Understanding How MLLMs Describe Artworks Using Token Activation Maps
Pith reviewed 2026-06-29 05:04 UTC · model grok-4.3
The pith
MLLMs ground artwork description tokens to image regions with strength that depends on token semantics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
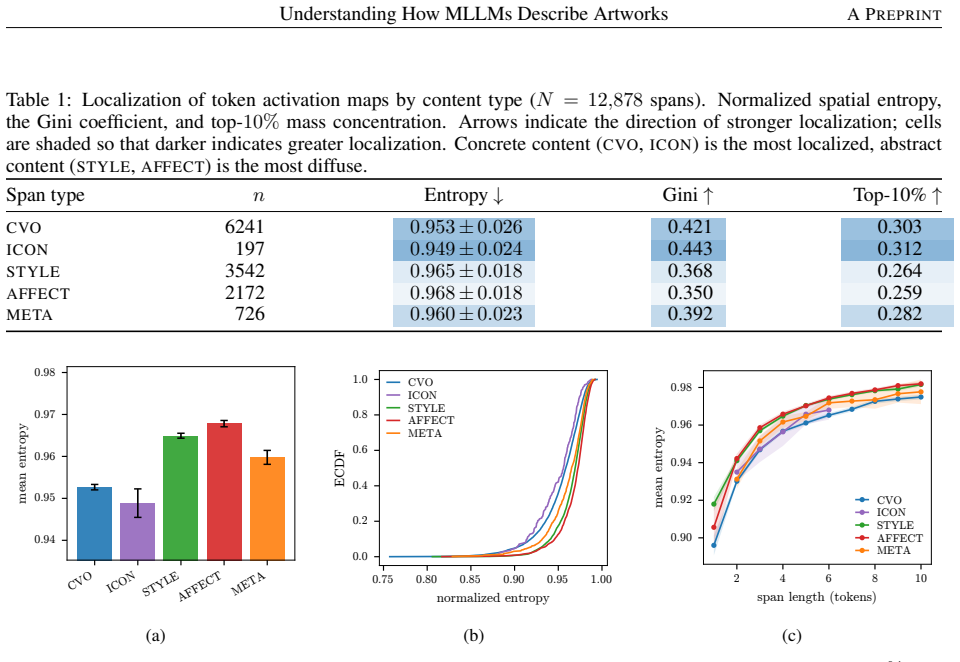
Applying Token Activation Maps to MLLM outputs on curated paintings shows that visual grounding varies substantially with token semantics across five categories, while the models attempt artist and title identification with higher accuracy for artists and more frequent hallucinations for titles; the same maps are compared to SAM 3 segmentation.
What carries the argument
Token Activation Map (TAM), which produces for each generated token a heatmap that isolates the visual evidence specific to that token from prior-context interference.
If this is right
- Grounding strength differs across common visual objects, style descriptors, metadata, iconographic tokens, and affective expressions.
- MLLMs reach higher accuracy attributing works to artists than predicting titles.
- Title predictions contain more hallucinations than artist attributions.
- TAM outputs can be directly compared with open-vocabulary segmentation from SAM 3.
Where Pith is reading between the lines
- The same per-token maps could be used to flag low-grounding tokens and trigger image re-examination in art-description systems.
- Semantic variation in grounding may generalize to other visual domains where MLLMs mix concrete and abstract language.
- If TAM shows weak grounding for affective tokens, that would suggest limits on using MLLMs for emotional analysis of images.
Load-bearing premise
TAM heatmaps succeed in isolating the visual contribution of one token at a time without leftover influence from the model's language priors or earlier tokens.
What would settle it
If masking the image region that humans judge relevant to a given token leaves the TAM activation for that token unchanged, the isolation property and the semantic-variation claim would both fail.
