OrthoTryOn: Geometric Orthogonalization for Conflict-Free Unified Fashion Generation
Pith reviewed 2026-06-29 04:26 UTC · model grok-4.3
The pith
Task-specific orthogonal rotations in a shared LoRA map fashion tasks into decorrelated frames to remove gradient conflicts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
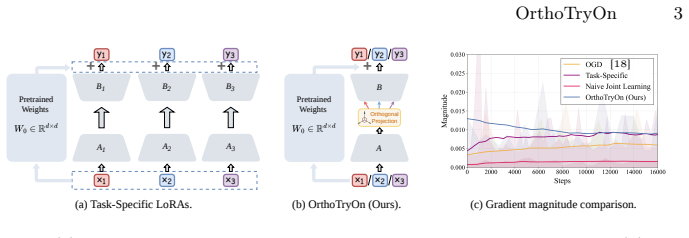
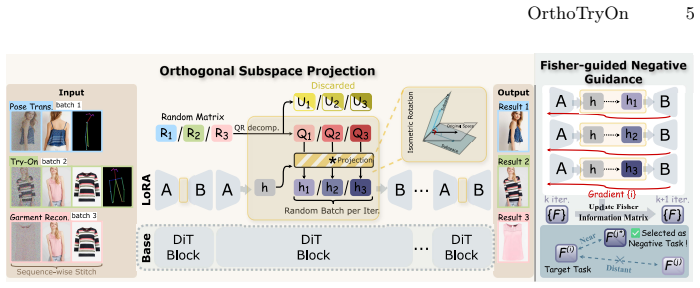
OrthoTryOn mitigates inter-task interference by applying Orthogonal Subspace Projection (OSP) that rotates bottleneck features with task-specific orthogonal matrices inside the shared LoRA module, placing each task in a decorrelated coordinate frame. Fisher-guided Negative Guidance (FNG) then uses the diagonal of the Fisher information matrix to measure sensitivity overlap and repels the sampling trajectory from the most confusable task via classifier-free guidance. Experiments confirm that this approach eliminates the severe degradation seen in naive unified training and surpasses independently trained models across multiple benchmarks while remaining compatible with diverse diffusion archi
What carries the argument
Orthogonal Subspace Projection (OSP) that applies task-specific orthogonal rotations to bottleneck features inside the shared LoRA module.
If this is right
- Unified training on multiple fashion tasks becomes feasible without the performance penalty of naive parameter sharing.
- The single model exceeds the accuracy of independently trained task-specific models on virtual try-on and garment reconstruction benchmarks.
- The same orthogonalization pattern works across multiple diffusion backbones without retraining the core architecture.
- Fisher-guided negative guidance removes residual task overlap at inference time with no added trainable parameters.
Where Pith is reading between the lines
- The same rotation-based separation could be tested on other multi-task generative problems such as simultaneous editing and captioning.
- Shared adapters with geometric decorrelation might cut the total compute needed when expanding a fashion model to additional output styles.
- Applying the method outside clothing domains would test whether the decorrelation benefit is specific to visual fashion semantics or holds more generally.
Load-bearing premise
That task-specific orthogonal rotations on bottleneck features will map the tasks into sufficiently decorrelated spaces without discarding important task information.
What would settle it
A controlled run in which OSP is added to the shared LoRA yet measured gradient conflicts between tasks stay high or final image quality remains below that of separate models.
Figures




read the original abstract
Unified fashion generation integrates tasks like virtual try-on and garment reconstruction into a single model to reduce task-specific adaptation costs. However, naive parameter sharing across semantically distinct tasks induces negative transfer through severe inter-task gradient conflict. We propose OrthoTryOn, a unified framework mitigating this interference within a shared Low-Rank Adaptation (LoRA) module. Its Orthogonal Subspace Projection (OSP) applies task-specific orthogonal rotations to bottleneck features, mapping them into decorrelated coordinate frames. To address residual semantic coupling at inference time, we further propose Fisher-guided Negative Guidance (FNG), a parameter-free strategy that utilizes diagonal Fisher information to quantify inter-task sensitivity overlap and explicitly repels generation trajectories from the most confusable task via Classifier-Free Guidance. Extensive experiments demonstrate that OrthoTryOn avoids the severe performance degradation typical of naive unified training and even surpasses independently trained task-specific models, achieving state-of-the-art results across multiple benchmarks while generalizing robustly across diverse diffusion backbones. Code is available at https://github.com/NJU-PCALab/OrthoTryOn.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces OrthoTryOn, a unified framework for fashion generation tasks such as virtual try-on and garment reconstruction. It uses a shared LoRA module with Orthogonal Subspace Projection (OSP) that applies task-specific orthogonal rotations to bottleneck features to map them into decorrelated frames, reducing gradient conflicts. Additionally, Fisher-guided Negative Guidance (FNG) is proposed to handle residual semantic coupling at inference using diagonal Fisher information. The authors claim that this approach avoids the performance degradation of naive unified training, surpasses task-specific models, and achieves state-of-the-art results on multiple benchmarks, generalizing across diffusion backbones.
