Unleashing Infinite Motion: Scaling Expressive Quadrupedal Motion via Generative Video Priors
Pith reviewed 2026-06-29 04:07 UTC · model grok-4.3
The pith
Uni-Mo generates expressive quadruped motions from text prompts using video diffusion models and lifts them into deployable 3D trajectories.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
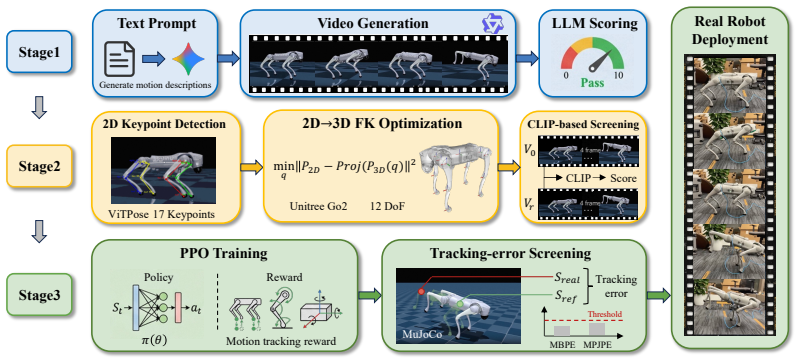
Reframing quadruped motion synthesis as a video generation problem, an LLM proposes motion prompts, a video diffusion model synthesizes the behaviors, and the generated videos are lifted into 3D reference trajectories used to train tracking policies that deploy on physical hardware without any animal data in the loop.
What carries the argument
The Uni-Mo pipeline that chains LLM prompts, video diffusion synthesis, and Identity Consistency Loss to produce coherent videos that lift reliably into 3D motion references.
If this is right
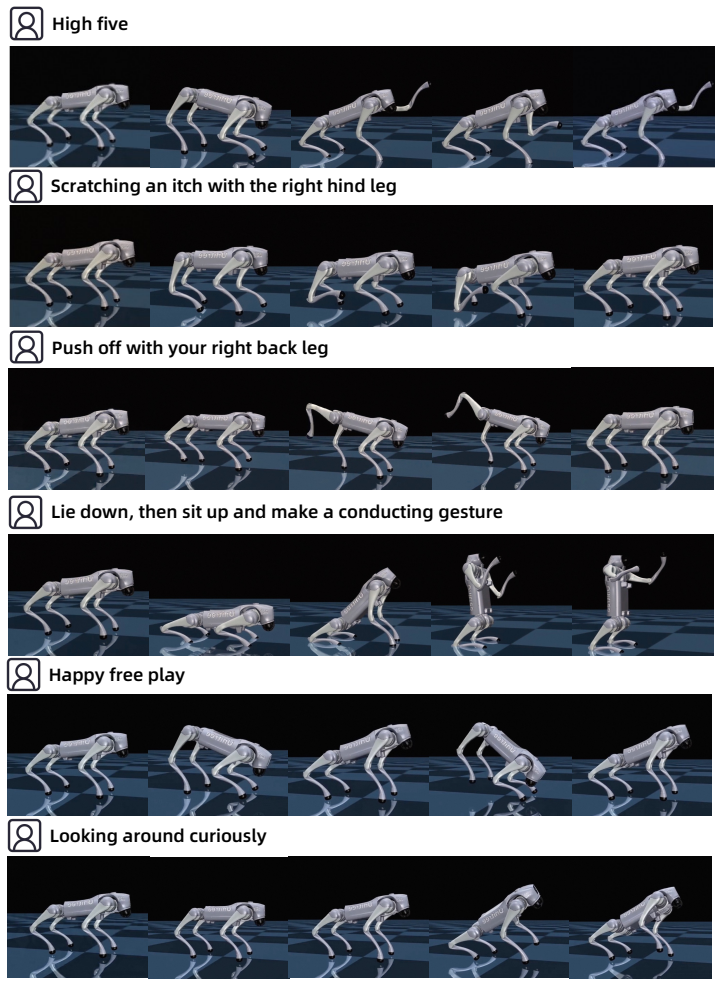
- The released dataset of 7,488 language-annotated motions spanning 18.5 hours supports training of many acrobatic and performative behaviors.