Figures





read the original abstract
Multimodal Large Language Models (MLLMs) describe artworks with remarkable fluency, yet the visual reasoning behind their outputs remains opaque. When an MLLM names a style, identifies a subject, or recognizes an iconographic symbol, does it ground each claim in the relevant region of the canvas, draw on an undifferentiated visual signal, or rely primarily on textual priors? We study this using the Token Activation Map (TAM), which produces, for each generated token, a heatmap isolating the visual evidence specific to that token from prior-context interference. Applying TAM to a curated set of paintings spanning multiple periods and genres, we analyze grounding patterns across five semantically distinct token categories: common visual objects, style descriptors, metadata, iconographic tokens, and affective expressions. We find that visual grounding varies substantially with token semantics. We further show that MLLMs attempt to identify artworks and artists, achieving higher accuracy in artist attribution than in title prediction, where hallucinations are more frequent. Finally, we compare TAM with SAM~3 open-vocabulary segmentation. To ensure reproducibility, we release our code, experimental configurations, prompts, and qualitative results on the project page at https://nicolafan.github.io/tamart/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Token Activation Maps (TAM) as a technique to produce per-token heatmaps when MLLMs generate descriptions of artworks. TAM is claimed to isolate the visual evidence used for each generated token while removing interference from prior context. The authors apply TAM to a curated collection of paintings across periods and genres, categorize generated tokens into five semantic groups (common visual objects, style descriptors, metadata, iconographic tokens, affective expressions), and report that grounding strength and spatial focus vary substantially across these categories. They additionally examine MLLM attempts at artwork identification, finding higher accuracy for artist attribution than for title prediction (with more frequent hallucinations in the latter), and provide a qualitative comparison of TAM against SAM-3 open-vocabulary segmentation. Code, prompts, and results are released for reproducibility.
Significance. If TAM can be shown to isolate token-specific visual evidence without context leakage, the work would supply a concrete interpretability tool for studying visual reasoning in MLLMs on culturally rich data. The reported semantic variation in grounding and the artist-versus-title accuracy gap would then constitute falsifiable observations about when MLLMs rely on image regions versus textual priors. The public release of code and configurations strengthens the contribution by enabling direct replication and extension.
major comments (3)
- [§3] §3 (TAM definition): The central claim that TAM 'isolates the visual evidence specific to that token from prior-context interference' is load-bearing for all subsequent findings, yet the manuscript provides no controlled ablation, synthetic test case with known ground-truth regions, or quantitative comparison against baselines that explicitly model context leakage. Without such validation, the reported differences across token categories and the artist/title accuracy gap cannot be interpreted as evidence of visual grounding.
- [§4.2] §4.2 (artist vs. title results): The claim of 'higher accuracy in artist attribution than in title prediction' is presented without accompanying quantitative metrics, confusion matrices, or error bars. If these numbers rest solely on qualitative inspection of TAM heatmaps, the finding is not yet load-bearing and requires explicit measurement against a held-out test set with ground-truth labels.
- [§4.3] §4.3 (SAM comparison): The comparison to SAM-3 is described only qualitatively. A quantitative overlap or IoU analysis between TAM heatmaps and SAM masks on the same tokens would be needed to establish whether TAM captures finer or more token-specific regions than an off-the-shelf segmenter.
minor comments (2)
- [§1] The abstract and §1 refer to 'five semantically distinct token categories' but the exact tokenization and classification procedure (e.g., how 'iconographic tokens' are distinguished from 'common visual objects') is not stated explicitly enough for replication.
- [Figures] Figure captions should include the exact MLLM backbone, prompt template, and temperature used for each example so that readers can reproduce the heatmaps without consulting the released code.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below and will incorporate revisions to strengthen the validation and quantitative aspects of the work.
read point-by-point responses
-
Referee: [§3] §3 (TAM definition): The central claim that TAM 'isolates the visual evidence specific to that token from prior-context interference' is load-bearing for all subsequent findings, yet the manuscript provides no controlled ablation, synthetic test case with known ground-truth regions, or quantitative comparison against baselines that explicitly model context leakage. Without such validation, the reported differences across token categories and the artist/title accuracy gap cannot be interpreted as evidence of visual grounding.