Significance. If the results hold, this work would be significant for multi-task learning in generative models, particularly in reducing the cost of maintaining separate models for related fashion tasks. The geometric approach to orthogonalization and the parameter-free FNG are novel contributions. The release of code supports reproducibility.
major comments (2)
- [§3.2] §3.2: The OSP method applies fixed orthogonal matrices R_t to the bottleneck activation h so that the projected features R_t h lie in mutually orthogonal frames. However, if the original features contain linearly inseparable semantic components shared between tasks (e.g., garment shape cues between try-on and reconstruction), the rotation may project out part of the signal or leave residual coupling; no analytic bound is provided showing that the retained subspace still spans the task-specific manifold.
- [Experiments] Experiments (quantitative tables and ablations): The central claim that the unified model matches or exceeds independently trained task-specific baselines requires detailed ablation studies, quantitative tables with error bars, and cross-backbone comparisons to evaluate whether OSP and FNG deliver the reported gains without substantial loss of task-relevant information.
minor comments (1)
- Clarify whether the diagonal Fisher information in FNG is computed once per task or updated during training, and specify the exact form of the negative guidance scale.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential significance of OrthoTryOn for multi-task generative modeling. We address each major comment below with clarifications and commitments to revision where appropriate.
read point-by-point responses
-
Referee: [§3.2] The OSP method applies fixed orthogonal matrices R_t to the bottleneck activation h so that the projected features R_t h lie in mutually orthogonal frames. However, if the original features contain linearly inseparable semantic components shared between tasks (e.g., garment shape cues between try-on and reconstruction), the rotation may project out part of the signal or leave residual coupling; no analytic bound is provided showing that the retained subspace still spans the task-specific manifold.
Authors: We appreciate this theoretical observation. OSP is motivated by the empirical observation that task-specific directions in the shared LoRA bottleneck can be decorrelated via fixed orthogonal rotations, and our experiments (including component ablations in Section 4) show that the unified model preserves or improves task performance relative to independent baselines. This suggests that, in practice, the projected subspaces retain sufficient task-relevant information. We agree that an analytic bound on subspace preservation would be desirable but is non-trivial to derive for high-dimensional diffusion features and lies outside the current scope; we will add a limitations paragraph discussing this point and possible future analysis in the revision. revision: partial
-
Referee: [Experiments] Experiments (quantitative tables and ablations): The central claim that the unified model matches or exceeds independently trained task-specific baselines requires detailed ablation studies, quantitative tables with error bars, and cross-backbone comparisons to evaluate whether OSP and FNG deliver the reported gains without substantial loss of task-relevant information.
Authors: We agree that stronger experimental support would improve the manuscript. The current version already contains quantitative comparisons and component ablations demonstrating that OSP and FNG are responsible for the observed gains. In the revision we will expand these with (i) additional ablation tables isolating each component, (ii) error bars computed from multiple random seeds, and (iii) results on further diffusion backbones beyond those already reported, to confirm that the improvements hold without loss of task-specific fidelity. revision: yes
- Deriving a rigorous analytic bound guaranteeing that OSP retains the full task-specific manifold when input features contain linearly inseparable shared components.
