StructSplat: Generalizable 3D Gaussian Splatting from Uncalibrated Sparse Views
Pith reviewed 2026-06-29 03:56 UTC · model grok-4.3
The pith
StructSplat reconstructs 3D Gaussians from uncalibrated sparse views by assigning explicit roles to geometry, semantic and texture cues.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
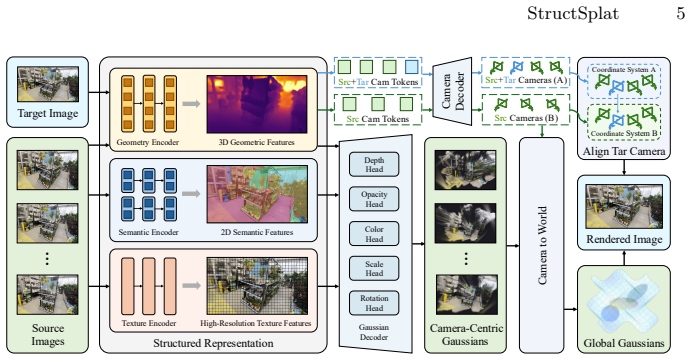
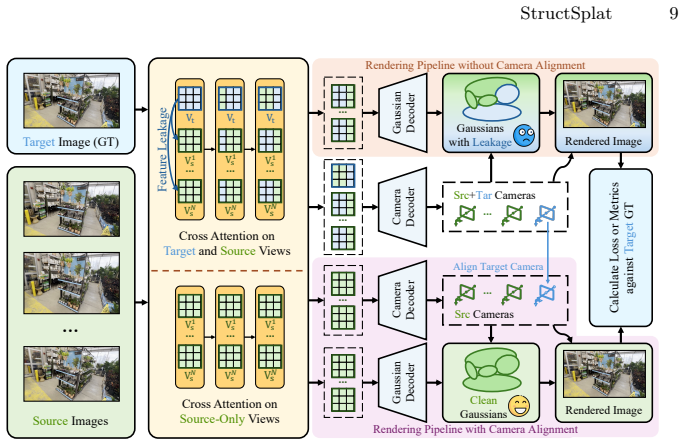
We present StructSplat, a feed-forward and generalizable 3D Gaussian reconstruction framework that operates directly on uncalibrated images without requiring camera parameters. Our key idea is to adopt a structured representation that organizes geometry, semantic, and texture cues with explicit roles in the reconstruction process. Specifically, we introduce a pixel-aligned feature injection mechanism to enable accurate texture modeling from 2D observations, incorporate semantic-aware priors to improve global consistency, and design a camera alignment strategy to prevent information leakage and improve generalization.
What carries the argument
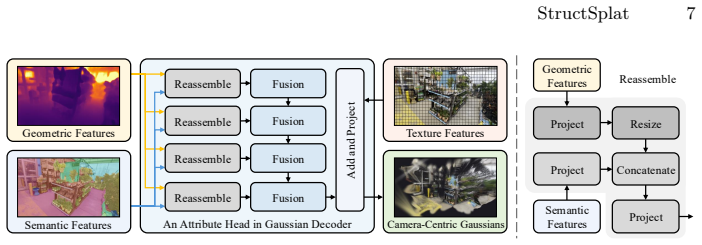
Structured representation that assigns explicit roles to geometry, semantic, and texture cues through pixel-aligned feature injection, semantic-aware priors, and a camera alignment strategy.
If this is right
- The method reaches 28.045 PSNR on DL3DV, exceeding AnySplat by 5.67 dB.
- Cross-dataset tests show gains of 1.94 dB on ACID and 1.72 dB on RealEstate10K over AnySplat.
- Reconstruction succeeds without input camera parameters or per-scene optimization.
- Explicit cue separation improves both fidelity and generalization compared with entangled backbones.
Where Pith is reading between the lines
- The same cue-separation pattern could be tested on other 3D representations such as NeRF variants.
- If the alignment strategy scales, casual multi-view capture on phones might become sufficient for high-quality 3D output.
- Limits may appear when scenes contain strong lighting changes or repetitive textures that weaken semantic priors.
Load-bearing premise
Separating geometry, semantic, and texture cues into explicit roles via pixel-aligned feature injection, semantic-aware priors, and a camera alignment strategy prevents information leakage and enables generalization from uncalibrated sparse views without per-scene optimization.
