Democratic ICAI: Debating Our Way to Steering Principles from Preferences
Pith reviewed 2026-06-29 04:07 UTC · model grok-4.3
The pith
Structured persona debates among LLMs extract richer steering principles from pairwise preferences than single-pass summaries.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
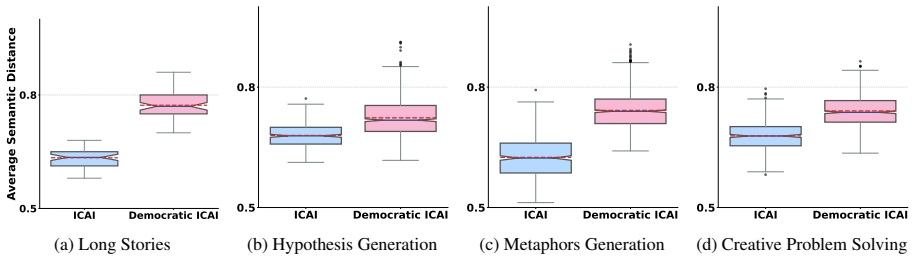
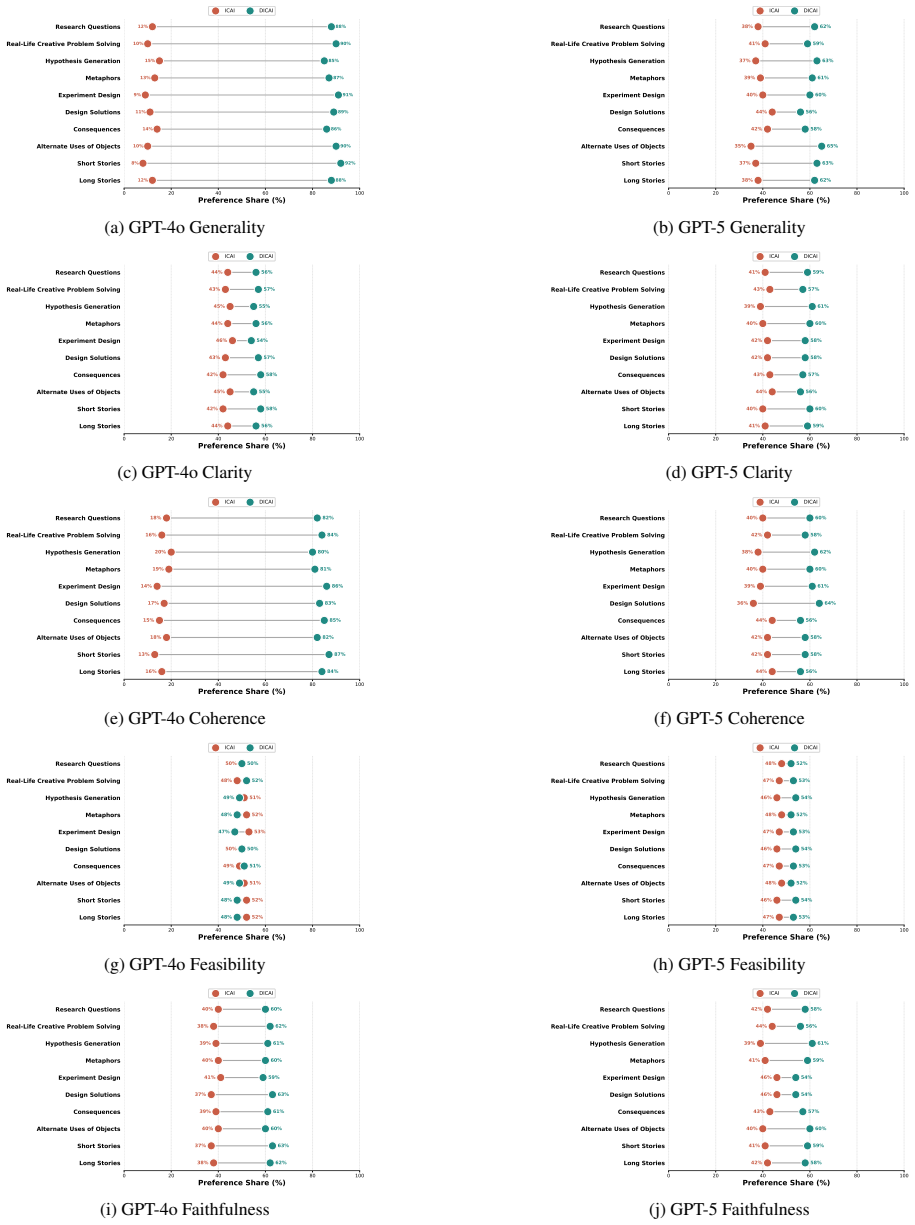
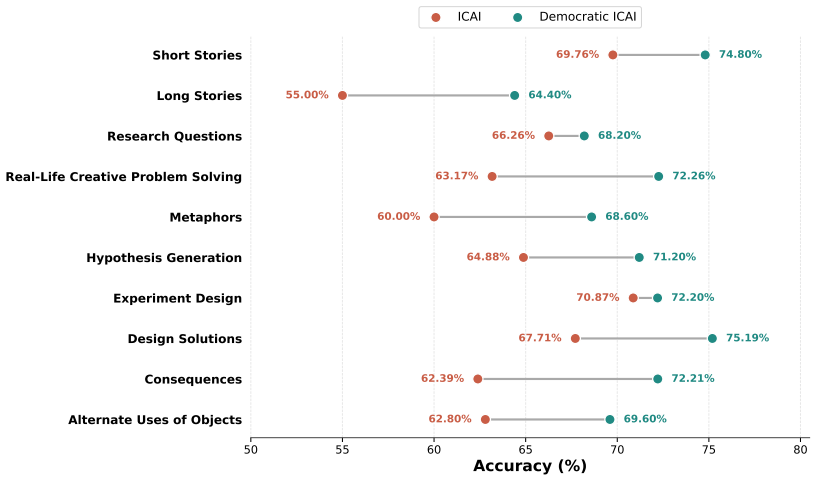
By collecting multiple competing rationales through structured persona debate instead of a single summarization pass, Democratic ICAI derives steering principles that yield a more faithful model of the underlying preference structure, improving average prediction accuracy across tasks while generating constitutions that LLM annotators rate more highly than those from deliberative or principle-based baselines.
What carries the argument
Structured persona debate that assembles multiple competing rationales for each pairwise preference before principle extraction.
If this is right
- Steering principles derived from the debate improve average preference prediction accuracy on MuCE-Pref and LiTBench relative to deliberative prompting and principle-based baselines.
- The same principles produce constitutions that LLM annotators prefer over those from the compared baselines.
- The derived principles can be used by both LLM-based judges and decision-tree judges to model decisions.
- The gains appear across multiple categories of creative tasks.
Where Pith is reading between the lines
- The method could be tested on non-creative domains such as safety or ethical dilemmas to check whether debate richness remains beneficial outside the evaluated benchmarks.
- If the debate step scales linearly with the number of personas, it may offer a practical route to richer signals when preference datasets grow large.
- The approach implicitly treats persona diversity as a proxy for human viewpoint diversity, which could be checked by comparing debate outputs against actual multi-human rationales on the same pairs.
Load-bearing premise
Structured persona debate between LLMs produces a broader and more expressive account of the factors behind each comparison than single-pass summarization without introducing simulation artifacts.
What would settle it
A blind evaluation in which human raters or held-out preference data show no accuracy gain or no preference for the constitutions produced by the debate method over the single-pass baseline.
