EMOSH: Expressive Motion and Shape Disentanglement for Human Animation
Pith reviewed 2026-06-29 04:39 UTC · model grok-4.3
The pith
Disentangling shape and pose parameters in an expressive human model stops body shape leakage during video animation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
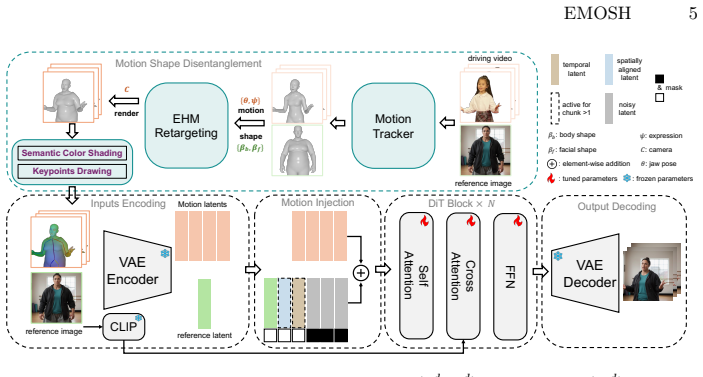
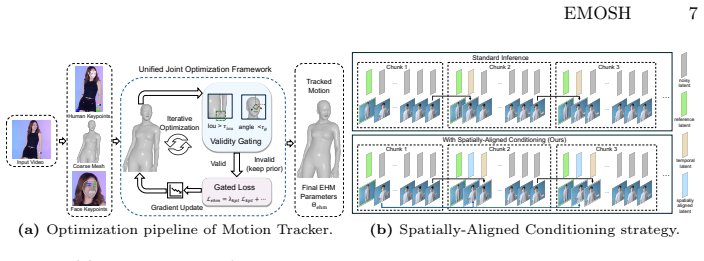
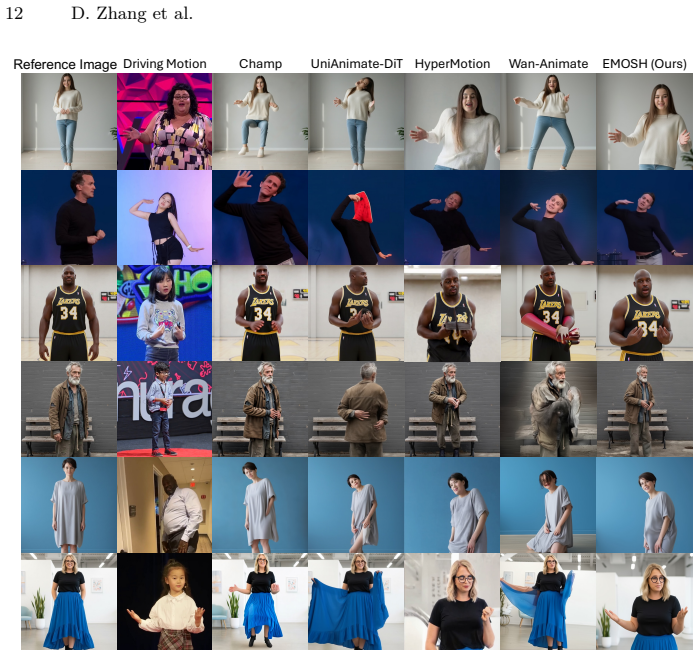
The paper introduces the Expressive Human Model (EHM) whose explicit separation of shape and pose parameters removes motion-shape entanglement. A robust motion tracker extracts EHM parameters from video; Coarse-to-Fine Hybrid Motion Injection supplies fine-grained expression and gesture control; and Spatially-Aligned Conditioning closes the train-inference gap. These elements together generate high-fidelity videos that keep target body shape intact while transferring vivid expressions in both self-driven and cross-driven settings.
What carries the argument
The Expressive Human Model (EHM), which serves as the core control representation by explicitly separating shape parameters from pose parameters.
If this is right
- Self-driven animation produces higher-fidelity output with preserved identity.
- Cross-driven animation transfers expressions and gestures without transferring body shape.
- Complex gestures and facial expressions remain controllable without the rigidity of pure 3D priors.
