The Signal-Coverage Matrix: Stratifying Type and Semantic Errors in Statement Autoformalization
Pith reviewed 2026-06-29 04:21 UTC · model grok-4.3
The pith
A four-cell signal-coverage matrix shows that LLM autoformalization gains recover type errors at a steady 23/61 rate while semantic errors remain flat on net.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
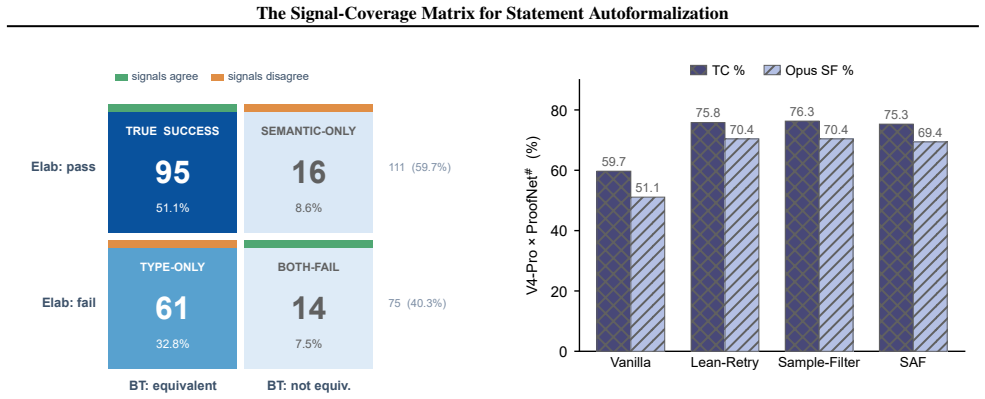
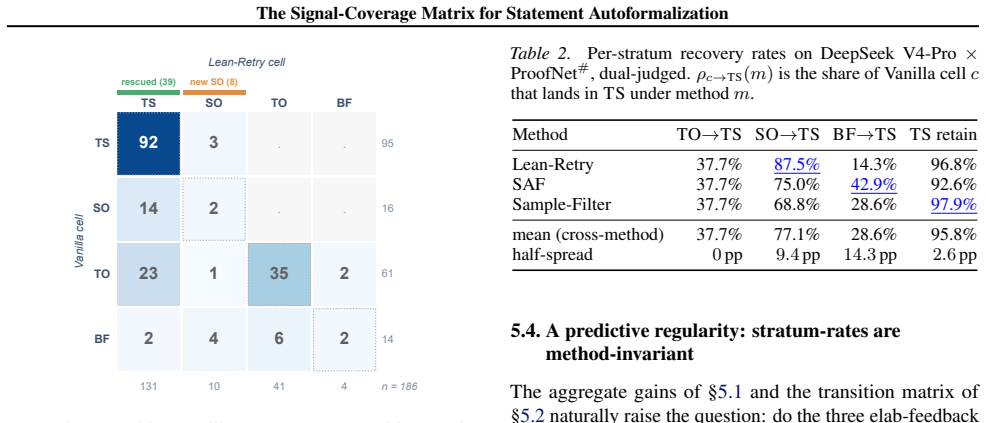
The signal-coverage matrix stratifies every autoformalization output by crossing the Lean elaborator signal with a semantic-equivalence judgment, yielding four exhaustive cells. On the tested datasets and methods the +34 to +36 true-success gains represent approximately 64 percent type-stratum recovery, the semantic-only count stays flat on net, and the type-only to true-success conversion rate of 23/61 predicts delta true-success on held-out methods to within 2/186 while rendering delta type-correctness linear in the vanilla elaborator-fail rate across six model-dataset cells with R-squared 0.96. The two judges disagree by 26 to 37 percentage points on elaboration-feedback outputs versus 7
What carries the argument
The signal-coverage matrix, which crosses the Lean elaborator pass/fail outcome with an independent semantic-equivalence judgment to partition outputs into four exhaustive cells.
If this is right
- The consistent type-only to true-success rate of 23/61 allows prediction of true-success gains on new methods within a narrow band.
- Type-correctness percentage gains should be credited according to which matrix cell moved rather than by the scalar alone.