Authors: We agree that the isolation property is central and would benefit from explicit validation. The TAM formulation subtracts context-only activations from the full forward pass to isolate token-specific visual contributions, but the manuscript lacks a controlled demonstration. We will add a new subsection with a synthetic test using images with known ground-truth regions and a quantitative comparison to context-leakage baselines. revision: yes
-
Referee: [§4.2] §4.2 (artist vs. title results): The claim of 'higher accuracy in artist attribution than in title prediction' is presented without accompanying quantitative metrics, confusion matrices, or error bars. If these numbers rest solely on qualitative inspection of TAM heatmaps, the finding is not yet load-bearing and requires explicit measurement against a held-out test set with ground-truth labels.
Authors: The artist/title comparison is performed on a held-out test set with ground-truth labels. We will expand §4.2 to report the explicit accuracy figures, confusion matrices, and error bars from this evaluation. revision: yes
-
Referee: [§4.3] §4.3 (SAM comparison): The comparison to SAM-3 is described only qualitatively. A quantitative overlap or IoU analysis between TAM heatmaps and SAM masks on the same tokens would be needed to establish whether TAM captures finer or more token-specific regions than an off-the-shelf segmenter.
Authors: We agree a quantitative metric is needed. We will compute and report IoU overlaps between TAM heatmaps and SAM-3 masks for the same tokens in the revised manuscript. revision: yes
Circularity Check
No significant circularity; TAM is introduced as an independent analysis tool applied to observations.
full rationale
The paper introduces Token Activation Map (TAM) as a method for generating per-token heatmaps and applies it to curated artwork descriptions to observe semantic variation in grounding and differences in artist vs. title attribution accuracy. No equations, fitted parameters, or predictions are described in the abstract or claims. The isolation property is presented as a definitional feature of the proposed TAM rather than derived from or equivalent to the target findings. No self-citations, ansatzes, or renamings of known results appear as load-bearing steps. The derivation chain consists of methodological definition followed by empirical application, remaining self-contained without reduction to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the 58th annual meeting of the association for computational linguistics
Abnar, S., Zuidema, W.: Quantifying attention flow in transformers. In: Proceedings of the 58th annual meeting of the association for computational linguistics. pp. 4190–4197 (2020)
2020
-
[2]
Nature machine intelligence 5(9), 1006–1019 (2023)
Achtibat, R., Dreyer, M., Eisenbraun, I., Bosse, S., Wiegand, T., Samek, W., Lapuschkin, S.: From attribution maps to human-understandable explanations through concept relevance propagation. Nature machine intelligence 5(9), 1006–1019 (2023)
2023
-
[3]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Alfarano, A., Venturoli, L., Del Castillo, D.N.: VQArt-Bench: A semantically rich VQA Benchmark for Art and Cultural Heritage. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 396–406 (2025)
2025
-
[4]
Asperti, A., Dessi, L., Tonetti, M.C., Wu, N.: Does CLIP perceive art the same way we do? In: 2025 International Conference on Content-Based Multimedia Indexing (CBMI). pp. 1–8. IEEE (2025)
2025
-
[5]
Bai, S., Cai, Y ., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., et al.: Qwen3-vl technical report. arXiv preprint arXiv:2511.21631 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Eliciting Latent Predictions from Transformers with the Tuned Lens
Belrose, N., Ostrovsky, I., McKinney, L., Furman, Z., Smith, L., Halawi, D., Biderman, S., Steinhardt, J.: Eliciting latent predictions from transformers with the tuned lens. arXiv preprint arXiv:2303.08112 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Advances in Neural Information Processing Systems37, 84298–84328 (2024)
Bhalla, U., Oesterling, A., Srinivas, S., Calmon, F.P., Lakkaraju, H.: Interpreting clip with sparse linear concept embeddings (splice). Advances in Neural Information Processing Systems37, 84298–84328 (2024)