- Identity consistency improves across training and inference through spatial alignment.
Where Pith is reading between the lines
- Avatar pipelines could reduce manual corrections for shape mismatches during cross-identity transfers.
- Real-time applications would need separate validation of the tracker's accuracy on live streams.
- The same separation principle could be tested on full-body plus hand animation where current methods still leak proportions.
Load-bearing premise
A motion tracker can reliably extract accurate EHM parameters from any video input without errors that would reintroduce shape leakage or weaken expression control.
What would settle it
A cross-identity driving test in which the generated video visibly adopts the driving subject's body proportions instead of the target's proportions would show the disentanglement has failed.
Figures








read the original abstract
High-fidelity and expressive controllable human animation is essential for content creation and digital avatar applications. However, existing methods face a dilemma between expressiveness and disentanglement. Mainstream 2D pose-conditioned approaches suffer from "motion-shape entanglement", leading to the leakage of the driving subject's body shape. Conversely, methods relying on 3D priors (e.g., SMPL) achieve geometric disentanglement but struggle to capture facial expressions and complex gestures, resulting in rigid animations. To this end, we propose EMOSH, a novel framework for high-fidelity controllable human video generation. First, an Expressive Human Model (EHM) is introduced as the core control representation. By explicitly disentangling shape and pose parameters, we fundamentally resolve the body shape leakage issue. Alongside this, a robust motion tracker is designed to accurately estimate EHM parameters from video. Second, we propose a Coarse-to-Fine Hybrid Motion Injection strategy, enabling more fine-grained control over expressions and gestures. Furthermore, we introduce a Spatially-Aligned Conditioning mechanism to bridge the domain gap between training and inference, improving identity consistency. Extensive experiments demonstrate that EMOSH outperforms previous methods in both self-driven and cross-driven scenarios, producing high-fidelity videos with vivid expressions while maintaining shape disentanglement.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes EMOSH, a framework for high-fidelity controllable human video generation. It introduces an Expressive Human Model (EHM) that explicitly disentangles shape and pose parameters to resolve body shape leakage from motion-shape entanglement in prior 2D approaches, while addressing the limited expressiveness of 3D-prior methods like SMPL. A robust motion tracker estimates EHM parameters from video; a Coarse-to-Fine Hybrid Motion Injection strategy provides fine-grained control over expressions and gestures; and a Spatially-Aligned Conditioning mechanism improves identity consistency. The paper claims that EMOSH outperforms prior methods in both self-driven and cross-driven scenarios, yielding high-fidelity videos with vivid expressions and maintained shape disentanglement.
Significance. If the central claims hold with supporting quantitative evidence, the explicit disentanglement in EHM could meaningfully advance controllable human animation by overcoming the expressiveness-disentanglement trade-off, with potential applications in digital avatars and content creation. The introduction of the EHM representation and associated tracker represents a targeted architectural response to a documented limitation in the field.
major comments (2)
- [Abstract] Abstract (second paragraph): The claim that EHM 'fundamentally resolve[s] the body shape leakage issue' by explicit disentanglement is load-bearing for the paper's central contribution, yet it depends on the unverified assumption that the accompanying motion tracker can estimate EHM parameters from arbitrary video input without errors that would reintroduce leakage or degrade control. No quantitative validation of tracker accuracy, failure modes, or leakage metrics is supplied.
- [Abstract] Abstract (final sentence): The assertion that 'extensive experiments demonstrate that EMOSH outperforms previous methods' is central to the paper's evaluation claim, but the provided text supplies no metrics, baselines, dataset details, ablation results, or quantitative comparisons, making it impossible to assess whether the disentanglement and expressiveness improvements are realized in practice.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. We address each point below and agree to revise the abstract for improved clarity and precision while defending the manuscript's core claims based on the full text.
read point-by-point responses
-
Referee: [Abstract] Abstract (second paragraph): The claim that EHM 'fundamentally resolve[s] the body shape leakage issue' by explicit disentanglement is load-bearing for the paper's central contribution, yet it depends on the unverified assumption that the accompanying motion tracker can estimate EHM parameters from arbitrary video input without errors that would reintroduce leakage or degrade control. No quantitative validation of tracker accuracy, failure modes, or leakage metrics is supplied.