- Tracking policies achieve a 96.7 percent success rate on 392 randomly sampled motions deployed on real hardware.
- A 97.6 percent success rate holds across the full dataset when tested in simulation.
- Expressive motions beyond standard gaits become feasible without animal capture or retargeting steps.
Where Pith is reading between the lines
- Similar prompt-and-lift pipelines could be adapted to other robot morphologies by changing only the video generation prompts.
- The open dataset may serve as a starting point for combining generated motions with small amounts of real data to improve robustness.
- The same generation approach might extend to tasks involving manipulation or multi-robot coordination once suitable video priors exist.
Load-bearing premise
Videos from the diffusion model stay consistent in robot appearance across frames so that accurate 3D trajectories can be extracted and used to train policies that work on real hardware.
What would settle it
If policies trained on the lifted trajectories show deployment success rates well below 90 percent on the physical Unitree Go2, the claim that the generated videos yield usable references would not hold.
Figures






read the original abstract
Quadruped robots have achieved remarkable locomotion, yet their behavioral repertoire remains confined to a few gaits--far from the expressive, companion-like presence long envisioned for them. Attempts to import the humanoid recipe of large-scale motion data have inherited one tacit assumption: that robot motion must first pass through an animal body, making data collection dependent on cooperative animals, reconstruction fragile across species, and retargeting ill-posed across incompatible morphologies. We propose Uni-Mo, a fully automated pipeline that removes the animal from the loop by reframing data scarcity as a generation problem: an LLM proposes motion prompts, a video diffusion model synthesizes the corresponding robot behaviors, and the generated videos are lifted into 3D reference trajectories used to train tracking policies deployed on a real Unitree Go2. To make naively-drifting generations reliably extractable, we introduce an Identity Consistency Loss that enforces appearance coherence across frames. We release Quad-Imaginarium at https://github.com/GaoLii/Quad-Imaginarium.git, the resulting open-source dataset of 7,488 language-annotated quadruped motions (18.5 hours) spanning acrobatic and performative behaviors. We validate 392 randomly sampled motions on a real Unitree Go2 with a 96.7% deployment success rate, complemented by a 97.6% success rate across the full dataset in simulation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents Uni-Mo, a fully automated pipeline for scaling expressive quadrupedal motions without animal data. An LLM generates motion prompts, a video diffusion model with a new Identity Consistency Loss synthesizes robot behaviors, the videos are lifted to 3D reference trajectories, and tracking policies are trained and deployed on a real Unitree Go2. The authors release the Quad-Imaginarium dataset (7,488 language-annotated motions) and report 96.7% success on 392 randomly sampled real-robot deployments plus 97.6% success across the full dataset in simulation.
Significance. If the lifting step produces accurate 3D trajectories, the approach would remove a major bottleneck in quadruped motion generation by replacing animal mocap with generative video priors, enabling broader behavioral repertoires. The open release of the 18.5-hour dataset is a concrete community contribution that supports reproducibility and follow-on work.
major comments (1)
- [Abstract and validation experiments] Abstract and validation experiments: the reported 96.7% real-robot and 97.6% simulation success rates are presented without any quantitative metrics on 3D lifting accuracy (e.g., 3D joint position error, reprojection error, foot-skate, or kinematic consistency against mocap or synthetic ground truth). This is load-bearing for the central claim, because policies could achieve high success rates even with depth-ambiguous or artifact-laden references if trained to be robust to noise.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the evaluation of the 3D lifting step. We address the major comment below.
read point-by-point responses
-
Referee: [Abstract and validation experiments] Abstract and validation experiments: the reported 96.7% real-robot and 97.6% simulation success rates are presented without any quantitative metrics on 3D lifting accuracy (e.g., 3D joint position error, reprojection error, foot-skate, or kinematic consistency against mocap or synthetic ground truth). This is load-bearing for the central claim, because policies could achieve high success rates even with depth-ambiguous or artifact-laden references if trained to be robust to noise.