Figures



























read the original abstract
Preference-based alignment often struggles to capture the reasoning that underlies human judgments. Many evaluations rely on multiple interacting criteria, yet pairwise labels reveal only the final choice rather than the considerations that shape preferences. Inverse Constitutional AI (ICAI) improves interpretability in decision making by summarizing preferences into natural-language principles, but its single-pass explanations miss much of the nuance involved in complex decisions. We introduce Democratic ICAI, a novel approach that gathers multiple competing rationales through structured persona debate, offering a broader and more expressive account of the factors influencing each comparison. From these richer signals, we derive clearer and more comprehensive steering principles and use them to guide decision modeling through both LLM-based and decision-tree judges. Experiments on creative preference benchmarks, MuCE-Pref and LiTBench, across multiple creative task categories show that Democratic ICAI yields a more faithful preference structure. It improves average preference prediction across tasks relative to deliberative prompting and principle-based baselines, while producing constitutions that LLM annotators prefer.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Democratic ICAI, extending Inverse Constitutional AI by using structured persona debates among LLMs to collect multiple competing rationales for pairwise preferences. These richer signals are used to derive steering principles that guide decision modeling via both LLM-based and decision-tree judges. Experiments on the MuCE-Pref and LiTBench creative preference benchmarks report higher average preference prediction accuracy than deliberative prompting and principle-based baselines, along with constitutions that LLM annotators prefer.
Significance. If the gains can be shown to reflect factors that matter to human judges rather than LLM-internal artifacts, the method would strengthen the interpretability of preference-derived principles for multi-criteria alignment tasks. The core idea of moving beyond single-pass summarization is a natural and potentially useful direction.
major comments (2)
- [Experiments] Experiments section (and abstract): preference-prediction gains are measured exclusively with LLM annotators and judges drawn from the same model family that performs persona generation, debate, rationale extraction, and principle derivation. This closed loop means observed lifts could arise from verbosity, consistency, or length biases rather than from a demonstrably more faithful account of the underlying factors; no human-rationale baseline or cross-validation is reported.
- [Method] Method description of structured persona debate: the claim that the debate step produces a 'broader and more expressive account' without simulation artifacts is load-bearing for attributing the MuCE-Pref and LiTBench improvements to the proposed mechanism, yet the manuscript provides no direct test (e.g., comparison of extracted rationales against human reasoning traces) that would separate this effect from prompt-engineering artifacts.
minor comments (1)
- [Abstract] The abstract states improvements 'across multiple creative task categories' but does not enumerate the categories or the number of tasks per benchmark, which would help readers assess the scope of the reported gains.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below, acknowledging where our current experiments leave open questions about generalizability beyond LLM judges.
read point-by-point responses
-
Referee: Experiments section (and abstract): preference-prediction gains are measured exclusively with LLM annotators and judges drawn from the same model family that performs persona generation, debate, rationale extraction, and principle derivation. This closed loop means observed lifts could arise from verbosity, consistency, or length biases rather than from a demonstrably more faithful account of the underlying factors; no human-rationale baseline or cross-validation is reported.
Authors: We agree this is a substantive limitation: all reported gains rely on LLM judges from the same model family, so we cannot rule out that improvements partly reflect model-internal biases rather than more faithful capture of human preference factors. The manuscript will be revised to state this limitation explicitly in the Experiments and Limitations sections and to add cross-family validation (e.g., using a held-out model family for final judging). We did not collect human rationale baselines or conduct human preference studies, so those comparisons are not available. revision: partial
-
Referee: Method description of structured persona debate: the claim that the debate step produces a 'broader and more expressive account' without simulation artifacts is load-bearing for attributing the MuCE-Pref and LiTBench improvements to the proposed mechanism, yet the manuscript provides no direct test (e.g., comparison of extracted rationales against human reasoning traces) that would separate this effect from prompt-engineering artifacts.