Authors: The EHM achieves disentanglement explicitly through its parameter design separating shape and pose, which directly addresses motion-shape entanglement in 2D methods by construction; tracker estimation errors do not reintroduce the same leakage mechanism. The full manuscript details the robust motion tracker with quantitative validation of accuracy, failure modes, and leakage metrics in Sections 3.2 and 5. We will revise the abstract wording to 'significantly mitigates' for precision. revision: partial
-
Referee: [Abstract] Abstract (final sentence): The assertion that 'extensive experiments demonstrate that EMOSH outperforms previous methods' is central to the paper's evaluation claim, but the provided text supplies no metrics, baselines, dataset details, ablation results, or quantitative comparisons, making it impossible to assess whether the disentanglement and expressiveness improvements are realized in practice.
Authors: Abstracts provide high-level overviews; the manuscript's Section 5 supplies the requested details including metrics, baselines, datasets, and ablations demonstrating outperformance in self- and cross-driven scenarios. To address the concern, we will revise the abstract's final sentence to reference key quantitative outcomes. revision: yes
Circularity Check
No significant circularity; claims rest on introduction of new disentangled model components
full rationale
The paper's central claims center on the introduction of the Expressive Human Model (EHM) with explicit shape-pose separation and an accompanying motion tracker, plus hybrid injection and conditioning mechanisms. No equations, fitted parameters, or self-citation chains are presented in the provided text that reduce any prediction or uniqueness result to its own inputs by construction. The resolution of shape leakage is asserted as a direct consequence of the explicit parameterization in the new model rather than a derived quantity that loops back to prior fitted values or self-referential definitions. This is the most common honest finding for a methods paper whose contributions are architectural rather than re-derivations of existing results.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Expressive Human Model (EHM)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
OpenAI Blog1(8), 1 (2024) 3
Brooks, T., Peebles, B., Holmes, C., DePue, W., Guo, Y., Jing, L., Schnurr, D., Taylor, J., Luhman, T., Luhman, E., et al.: Video generation models as world simulators. OpenAI Blog1(8), 1 (2024) 3
2024
-
[2]
In: Proceedings of the SIGGRAPH Asia 2025 Conference Papers
Cao, C., Zhou, J., Li, S., Liang, J., Yu, C., Wang, F., Xue, X., Fu, Y.: Uni3c: Unifying precisely 3d-enhanced camera and human motion controls for video gen- eration. In: Proceedings of the SIGGRAPH Asia 2025 Conference Papers. pp. 1–12 (2025) 4
2025
-
[3]
IEEE transactions on pattern analysis and machine intelligence43(1), 172–186 (2019) 4
Cao, Z., Hidalgo, G., Simon, T., Wei, S.E., Sheikh, Y.: Openpose: Realtime multi- person 2d pose estimation using part affinity fields. IEEE transactions on pattern analysis and machine intelligence43(1), 172–186 (2019) 4
2019
-
[4]
arXiv preprint arXiv:2311.12052 (2023) 2
Chang, D., Shi, Y., Gao, Q., Fu, J., Xu, H., Song, G., Yan, Q., Zhu, Y., Yang, X., Soleymani,M.:Magicpose:Realistichumanposesandfacialexpressionsretargeting with identity-aware diffusion. arXiv preprint arXiv:2311.12052 (2023) 2
-
[5]
arXiv preprint arXiv:2509.14055 (2025) 4, 9, 21
Cheng, G., Gao, X., Hu, L., Hu, S., Huang, M., Ji, C., Li, J., Meng, D., Qi, J., Qiao, P., et al.: Wan-animate: Unified character animation and replacement with holistic replication. arXiv preprint arXiv:2509.14055 (2025) 4, 9, 21
-
[6]
arXiv preprint arXiv:1907.06571 (2019) 3
Clark, A., Donahue, J., Simonyan, K.: Adversarial video generation on complex datasets. arXiv preprint arXiv:1907.06571 (2019) 3