- Higher judge disagreement on elaboration-feedback outputs is largely explained by elaborator-forced rewrites.
- The residual disagreement after accounting for rewrites reduces to two errors in the gold formalizations.
Where Pith is reading between the lines
- The matrix could be applied to autoformalization pipelines in other proof assistants to separate type and semantic error sources.
- Once type recovery saturates, further gains would require methods that specifically target the semantic-only cell.
- The observed linearity between delta type-correctness and vanilla elaborator-fail rate suggests a simple baseline model for expected improvement on any new dataset.
Load-bearing premise
The semantic-equivalence judgment supplies an accurate independent correctness signal separate from the elaborator, and the four cells are exhaustive and mutually exclusive for every generated statement.
What would settle it
A new elaboration-feedback method on the same datasets where the type-only to true-success conversion rate falls outside the Wilson 95 percent interval of 26.6 to 50.3 percent, or where the observed delta true-success deviates from the 23/61 prediction by more than two statements out of 186.
Figures


read the original abstract
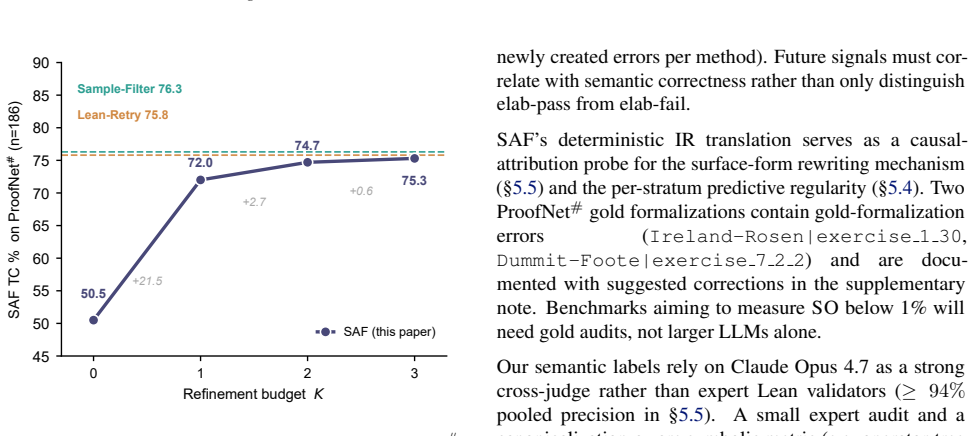
Headline type-correctness (TC\%) of LLM autoformalization has climbed from $\sim$53\% to $\sim$76\% in two years, yet this scalar conceals which errors each method resolves. We propose a signal-coverage matrix that crosses the Lean elaborator (pass/fail) with a semantic-equivalence judgment (equivalent/not), sorting every output into one of four cells: true success (TS), type-only (TO), semantic-only (SO), or both fail (BF). On ProofNet\# and MiniF2F-test with DeepSeek V4-Pro across Vanilla, Lean-Retry, Sample-Filter, and Stratified Autoformalization (SAF): (1) the +34 to +36 TS gain across the three elab-feedback methods is $\sim$64\% type-stratum recovery, with SO flat on net (87.5\% of original semantic errors rescued, 8 newly created). (2) The TO-to-TS rate is 23/61 for each method (Wilson 95\% CI [26.6\%, 50.3\%]), and this stratum-level recovery rate predicts $\Delta$TS on held-out methods to within 2/186 and renders $\Delta$TC linear in the Vanilla elab-fail rate across six (model, dataset) cells ($R^2=0.96$). (3) The two judges disagree by 26 to 37 pp on elab-feedback outputs (vs. 7 pp on Vanilla), with 30 to 56\% of symbolic-judge false negatives traceable to elaborator-forced rewrites. The persistent residual reduces to two gold-formalization errors. TC\% gains should be credited by which cell moved, not by the scalar alone.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a signal-coverage matrix for stratifying errors in LLM-based statement autoformalization. The matrix is formed by crossing the Lean elaborator's pass/fail outcome with an independent semantic-equivalence judgment, yielding four exhaustive cells: true success (TS: pass+equiv), type-only (TO: pass+not), semantic-only (SO: fail+equiv), and both-fail (BF: fail+not). Experiments on ProofNet# and MiniF2F-test with DeepSeek-V4-Pro compare Vanilla, Lean-Retry, Sample-Filter, and Stratified Autoformalization (SAF). Key findings include +34–36 TS gains from the three elab-feedback methods representing ~64% type-stratum recovery (SO net flat at 87.5% rescue with 8 new errors created), a consistent 23/61 TO-to-TS conversion rate (Wilson CI [26.6%, 50.3%]) that predicts ΔTS on held-out methods to within 2/186 and explains ΔTC linearity (R²=0.96) with Vanilla elab-fail rate across six (model, dataset) pairs. Judge disagreement is higher on feedback outputs (26–37 pp vs. 7 pp on Vanilla), with 30–56% of symbolic false negatives linked to elaborator rewrites; residuals reduce to two gold-formalization errors.
