders
Zheng, B., Ma, N., Tong, S., Xie, S.: Diffusion transformers with representation autoencoders. arXiv preprint arXiv:2510.11690 (2025) 28 Z. Guo et al
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[56]
arXiv preprint arXiv:2510.23588 (2025)
Zheng, G., Zhao, Q., Yang, T., Xiao, F., Lin, Z., Wu, J., Deng, J., Zhang, Y., Zhu, R.: Farmer: Flow autoregressive transformer over pixels. arXiv preprint arXiv:2510.23588 (2025)
-
[57]
arXiv preprint arXiv:2306.09305 (2023)
Zheng, H., Nie, W., Vahdat, A., Anandkumar, A.: Fast training of diffusion models with masked transformers. arXiv preprint arXiv:2306.09305 (2023)
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.