-
[7]
google / blog / genie - 3 - a - new - frontier - for - world - models/, ac- cessed: 2026-02-15 4
DeepMind, G.: Genie 3: A new frontier for world models (2025),https:// deepmind . google / blog / genie - 3 - a - new - frontier - for - world - models/, ac- cessed: 2026-02-15 4
2025
-
[8]
DeepMind, G.: Veo 3 (2025),https://deepmind.google/technologies/veo/, ac- cessed: 2026-02-15 4
2025
-
[9]
In: CVPR (2019) 10
Deng, J., Guo, J., Niannan, X., Zafeiriou, S.: Arcface: Additive angular margin loss for deep face recognition. In: CVPR (2019) 10
2019
-
[10]
Advances in neural information processing systems31(2018) 4
Dong, H., Liang, X., Gong, K., Lai, H., Zhu, J., Yin, J.: Soft-gated warping-gan for pose-guided person image synthesis. Advances in neural information processing systems31(2018) 4
2018
-
[11]
Seedance 1.0: Exploring the Boundaries of Video Generation Models
Gao, Y., Guo, H., Hoang, T., Huang, W., Jiang, L., Kong, F., Li, H., Li, J., Li, L., Li, X., et al.: Seedance 1.0: Exploring the boundaries of video generation models. arXiv preprint arXiv:2506.09113 (2025) 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Communications of the ACM63(11), 139–144 (2020) 2
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., Bengio, Y.: Generative adversarial networks. Communications of the ACM63(11), 139–144 (2020) 2
2020
-
[13]
Imagen Video: High Definition Video Generation with Diffusion Models
Ho, J., Chan, W., Saharia, C., Whang, J., Gao, R., Gritsenko, A., Kingma, D.P., Poole, B., Norouzi, M., Fleet, D.J., et al.: Imagen video: High definition video generation with diffusion models. arXiv preprint arXiv:2210.02303 (2022) 3
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[14]
Advances in neural information processing systems33, 6840–6851 (2020) 2, 3
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. Advances in neural information processing systems33, 6840–6851 (2020) 2, 3
2020
-
[15]
Advances in neural information processing systems35, 8633– 8646 (2022) 3
Ho, J., Salimans, T., Gritsenko, A., Chan, W., Norouzi, M., Fleet, D.J.: Video diffusion models. Advances in neural information processing systems35, 8633– 8646 (2022) 3
2022
-
[16]
In: Proceedings of the IEEE/CVF confer- ence on computer vision and pattern recognition
Hong, F.T., Zhang, L., Shen, L., Xu, D.: Depth-aware generative adversarial net- work for talking head video generation. In: Proceedings of the IEEE/CVF confer- ence on computer vision and pattern recognition. pp. 3397–3406 (2022) 4 16 D. Zhang et al
2022
-
[17]
Iclr1(2), 3 (2022) 22
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W., et al.: Lora: Low-rank adaptation of large language models. Iclr1(2), 3 (2022) 22
2022
-
[18]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Hu, L.: Animate anyone: Consistent and controllable image-to-video synthesis for character animation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 8153–8163 (2024) 2, 4
2024
-
[19]
ACM Transactions on Graphics (TOG)44(6), 1–15 (2025) 4
Huang, T., Zheng, W., Wang, T., Liu, Y., Wang, Z., Wu, J., Jiang, J., Li, H., Lau, R., Zuo, W., et al.: Voyager: Long-range and world-consistent video diffusion for explorable 3d scene generation. ACM Transactions on Graphics (TOG)44(6), 1–15 (2025) 4
2025
-
[20]
Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion
Huang, X., Li, Z., He, G., Zhou, M., Shechtman, E.: Self forcing: Bridging the train-test gap in autoregressive video diffusion. arXiv preprint arXiv:2506.08009 (2025) 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Jafarian, Y., Park, H.S.: Learning high fidelity depths of dressed humans by watch- ing social media dance videos. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 12753–12762 (2021) 10
2021
-