Circularity Check
No circularity: empirical method with independent experimental validation
full rationale
The paper introduces OSP as a geometric rotation applied to LoRA bottlenecks and FNG as a Fisher-based guidance term, both defined directly from first principles without reference to the final performance metrics. Claims of unified training outperforming task-specific models are supported solely by benchmark experiments rather than any equation that re-derives the improvement from the same fitted quantities. No self-citation chains, fitted-input predictions, or ansatz smuggling appear in the provided sections. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
An, X., Zhao, L., Gong, C., Wang, N., Wang, D., Yang, J.: Sharpose: Sparse high- resolutionrepresentationforhumanposeestimation.In:AAAI.vol.38,pp.691–699 (2024)
2024
-
[2]
In: ICML
Arjovsky, M., Shah, A., Bengio, Y.: Unitary evolution recurrent neural networks. In: ICML. pp. 1120–1128. PMLR (2016)
2016
-
[3]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., et al.: Qwen2. 5-vl technical report. arXiv preprint arXiv:2502.13923 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
arXiv preprint arXiv:2603.09111 (2026)
Bao, J., Qian, J., Yan, M., Yang, J.: Progressive representation learning for multimodal sentiment analysis with incomplete modalities. arXiv preprint arXiv:2603.09111 (2026)
-
[5]
In: AAAI
Bi, J., Wu, Q., Qian, J., Luo, L., Yang, J.: Dual manifold regularization steered robust representation learning for point cloud analysis. In: AAAI. vol. 39, pp. 1844–1852 (2025)
2025
-
[6]
In: ICLR (2018)
Bińkowski, M., Sutherland, D.J., Arbel, M., Gretton, A.: Demystifying mmd gans. In: ICLR (2018)
2018
-
[7]
In: CVPR
Chen, X., Huang, L., Liu, Y., Shen, Y., Zhao, D., Zhao, H.: Anydoor: Zero-shot object-level image customization. In: CVPR. pp. 6593–6602 (2024)
2024
-
[8]
In: ECAI (2023)
Chen, Z., Gao, R., Xiang, T.Z., Lin, F.: Diffusion model for camouflaged object detection. In: ECAI (2023)
2023
-
[9]
In: ICCV
Chen, Z., Li, Y., Wang, H., Chen, Z., Jiang, Z., Li, J., Wang, Q., Yang, J., Tai, Y.: Ragd: Regional-aware diffusion model for text-to-image generation. In: ICCV. pp. 19331–19341 (2025)
2025
-
[10]
L2P: Unlocking Latent Potential for Pixel Generation
Chen, Z., Zhu, J., Chen, X., Zhang, J., Chen, J., Zeng, Z., Zhang, W., Wang, C., Yang, J., Tai, Y.: L2p: Unlocking latent potential for pixel generation. arXiv preprint arXiv:2605.12013 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[11]
In: CVPR
Chen, Z., Zhu, J., Chen, X., Zhang, J., Hu, X., Zhao, H., Wang, C., Yang, J., Tai, Y.: Dip: Taming diffusion models in pixel space. In: CVPR. pp. 36136–36146 (2026)
2026
-
[12]
In: CVPR
Choi, S., Park, S., Lee, M., Choo, J.: Viton-hd: High-resolution virtual try-on via misalignment-aware normalization. In: CVPR. pp. 14131–14140 (2021) 16 Yang et al
2021
-
[13]
In: ECCV
Choi, Y., Kwak, S., Lee, K., Choi, H., Shin, J.: Improving diffusion models for authentic virtual try-on in the wild. In: ECCV. pp. 206–235. Springer (2024)
2024
-
[14]
In: ICLR (2025)
Chong, Z., Dong, X., Li, H., Zhang, S., Zhang, W., Zhang, X., Zhao, H., Jiang, D., Liang, X.: Catvton: Concatenation is all you need for virtual try-on with diffusion models. In: ICLR (2025)
2025
-
[15]
IEEE TPAMI44(5), 2567–2581 (2020)