Authors: We agree that direct quantitative metrics on 3D lifting accuracy would provide valuable additional evidence and address the concern that high policy success could arise from robustness to noisy references rather than accurate trajectories. The real-robot success rate serves as an end-to-end measure of trajectory usability, but we acknowledge the referee's point that intermediate lifting quality metrics strengthen the central claim. In the revised manuscript we will add such evaluations, including 3D joint position error, reprojection error, foot-skate, and kinematic consistency, computed against synthetic ground truth derived from the video generation process and available kinematic priors. revision: yes
Circularity Check
No significant circularity; derivation relies on external validation
full rationale
The paper describes a pipeline of LLM prompt generation, video diffusion synthesis, 3D lifting via Identity Consistency Loss, policy training, and deployment validation on a real Unitree Go2 robot (96.7% success on 392 samples) plus simulation (97.6%). No equations, fitted parameters, or self-citations are presented that reduce any claimed result to an internal definition or input by construction. The reported success rates are measured on physical hardware and independent simulation benchmarks, making the central claims self-contained against external evaluation rather than tautological. No load-bearing steps match the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Video diffusion models trained on general video data can synthesize coherent quadruped robot motions when conditioned on text prompts
- domain assumption 3D trajectories extracted from generated videos are sufficiently accurate to train deployable tracking policies
Reference graph
Works this paper leans on
-
[1]
Cheng, K
X. Cheng, K. Shi, A. Agarwal, and D. Pathak. Extreme parkour with legged robots. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 11443–11450,
-
[2]
doi:10.1109/ICRA57147.2024.10610200
-
[3]
Kumar, Z
A. Kumar, Z. Fu, D. Pathak, and J. Malik. Rma: Rapid motor adaptation for legged robots. 07
-
[4]
doi:10.15607/RSS.2021.XVII.011
- [5]
-
[6]
T. Haarnoja, B. Moran, G. Lever, S. H. Huang, et al. Learning agile soccer skills for a bipedal robot with deep reinforcement learning.Science Robotics, 9(89), 2024. doi: 10.1126/scirobotics.adi8022
-
[7]
T. Li et al. Learning terrain-adaptive locomotion with agile behaviors by imitating animals. In2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 339–345, 2023. doi:10.1109/IROS55552.2023.10342271
-
[8]
Yang et al
R. Yang et al. Generalized animal imitator: Agile locomotion with versatile motion prior. In Conference on Robot Learning, pages 4631–4650, 2023
2023
- [9]
-
[10]
Z. Fu, Q. Zhao, Q. Wu, G. Wetzstein, and C. Finn. Humanplus: Humanoid shadowing and imitation from humans, 2024. URLhttps://arxiv.org/abs/2406.10454
arXiv 2024
-
[11]
X. B. Peng, Y . Guo, L. Halper, S. Levine, and S. Fidler. Ase: large-scale reusable adver- sarial skill embeddings for physically simulated characters.ACM Trans. Graph., 41(4), July
-
[12]
