Learning Stable In-Grasp Manipulation in a Non-Dropping Action Space
Pith reviewed 2026-06-29 04:11 UTC · model grok-4.3
The pith
Decomposing in-grasp manipulation into theory-constrained components makes reinforcement learning efficient and stable for repositioning without dropping.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By decomposing dexterous skills into multiple simpler and analyzable components and learning each component with explicit constraints and guidance drawn from classical physics and control theory, the acquisition of stable grasp maintenance together with in-grasp reposition and reorientation becomes both efficient and stable, even when objects, sensor and motor noise, communication latency, and frictional conditions vary.
What carries the argument
Decomposition of the full manipulation skill into simpler components, each constrained by classical physics and control theory, inside a non-dropping action space that prevents object release.
If this is right
- Stable in-grasp repositioning and reorientation become learnable for multiple object geometries without hand-specific analytic models.
- The learned skills remain functional under realistic sensor noise, motor noise, and communication delays.
- Friction variations between object and finger surfaces no longer require separate retuning of the controller.
- The non-dropping constraint built into the action space keeps the object in the hand throughout learning and execution.
Where Pith is reading between the lines
- The same decomposition pattern could be applied to other contact-rich tasks such as in-hand tool use or precise assembly.
- The non-dropping action space may serve as a reusable safety layer when combining learned skills with model-based planners.
- Because each component stays analyzable, the approach may allow incremental addition of new sub-skills without retraining the entire policy.
Load-bearing premise
That the instability and objective conflicts seen in end-to-end RL arise mainly from the lack of explicit physical constraints on each sub-skill and can therefore be removed by decomposition.
What would settle it
A controlled experiment in which an unconstrained end-to-end RL agent is trained on the same in-grasp repositioning task with added latency and friction variation and is shown to drop the object or fail to converge while the decomposed version succeeds within the same number of trials.
Figures


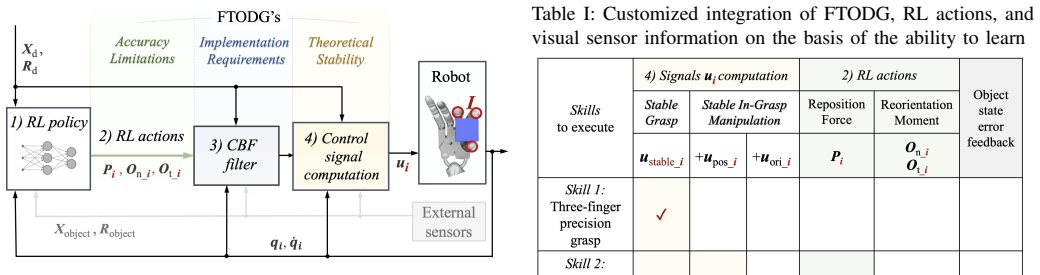

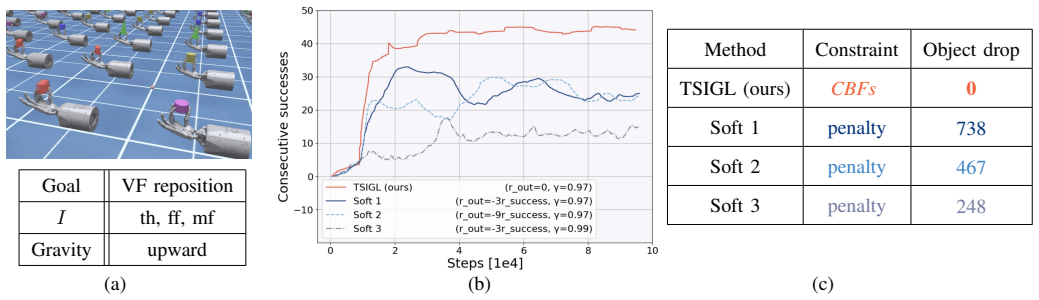

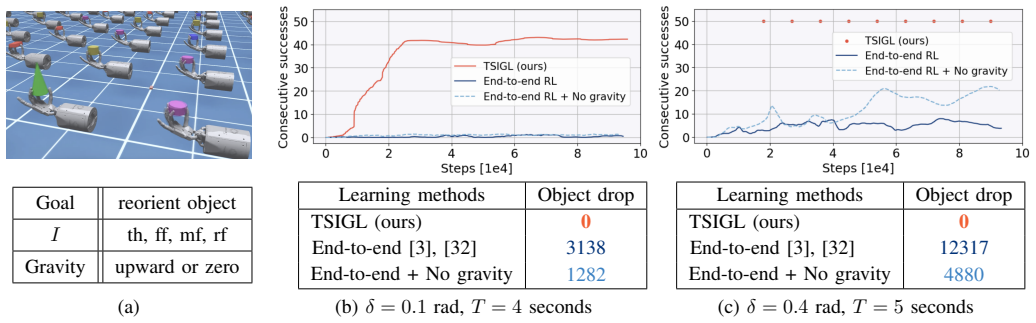

read the original abstract