[22]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Jiang, Z., Han, Z., Mao, C., Zhang, J., Pan, Y., Liu, Y.: Vace: All-in-one video creation and editing. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 17191–17202 (2025) 2
2025
-
[23]
ACM Trans
Kerbl, B., Kopanas, G., Leimkühler, T., Drettakis, G., et al.: 3d gaussian splatting for real-time radiance field rendering. ACM Trans. Graph.42(4), 139–1 (2023) 4
2023
-
[24]
Adam: A Method for Stochastic Optimization
Kingma, D.P., Ba, J.: Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014) 9
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[25]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Kong, W., Tian, Q., Zhang, Z., Min, R., Dai, Z., Zhou, J., Xiong, J., Li, X., Wu, B., Zhang, J., et al.: Hunyuanvideo: A systematic framework for large video generative models. arXiv preprint arXiv:2412.03603 (2024) 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
arXiv preprint arXiv:2506.172012(3), 6 (2025) 4
Li, J., Tang, J., Xu, Z., Wu, L., Zhou, Y., Shao, S., Yu, T., Cao, Z., Lu, Q.: Hunyuan-gamecraft: High-dynamic interactive game video generation with hybrid history condition. arXiv preprint arXiv:2506.172012(3), 6 (2025) 4
-
[27]
ACM Transactions on Graphics, (Proc
Li, T., Bolkart, T., Black, M.J., Li, H., Romero, J.: Learning a model of facial shape and expression from 4D scans. ACM Transactions on Graphics, (Proc. SIGGRAPH Asia)36(6), 194:1–194:17 (2017),https://doi.org/10.1145/3130800.31308136, 23
-
[28]
Flow Matching for Generative Modeling
Lipman, Y., Chen, R.T., Ben-Hamu, H., Nickel, M., Le, M.: Flow matching for generative modeling. arXiv preprint arXiv:2210.02747 (2022) 9, 21
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[29]
IEEE Transactions on Pattern Analysis and Machine Intelligence44(9), 5115–5133 (2021) 4
Liu, W., Piao, Z., Tu, Z., Luo, W., Ma, L., Gao, S.: Liquid warping gan with attention: A unified framework for human image synthesis. IEEE Transactions on Pattern Analysis and Machine Intelligence44(9), 5115–5133 (2021) 4
2021
-
[30]
arXiv preprint arXiv:2502.10982 (2025) 9, 24
Liu, Y., Zhu, L., Lin, L., Zhu, Y., Zhang, A., Li, Y.: Teaser: Token enhanced spatial modeling for expressions reconstruction. arXiv preprint arXiv:2502.10982 (2025) 9, 24
-
[31]
Loper, M., Mahmood, N., Romero, J., Pons-Moll, G., Black, M.J.: SMPL: A skinnedmulti-personlinearmodel.ACMTrans.Graphics(Proc.SIGGRAPHAsia) 34(6), 248:1–248:16 (Oct 2015) 2, 4, 6
2015
-
[32]
Ovi: Twin Backbone Cross-Modal Fusion for Audio-Video Generation
Low, C., Wang, W., Katyal, C.: Ovi: Twin backbone cross-modal fusion for audio- video generation. arXiv preprint arXiv:2510.01284 (2025) 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
MediaPipe: A Framework for Building Perception Pipelines
Lugaresi, C., Tang, J., Nash, H., McClanahan, C., Uboweja, E., Hays, M., Zhang, F., Chang, C.L., Yong, M.G., Lee, J., et al.: Mediapipe: A framework for building perception pipelines. arXiv preprint arXiv:1906.08172 (2019) 9, 23
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[34]
In: Proceedings of EMOSH 17 the IEEE/CVF International Conference on Computer Vision
Luo, Y., Rong, Z., Wang, L., Zhang, L., Hu, T.: Dreamactor-m1: Holistic, expres- sive and robust human image animation with hybrid guidance. In: Proceedings of EMOSH 17 the IEEE/CVF International Conference on Computer Vision. pp. 11036–11046 (2025) 2
2025
-
[35]
Advances in neural information processing systems30 (2017) 4
Ma, L., Jia, X., Sun, Q., Schiele, B., Tuytelaars, T., Van Gool, L.: Pose guided person image generation. Advances in neural information processing systems30 (2017) 4
2017
-
[36]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Ma, Y., He, Y., Cun, X., Wang, X., Chen, S., Li, X., Chen, Q.: Follow your pose: Pose-guided text-to-video generation using pose-free videos. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 38, pp. 4117–4125 (2024) 4
2024
-