2024
-
[8]
In: Proceedings of the 32nd ACM International Conference on Multimedia
Bin, Y ., Shi, W., Ding, Y ., Hu, Z., Wang, Z., Yang, Y ., Ng, S.K., Shen, H.T.: Gallerygpt: Analyzing paintings with large multimodal models. In: Proceedings of the 32nd ACM International Conference on Multimedia. pp. 7734–7743 (2024)
2024
-
[9]
In: The Fourteenth International Conference on Learning Representations (2026),https://openreview.net/forum?id=r35clVtGzw
Carion, N., et al.: SAM 3: Segment anything with concepts. In: The Fourteenth International Conference on Learning Representations (2026),https://openreview.net/forum?id=r35clVtGzw
2026
-
[10]
Castellano, G., Miccoli, M.G., Scaringi, R., Vessio, G., Zaza, G., et al.: Using LLMs to explain AI-generated art classification via Grad-CAM heatmaps. In: XAI. it@ AI* IA. pp. 65–74 (2024)
2024
-
[11]
IEEE access7, 73694–73710 (2019)
Cetinic, E., Lipic, T., Grgic, S.: A deep learning perspective on beauty, sentiment, and remembrance of art. IEEE access7, 73694–73710 (2019)
2019
-
[12]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Chefer, H., Gur, S., Wolf, L.: Transformer interpretability beyond attention visualization. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 782–791 (2021) 9 Understanding How MLLMs Describe ArtworksA PREPRINT
2021
-
[13]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Chen, Z., Wu, J., Wang, W., Su, W., Chen, G., Xing, S., Zhong, M., Zhang, Q., Zhu, X., Lu, L., et al.: Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 24185–24198 (2024)
2024
-
[14]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Conde, M.V ., Turgutlu, K.: Clip-art: Contrastive pre-training for fine-grained art classification. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 3956–3960 (2021)
2021
-
[15]
In: LWDA
Diem, S., Mandl, T.: Automatic Classification of Portraits: Application of Transformer and CNN Based Models for an Art Historic Dataset. In: LWDA. pp. 192–206 (2023)
2023
-
[16]
In: International Conference on Learning Representations (2021)
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., Houlsby, N.: An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In: International Conference on Learning Representations (2021)
2021
-
[17]
arXiv preprint arXiv:2507.21917 (2025)
Fanelli, N., Vessio, G., Castellano, G.: ArtSeek: Deep artwork understanding via multimodal in-context reason- ing and late interaction retrieval. arXiv preprint arXiv:2507.21917 (2025)
-
[18]
In: 2025 IEEE/CVF Winter Conference on Applica- tions of Computer Vision (W ACV)
Fanelli, N., Vessio, G., Castellano, G.: I dream my painting: Connecting MLLMS and diffusion models via prompt generation for text-guided multi-mask inpainting. In: 2025 IEEE/CVF Winter Conference on Applica- tions of Computer Vision (W ACV). pp. 6073–6082. IEEE (2025)
2025
-
[19]
In: Proceedings of the European Conference on Computer Vision (ECCV) Workshops
Garcia, N., V ogiatzis, G.: How to read paintings: semantic art understanding with multi-modal retrieval. In: Proceedings of the European Conference on Computer Vision (ECCV) Workshops. pp. 0–0 (2018)
2018
-
[20]
In: European conference on computer vision
Garcia, N., Ye, C., Liu, Z., Hu, Q., Otani, M., Chu, C., Nakashima, Y ., Mitamura, T.: A dataset and baselines for visual question answering on art. In: European conference on computer vision. pp. 92–108. Springer (2020)
2020
-
[21]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Ghildyal, A., Wang, L.Y ., Liu, F.: WP-CLIP: Leveraging CLIP to Predict Wolfflin’s Principles in Visual Art. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 396–405 (2025)
2025
-
[22]
In: European Conference on Computer Vision
Heo, B., Park, S., Han, D., Yun, S.: Rotary position embedding for vision transformer. In: European Conference on Computer Vision. pp. 289–305. Springer (2024)
2024
-
[23]
In: International conference on machine learning
Kim, B., Wattenberg, M., Gilmer, J., Cai, C., Wexler, J., Viegas, F., et al.: Interpretability beyond feature at- tribution: Quantitative testing with concept activation vectors (tcav). In: International conference on machine learning. pp. 2668–2677. PMLR (2018)