What would settle it
Performance on a held-out set of uncalibrated sparse-view scenes that falls below baselines using known camera poses would falsify the claim that the structured separation enables reliable generalization.
Figures







read the original abstract
We present StructSplat, a feed-forward and generalizable 3D Gaussian reconstruction framework that operates directly on uncalibrated images without requiring camera parameters. Existing methods either rely on per-scene optimization or assume known camera poses, and often entangle geometry and appearance within a unified backbone, limiting reconstruction fidelity and generalization. Our key idea is to adopt a structured representation that organizes geometry, semantic, and texture cues with explicit roles in the reconstruction process. Specifically, we introduce a pixel-aligned feature injection mechanism to enable accurate texture modeling from 2D observations, incorporate semantic-aware priors to improve global consistency, and design a camera alignment strategy to prevent information leakage and improve generalization. Experiments show that our method significantly outperforms prior approaches on challenging benchmarks. On DL3DV, our method achieves 28.045 PSNR, surpassing AnySplat (22.377) by +5.67 dB. In cross-dataset evaluation, our method achieves +1.94 dB over AnySplat on ACID and +1.72 dB on RealEstate10K. Project page: https://structsplat.github.io Code: https://github.com/J-C-Zhao/StructSplat
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces StructSplat, a feed-forward 3D Gaussian Splatting framework that reconstructs from uncalibrated sparse views without per-scene optimization or known camera poses. It organizes geometry, semantic, and texture cues via three mechanisms: pixel-aligned feature injection for texture modeling, semantic-aware priors for global consistency, and a camera alignment strategy to avoid information leakage. The central empirical claim is large performance gains, including 28.045 PSNR on DL3DV (+5.67 dB over AnySplat), +1.94 dB on ACID, and +1.72 dB on RealEstate10K in cross-dataset tests.
Significance. If the reported gains are supported by detailed ablations and analysis, the work would represent a meaningful step toward practical generalizable 3D reconstruction from casual image collections. The public release of code and project page is a clear strength that supports reproducibility and follow-on research.
major comments (2)
- [Experiments] Experiments section: The abstract reports specific PSNR deltas (e.g., +5.67 dB on DL3DV) but the provided source contains no ablation tables, variance across runs, or component-wise breakdowns isolating the contribution of pixel-aligned injection versus semantic priors versus the alignment module; without these, attribution of the gains to the structured representation remains unverified.
- [Method] Method section: The camera alignment strategy is described at a high level as preventing leakage, yet no equations, loss terms, or pseudocode detail how alignment is enforced during feature injection or how it interacts with the uncalibrated input assumption; this is load-bearing for the generalization claim.
minor comments (1)
- [Abstract] The abstract and introduction would benefit from a brief statement of the input resolution and number of views used in the reported benchmarks to allow direct comparison with prior feed-forward methods.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that the current version would benefit from expanded experimental analysis and methodological details. We will revise the manuscript to address both major comments.
read point-by-point responses
-
Referee: [Experiments] Experiments section: The abstract reports specific PSNR deltas (e.g., +5.67 dB on DL3DV) but the provided source contains no ablation tables, variance across runs, or component-wise breakdowns isolating the contribution of pixel-aligned injection versus semantic priors versus the alignment module; without these, attribution of the gains to the structured representation remains unverified.
Authors: We agree that the manuscript lacks the requested ablation studies and statistical details. In the revision we will add (i) a dedicated ablation table isolating the contribution of pixel-aligned feature injection, semantic-aware priors, and the camera alignment module, (ii) standard deviation across multiple random seeds for the reported PSNR values, and (iii) component-wise breakdowns on DL3DV, ACID, and RealEstate10K to substantiate attribution of the observed gains. revision: yes
-
Referee: [Method] Method section: The camera alignment strategy is described at a high level as preventing leakage, yet no equations, loss terms, or pseudocode detail how alignment is enforced during feature injection or how it interacts with the uncalibrated input assumption; this is load-bearing for the generalization claim.