Traditionally, dexterous manipulation controllers are designed using analytic models constrained by strong assumptions about the hand and the objects being manipulated. Reinforcement learning (RL) has become another common approach in which skills are explored openly in an end-to-end manner but is inefficient because of unnoticeable instability and conflicts in learning objectives. This paper attempts to efficiently explore stable and accurate manipulation skills by decomposing dexterous skills into multiple simpler/analyzable components. Each skill component is subsequently learned with constraints and guidance from classical physics and control theory. Our work shows that for stable grasp, in-grasp reposition/reorientation with different objects, sensor/motor noise, latency, and frictional conditions, skill learning becomes efficient and stable with prior knowledge from theory.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript argues that analytic dexterous manipulation controllers rely on strong assumptions while end-to-end RL suffers from instability and objective conflicts; it proposes decomposing skills into simpler components each constrained by classical physics and control theory, claiming this yields efficient and stable learning for stable grasp and in-grasp reposition/reorientation across objects, sensor/motor noise, latency, and friction.
Significance. If the empirical results hold, the hybrid decomposition could reduce sample inefficiency in RL for dexterous tasks by injecting domain knowledge, offering a practical bridge between model-based control and learning-based methods.
major comments (1)
- Abstract: the central empirical claim that 'skill learning becomes efficient and stable with prior knowledge from theory' is asserted without any quantitative results, baselines, metrics (e.g., success rate, sample efficiency), experimental protocol, or even a high-level description of the decomposition or constraints; this is load-bearing because the contribution is presented as an outcome rather than a derivation.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. The single major comment concerns the abstract; we address it directly below and agree that a revision is warranted to better support the central claim.
read point-by-point responses
-
Referee: [—] Abstract: the central empirical claim that 'skill learning becomes efficient and stable with prior knowledge from theory' is asserted without any quantitative results, baselines, metrics (e.g., success rate, sample efficiency), experimental protocol, or even a high-level description of the decomposition or constraints; this is load-bearing because the contribution is presented as an outcome rather than a derivation.