[37]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Meng, R., Zhang, X., Li, Y., Ma, C.: Echomimicv2: Towards striking, simplified, and semi-body human animation. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 5489–5498 (2025) 10
2025
-
[38]
Commu- nications of the ACM65(1), 99–106 (2021) 4
Mildenhall, B., Srinivasan, P.P., Tancik, M., Barron, J.T., Ramamoorthi, R., Ng, R.: Nerf: Representing scenes as neural radiance fields for view synthesis. Commu- nications of the ACM65(1), 99–106 (2021) 4
2021
-
[39]
com / MooreThreads / Moore-AnimateAnyone(2024), accessed: 2026-02-15 9
Moore Threads: Moore-animateanyone.https : / / github . com / MooreThreads / Moore-AnimateAnyone(2024), accessed: 2026-02-15 9
2024
-
[40]
Advances in neural information processing sys- tems32(2019) 9, 26
Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., Killeen, T., Lin, Z., Gimelshein, N., Antiga, L., et al.: Pytorch: An imperative style, high- performance deep learning library. Advances in neural information processing sys- tems32(2019) 9, 26
2019
-
[41]
In: Proceedings IEEE Conf
Pavlakos, G., Choutas, V., Ghorbani, N., Bolkart, T., Osman, A.A.A., Tzionas, D., Black, M.J.: Expressive body capture: 3D hands, face, and body from a single image. In: Proceedings IEEE Conf. on Computer Vision and Pattern Recognition (CVPR). pp. 10975–10985 (2019) 6, 23
2019
-
[42]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Pavlakos, G., Shan, D., Radosavovic, I., Kanazawa, A., Fouhey, D., Malik, J.: Reconstructing hands in 3d with transformers. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 9826–9836 (2024) 9, 24
2024
-
[43]
Peebles,W.,Xie,S.:Scalablediffusionmodelswithtransformers.In:Proceedingsof the IEEE/CVF international conference on computer vision. pp. 4195–4205 (2023) 3, 5, 9, 22
2023
-
[44]
Qian, S., Kirschstein, T., Schoneveld, L., Davoli, D., Giebenhain, S., Nießner, M.: Gaussianavatars:Photorealisticheadavatarswithrigged3dgaussians.In:Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 20299–20309 (2024) 4
2024
-
[45]
Geometry-Contrastive GAN for Facial Expression Transfer
Qiao, F., Yao, N., Jiao, Z., Li, Z., Chen, H., Wang, H.: Geometry-contrastive gan for facial expression transfer. arXiv preprint arXiv:1802.01822 (2018) 4
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[46]
arXiv preprint arXiv:2512.21338 (2025) 4, 8
Qiu, H., Liu, S., Zhou, Z., An, Z., Ren, W., Liu, Z., Schult, J., He, S., Chen, S., Cong, Y., et al.: Histream: Efficient high-resolution video generation via redundancy-eliminated streaming. arXiv preprint arXiv:2512.21338 (2025) 4, 8
-
[47]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Qiu, L., Gu, X., Li, P., Zuo, Q., Shen, W., Zhang, J., Qiu, K., Yuan, W., Chen, G., Dong, Z., et al.: Lhm: Large animatable human reconstruction model for single image to 3d in seconds. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 14184–14194 (2025) 4
2025
-
[48]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PmLR (2021) 5
2021
-
[49]
Journal of machine learning research21(140), 1–67 (2020) 5 18 D
Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y., Li, W., Liu, P.J.: Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of machine learning research21(140), 1–67 (2020) 5 18 D. Zhang et al
2020
-
[50]
In: International conference on machine learning
Ramesh, A., Pavlov, M., Goh, G., Gray, S., Voss, C., Radford, A., Chen, M., Sutskever, I.: Zero-shot text-to-image generation. In: International conference on machine learning. pp. 8821–8831. Pmlr (2021) 3
2021
-
[51]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10684–10695 (2022) 3
2022
-
[52]
Runway: Introducing runway gen-4.5: A new frontier for video generation.https: //runwayml.com/research/introducing-runway-gen-4.5(2025), accessed: 2026- 02-15 3
2025
-
[53]
Advances in neural information processing systems35, 36479–36494 (2022) 3