Authors: We acknowledge that the camera alignment module is currently presented at a high level. In the revised manuscript we will expand Section 3 with the explicit formulation (including the alignment loss term and its weighting), the precise interaction between the alignment module and the pixel-aligned feature injection pathway, and pseudocode that shows how alignment is maintained under the uncalibrated-input assumption. revision: yes
Circularity Check
No significant circularity detected
full rationale
The abstract and available description present a high-level architectural description (pixel-aligned feature injection, semantic-aware priors, camera alignment) and empirical benchmark results without any equations, parameter-fitting steps, self-citations, or derivation chains. No load-bearing claim reduces to a fitted input, self-definition, or author-prior ansatz by construction. The reported PSNR gains are presented as experimental outcomes rather than derived predictions, leaving the method self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: ICCV
Barron, J.T., Mildenhall, B., Tancik, M., Hedman, P., Martin-Brualla, R., Srini- vasan, P.P.: Mip-nerf: A multiscale representation for anti-aliasing neural radiance fields. In: ICCV. pp. 5855–5864 (2021)
2021
-
[2]
In: ICCV
Barron, J.T., Mildenhall, B., Verbin, D., Srinivasan, P.P., Hedman, P.: Zip-nerf: Anti-aliased grid-based neural radiance fields. In: ICCV. pp. 19697–19705 (2023)
2023
-
[3]
In: CVPR
Bian, W., Wang, Z., Li, K., Bian, J.W.: NoPe-NeRF: Optimising neural radiance field with no pose prior. In: CVPR. pp. 4160–4169 (2023)
2023
-
[4]
In: CVPR
Bourigault, E., Bourigault, P.: MVDiff: Scalable and flexible multi-view diffusion for 3d object reconstruction from single-view. In: CVPR. pp. 7579–7586 (2024)
2024
-
[5]
In: CVPR
Charatan, D., Li, S.L., Tagliasacchi, A., Sitzmann, V.: PixelSplat: 3d gaussian splats from image pairs for scalable generalizable 3d reconstruction. In: CVPR. pp. 19457–19467 (2024)
2024
-
[6]
In: ICCV
Chen, A., Xu, Z., Zhao, F., Zhang, X., Xiang, F., Yu, J., Su, H.: MVSNerf: Fast generalizable radiance field reconstruction from multi-view stereo. In: ICCV. pp. 14124–14133 (2021)
2021
-
[7]
In: ECCV
Chen, S., Li, X., Wang, Z., Prisacariu, V.A.: DFNet: Enhance absolute pose re- gression with direct feature matching. In: ECCV. pp. 1–17 (2022)
2022
-
[8]
In: ECCV
Chen, Y., Xu, H., Zheng, C., Zhuang, B., Pollefeys, M., Geiger, A., Cham, T.J., Cai, J.: MVSplat: Efficient 3d gaussian splatting from sparse multi-view images. In: ECCV. pp. 370–386 (2024)
2024
-
[9]
arXiv preprint arXiv:2010.11929 (2020)
Dosovitskiy, A., Beyer, L., Kolesnikov, A., et al.: An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929 (2020)
Pith/arXiv arXiv 2010
-
[10]
In: ECCV
Fang,G.,Wang,B.:Mini-splatting:Representingsceneswithaconstrainednumber of gaussians. In: ECCV. pp. 165–181. Springer (2024) 16 J.-C. Zhao et al
2024
-
[11]
In: CVPR
Fu, Y., Wang, X., Liu, S., Kulkarni, A., Kautz, J., Efros, A.A.: COLMAP-free 3d gaussian splatting. In: CVPR. pp. 20796–20805 (2024)
2024
-
[12]
In: CVPR
He, Y., Yan, R., Fragkiadaki, K., Yu, S.I.: Epipolar transformers. In: CVPR. pp. 7776–7785 (2020)
2020
-
[13]
In: ICML (2025)