Ding, K., Ma, K., Wang, S., Simoncelli, E.P.: Image quality assessment: Unifying structure and texture similarity. IEEE TPAMI44(5), 2567–2581 (2020)
2020
-
[16]
In: CVPR
Ding, T., Yang, H., Shi, L., Li, J., Hu, X., Yang, J., Tai, Y.: Adaptive depth lightweight rgb-t tracking with holistic token routing. In: CVPR. pp. 20942–20952 (2026)
2026
-
[17]
IEEE TPAMI47(4), 2865–2881 (2025)
Du, Y., Zhan, J., Li, X., Dong, J., Chen, S., Yang, M.H., He, S.: One-for-all: towards universal domain translation with a single stylegan. IEEE TPAMI47(4), 2865–2881 (2025)
2025
-
[18]
In: AISTATS
Farajtabar, M., Azizan, N., Mott, A., Li, A.: Orthogonal gradient descent for con- tinual learning. In: AISTATS. pp. 3762–3773. PMLR (2020)
2020
-
[19]
In: CVPR
Güler, R.A., Neverova, N., Kokkinos, I.: Densepose: Dense human pose estimation in the wild. In: CVPR. pp. 7297–7306 (2018)
2018
-
[20]
In: ICCV
Guo, H., Zeng, B., Song, Y., Zhang, W., Zhang, C., Liu, J.: Any2anytryon: Lever- aging adaptive position embeddings for versatile virtual clothing tasks. In: ICCV. pp. 19085–19096 (2025)
2025
-
[21]
In: ICCV
Han, X., Zhu, X., Deng, J., Song, Y.Z., Xiang, T.: Controllable person image synthesis with pose-constrained latent diffusion. In: ICCV. pp. 22768–22777 (2023)
2023
-
[22]
In: CVPR
Han, X., Wu, Z., Wu, Z., Yu, R., Davis, L.S.: Viton: An image-based virtual try-on network. In: CVPR. pp. 7543–7552 (2018)
2018
-
[23]
Classifier-Free Diffusion Guidance
Ho, J., Salimans, T.: Classifier-free diffusion guidance. arXiv preprint arXiv:2207.12598 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[24]
In: ICML
Houlsby, N., Giurgiu, A., Jastrzebski, S., Morrone, B., De Laroussilhe, Q., Ges- mundo, A., Attariyan, M., Gelly, S.: Parameter-efficient transfer learning for nlp. In: ICML. pp. 2790–2799. PMLR (2019)
2019
-
[25]
In: ICLR (2022)
Hu, E.J., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W., et al.: Lora: Low-rank adaptation of large language models. In: ICLR (2022)
2022
-
[26]
In: AAAI
Hu,X.,Tai,Y.,Zhao,X.,Zhao,C.,Zhang,Z.,Li,J.,Zhong,B.,Yang,J.:Exploiting multimodal spatial-temporal patterns for video object tracking. In: AAAI. vol. 39, pp. 3581–3589 (2025)
2025
-
[27]
arXiv preprint arXiv:2411.10499 (2024)
Jiang, B., Hu, X., Luo, D., He, Q., Xu, C., Peng, J., Zhang, J., Wang, C., Wu, Y., Fu, Y.: Fitdit: Advancing the authentic garment details for high-fidelity virtual try-on. arXiv preprint arXiv:2411.10499 (2024)
-
[28]
In: ECCV
Jin, J., Shen, Y., Fu, Z., Yang, J.: Customized generation reimagined: Fidelity and editability harmonized. In: ECCV. pp. 410–426. Springer (2024)
2024
-
[29]
In: CVPR
Jin, J., Yu, Z., Shen, Y., Fu, Z., Yang, J.: Latexblend: Scaling multi-concept customized generation with latent textual blending. In: CVPR. pp. 23585–23594 (2025)
2025
-
[30]
PNAS114(13), 3521–3526 (2017)
Kirkpatrick, J., Pascanu, R., Rabinowitz, N., Veness, J., Desjardins, G., Rusu, A.A., Milan, K., Quan, J., Ramalho, T., Grabska-Barwinska, A., et al.: Overcoming catastrophic forgetting in neural networks. PNAS114(13), 3521–3526 (2017)
2017
-
[31]
Labs, B.F.: Flux.https://github.com/black-forest-labs/flux(2024)
2024
-
[32]
Labs, B.F.: Flux.2.https://github.com/black-forest-labs/flux2(2025)
2025
-
[33]
In: ECCV
