Video-MME-Logical: A Controlled Diagnostic Benchmark for Video Temporal-Logical Reasoning
Pith reviewed 2026-06-29 04:51 UTC · model grok-4.3
The pith
Video-MME-Logical creates a controlled benchmark around five temporal-logical operations to measure how MLLMs maintain and compose evidence across video frames.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that a benchmark built on five temporal-logical operations with controlled generation accurately diagnoses video temporal-logical reasoning in MLLMs, that current models exhibit a substantial and complexity-dependent gap relative to humans, and that supervised fine-tuning on hundreds of thousands of samples narrows but does not eliminate this gap.
What carries the argument
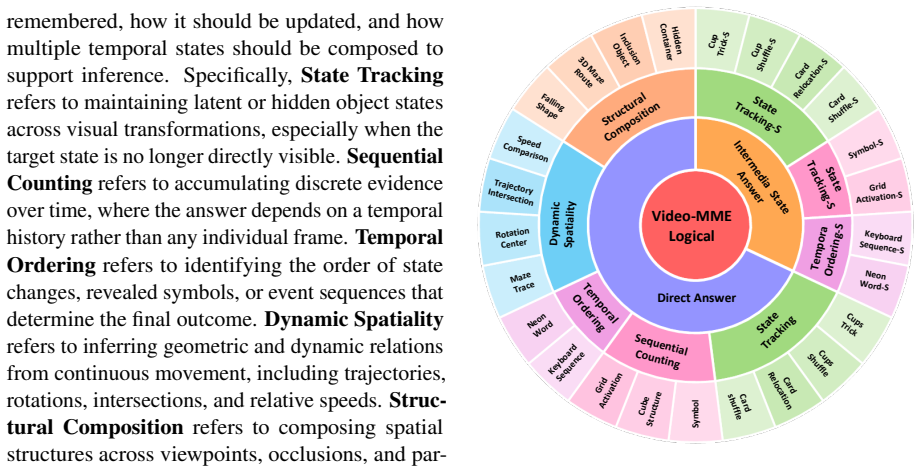
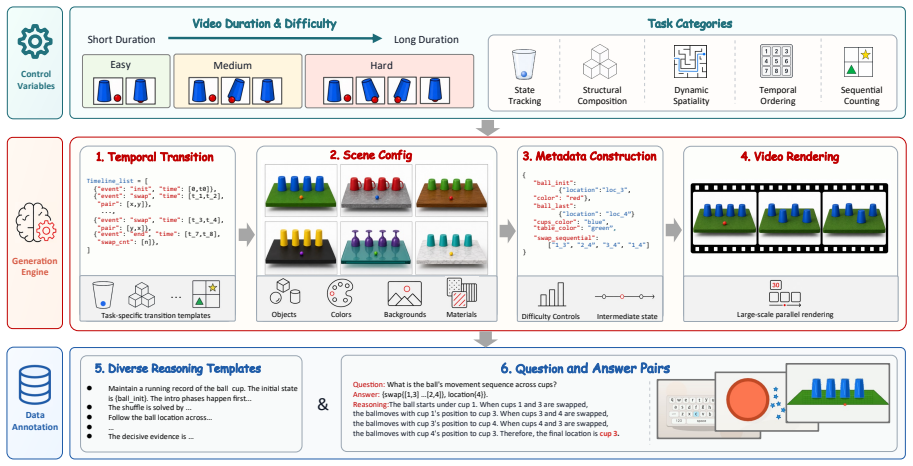
The five temporal-logical operations (state tracking, sequential counting, temporal ordering, dynamic spatiality, structural composition) together with controlled generation of tasks that vary temporal horizon and reasoning complexity.
If this is right
- Gaps between models and humans increase as temporal horizon and logical complexity rise.
- Supervised fine-tuning on 500K samples improves scores but leaves a remaining gap.
- The benchmark supports diagnostic checks on whether models recover the required reasoning trace before the final answer.
- The construction positions the benchmark as a scalable testbed for further analysis of temporal-logical capabilities.
Where Pith is reading between the lines
- Architectures may need explicit mechanisms for updating and composing states across frames rather than relying on next-token prediction alone.