2018
-
[24]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Li, Y ., Wang, H., Ding, X., Wang, H., Li, X.: Token activation map to visually explain multimodal llms. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 48–58 (2025)
2025
-
[25]
Does AI See like Art Historians? Interpreting How Vision Language Models Recognize Artistic Style
Limpijankit, M., Alshomary, M., Daoud, Y .O., Ananthram, A., Trombley, T., Spratt, E.L., Filonenko, A., Pivo, H., Stengel-Eskin, E., Bansal, M., et al.: Does AI See like Art Historians? Interpreting How Vision Language Models Recognize Artistic Style. arXiv preprint arXiv:2603.11024 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[26]
Advances in neural information processing systems 36, 34892–34916 (2023)
Liu, H., Li, C., Wu, Q., Lee, Y .J.: Visual instruction tuning. Advances in neural information processing systems 36, 34892–34916 (2023)
2023
-
[27]
Journal on Computing and Cultural Heritage (JOCCH)14(4), 1–18 (2021)
Milani, F., Fraternali, P.: A dataset and a convolutional model for iconography classification in paintings. Journal on Computing and Cultural Heritage (JOCCH)14(4), 1–18 (2021)
2021
-
[28]
In: International Conference on Learning Representations
Neo, C., Ong, L., Torr, P., Geva, M., Krueger, D., Barez, F.: Towards interpreting visual information processing in vision-language models. In: International Conference on Learning Representations. vol. 2025, pp. 57172–57189 (2025)
2025
-
[29]
Journal of Imaging7(7), 106 (2021)
Pinciroli Vago, N.O., Milani, F., Fraternali, P., da Silva Torres, R.: Comparing cam algorithms for the identifica- tion of salient image features in iconography artwork analysis. Journal of Imaging7(7), 106 (2021)
2021
-
[30]
In: 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (W ACV)
Ramos, P., Gonthier, N., Khan, S., Nakashima, Y ., Garcia, N.: No annotations for object detection in art through stable diffusion. In: 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (W ACV). pp. 6228–6237. IEEE (2025)
2025
-
[31]
Knowledge-Based Systems310, 112857 (2025)
Scaringi, R., Fiameni, G., Vessio, G., Castellano, G.: GraphCLIP: Image-graph contrastive learning for multi- modal artwork classification. Knowledge-Based Systems310, 112857 (2025)
2025
-
[32]
arXiv preprint arXiv:2602.20853 (2026)
Schneider, S.: On the Explainability of Vision-Language Models in Art History. arXiv preprint arXiv:2602.20853 (2026)
-
[33]
In: Proceedings of the IEEE international conference on computer vision
Selvaraju, R.R., Cogswell, M., Das, A., Vedantam, R., Parikh, D., Batra, D.: Grad-cam: Visual explanations from deep networks via gradient-based localization. In: Proceedings of the IEEE international conference on computer vision. pp. 618–626 (2017) 10 Understanding How MLLMs Describe ArtworksA PREPRINT
2017
-
[34]
Strafforello, O., Soydaner, D., Willems, M., Maerten, A.S., De Winter, S.: Have large vision-language models mastered art history? In: International Conference on Image Analysis and Processing. pp. 524–544. Springer (2025)
2025
-
[35]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Wang, P., Bai, S., Tan, S., Wang, S., Fan, Z., Bai, J., Chen, K., Liu, X., Wang, J., Ge, W., et al.: Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution. arXiv preprint arXiv:2409.12191 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
Advances in Neural Information Processing Systems36, 16009–16027 (2023)
Wang, Y ., Rudner, T.G., Wilson, A.G.: Visual explanations of image-text representations via multi-modal infor- mation bottleneck attribution. Advances in Neural Information Processing Systems36, 16009–16027 (2023)
2023
-
[37]
In: 2023 IEEE International Conference on Big Data (BigData)
Wu, J., Gan, W., Chen, Z., Wan, S., Yu, P.S.: Multimodal large language models: A survey. In: 2023 IEEE International Conference on Big Data (BigData). pp. 2247–2256. IEEE (2023)
2023
-
[38]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Zhou, B., Khosla, A., Lapedriza, A., Oliva, A., Torralba, A.: Learning deep features for discriminative local- ization. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 2921–2929 (2016) 11
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.