Hong, S., Jung, J., Shin, H., Han, J., Yang, J., Luo, C., Kim, S.: PF3plat: Pose-free feed-forward 3d gaussian splatting for novel view synthesis. In: ICML (2025)
2025
-
[14]
In: CVPR
Hong, S., Jung, J., Shin, H., Yang, J., Kim, S., Luo, C.: Unifying correspondence, pose and nerf for generalized pose-free novel view synthesis. In: CVPR. pp. 20196– 20206 (2024)
2024
-
[15]
In: ICLR (2024)
Hong, Y., Zhang, K., Gu, J., Bi, S., Zhou, Y., Liu, D., Liu, F., Sunkavalli, K., Bui, T., Tan, H.: LRM: Large reconstruction model for single image to 3d. In: ICLR (2024)
2024
-
[16]
arXiv preprint arXiv:2404.06395 (2024)
Hu, S., Tu, Y., Han, X., et al.: Minicpm: Unveiling the potential of small language models with scalable training strategies. arXiv preprint arXiv:2404.06395 (2024)
Pith/arXiv arXiv 2024
-
[17]
In: ICCV
Jia,H.,Zhu,L.,Zhao,N.:H3R:Hybridmulti-viewcorrespondenceforgeneralizable 3d reconstruction. In: ICCV. pp. 7655–7665 (2025)
2025
-
[18]
In: ICCV
Jiang, H., Tan, H., Wang, P., et al.: Rayzer: A self-supervised large view synthesis model. In: ICCV. pp. 4918–4929 (2025)
2025
-
[19]
arXiv preprint arXiv:2505.23716 (2025)
Jiang, L., Mao, Y., Xu, L., Lu, T., Ren, K., Jin, Y., Xu, X., Yu, M., Pang, J., Zhao, F., et al.: AnySplat: Feed-forward 3d gaussian splatting from unconstrained views. arXiv preprint arXiv:2505.23716 (2025)
arXiv 2025
-
[20]
In: ICLR
Jin, H., Jiang, H., Tan, H., Zhang, K., Bi, S., Zhang, T., Luan, F., Snavely, N., Xu, Z.: LVSM: A large view synthesis model with minimal 3d inductive bias. In: ICLR. vol. 2025, pp. 60001–60021 (2025)
2025
-
[21]
In: CVPR
Johari, M.M., Lepoittevin, Y., Fleuret, F.: Geonerf: Generalizing nerf with geom- etry priors. In: CVPR. pp. 18365–18375 (2022)
2022
-
[22]
arXiv preprint arXiv:1905.12322 (2019)
Kalamkar, D., Mudigere, D., Mellempudi, N., Das, D., Banerjee, K., Avancha, S., Vooturi, D.T., Jammalamadaka, N., Huang, J., Yuen, H., et al.: A study of bfloat16 for deep learning training. arXiv preprint arXiv:1905.12322 (2019)
Pith/arXiv arXiv 1905
-
[23]
In: CVPR
Kang, G., Yoo, J., Park, J., Nam, S., Im, H., Shin, S., Kim, S., Park, E.: Selfsplat: Pose-free and 3d prior-free generalizable 3d gaussian splatting. In: CVPR. pp. 22012–22022 (2025)
2025
-
[24]
ACM Trans
Kerbl, B., Kopanas, G., Leimkühler, T., Drettakis, G.: 3d gaussian splatting for real-time radiance field rendering. ACM Trans. Graph.42(4), 139–1 (2023)
2023
-
[25]
In: ECCV
Leroy, V., Cabon, Y., Revaud, J.: Grounding image matching in 3d with mast3r. In: ECCV. pp. 71–91 (2024)
2024
-
[26]
ICLR (2024)
Li, J., Tan, H., Zhang, K., Xu, Z., Luan, F., Xu, Y., Hong, Y., Sunkavalli, K., Shakhnarovich, G., Bi, S.: Instant3d: Fast text-to-3d with sparse-view generation and large reconstruction model. ICLR (2024)
2024
-
[27]
arXiv preprint arXiv:2511.10647 (2025)
Lin, H., Chen, S., Liew, J., Chen, D.Y., Li, Z., Shi, G., Feng, J., Kang, B.: Depth anything 3: Recovering the visual space from any views. arXiv preprint arXiv:2511.10647 (2025)
Pith/arXiv arXiv 2025
-
[28]
In: CVPR
Ling, L., Sheng, Y., Tu, Z., Zhao, W., Xin, C., Wan, K., Yu, L., Guo, Q., Yu, Z., Lu, Y., et al.: Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vision. In: CVPR. pp. 22160–22169 (2024)
2024
-
[29]
In: ICCV