Authors: The abstract is intended as a concise summary of the full manuscript, which details the decomposition into physics-constrained components, the experimental protocol (including object variations, noise, latency, and friction conditions), baselines, success rates, and sample-efficiency metrics in the Experiments and Results sections. We agree, however, that the abstract itself should more explicitly preview these elements to stand alone. We will revise the abstract to include a high-level description of the decomposition and constraints together with key quantitative outcomes (e.g., success-rate improvements and reduced sample complexity relative to end-to-end RL). revision: yes
Circularity Check
No significant circularity identified
full rationale
The abstract and description present an empirical approach: decomposing dexterous skills into simpler components, each learned under constraints from classical physics and control theory, with results framed as experimental outcomes across objects, noise, latency, and friction. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains are visible that would reduce any claimed result to its own inputs by construction. The derivation chain is therefore self-contained against external benchmarks, with the central claim left to validation by unseen experiments rather than deductive necessity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Trends and challenges in robot manipulation,
A. Billard and D. Kragic, “Trends and challenges in robot manipulation,” Science, vol. 364, no. 6446, p. eaat8414, 2019
2019
-
[2]
Toward next-generation learned robot manipula- tion,
J. Cui and J. Trinkle, “Toward next-generation learned robot manipula- tion,”Science Robotics, vol. 6, no. 54, p. eabd9461, 2021
2021
-
[3]
Learning dexterous in-hand manipulation,
OpenAI, M. Andrychowicz, B. Baker, M. Chociej, R. J ´ozefowicz, B. McGrew, J. Pachocki, A. Petron, M. Plappert, G. Powell, A. Ray, J. Schneider, S. Sidor, J. Tobin, P. Welinder, L. Weng, and W. Zaremba, “Learning dexterous in-hand manipulation,”The International Journal of Robotics Research, vol. 39, no. 1, pp. 3–20, 2020
2020
-
[4]
Learning purely tactile in-hand manipulation with a torque-controlled hand,
L. Sievers, J. Pitz, and B. B ¨auml, “Learning purely tactile in-hand manipulation with a torque-controlled hand,” inProceedings of the International Conference on Robotics and Automation (ICRA), 2022, pp. 2745–2751
2022
-
[5]
Stable in-hand manipulation with finger-specific multi-agent shadow critic consensus and information sharing,
L. Tao, J. Zhang, and X. Zhang, “Stable in-hand manipulation with finger-specific multi-agent shadow critic consensus and information sharing,”IEEE Robotics and Automation Letters, vol. 10, no. 3, pp. 2407–2413, 2025
2025
-
[6]
Guided rein- forcement learning: A review and evaluation for efficient and effective real-world robotics,
J. Eßer, N. Bach, C. Jestel, O. Urbann, and S. Kerner, “Guided rein- forcement learning: A review and evaluation for efficient and effective real-world robotics,”IEEE Robotics and Automation Magazine, vol. 30, no. 2, pp. 67–85, 2023
2023
-
[7]
Arimoto,Control Theory of Multi-fingered Hands: A Modelling and Analytical–Mechanics Approach for Dexterity and Intelligence
S. Arimoto,Control Theory of Multi-fingered Hands: A Modelling and Analytical–Mechanics Approach for Dexterity and Intelligence. Springer London, 2008
2008
-
[8]
Safe learning in robotics: From learning-based control to safe reinforcement learning,
L. Brunke, M. Greeff, A. W. Hall, Z. Yuan, S. Zhou, J. Panerati, and A. P. Schoellig, “Safe learning in robotics: From learning-based control to safe reinforcement learning,”Annual Review of Control, Robotics, and Autonomous Systems, vol. 5, no. V olume 5, pp. 411–444, 2022
2022
-
[9]
Multi-fingered in-hand manipulation with various object properties using graph convolutional networks and distributed tactile sensors,