Significance. If the semantic-equivalence judgment is reliable and independent, the matrix provides a valuable decomposition of autoformalization performance, showing that recent type-correctness gains are predominantly recoveries from the type-only stratum rather than semantic improvements. The absence of free parameters in the matrix definition, the consistency of the TO-to-TS rate across methods, and its predictive accuracy on held-out cases are notable strengths that support falsifiable claims about method behavior. This could encourage more granular reporting in the field beyond aggregate TC% metrics.
major comments (1)
- [Semantic-equivalence judgment procedure and cell assignment] The central results (TS gains of +34–36, ~64% type-stratum recovery, 23/61 TO-to-TS rate, and R²=0.96 linearity) rest on the accuracy and independence of the semantic-equivalence judgment used to assign outputs to the four cells. The manuscript reports 26–37 pp disagreement with the symbolic judge on elab-feedback outputs (vs. 7 pp on Vanilla) and traces 30–56% of symbolic false negatives to elaborator-forced rewrites, but provides no independent validation (e.g., human evaluation of a stratified sample of rewritten statements) to rule out systematic bias in the semantic judge itself.
minor comments (2)
- [Results on TO-to-TS rate] The Wilson 95% CI [26.6%, 50.3%] for the 23/61 rate is reported; state the exact binomial method or library used and whether the interval was computed on the pooled data or per-method.
- [Experimental setup and results] Ensure consistent terminology for the three elab-feedback methods (Lean-Retry, Sample-Filter, SAF) when discussing the +34–36 TS gain and the held-out prediction within 2/186.
Simulated Author's Rebuttal
We thank the referee for their careful reading and for recognizing the value of the signal-coverage matrix in providing a granular decomposition of autoformalization performance. We address the single major comment below.
read point-by-point responses
-
Referee: The central results (TS gains of +34–36, ~64% type-stratum recovery, 23/61 TO-to-TS rate, and R²=0.96 linearity) rest on the accuracy and independence of the semantic-equivalence judgment used to assign outputs to the four cells. The manuscript reports 26–37 pp disagreement with the symbolic judge on elab-feedback outputs (vs. 7 pp on Vanilla) and traces 30–56% of symbolic false negatives to elaborator-forced rewrites, but provides no independent validation (e.g., human evaluation of a stratified sample of rewritten statements) to rule out systematic bias in the semantic judge itself.