Lee, S., Gu, G., Park, S., Choi, S., Choo, J.: High-resolution virtual try-on with misalignment and occlusion-handled conditions. In: ECCV. pp. 204–219. Springer (2022) OrthoTryOn 17
2022
-
[34]
In: EMNLP
Lester, B., Al-Rfou, R., Constant, N.: The power of scale for parameter-efficient prompt tuning. In: EMNLP. pp. 3045–3059 (2021)
2021
-
[35]
Lezcano-Casado, M., Martınez-Rubio, D.: Cheap orthogonal constraints in neural networks:Asimpleparametrizationoftheorthogonalandunitarygroup.In:ICML. pp. 3794–3803. PMLR (2019)
2019
-
[36]
Li, X.L., Liang, P.: Prefix-tuning: Optimizing continuous prompts for generation. In: ACL. pp. 4582–4597 (2021)
2021
-
[37]
In: AAAI
Li, X., Zhan, J., He, S., Xu, Y., Dong, J., Zhang, H., Du, Y.: Personamagic: Stage- regulated high-fidelity face customization with tandem equilibrium. In: AAAI. vol. 39, pp. 4995–5003 (2025)
2025
-
[38]
In: CVPR
Liu, J., Zhang, J., Rota, P., Sebe, N.: Multi-focal conditioned latent diffusion for person image synthesis. In: CVPR. pp. 16019–16028 (2025)
2025
-
[39]
In: CVPR
Liu, Z., Luo, P., Qiu, S., Wang, X., Tang, X.: Deepfashion: Powering robust clothes recognition and retrieval with rich annotations. In: CVPR. pp. 1096–1104 (2016)
2016
-
[40]
In: ICLR (2019)
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. In: ICLR (2019)
2019
-
[41]
In: CVPR
Lu, Y., Zhang, M., Ma, A.J., Xie, X., Lai, J.: Coarse-to-fine latent diffusion for pose-guided person image synthesis. In: CVPR. pp. 6420–6429 (2024)
2024
-
[42]
In: ICLR (2016)
Mishkin, D., Matas, J.: All you need is a good init. In: ICLR (2016)
2016
-
[43]
In: ICLR
Nan, K., Xie, R., Zhou, P., Fan, T., Yang, Z., Chen, Z., Li, X., Yang, J., Tai, Y.: Openvid-1m: A large-scale high-quality dataset for text-to-video generation. In: ICLR. vol. 2025, pp. 1045–1064 (2025)
2025
-
[44]
In: CVPR
Parmar, G., Zhang, R., Zhu, J.Y.: On aliased resizing and surprising subtleties in gan evaluation. In: CVPR. pp. 11410–11420 (2022)
2022
-
[45]
In: ICML
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: ICML. pp. 8748–8763. PMLR (2021)
2021
-
[46]
In: CVPR
Ren,Y.,Fan,X.,Li,G.,Liu,S.,Li,T.H.:Neuraltextureextractionanddistribution for controllable person image synthesis. In: CVPR. pp. 13535–13544 (2022)
2022
-
[47]
In: CVPR
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: CVPR. pp. 10684–10695 (2022)
2022
-
[48]
In: ICLR (2014)
Saxe, A.M., McClelland, J.L., Ganguli, S.: Exact solutions to the nonlinear dy- namics of learning in deep linear neural networks. In: ICLR (2014)
2014
-
[49]
In: ICML
Schwarz, J., Czarnecki, W., Luketina, J., Grabska-Barwinska, A., Teh, Y.W., Pas- canu, R., Hadsell, R.: Progress & compress: A scalable framework for continual learning. In: ICML. pp. 4528–4537. PMLR (2018)
2018
-
[50]
In: CVPR
Sun, K., Xiao, B., Liu, D., Wang, J.: Deep high-resolution representation learning for human pose estimation. In: CVPR. pp. 5693–5703 (2019)
2019
-
[51]
LongCat-Image Technical Report
Team, M.L., Ma, H., Tan, H., Huang, J., Wu, J., He, J.Y., Gao, L., Xiao, S., Wei, X., Ma, X., et al.: Longcat-image technical report. arXiv preprint arXiv:2512.07584 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
In: BMVC (2025)
Velioglu, R., Bevandic, P., Chan, R., Hammer, B.: Tryoffdiff: Virtual-try-off via high-fidelity garment reconstruction using diffusion models. In: BMVC (2025)