S. Funabashi, T. Isobe, F. Hongyi, A. Hiramoto, A. Schmitz, S. Sugano, and T. Ogata, “Multi-fingered in-hand manipulation with various object properties using graph convolutional networks and distributed tactile sensors,”IEEE Robotics and Automation Letters, vol. 7, no. 2, pp. 2102– 2109, 2022
2022
-
[10]
Learning a shape-conditioned agent for purely tactile in-hand manipulation of vari- ous objects,
J. Pitz, L. R ¨ostel, L. Sievers, D. Burschka, and B. B ¨auml, “Learning a shape-conditioned agent for purely tactile in-hand manipulation of vari- ous objects,” inProceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2024, pp. 13 112–13 119
2024
-
[11]
Dextrous tactile in-hand manipulation using a modular reinforcement learning architecture,
J. Pitz, L. R ¨ostel, L. Sievers, and B. B ¨auml, “Dextrous tactile in-hand manipulation using a modular reinforcement learning architecture,” in Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), 2023, pp. 1852–1858
2023
-
[12]
Solving rubik’s cube with a robot hand,
OpenAI, I. Akkaya, M. Andrychowicz, M. Chociej, M. Litwin, B. McGrew, A. Petron, A. Paino, M. Plappert, G. Powell, R. Ribas, J. Schneider, N. Tezak, J. Tworek, P. Welinder, L. Weng, Q. Yuan, W. Zaremba, and L. Zhang, “Solving rubik’s cube with a robot hand,”
-
[13]
Available: https://arxiv.org/abs/1910.07113
[Online]. Available: https://arxiv.org/abs/1910.07113
Pith/arXiv arXiv 1910
-
[14]
Lynch and F
K. Lynch and F. Park,Modern Robotics: Mechanics, Planning, and Control. Cambridge Univeristy Press, 2017
2017
-
[15]
Analysis and control of power grasping,
A. Bicchi, “Analysis and control of power grasping,” inProceedings of the IEEE/RSJ International Workshop on Intelligent Robots and Systems, 1991, pp. 691–697 vol.2
1991
-
[16]
Coordination and control of multi-fingered robot hands with rolling and sliding contacts,
M. Zribi, J. Chen, and M. S. Mahmoud, “Coordination and control of multi-fingered robot hands with rolling and sliding contacts,”Journal of Intelligent and Robotic Systems, vol. 24, no. 2, pp. 125–149, 1999
1999
-
[17]
Rotary object dexterous manipulation in hand: A feedback-based method,
Q. Li, M. Meier, R. Haschke, H. Ritter, and B. Bolder, “Rotary object dexterous manipulation in hand: A feedback-based method,” International Journal of Mechatronics and Automation (IJMA), vol. 3, 01 2013
2013
-
[18]
Dynamic control of sliding by robot hands for regrasping,
A. Cole, P. Hsu, and S. Sastry, “Dynamic control of sliding by robot hands for regrasping,”IEEE Transactions on Robotics and Automation, vol. 8, no. 1, pp. 42–52, 1992
1992
-
[19]
Dynamic force/torque equi- librium for stable grasping by a triple robotic fingers system,
K. Tahara, S. Arimoto, and M. Yoshida, “Dynamic force/torque equi- librium for stable grasping by a triple robotic fingers system,” in Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2009, pp. 2257–2263
2009
-
[20]
Dynamic object manipulation using a virtual frame by a triple soft-fingered robotic hand,
——, “Dynamic object manipulation using a virtual frame by a triple soft-fingered robotic hand,” inProceedings of the IEEE International Conference on Robotics and Automation, 2010, pp. 4322–4327
2010
-
[21]
Externally sensorless dynamic regrasping and manipulation by a triple-fingered robotic hand with torsional fingertip joints,
K. Tahara, K. Maruta, A. Kawamura, and M. Yamamoto, “Externally sensorless dynamic regrasping and manipulation by a triple-fingered robotic hand with torsional fingertip joints,” inProceedings of the IEEE International Conference on Robotics and Automation, 2012, pp. 3252– 3257
2012
-
[22]
Grasp and dexterous manipulation of multi- fingered robotic hands: a review from a control view point,
R. Ozawa and K. Tahara, “Grasp and dexterous manipulation of multi- fingered robotic hands: a review from a control view point,”Advanced Robotics, vol. 31, no. 19-20, pp. 1030–1050, 2017
2017
-
[23]
Residual reinforcement learning for robot control,