Liu, A., Tucker, R., Jampani, V., Makadia, A., Snavely, N., Kanazawa, A.: Infinite nature: Perpetual view generation of natural scenes from a single image. In: ICCV. pp. 14458–14467 (2021)
2021
-
[30]
In: ECCV
Liu, T., Wang, G., Hu, S., Shen, L., Ye, X., Zang, Y., Cao, Z., Li, W., Liu, Z.: MVSGaussian: Fast generalizable gaussian splatting reconstruction from multi- view stereo. In: ECCV. pp. 37–53 (2024) StructSplat 17
2024
-
[31]
Mildenhall, B., Srinivasan, P.P., Tancik, M., Barron, J.T., Ramamoorthi, R., Ng, R.: Nerf: Representing scenes as neural radiance fields for view synthesis. Commun. ACM65(1), 99–106 (2021)
2021
-
[32]
In: ECCV
Pan, L., Baráth, D., Pollefeys, M., Schönberger, J.L.: Global structure-from-motion revisited. In: ECCV. pp. 58–77 (2024)
2024
-
[33]
Rajbhandari, S., Rasley, J., Ruwase, O., He, Y.: Zero: Memory optimizations to- ward training trillion parameter models. In: Int. Conf. High Perform. Comput. Netw. Storage Anal. pp. 1–16 (2020)
2020
-
[34]
Rajbhandari, S., Ruwase, O., Rasley, J., Smith, S., He, Y.: Zero-infinity: Breaking the gpu memory wall for extreme scale deep learning. In: Int. Conf. High Perform. Comput. Netw. Storage Anal. pp. 1–14 (2021)
2021
-
[35]
In: ICCV
Ranftl, R., Bochkovskiy, A., Koltun, V.: Vision transformers for dense prediction. In: ICCV. pp. 12179–12188 (2021)
2021
-
[36]
In: USENIX Annu
Ren, J., Rajbhandari, S., Aminabadi, R.Y., Ruwase, O., Yang, S., Zhang, M., Li, D., He, Y.: Zero-offload: Democratizing billion-scale model training. In: USENIX Annu. Tech. Conf. pp. 551–564 (2021)
2021
-
[37]
In: CVPR
Schönberger, J.L., Frahm, J.M.: Structure-from-motion revisited. In: CVPR. pp. 4104–4113 (2016)
2016
-
[38]
In: ICCV
Sheng, Y., Deng, J., Zhang, X., Zhang, Y., Hua, B., Zhang, Y., Ji, J.: Spatialsplat: Efficient semantic 3d from sparse unposed images. In: ICCV. pp. 26404–26414 (2025)
2025
-
[39]
arXiv preprint arXiv:2508.10104 (2025)
Siméoni, O., Vo, H.V., Seitzer, M., Baldassarre, F., Oquab, M., et al.: Dinov3. arXiv preprint arXiv:2508.10104 (2025)
Pith/arXiv arXiv 2025
-
[40]
arXiv preprint arXiv:2408.13912 (2024)
Smart, B., Zheng, C., Laina, I., Prisacariu, V.A.: Splatt3r: Zero-shot gaussian splatting from uncalibrated image pairs. arXiv preprint arXiv:2408.13912 (2024)
Pith/arXiv arXiv 2024
-
[41]
In: ECCV
Suhail, M., Esteves, C., Sigal, L., Makadia, A.: Generalizable patch-based neural rendering. In: ECCV. pp. 156–174 (2022)
2022
-
[42]
In: CVPR
Sun, X., Jiang, H., Liu, L., et al.: Uni3r: Unified 3d reconstruction and semantic un- derstanding via generalizable gaussian splatting from unposed multi-view images. In: CVPR. pp. 33280–33290 (2026)
2026
-
[43]
In: ECCV
Tang, J., Chen, Z., Chen, X., Wang, T., Zeng, G., Liu, Z.: Lgm: Large multi-view gaussian model for high-resolution 3d content creation. In: ECCV. pp. 1–18 (2024)
2024
-
[44]
In: ICCV
Wang, G., Chen, Z., Loy, C.C., Liu, Z.: Sparsenerf: Distilling depth ranking for few-shot novel view synthesis. In: ICCV. pp. 9065–9076 (2023)
2023
-
[45]
In: CVPR
Wang, J., Chen, M., Karaev, N., Vedaldi, A., Rupprecht, C., Novotny, D.: VGGT: Visual geometry grounded transformer. In: CVPR. pp. 5294–5306 (2025)
2025
-
[46]
In: CVPR
Wang, J., Karaev, N., Rupprecht, C., Novotny, D.: VGGSfM: Visual geometry grounded deep structure from motion. In: CVPR. pp. 21686–21697 (2024)