Authors: The manuscript already quantifies disagreement between the semantic-equivalence judge and the Lean symbolic judge, traces 30–56% of discrepancies to elaborator rewrites, and reduces the residual to two gold-formalization errors. This cross-check, together with the observed constancy of the 23/61 TO-to-TS rate across methods and its ability to predict held-out ΔTS within 2/186, supplies evidence that any bias in the semantic judge does not materially affect the reported stratification or the linearity result (R²=0.96). We acknowledge, however, that a human evaluation of a stratified sample of the rewritten statements is absent. We will add an explicit limitations paragraph discussing the judge-validation evidence that is present and noting the absence of human adjudication as a point for future work. revision: partial
Circularity Check
No significant circularity; matrix and rates defined independently of outcomes
full rationale
The signal-coverage matrix is defined by crossing the Lean elaborator (pass/fail) with a separate semantic-equivalence judgment, producing four exhaustive cells (TS/TO/SO/BF) without reference to the experimental cell counts or recovery statistics. All headline quantities—the +34–36 TS gains, 23/61 TO-to-TS rate, 87.5% semantic rescue, and R²=0.96 linearity—are direct tallies or observed ratios computed from those cell assignments on the reported datasets. The claim that the observed stratum rate “predicts” ΔTS on held-out methods is a post-hoc validation check, not a fitted parameter renamed as a prediction or a self-referential definition. No self-citation chain, ansatz smuggling, or uniqueness theorem is invoked to justify the matrix or the cell movements; the derivation remains self-contained against the external benchmarks of elaborator output and semantic judgment.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The semantic-equivalence judgment accurately classifies whether an output is equivalent to the gold formalization
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems , volume=
Autoformalization with Large Language Models , author=. Advances in Neural Information Processing Systems , volume=
-
[6]
International Conference on Learning Representations , year=
Draft, Sketch, and Prove: Guiding Formal Theorem Provers with Informal Proofs , author=. International Conference on Learning Representations , year=
-
[7]
International Conference on Learning Representations , year=
Don't Trust: Verify -- Grounding LLM Quantitative Reasoning with Autoformalization , author=. International Conference on Learning Representations , year=
-
[8]
Liu, Xiaoyang and Bao, Kangjie and Zhang, Jiashuo and Liu, Yunqi and Chen, Yu and Liu, Yuntian and Jiao, Yang and Luo, Tao , journal =
-
[9]
Generalized Tree Edit Distance (
Liu, Yuntian and Zhu, Tao and Liu, Xiaoyang and Chen, Yu and Liu, Zhaoxuan and Guo, Qingfeng and Zhang, Jiashuo and Bao, Kangjie and Luo, Tao , booktitle =. Generalized Tree Edit Distance (. 2025 , note =
2025
-
[10]
2022 , url =
Zheng, Kunhao and Han, Jesse Michael and Polu, Stanislas , booktitle =. 2022 , url =
2022
-
[11]
2026 , howpublished =
2026
-
[12]
2026 , howpublished=
The. 2026 , howpublished=
2026
-
[13]
2024 , howpublished=
Hello. 2024 , howpublished=
2024
-
[15]
Yang, Kaiyu and Swope, Aidan and Gu, Alex and Chalamala, Rahul and Song, Peiyang and Yu, Shixing and Godil, Saad and Prenger, Ryan and Anandkumar, Anima , booktitle=
-
[16]
International Conference on Learning Representations , year=
Llemma: An Open Language Model for Mathematics , author=. International Conference on Learning Representations , year=
-
[17]
Lin, Haohan and Sun, Zhiqing and Welleck, Sean and Yang, Yiming , booktitle=
-
[18]
The Claude 4 model family
Anthropic . The Claude 4 model family. https://www.anthropic.com/claude, 2026. Model card
2026
-
[19]
Azerbayev, Z., Piotrowski, B., Schoelkopf, H., Ayers, E. W., Radev, D., and Avigad, J. Proofnet: Autoformalizing and formally proving undergraduate-level mathematics. arXiv preprint arXiv:2302.12433, 2023
arXiv 2023
-
[20]