T. Johannink, S. Bahl, A. Nair, J. Luo, A. Kumar, M. Loskyll, J. A. Ojea, E. Solowjow, and S. Levine, “Residual reinforcement learning for robot control,” inProceedings of the International Conference on Robotics and Automation (ICRA), 2019, pp. 6023–6029
2019
-
[24]
Deep reinforcement learning for industrial insertion tasks with visual inputs and natural rewards,
G. Schoettler, A. Nair, J. Luo, S. Bahl, J. Aparicio Ojea, E. Solowjow, and S. Levine, “Deep reinforcement learning for industrial insertion tasks with visual inputs and natural rewards,” inProceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2020, pp. 5548–5555
2020
-
[25]
Minimizing energy consump- tion leads to the emergence of gaits in legged robots,
Z. Fu, A. Kumar, J. Malik, and D. Pathak, “Minimizing energy consump- tion leads to the emergence of gaits in legged robots,” inConference on Robot Learning, 2021
2021
-
[26]
Learning to jump from pixels,
G. B. Margolis, T. Chen, K. Paigwar, X. Fu, D. Kim, S. b. Kim, and P. Agrawal, “Learning to jump from pixels,” inProceedings of the 5th Conference on Robot Learning, ser. Proceedings of Machine Learning Research, A. Faust, D. Hsu, and G. Neumann, Eds., vol. 164. PMLR, 08–11 Nov 2022, pp. 1025–1034
2022
-
[27]
Safe reinforcement learning using robust control barrier functions,
Y . Emam, G. Notomista, P. Glotfelter, Z. Kira, and M. Egerstedt, “Safe reinforcement learning using robust control barrier functions,”IEEE Robotics and Automation Letters, vol. 10, no. 3, pp. 2886–2893, 2025
2025
-
[28]
Principles of superposition for controlling pinch motions by means of robot fingers with soft tips,
S. Arimoto, K. Tahara, M. Yamaguchi, P. Nguyen, and M.-Y . Han, “Principles of superposition for controlling pinch motions by means of robot fingers with soft tips,”Robotica, vol. 19, no. 1, pp. 21–28, 2001
2001
-
[29]
Robust visual servoing for object manipulation with large time-delays of visual information,
A. Kawamura, K. Tahara, R. Kurazume, and T. Hasegawa, “Robust visual servoing for object manipulation with large time-delays of visual information,” inProceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2012, pp. 4797–4803
2012
-
[30]
Dexterous object manipulation by a multi- fingered robotic hand with visual-tactile fingertip sensors,
S.-h. Choi and K. Tahara, “Dexterous object manipulation by a multi- fingered robotic hand with visual-tactile fingertip sensors,”ROBOMECH Journal, vol. 7, no. 1, p. 14, 2020
2020
-
[31]
Enabling external sensorless in- hand object position manipulation by linkage-based underactuated hands with mechanical stoppers,
H. T. L. Doan, H. Arita, and K. Tahara, “Enabling external sensorless in- hand object position manipulation by linkage-based underactuated hands with mechanical stoppers,”ROBOMECH Journal, vol. 12, no. 1, p. 39, 2025
2025
-
[32]
Orbit: A unified simulation framework for interactive robot learning environments,
M. Mittal, C. Yu, Q. Yu, J. Liu, N. Rudin, D. Hoeller, J. L. Yuan, R. Singh, Y . Guo, H. Mazhar, A. Mandlekar, B. Babich, G. State, M. Hutter, and A. Garg, “Orbit: A unified simulation framework for interactive robot learning environments,”IEEE Robotics and Automation Letters, vol. 8, no. 6, pp. 3740–3747, 2023
2023
-
[33]
Available: https://isaac-sim.github.io/IsaacLab/v2.3.0
[Online]. Available: https://isaac-sim.github.io/IsaacLab/v2.3.0
-
[34]
Available: https://shadowrobot.com/dexterous-hand-series
[Online]. Available: https://shadowrobot.com/dexterous-hand-series
-
[35]
High-dimensional continuous control using generalized advantage estimation,
J. Schulman, P. Moritz, S. Levine, M. Jordan, and P. Abbeel, “High-dimensional continuous control using generalized advantage estimation,” 2018. [Online]. Available: https://arxiv.org/abs/1506.02438
Pith/arXiv arXiv 2018
-
[36]
Proximal policy optimization algorithms,
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,” 2017. [Online]. Available: https://arxiv.org/abs/1707.06347
Pith/arXiv arXiv 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.