ISSN 0730-0301. doi:10.1145/3528223.3530110. URLhttps://doi.org/10.1145/ 3528223.3530110
-
[13]
M. Ji, X. Peng, F. Liu, J. Li, G. Yang, X. Cheng, and X. Wang. Exbody2: Advanced expressive humanoid whole-body control.arXiv preprint arXiv:2412.13196, 2024
arXiv 2024
-
[14]
T. He, W. Xiao, T. Lin, Z. Luo, Z. Xu, Z. Jiang, J. Kautz, C. Liu, G. Shi, X. Wang, L. Fan, and Y . Zhu. Hover: Versatile neural whole-body controller for humanoid robots.arXiv preprint arXiv:2410.21229, 2024
arXiv 2024
- [15]
- [16]
-
[17]
CMU MoCap Dataset
Carnegie Mellon University. CMU MoCap Dataset. URLhttp://mocap.cs.cmu.edu
-
[18]
Mahmood, N
N. Mahmood, N. Ghorbani, N. F. Troje, G. Pons-Moll, and M. J. Black. AMASS: Archive of motion capture as surface shapes. InInternational Conference on Computer Vision, pages 5442–5451, Oct. 2019
2019
-
[19]
X. Chen, B. Jiang, W. Liu, Z. Huang, B. Fu, T. Chen, J. Yu, and G. Yu. Executing your commands via motion diffusion in latent space.arXiv preprint arXiv:2212.04048, 2023. 9
arXiv 2023
-
[20]
M. Loper, N. Mahmood, J. Romero, G. Pons-Moll, and M. J. Black. Smpl: a skinned multi- person linear model. 34(6), Nov. 2015. ISSN 0730-0301. doi:10.1145/2816795.2818013. URLhttps://doi.org/10.1145/2816795.2818013
-
[21]
Allshire, H
A. Allshire, H. Choi, J. Zhang, D. McAllister, A. Zhang, C. M. Kim, T. Darrell, P. Abbeel, J. Malik, and A. Kanazawa. Visual imitation enables contextual humanoid control. In9th Conference on Robot Learning (CoRL), 2025
2025
-
[22]
J. Z. Zhang et al. Slomo: A general system for legged robot motion imitation from casual videos.IEEE Robotics and Automation Letters, 8:7154–7161, 2023. doi:10.1109/LRA.2023. 3313937
-
[23]
D. Joska, L. Clark, N. Muramatsu, R. Jericevich, F. Nicolls, A. Mathis, M. W. Mathis, and A. Patel. Acinoset: A 3d pose estimation dataset and baseline models for cheetahs in the wild. In2021 IEEE International Conference on Robotics and Automation (ICRA), pages 13901– 13908, 2021. doi:10.1109/ICRA48506.2021.9561338
-
[24]
Z. Wang, S. Chen, L. Mo, X. Gao, Y . Shen, L. Ding, and W. Liang. Dogmo: A large-scale multi-view rgb-d dataset for 4d canine motion recovery, 2025. URLhttps://arxiv.org/ abs/2510.24117
arXiv 2025
-
[25]
H. Yu, Y . Xu, J. Zhang, W. Zhao, Z. Guan, and D. Tao. Ap-10k: A benchmark for animal pose estimation in the wild.arXiv preprint arXiv:2108.12617, 2021
arXiv 2021
-
[26]
L. Zhao, Z. Luo, Y . Han, J. Zhang, Y . Chen, Y . Liu, and P. Lu. Learning aggressive animal locomotion skills for quadrupedal robots solely from monocular videos.npj Robotics, 3(1):32, 2025
2025
-
[27]
E. Chane-Sane, C. Roux, O. Stasse, and N. Mansard. Reinforcement learning from wild animal videos, 2024. URLhttps://arxiv.org/abs/2412.04273
arXiv 2024
-
[28]
S. Zuffi, A. Kanazawa, D. W. Jacobs, and M. J. Black. 3D Menagerie: Modeling the 3D Shape and Pose of Animals . In2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 5524–5532, Los Alamitos, CA, USA, July 2017. IEEE Computer Society. doi:10.1109/CVPR.2017.586. URLhttps://doi.ieeecomputersociety.org/ 10.1109/CVPR.2017.586
-
[29]
Wan Team, A. Wang, B. Ai, B. Wen, C. Mao, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