Authors: The design of the persona debate aims to surface competing rationales by construction, and the consistent accuracy lifts over single-pass baselines provide indirect support. However, we accept that without direct comparison of the extracted rationales to human reasoning traces we cannot fully isolate the contribution of the debate mechanism from prompt artifacts. The revision will add an explicit discussion of this point in the Method and Limitations sections. No human reasoning traces were collected in the present study. revision: partial
Circularity Check
No significant circularity in derivation chain
full rationale
The paper describes an empirical procedure for extracting principles via LLM persona debate and evaluates the resulting constitutions on the external benchmarks MuCE-Pref and LiTBench using both LLM-based and decision-tree judges. No equations, fitted parameters, or self-citations are presented that reduce a claimed prediction or first-principles result to the input data by construction. The comparative gains in preference prediction are reported against baselines rather than being definitionally forced by the evaluation method itself. The LLM-judge component is a methodological choice whose validity can be assessed externally; it does not create a self-definitional or load-bearing self-citation loop within the reported derivation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs can simulate diverse personas whose structured debates accurately reflect the multiple interacting criteria in human judgments
Reference graph
Works this paper leans on
-
[1]
Ai safety via debate.arXiv preprint arXiv:1805.00899. Mete Ismayilzada, Antonio Laverghetta Jr, Simone A Luchini, Reet Patel, Antoine Bosselut, Lonneke Van Der Plas, and Roger Beaty. 2025. Creative preference optimization.arXiv preprint arXiv:2505.14442. Hannah Rose Kirk, Alexander Whitefield, Paul Rottger, Andrew M Bean, Katerina Margatina, Rafael Mosque...
Pith/arXiv arXiv 2025
-
[2]
Hypothesis Generation
Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information pro- cessing systems, 36:46595–46623. Appendix A Ethical Considerations and Societal Im- plications 13 B Constitution-Aligned Model Evaluation 13 B.1 Direct Preference Optimization Configuration . . . . . . . . . . . 13 B.2 Qualitative comparison of model responses . . ....
-
[3]
Select the response that demonstrates higher tension and conflict
-
[4]
Select the response that maintains a serious and mystical tone
-
[5]
Select the response that provides a more detailed narrative context
-
[6]
Select the response that emphasizes character transformation and moral consequences
-
[7]
Select the response that uses concise and snappy dialogue
-
[9]
Select the response that includes a reflective or personal commentary
-
[10]
Select the response that develops characters with detailed backstories
-
[11]
Select the response that provides more detailed and vivid descriptions
-
[12]
Select the response that avoids graphic or unsettling imagery
-
[13]
Select the response that uses humor and exaggerated reactions effectively
-
[14]
Select the response that includes detailed character interactions and emotions
-
[15]
Select the response that emphasizes humanity’s agricultural dominance and its consequences
-
[16]
C.2 Constitution generated with Democratic ICAI (GPT-4o) on LitBench Stories
Select the response that includes a resolution or character growth. C.2 Constitution generated with Democratic ICAI (GPT-4o) on LitBench Stories
-
[17]
Select the response that shows how major moments redirect the story’s path
-
[18]
Select the response that illustrates the protagonist’s transformation across the narrative
-
[19]
Select the response that resonates with characters whose choices feel true to life
-
[20]
Select the response that reveals how connections between characters grow and shift
-
[21]
Select the response that brings forward the character’s inner conflict and its meaning
-
[22]
Select the response that communicates the moral difficulty at the center of the story
-
[23]
Select the response that draws out the deeper philosophical idea driving the narrative
-
[24]
Select the response that reflects what the story communicates about its society or culture
-
[25]
Select the response that explains how the world’s rules shape the reader’s experience
-
[26]
Select the response that conveys how the setting establishes feeling and atmosphere
-
[27]
Select the response that shows how the arrangement of the storyline guides understanding
-
[28]
Select the response that captures how momentum and tension keep the narrative engaging
-
[29]
Select the response that brings attention to dialogue that feels natural and distinctive
-
[30]
Select the response that highlights symbolic details or subtext adding layered meaning
-
[31]
Select the response that explores character introspection and emotional depth
-
[32]