2024
-
[47]
ICLR (2024)
Wang, P., Tan, H., Bi, S., Xu, Y., Luan, F., Sunkavalli, K., Wang, W., Xu, Z., Zhang, K.: Pf-lrm: Pose-free large reconstruction model for joint pose and shape prediction. ICLR (2024)
2024
-
[48]
IEEE TIP13(4), 600–612 (2004)
Wang, Z., Bovik, A.C., Sheikh, H.R., Simoncelli, E.P.: Image quality assessment: from error visibility to structural similarity. IEEE TIP13(4), 600–612 (2004)
2004
-
[49]
arXiv preprint arXiv:2102.07064 (2022)
Wang, Z., Wu, S., Xie, W., Chen, M., Prisacariu, V.A.: NeRF–: Neural radiance fields without known camera parameters. arXiv preprint arXiv:2102.07064 (2022)
arXiv 2022
-
[50]
In: ICCV
Xu, G., Yin, W., Chen, H., Shen, C., Cheng, K., Zhao, F.: FrozenRecon: Pose-free 3d scene reconstruction with frozen depth models. In: ICCV. pp. 9276–9286 (2023)
2023
-
[51]
Zhao et al
Xu, H., Peng, S., Wang, F., Blum, H., Barath, D., Geiger, A., Pollefeys, M.: Depth- Splat:Connectinggaussiansplattinganddepth.In:CVPR.pp.16453–16463(2025) 18 J.-C. Zhao et al
2025
-
[52]
In: AAAI
Yan, Q., Wang, Q., Zhao, K., Chen, J., Li, B., Chu, X., Deng, F.: CF-NeRF: Camera parameter free neural radiance fields with incremental learning. In: AAAI. vol. 38, pp. 6440–6448 (2024)
2024
-
[53]
arXiv preprint arXiv:2410.24207 (2024)
Ye, B., Liu, S., Xu, H., Li, X., Pollefeys, M., Yang, M.H., Peng, S.: No pose, no problem: Surprisingly simple 3d gaussian splats from sparse unposed images. arXiv preprint arXiv:2410.24207 (2024)
arXiv 2024
-
[54]
In: IROS
Yen-Chen,L.,Florence,P.,Barron,J.T.,Rodriguez,A.,Isola,P.,Lin,T.Y.:iNeRF: Inverting neural radiance fields for pose estimation. In: IROS. pp. 1323–1330 (2021)
2021
-
[55]
In: CVPR
Yu, Z., Chen, A., Huang, B., Sattler, T., Geiger, A.: Mip-splatting: Alias-free 3d gaussian splatting. In: CVPR. pp. 19447–19456 (2024)
2024
-
[56]
In: ECCV
Zhang, K., Bi, S., Tan, H., Xiangli, Y., Zhao, N., Sunkavalli, K., Xu, Z.: GS-LRM: Large reconstruction model for 3d gaussian splatting. In: ECCV. pp. 1–19 (2024)
2024
-
[57]
In: CVPR
Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O.: The unreasonable effectiveness of deep features as a perceptual metric. In: CVPR. pp. 586–595 (2018)
2018
-
[58]
In: CVPR
Zhang, S., Wang, J., Xu, Y., Xue, N., Rupprecht, C., Zhou, X., Shen, Y., Wet- zstein, G.: Flare: Feed-forward geometry, appearance and camera estimation from uncalibrated sparse views. In: CVPR. pp. 21936–21947 (2025)
2025
-
[59]
In: IROS
Zhang, Z., Scaramuzza, D.: A tutorial on quantitative trajectory evaluation for visual (-inertial) odometry. In: IROS. pp. 7244–7251 (2018)
2018
-
[60]
Zhou, T., Tucker, R., Flynn, J., Fyffe, G., Snavely, N.: Stereo magnification: Learn- ingviewsynthesisusingmultiplaneimages.arXivpreprintarXiv:1805.09817(2018)
Pith/arXiv arXiv 2018
-
[61]
Ziwen, C., Tan, H., Zhang, K., Bi, S., Luan, F., Hong, Y., Fuxin, L., Xu, Z.: Long- LRM: Long-sequence large reconstruction model for wide-coverage gaussian splats. In: ICCV. pp. 4349–4359 (2025) StructSplat 19 A Implementation and Architecture Details Gaussian Activations.As summarized in Table 7, the output activations of different attribute heads in th...
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.