Q., Deng, J., Biderman, S., and Welleck, S
Azerbayev, Z., Schoelkopf, H., Paster, K., Dos Santos, M., McAleer, S., Jiang, A. Q., Deng, J., Biderman, S., and Welleck, S. Llemma: An open language model for mathematics. In International Conference on Learning Representations, 2024
2024
-
[21]
DeepSeek-V4 technical report
DeepSeek-AI . DeepSeek-V4 technical report. https://huggingface.co/deepseek-ai, 2026. Technical report
2026
-
[22]
Autoformalizer with tool feedback
Guo, Q., Wang, J., Zhang, J., Kong, D., Huang, X., Xi, X., Wang, W., Wang, J., Cai, X., Zhang, S., and Ye, W. Autoformalizer with tool feedback. arXiv preprint arXiv:2510.06857, 2025
arXiv 2025
-
[23]
Q., Welleck, S., Zhou, J
Jiang, A. Q., Welleck, S., Zhou, J. P., Li, W., Liu, J., Jamnik, M., Lacroix, T., Wu, Y., and Lample, G. Draft, sketch, and prove: Guiding formal theorem provers with informal proofs. In International Conference on Learning Representations, 2023
2023
-
[24]
Lean-STaR : Learning to interleave thinking and proving
Lin, H., Sun, Z., Welleck, S., and Yang, Y. Lean-STaR : Learning to interleave thinking and proving. In International Conference on Learning Representations, 2025
2025
-
[25]
ATLAS : Autoformalizing theorems through lifting, augmentation, and synthesis of data
Liu, X., Bao, K., Zhang, J., Liu, Y., Chen, Y., Liu, Y., Jiao, Y., and Luo, T. ATLAS : Autoformalizing theorems through lifting, augmentation, and synthesis of data. arXiv preprint arXiv:2502.05567, 2025 a
arXiv 2025
-
[26]
Liu, Y., Zhu, T., Liu, X., Chen, Y., Liu, Z., Guo, Q., Zhang, J., Bao, K., and Luo, T. Generalized tree edit distance ( GTED ): A faithful evaluation metric for statement autoformalization. In ICML 2025 Workshop on AI for Math (AI4Math), 2025 b . arXiv:2507.07399
arXiv 2025
-
[27]
Process-driven autoformalization in lean 4
Lu, J., Wan, Y., Liu, Z., Huang, Y., Xiong, J., Liu, C., Shen, J., Jin, H., Zhang, J., Wang, H., Yang, Z., Tang, J., and Guo, Z. Process-driven autoformalization in lean 4. arXiv preprint arXiv:2406.01940, 2024
arXiv 2024
-
[28]
Hello GPT-4o
OpenAI . Hello GPT-4o . https://openai.com/index/hello-gpt-4o/, 2024
2024
-
[29]
Improving autoformalization using type checking
Poiroux, A., Weiss, G., Kun c ak, V., and Bosselut, A. Improving autoformalization using type checking. arXiv preprint arXiv:2406.07222, 2024
arXiv 2024
-
[30]
Polu, S. and Sutskever, I. Generative language modeling for automated theorem proving. arXiv preprint arXiv:2009.03393, 2020
Pith/arXiv arXiv 2009
-
[31]
Qwen3.5 technical report
Qwen Team . Qwen3.5 technical report. https://qwenlm.github.io, 2026. Technical report
2026
-
[32]
Q., Li, W., Rabe, M., Staats, C., Jamnik, M., and Szegedy, C
Wu, Y., Jiang, A. Q., Li, W., Rabe, M., Staats, C., Jamnik, M., and Szegedy, C. Autoformalization with large language models. Advances in Neural Information Processing Systems, 35: 0 32353--32368, 2022
2022
-
[33]
MiMo-V2.5-Pro : Reasoning model technical report
Xiaomi MiMo Team . MiMo-V2.5-Pro : Reasoning model technical report. https://github.com/XiaomiMiMo, 2026. Technical report
2026
-
[34]
LeanDojo : Theorem proving with retrieval-augmented language models
Yang, K., Swope, A., Gu, A., Chalamala, R., Song, P., Yu, S., Godil, S., Prenger, R., and Anandkumar, A. LeanDojo : Theorem proving with retrieval-augmented language models. In Advances in Neural Information Processing Systems, 2023
2023
-
[35]
MiniF2F: a cross-system benchmark for formal Olympiad-level mathematics
Zheng, K., Han, J. M., and Polu, S. MiniF2F : a cross-system benchmark for formal olympiad-level mathematics. In International Conference on Learning Representations, 2022. doi:10.48550/arXiv.2109.00110. URL https://arxiv.org/abs/2109.00110
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2109.00110 2022
-
[36]
P., Staats, C., Li, W., Szegedy, C., Weinberger, K
Zhou, J. P., Staats, C., Li, W., Szegedy, C., Weinberger, K. Q., and Wu, Y. Don't trust: Verify -- grounding llm quantitative reasoning with autoformalization. In International Conference on Learning Representations, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.