Saharia, C., Chan, W., Saxena, S., Li, L., Whang, J., Denton, E.L., Ghasemipour, K., Gontijo Lopes, R., Karagol Ayan, B., Salimans, T., et al.: Photorealistic text- to-image diffusion models with deep language understanding. Advances in neural information processing systems35, 36479–36494 (2022) 3
2022
-
[54]
ACM Transactions on Graphics (TOG)43(6), 1–13 (2024) 4
Shao, R., Pang, Y., Zheng, Z., Sun, J., Liu, Y.: 360-degree human video generation with 4d diffusion transformer. ACM Transactions on Graphics (TOG)43(6), 1–13 (2024) 4
2024
-
[55]
Shen, L., Qiao, Q., Yu, T., Zhou, K., Yu, T., Zhan, Y., Wang, Z., Tao, M., Yin, S., Liu, S.: Soulx-flashtalk: Real-time infinite streaming of audio-driven avatars via self-correcting bidirectional distillation (2025),https://arxiv.org/abs/2512. 233798
2025
-
[56]
In: SIGGRAPH Asia 2024 Conference Papers
Shen,Z.,Pi,H.,Xia,Y.,Cen,Z.,Peng,S.,Hu,Z.,Bao,H.,Hu,R.,Zhou,X.:World- grounded human motion recovery via gravity-view coordinates. In: SIGGRAPH Asia 2024 Conference Papers. pp. 1–11 (2024) 9, 24
2024
-
[57]
Advances in neural information processing systems32 (2019) 2
Siarohin, A., Lathuilière, S., Tulyakov, S., Ricci, E., Sebe, N.: First order motion model for image animation. Advances in neural information processing systems32 (2019) 2
2019
-
[58]
In: Proceedings of the IEEE conference on com- puter vision and pattern recognition
Siarohin, A., Sangineto, E., Lathuiliere, S., Sebe, N.: Deformable gans for pose- based human image generation. In: Proceedings of the IEEE conference on com- puter vision and pattern recognition. pp. 3408–3416 (2018) 2
2018
-
[59]
Make-A-Video: Text-to-Video Generation without Text-Video Data
Singer, U., Polyak, A., Hayes, T., Yin, X., An, J., Zhang, S., Hu, Q., Yang, H., Ashual, O., Gafni, O., et al.: Make-a-video: Text-to-video generation without text- video data. arXiv preprint arXiv:2209.14792 (2022) 3
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[60]
In: Proceedings of the SIGGRAPH Asia 2025 Conference Papers
Song, G., Xu, H., Zhao, X., Xie, Y., Gu, T., Li, Z., Zhang, C., Luo, L.: X-unimotion: Animating human images with expressive, unified and identity-agnostic motion latents. In: Proceedings of the SIGGRAPH Asia 2025 Conference Papers. pp. 1–11 (2025) 2
2025
-
[61]
Denoising Diffusion Implicit Models
Song, J., Meng, C., Ermon, S.: Denoising diffusion implicit models. arXiv preprint arXiv:2010.02502 (2020) 3
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[62]
Score-Based Generative Modeling through Stochastic Differential Equations
Song, Y., Sohl-Dickstein, J., Kingma, D.P., Kumar, A., Ermon, S., Poole, B.: Score- based generative modeling through stochastic differential equations. arXiv preprint arXiv:2011.13456 (2020) 2
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[63]
Neurocomputing568, 127063 (2024) 4
Su, J., Ahmed, M., Lu, Y., Pan, S., Bo, W., Liu, Y.: Roformer: Enhanced trans- former with rotary position embedding. Neurocomputing568, 127063 (2024) 4
2024
-
[64]
IEEE Transactions on Pattern Analysis and Machine Intelligence45(4), 4682–4693 (2022) 4
Sun, Y.T., Fu, Q.C., Jiang, Y.R., Liu, Z., Lai, Y.K., Fu, H., Gao, L.: Human motion transfer with 3d constraints and detail enhancement. IEEE Transactions on Pattern Analysis and Machine Intelligence45(4), 4682–4693 (2022) 4
2022
-
[65]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Tu, S., Xing, Z., Han, X., Cheng, Z.Q., Dai, Q., Luo, C., Wu, Z.: Stableanimator: High-quality identity-preserving human image animation. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 21096–21106 (2025) 4, 9 EMOSH 19
2025
-
[66]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Tulyakov, S., Liu, M.Y., Yang, X., Kautz, J.: Mocogan: Decomposing motion and content for video generation. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 1526–1535 (2018) 3
2018
-
[67]