- The same controlled-generation approach could be applied to isolate other forms of dynamic reasoning such as causal or counterfactual inference in video.
- Persistent gaps after large-scale fine-tuning suggest that data scale alone may not suffice and that new objectives or memory structures warrant testing.
Load-bearing premise
The five operations and controlled generation process isolate temporal-logical reasoning without being affected by static object recognition or uncontrolled scene factors.
What would settle it
A result in which models reach human-level accuracy on the benchmark yet still fail to maintain or compose evidence correctly on matched real-world videos that require the same operations.
Figures










read the original abstract
Recent interest in multimodal large language models (MLLMs) raises a central question: can they reason over dynamic visual evidence rather than merely recognize objects or events in individual frames? This ability, which we refer to as video temporal-logical reasoning, requires models to maintain, update, and compose evidence as visual states evolve across frames. Existing video benchmarks often conflate this capability with scene complexity, static recognition, or uncontrolled temporal variation. To isolate this capability, we introduce Video-MME-Logical, a controlled benchmark organized around five temporal-logical operations: state tracking, sequential counting, temporal ordering, dynamic spatiality, and structural composition. The benchmark contains 25 fine-grained task categories generated with controlled object states, transitions, temporal dependencies, and logical compositions. It enables difficulty-controlled final-answer evaluation by varying temporal horizon and reasoning complexity, and supports intermediate-state diagnostics by verifying whether models recover the required logical reasoning trace before producing the final answer. Experiments with state-of-the-art MLLMs reveal a substantial human-model gap, especially as temporal-logical complexity increases. Supervised fine-tuning on up to 500K generated samples improves performance but remains insufficient to close the reasoning gap, positioning Video-MME-Logical as a scalable testbed for analyzing and improving temporal-logical reasoning in MLLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Video-MME-Logical, a controlled diagnostic benchmark for video temporal-logical reasoning in MLLMs. It organizes evaluation around five operations (state tracking, sequential counting, temporal ordering, dynamic spatiality, structural composition) realized in 25 fine-grained task categories via controlled generation of object states, transitions, and logical compositions. The benchmark supports difficulty scaling by temporal horizon and complexity, plus intermediate-state diagnostics. Experiments on SOTA MLLMs show a substantial human-model gap that widens with complexity; supervised fine-tuning on up to 500K generated samples yields gains but does not close the gap.
Significance. If the controlled generation and diagnostic protocol successfully isolate temporal-logical reasoning without confounding by static recognition or scene complexity, the benchmark would supply a scalable, falsifiable testbed for a capability that current video benchmarks largely conflate with other skills. The reported persistence of the gap after large-scale SFT would indicate a genuine limitation worth targeted architectural or training research.
minor comments (4)
- The abstract and introduction refer to 'controlled object states, transitions, temporal dependencies, and logical compositions' and 'intermediate-state diagnostics' but the manuscript should supply explicit pseudocode or a figure detailing the generation pipeline and the exact verification procedure for the reasoning trace (e.g., how intermediate states are extracted and scored).
- Table or figure reporting per-operation and per-complexity human vs. model accuracies (with standard errors) is needed to substantiate the claim that the gap 'especially' increases with temporal-logical complexity; aggregate numbers alone are insufficient.
- The SFT protocol (data volume, sampling strategy, base model, training hyperparameters, and whether the 500K samples overlap with the benchmark) should be described in a dedicated subsection so that the 'remains insufficient' conclusion can be reproduced or extended.
- Clarify the exact definition of 'temporal horizon' and 'reasoning complexity' used for difficulty control, and report how many videos fall into each bin.
Simulated Author's Rebuttal
We thank the referee for the positive summary of Video-MME-Logical and the recommendation for minor revision. The summary accurately reflects the benchmark's design around the five operations, controlled generation, and experimental findings on the human-model gap.
Circularity Check
Benchmark construction with no derivations or fitted predictions
full rationale
The paper introduces Video-MME-Logical as a controlled benchmark organized around five temporal-logical operations, generated with explicit states, transitions, and compositions. No equations, parameter fittings, predictions derived from prior fits, or self-citation chains appear in the abstract or described methods. The central claims concern benchmark isolation of capabilities and experimental reporting of model gaps after SFT; these do not reduce to self-referential inputs by construction. The work is self-contained as diagnostic data generation and evaluation, with no load-bearing steps matching the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The five operations (state tracking, sequential counting, temporal ordering, dynamic spatiality, structural composition) isolate the target capability.