2025
-
[53]
IEEE TIP13(4), 600–612 (2004)
Wang, Z., Bovik, A.C., Sheikh, H.R., Simoncelli, E.P.: Image quality assessment: from error visibility to structural similarity. IEEE TIP13(4), 600–612 (2004)
2004
-
[54]
NeurIPS29(2016)
Wisdom, S., Powers, T., Hershey, J., Le Roux, J., Atlas, L.: Full-capacity unitary recurrent neural networks. NeurIPS29(2016)
2016
-
[55]
arXiv preprint arXiv:2412.08573 (2024)
Xarchakos, I., Koukopoulos, T.: Tryoffanyone: Tiled cloth generation from a dressed person. arXiv preprint arXiv:2412.08573 (2024)
-
[56]
In: CVPR
Xie, Z., Huang, Z., Dong, X., Zhao, F., Dong, H., Zhang, X., Zhu, F., Liang, X.: Gp-vton: Towards general purpose virtual try-on via collaborative local-flow global-parsing learning. In: CVPR. pp. 23550–23559 (2023) 18 Yang et al
2023
-
[57]
In: AAAI
Xu, Y., Gu, T., Chen, W., Chen, A.: Ootdiffusion: Outfitting fusion based latent diffusion for controllable virtual try-on. In: AAAI. vol. 39, pp. 8996–9004 (2025)
2025
-
[58]
arXiv preprint arXiv:2510.24260 (2025)
Yang, Z., Chen, Y., Li, Y., He, S., Xu, Y., Dong, J., Yang, J., Du, Y.: Deshadow- mamba: Deshadowing as 1d sequential similarity. arXiv preprint arXiv:2510.24260 (2025)
-
[59]
In: ECCV
Yang,Z.,Jiang,Z.,Li,X.,Zhou,H.,Dong,J.,Zhang,H.,Du,Y.:D 4-vton:Dynamic semantics disentangling for differential diffusion based virtual try-on. In: ECCV. pp. 36–52. Springer (2024)
2024
-
[60]
In: ICCV
Yang, Z., Li, Y., He, S., Li, X., Xu, Y., Dong, J., Du, Y.: Omnivton: Training-free universal virtual try-on. In: ICCV. pp. 16702–16711 (2025)
2025
-
[61]
NeurIPS33, 5824–5836 (2020)
Yu, T., Kumar, S., Gupta, A., Levine, S., Hausman, K., Finn, C.: Gradient surgery for multi-task learning. NeurIPS33, 5824–5836 (2020)
2020
-
[62]
In: CVPR
Zhan, J., Sun, X., Zhu, X., Ji, Y., Liu, R., Zhang, L., Zhang, J.: Towards source- aware object swapping with initial noise perturbation. In: CVPR. pp. 4400–4409 (2026)
2026
-
[63]
In: CVPR
Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O.: The unreasonable effectiveness of deep features as a perceptual metric. In: CVPR. pp. 586–595 (2018)
2018
-
[64]
In: AAAI (2026)
Zhang, W., Jin, Y., Li, X., Zhang, Y., Cong, X., Wang, C., Qiao, F., et al.: Unifit: Towards universal virtual try-on with mllm-guided semantic alignment. In: AAAI (2026)
2026
-
[65]
IEEE TCSVT (2026)
Zheng, Y., Fang, W., Hu, X., Fan, J., Weng, J., Li, J., Zhang, K., Yang, J.: Dvdpec: Driving-video dehazing via position embedding-based codebook. IEEE TCSVT (2026)
2026
-
[66]
In: CVPR
Zheng, Y., Zhan, J., He, S., Dong, J., Du, Y.: Curricular contrastive regularization for physics-aware single image dehazing. In: CVPR. pp. 5785–5794 (2023)
2023
-
[67]
In: CVPR
Zheng, Y., Zhang, K., Zhu, W., Liu, Q., Hu, X., Li, J., Yang, J.: Dvar: Dynamic visual autoregressive modeling for image super-resolution. In: CVPR. pp. 23378– 23387 (2026)
2026
-
[68]
In: CVPR
Zhou, X., Zhang, B., Zhang, T., Zhang, P., Bao, J., Chen, D., Zhang, Z., Wen, F.: Cocosnet v2: Full-resolution correspondence learning for image translation. In: CVPR. pp. 11465–11475 (2021)
2021
-
[69]
In: CVPR
Zhu, Z., Huang, T., Shi, B., Yu, M., Wang, B., Bai, X.: Progressive pose attention transfer for person image generation. In: CVPR. pp. 2347–2356 (2019)
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.