Phenaki: Variable Length Video Generation From Open Domain Textual Description
Villegas, R., Babaeizadeh, M., Kindermans, P.J., Moraldo, H., Zhang, H., Saffar, M.T., Castro, S., Kunze, J., Erhan, D.: Phenaki: Variable length video generation from open domain textual description. arXiv preprint arXiv:2210.02399 (2022) 3
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[68]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan, T., Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.W., Chen, D., Yu, F., Zhao, H., Yang, J., et al.: Wan: Open and advanced large-scale video generative models. arXiv preprint arXiv:2503.20314 (2025) 4, 5, 8, 9, 22
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[69]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wang,T.,Li,L.,Lin,K.,Zhai,Y.,Lin,C.C.,Yang,Z.,Zhang,H.,Liu,Z.,Wang,L.: Disco: Disentangled control for realistic human dance generation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 9326–9336 (2024) 4
2024
-
[70]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Wang, T.C., Mallya, A., Liu, M.Y.: One-shot free-view neural talking-head syn- thesis for video conferencing. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10039–10049 (2021) 4
2021
-
[71]
Science China Information Sciences68(10), 200103 (2025) 4, 10, 21
Wang, X., Zhang, S., Gao, C., Wang, J., Zhou, X., Zhang, Y., Yan, L., Sang, N.: Unianimate: Taming unified video diffusion models for consistent human image animation. Science China Information Sciences68(10), 200103 (2025) 4, 10, 21
2025
-
[72]
IEEE Transactions on Multimedia23, 2457–2470 (2020) 2, 4
Wei, D., Xu, X., Shen, H., Huang, K.: Gac-gan: A general method for appearance- controllable human video motion transfer. IEEE Transactions on Multimedia23, 2457–2470 (2020) 2, 4
2020
-
[73]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Xie, L., Wang, X., Zhang, H., Dong, C., Shan, Y.: Vfhq: A high-quality dataset and benchmark for video face super-resolution. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 657–666 (2022) 9
2022
-
[74]
arXiv preprint arXiv:2505.22977 (2025) 2, 4, 9, 21
Xu, S., Zheng, S., Wang, Z., Yu, H., Chen, J., Zhang, H., Li, B., Jiang, P.T.: Hypermotion: Dit-based pose-guided human image animation of complex motions. arXiv preprint arXiv:2505.22977 (2025) 2, 4, 9, 21
-
[75]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Xu, Z., Zhang, J., Liew, J.H., Yan, H., Liu, J.W., Zhang, C., Feng, J., Shou, M.Z.: Magicanimate: Temporally consistent human image animation using diffu- sion model. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 1481–1490 (2024) 4
2024
-
[76]
VideoGPT: Video Generation using VQ-VAE and Transformers
Yan, W., Zhang, Y., Abbeel, P., Srinivas, A.: Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:2104.10157 (2021) 3
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[77]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Yang, Z., Zeng, A., Yuan, C., Li, Y.: Effective whole-body pose estimation with two-stages distillation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 4210–4220 (2023) 4, 9, 23
2023
-
[78]
arXiv preprint arXiv:2512.05081 (2025) 4
Yi, J., Jang, W., Cho, P.H., Nam, J., Yoon, H., Kim, S.: Deep forcing: Training-free long video generation with deep sink and participative compression. arXiv preprint arXiv:2512.05081 (2025) 4
-
[79]
Zhang, D., Liu, Y., Lin, L., Zhu, Y., Chen, K., Qin, M., Li, Y., Wang, H.: Hravatar: High-qualityandrelightablegaussianheadavatar.In:ProceedingsoftheComputer Vision and Pattern Recognition Conference. pp. 26285–26296 (2025) 4
2025
-
[80]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Zhang, D., Liu, Y., Lin, L., Zhu, Y., Li, Y., Qin, M., Li, Y., Wang, H.: Guava: Generalizable upper body 3d gaussian avatar. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 14205–14217 (2025) 2, 4, 6, 21, 23, 27
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.