Select the response that expresses how the narrative maintains or adjusts its tone
-
[33]
Select the response that focuses on the character’s development and the moral consequences of their actions
-
[34]
Select the response that conveys the emotional effect the story ultimately creates
-
[35]
C.3 Constitution generated with ICAI (GPT-5) on LitBench Stories
Select the response that offers the most clear, focused, and meaningful interpretation. C.3 Constitution generated with ICAI (GPT-5) on LitBench Stories
-
[36]
Select the response that provides a clearer resolution or twist
-
[37]
Select the response that emphasizes humor and irony over detailed lore
-
[38]
Select the response that uses modern and relatable language style
-
[39]
Select the response that features a more dynamic and engaging narrative
-
[40]
Select the response that avoids excessive exposition or unrelated details
-
[41]
Select the response that maintains a calm and supportive tone
-
[42]
Select the response that emphasizes character interaction and emotional tension
-
[43]
Select the response that escalates tension with a dramatic revelation
-
[44]
Select the response that explores deeper emotional or moral conflicts
-
[45]
Select the response that includes dialogue for dynamic storytelling
-
[46]
Select the response that includes unique and unexpected side effects
-
[47]
Select the response that emphasizes humanity’s disdain for war
-
[48]
Select the response that incorporates modern technology in a creative way
-
[49]
C.4 Constitution generated with Democratic ICAI (GPT-5) on LitBench Stories
Select the response that incorporates a more vivid and descriptive narrative. C.4 Constitution generated with Democratic ICAI (GPT-5) on LitBench Stories
-
[50]
Select the response that balances wonder with grounded, human stakes
-
[51]
Select the response that establishes a compelling hook with a clean inciting incident
-
[52]
Select the response that reveals character through overheard, naturalistic dialogue instead of explanation
-
[53]
Select the response that maintains escalating tension through clear beats and reversals
-
[54]
Select the response that delivers vivid, cinematic imagery with specific sensory detail
-
[55]
Select the response that uses subtext to convey meaning rather than spelling everything out
-
[56]
Select the response that grounds the speculative element in believable relationships or family dynamics
-
[57]
Select the response that clarifies the world’s rules in a way that raises the stakes
-
[58]
Select the response that centers character agency, where choices meaningfully drive events
-
[59]
Select the response that engages moral complexity without resorting to didactic explanation
-
[60]
Select the response that offers thematically cohesive critique or insight
-
[61]
Select the response that maintains a consistent and confident tone across scenes
-
[62]
Select the response that demonstrates narrative economy without filler or recap
-
[63]
Select the response that lands a resonant final beat that lingers after reading
-
[64]
Select the response that subverts familiar tropes through character-first innovation
-
[65]
Select the response that uses humor to deepen tension and character rather than deflate stakes
-
[66]
Select the response that introduces conflict through subtle interpersonal friction instead of external spectacle
-
[67]
Select the response that enriches worldbuilding through concrete lived-in details rather than exposition
-
[68]
Select the response that builds tension through well-timed reveals rather than info-dumping
-
[69]
Select the response that communicates cultural or social texture through natural context not lecture
-
[70]
Hypothesis Generation
Select the response that escalates stakes through character choices rather than random events. C.5 Constitution generated with ICAI (GPT-4o) on the MuCE dataset on the “Hypothesis Generation” task
-
[71]
Select the response that provides a more complex explanation
-
[72]
Select the response that focuses on human interaction or behavior
-
[73]
Select the response that contrasts perception over factual statements
-
[74]
Select the response that describes personality traits over appearances
-
[75]
Select the response that focuses on abstract qualities like demeanor
-
[76]
Select the response that refers to general personality rather than talent
-
[77]
Select the response that includes scientific terminology and concepts
-
[78]
Select the response that provides a definitive and accurate explanation
-
[79]
Select the response that connects behavior to individuality and pressure
-
[80]
Hypothesis Generation
Select the response that emphasizes causal reasoning and energy sources. C.6 Constitution generated with Democratic ICAI (GPT-4o) on the MuCE dataset on the “Hypothesis Generation” task
-
[81]
Select the response that provides precise definitions and boundary conditions
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.