Reference graph
Works this paper leans on
-
[1]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Qwen2.5-VL Technical Report , author=. arXiv preprint arXiv:2502.13923 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Qwen3-VL Technical Report , author=. arXiv preprint arXiv:2511.21631 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency , author=. arXiv preprint arXiv:2508.18265 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Transactions on Machine Learning Research , year=
LLaVA-Video: Video Instruction Tuning With Synthetic Data , author=. Transactions on Machine Learning Research , year=
-
[6]
Kimi-VL Technical Report , author=. arXiv preprint arXiv:2504.07491 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
2026 , howpublished=
Introducing GPT-5.4 , author=. 2026 , howpublished=
2026
-
[8]
2025 , howpublished=
Gemini 3 Pro Model Card , author=. 2025 , howpublished=
2025
-
[9]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , month =
Fu, Chaoyou and Dai, Yuhan and Luo, Yongdong and Li, Lei and Ren, Shuhuai and Zhang, Renrui and Wang, Zihan and Zhou, Chenyu and Shen, Yunhang and Zhang, Mengdan and Chen, Peixian and Li, Yanwei and Lin, Shaohui and Zhao, Sirui and Li, Ke and Xu, Tong and Zheng, Xiawu and Chen, Enhong and Shan, Caifeng and He, Ran and Sun, Xing , title =. Proceedings of t...
2025
-
[10]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Zhou, Junjie and Shu, Yan and Zhao, Bo and Wu, Boya and Liang, Zhengyang and Xiao, Shitao and Qin, Minghao and Yang, Xi and Xiong, Yongping and Zhang, Bo and Huang, Tiejun and Liu, Zheng , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2025 , pages =
2025
-
[11]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
ALLVB: All-in-One Long Video Understanding Benchmark , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[12]
LongVideoBench: A Benchmark for Long-context Interleaved Video-Language Understanding , url =
Wu, Haoning and Li, Dongxu and Chen, Bei and Li, Junnan , booktitle =. LongVideoBench: A Benchmark for Long-context Interleaved Video-Language Understanding , url =. doi:10.52202/079017-0907 , editor =
-
[13]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
LVBench: An Extreme Long Video Understanding Benchmark , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[14]
arXiv preprint arXiv:2405.08813 , year=
CinePile: A Long Video Question Answering Dataset and Benchmark , author=. arXiv preprint arXiv:2405.08813 , year=
-
[15]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
MovieChat: From Dense Token to Sparse Memory for Long Video Understanding , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[16]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Li, Kunchang and Wang, Yali and He, Yinan and Li, Yizhuo and Wang, Yi and Liu, Yi and Wang, Zun and Xu, Jilan and Chen, Guo and Luo, Ping and Wang, Limin and Qiao, Yu , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2024 , pages =
2024
-
[17]
Advances in Neural Information Processing Systems , volume=
EgoSchema: A Diagnostic Benchmark for Very Long-form Video Language Understanding , author=. Advances in Neural Information Processing Systems , volume=. 2023 , url=
2023
-
[18]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Ego4D: Around the World in 3,000 Hours of Egocentric Video , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[19]
Perception Test: A Diagnostic Benchmark for Multimodal Video Models , url =
Patraucean, Viorica and Smaira, Lucas and Gupta, Ankush and Recasens, Adria and Markeeva, Larisa and Banarse, Dylan and Koppula, Skanda and heyward, joseph and Malinowski, Mateusz and Yang, Yi and Doersch, Carl and Matejovicova, Tatiana and Sulsky, Yury and Miech, Antoine and Fr\'. Perception Test: A Diagnostic Benchmark for Multimodal Video Models , url ...