Pith/arXiv arXiv 2025
-
[30]
W. Kong, Q. Tian, Z. Zhang, R. Min, Z. Dai, J. Zhou, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603, 2024
Pith/arXiv arXiv 2024
-
[31]
Team Seedance, D. Chen, L. Chen, X. Chen, Y . Chen, et al. Seedance 2.0: Advancing video generation for world complexity, 2026. URLhttps://arxiv.org/abs/2604.14148
Pith/arXiv arXiv 2026
-
[32]
L. Mou, J. Lei, C. Wang, L. Liu, and K. Daniilidis. Dimo: Diverse 3d motion generation for arbitrary objects, 2025. URLhttps://arxiv.org/abs/2511.07409
arXiv 2025
-
[33]
J. Mao, S. He, H.-N. Wu, Y . You, S. Sun, Z. Wang, Y . Bao, H. Chen, L. Guibas, V . Guizilini, H. Zhou, and Y . Wang. Robot learning from a physical world model, 2025. URLhttps: //arxiv.org/abs/2511.07416
arXiv 2025
-
[34]
K. Ye, Y . Wu, S. Hu, J. Li, M. Liu, Y . Chen, and R. Huang. Gen2real: Towards demo-free dexterous manipulation by harnessing generated video, 2025. URLhttps://arxiv.org/ abs/2509.14178
arXiv 2025
-
[35]
J. Ni, Z. Wang, W. Lin, A. Bar, Y . LeCun, T. Darrell, J. Malik, and R. Herzig. From generated human videos to physically plausible robot trajectories, 2025. URLhttps://arxiv.org/ abs/2512.05094. 10
arXiv 2025
-
[36]
S. Wu, F. Teng, H. Shi, Q. Jiang, K. Luo, K. Wang, and K. Yang. Quadreamer: Controllable panoramic video generation for quadruped robots, 2025. URLhttps://arxiv.org/abs/ 2508.02512
arXiv 2025
-
[37]
Y . Tang, Y . Lou, P. Han, H. Song, X. Ye, D. Wang, and B. Zhao. Trajectory conditioned cross-embodiment skill transfer, 2025. URLhttps://arxiv.org/abs/2510.07773
arXiv 2025
-
[38]
H. Li, L. Sun, Y . Hu, D. Ta, J. Barry, G. Konidaris, and J. Fu. Novaflow: Zero-shot manip- ulation via actionable flow from generated videos, 2025. URLhttps://arxiv.org/abs/ 2510.08568
arXiv 2025
- [39]
-
[40]
X. B. Peng, E. Coumans, T. Zhang, T.-W. Lee, J. Tan, and S. Levine. Learning agile robotic locomotion skills by imitating animals. InRobotics: Science and Systems, 2020. doi:10.15607/ rss.2020.xvi.064
2020
-
[41]
X. B. Peng, Z. Ma, P. Abbeel, S. Levine, and A. Kanazawa. Amp: Adversarial motion priors for stylized physics-based character control.ACM Transactions on Graphics (TOG), 40(4): 1–20, 2021. doi:10.1145/3450626.3459670
-
[42]
A. Escontrela et al. Adversarial motion priors make good substitutes for complex reward functions. In2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 25–32, 2022. doi:10.1109/IROS47612.2022.9981973
-
[43]
S. Bohez et al. Imitate and repurpose: Learning reusable robot movement skills from human and animal behaviors. InarXiv preprint arXiv:2203.17138, 2022
arXiv 2022
-
[44]
T. Yoon, D. Kang, S. Kim, M. Ahn, S. Coros, and S. Choi. Spatio-temporal motion retargeting for quadruped robots.IEEE Transactions on Robotics, 41:5471–5490, 2024. doi:10.1109/ TRO.2025.3600123
arXiv 2024
-
[45]
X. Huang et al. Diffuseloco: Real-time legged locomotion control with diffusion from offline datasets.arXiv preprint arXiv:2404.19264, 2024
arXiv 2024
-
[46]
Y . Chen, L. Zhao, J. Ma, and P. Lu. In-between motion generation based multi-style quadruped robot locomotion, 2025. URLhttps://arxiv.org/abs/2507.23053
arXiv 2025
-
[47]
L. Gao, F. Yang, J. Chen, L. Liu, Y . Zheng, Y . Cai, and Z. Li. Quadfm: Foundational text- driven quadruped motion dataset for generation and control, 2026. URLhttps://arxiv. org/abs/2603.24021
arXiv 2026
-
[48]
M. Wang, Z. Wang, H. Xu, K. Hu, Z. Wang, and W. Kang. T2qrm: Text-driven quadruped robot motion generation. InProceedings of the 6th ACM International Conference on Multimedia in Asia, MMAsia ’24, New York, NY , USA, 2024. Association for Computing Machinery. ISBN 9798400712739. doi:10.1145/3696409.3700230. URLhttps://doi.org/10.1145/ 3696409.3700230
-
[49]
Q. Liao, T. E. Truong, X. Huang, Y . Gao, G. Tevet, K. Sreenath, and C. K. Liu. Beyondmimic: From motion tracking to versatile humanoid control via guided diffusion, 2025. URLhttps: //arxiv.org/abs/2508.08241
Pith/arXiv arXiv 2025
-
[50]
Gemini Team, R. Anil, S. Borgeaud, J.-B. Alayrac, et al. Gemini: A family of highly capable multimodal models, 2025. URLhttps://arxiv.org/abs/2312.11805. 11
Pith/arXiv arXiv 2025
-
[51]
M. Oquab, T. Darcet, T. Moutakanni, H. V o, M. Szafraniec, V . Khalidov, P. Fernandez, D. Haz- iza, F. Massa, A. El-Nouby, M. Assran, N. Ballas, W. Galuba, R. Howes, P.-Y . Huang, S.-W. Li, I. Misra, M. Rabbat, V . Sharma, G. Synnaeve, H. Xu, H. Jegou, J. Mairal, P. Labatut, A. Joulin, and P. Bojanowski. Dinov2: Learning robust visual features without sup...
Pith/arXiv arXiv 2024
-
[52]
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen. Lora: Low- rank adaptation of large language models, 2021. URLhttps://arxiv.org/abs/2106. 09685
2021
-
[53]
Y . Xu, J. Zhang, Q. Zhang, and D. Tao. Vitpose: Simple vision transformer baselines for human pose estimation, 2022. URLhttps://arxiv.org/abs/2204.12484
arXiv 2022
-
[54]
M. J. Chong and D. Forsyth. Effectively unbiased fid and inception score and where to find them, 2020. URLhttps://arxiv.org/abs/1911.07023
arXiv 2020
-
[55]
T. Unterthiner, S. van Steenkiste, K. Kurach, R. Marinier, M. Michalski, and S. Gelly. Towards accurate generative models of video: A new metric & challenges, 2019. URLhttps:// arxiv.org/abs/1812.01717
Pith/arXiv arXiv 2019
-
[56]
Comanici, E
G. Comanici, E. Bieber, M. Schaekermann, I. Pasupat, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities,
-
[57]
URLhttps://arxiv.org/abs/2507.06261
-
[58]
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever. Learning transferable visual models from natural language supervision, 2021. URLhttps://arxiv.org/abs/2103.00020
Pith/arXiv arXiv 2021
-
[59]
E. Todorov, T. Erez, and Y . Tassa. Mujoco: A physics engine for model-based control. In 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, pages 5026– 5033, 2012. doi:10.1109/IROS.2012.6386109
-
[60]
Zakka, Q
K. Zakka, Q. Liao, B. Yi, L. L. Lay, K. Sreenath, and P. Abbeel. mjlab: A lightweight framework for gpu-accelerated robot learning, 2026. URLhttps://arxiv.org/abs/2601. 22074. A Implementation Details A.1 Video Generation Model Fine-tuning We fine-tune Wan2.2-I2V-A14B [26] using LoRA [49] with rank 32, targeting the attention projec- tion matrices and fee...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.