-
[20]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
NExT-QA: Next Phase of Question-Answering to Explaining Temporal Actions , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
-
[21]
Advances in Neural Information Processing Systems , volume=
STAR: A Benchmark for Situated Reasoning in Real-World Videos , author=. Advances in Neural Information Processing Systems , volume=. 2021 , url=
2021
-
[22]
Computer Vision -
Shicheng Li and Lei Li and Yi Liu and Shuhuai Ren and Yuanxin Liu and Rundong Gao and Xu Sun and Lu Hou , title =. Computer Vision -
-
[23]
arXiv preprint arXiv:2501.10674 , year=
Can Multimodal LLMs do Visual Temporal Understanding and Reasoning? The answer is No! , author=. arXiv preprint arXiv:2501.10674 , year=
-
[24]
The Thirteenth International Conference on Learning Representations , year=
TOMATO: Assessing Visual Temporal Reasoning Capabilities in Multimodal Foundation Models , author=. The Thirteenth International Conference on Learning Representations , year=
-
[25]
Liu, Yuanxin and Li, Shicheng and Liu, Yi and Wang, Yuxiang and Ren, Shuhuai and Li, Lei and Chen, Sishuo and Sun, Xu and Hou, Lu , booktitle=. 2024 , address=. doi:10.18653/v1/2024.findings-acl.517 , url=
-
[26]
Advances in Neural Information Processing Systems , volume=
ReXTime: A Benchmark Suite for Reasoning-Across-Time in Videos , author=. Advances in Neural Information Processing Systems , volume=. 2024 , doi=
2024
-
[27]
VideoReasonBench: Can
Yuanxin Liu and Kun Ouyang and Haoning Wu and Yi Liu and Lin Sui and Xinhao Li and Yan Zhong and Y.Charles and Xinyu Zhou and Xu Sun , booktitle=. VideoReasonBench: Can
-
[28]
arXiv preprint arXiv:2503.11495 , year=
V-STaR: Benchmarking Video-LLMs on Video Spatio-Temporal Reasoning , author=. arXiv preprint arXiv:2503.11495 , year=
-
[29]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , year=
CLEVR: A Diagnostic Dataset for Compositional Language and Elementary Visual Reasoning , author=. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , year=
-
[30]
arXiv preprint arXiv:2510.05091 , year=
Factuality Matters: When Image Generation and Editing Meet Structured Visuals , author=. arXiv preprint arXiv:2510.05091 , year=
-
[31]
International Conference on Learning Representations , year=
CLEVRER: Collision Events for Video Representation and Reasoning , author=. International Conference on Learning Representations , year=
-
[32]
Cognitive psychology , volume=
The reviewing of object files: Object-specific integration of information , author=. Cognitive psychology , volume=. 1992 , publisher=
1992
-
[33]
Cognition , volume=
Visual indexes, preconceptual objects, and situated vision , author=. Cognition , volume=. 2001 , publisher=
2001
-
[34]
Vision research , volume=
Visual cognition , author=. Vision research , volume=. 2011 , publisher=
2011
-
[35]
2026 , eprint=
Video-MME-v2: Towards the Next Stage in Benchmarks for Comprehensive Video Understanding , author=. 2026 , eprint=
2026
-
[36]
Qwen3. 5-omni technical report , author=. arXiv preprint arXiv:2604.15804 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
2026 , eprint=
GLM-4.5V and GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning , author=. 2026 , eprint=
2026
-
[38]
Deepseek-v3 technical report , author=. arXiv preprint arXiv:2412.19437 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[39]
arXiv preprint arXiv:2603.08436 , year=
Can Vision-Language Models Solve the Shell Game? , author=. arXiv preprint arXiv:2603.08436 , year=
-
[40]
arXiv preprint arXiv:2602.20159 , year=
A very big video reasoning suite , author=. arXiv preprint arXiv:2602.20159 , year=
-
[41]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Videoespresso: A large-scale chain-of-thought dataset for fine-grained video reasoning via core frame selection , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[42]
arXiv preprint arXiv:2506.01908 , year=
Reinforcement learning tuning for videollms: Reward design and data efficiency , author=. arXiv preprint arXiv:2506.01908 , year=
-
[43]
Advances in Neural Information Processing Systems , volume=
Robocerebra: A large-scale benchmark for long-horizon robotic manipulation evaluation , author=. Advances in Neural Information Processing Systems , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.