Intent-Driven 6G Service Orchestration: Grounded Translation, Validation, and Decomposition
Pith reviewed 2026-06-30 11:34 UTC · model grok-4.3
The pith
Grounding LLM intent translation in service catalogs plus formal validation and decomposition delivers 97 percent success for 6G orchestration.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Coupling LLM translation with grounding in a semantic service catalog that exposes TMF-compliant specifications, followed by SHACL validation against the TMF Intent Ontology and constraint-driven decomposition into CFSS and RFSS profiles, produces reliable intent orchestration that rejects infeasible requests at 100 percent and reduces hallucinations by 26 points compared with ungrounded baselines.
What carries the argument
The three-layer agentic workflow that first grounds translation in catalog metadata, then validates RDF structure with SHACL, then selects and covers profiles via constraint satisfaction and weighted set cover.
If this is right
- Production 6G intent automation becomes feasible without manual low-level configuration.
- Adversarial hallucinations drop substantially once catalog metadata anchors the LLM context.
- Infeasible requests are rejected correctly regardless of model size or prompt style.
- The same workflow structure applies across multiple GPT-4.1/5 model variants.
- Decomposition reliably maps high-level QoS envelopes to infrastructure profiles.
Where Pith is reading between the lines
- The approach could be tested in live network testbeds to measure end-to-end latency and resource usage beyond benchmark runs.
- Similar grounding-plus-validation layers might transfer to intent orchestration in cloud or edge computing domains that already use catalog-style metadata.
- If catalog gaps are detected automatically, the workflow could trigger catalog updates as a side effect of validation failures.
Load-bearing premise
The semantic service catalog and TMF Intent Ontology are assumed to be complete, up-to-date, and accurate representations of all relevant capabilities and constraints.
What would settle it
Measure hallucination and validation failure rates when the same workflow is run against a deliberately incomplete or stale version of the service catalog.
Figures



read the original abstract
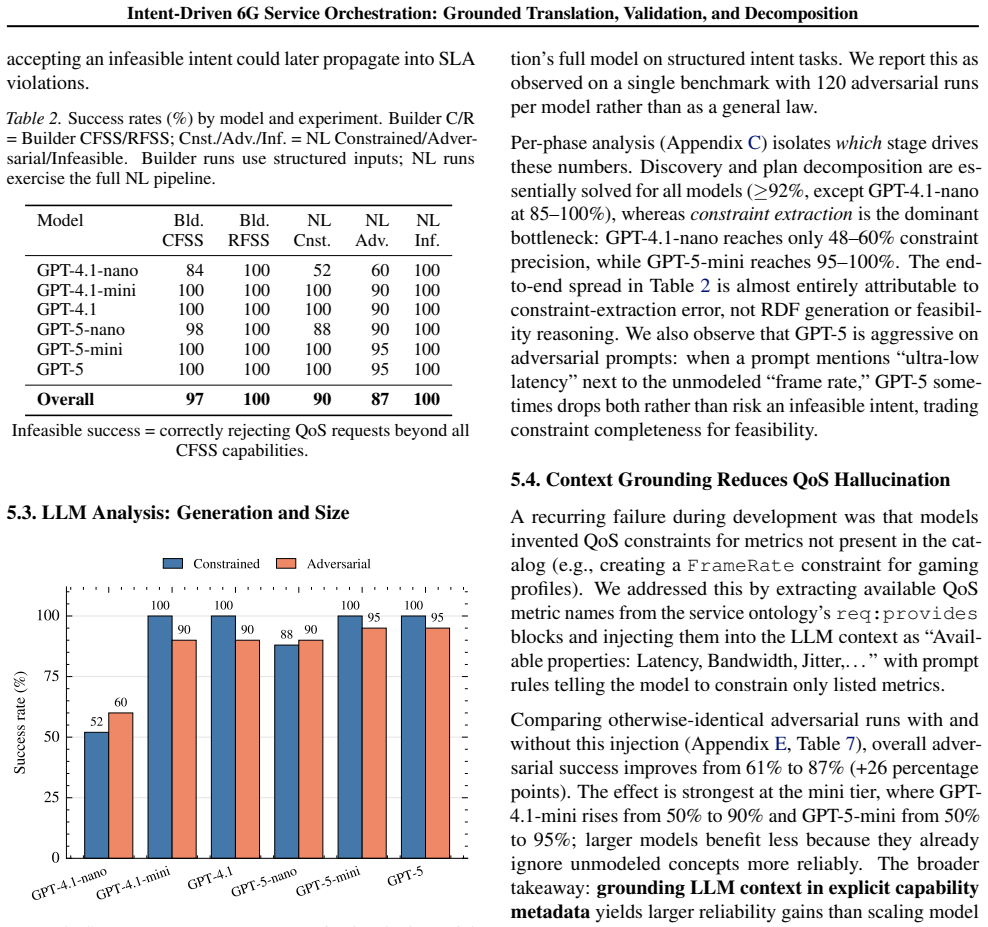
Intent-based automation for 6G envisions networks steered by high-level goals rather than low-level configurations. Existing LLM-based approaches translate natural language into plausible intent representations but typically omit what production deployment requires: grounding in actual service catalogs, formal validation, and cross-layer decomposition. We address this with an agentic workflow comprising three coupled reasoning layers: (i) grounding the translation in a semantic service catalog that exposes TMF compliant service specifications; (ii) validation of the RDF intent via SHACL structural checking against the TMF Intent Ontology; and (iii) decomposition that selects a CFSS profile via constraint satisfaction over QoS capability envelopes, then covers its infrastructure requirements with RFSS profiles via weighted set cover. Across 930 benchmark runs over six GPT-4.1/5 models, the workflow achieves 97% success in structured mode and 90% on average across natural-language scenarios, with 100% correct rejection of infeasible requests. Grounding LLM context in catalog capability metadata reduces adversarial hallucinations by 26 percentage points; larger gains than scaling model size alone.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an agentic workflow for intent-driven 6G service orchestration with three coupled layers: (i) grounding LLM intent translation in a TMF-compliant semantic service catalog, (ii) SHACL validation of the RDF intent against the TMF Intent Ontology, and (iii) decomposition selecting CFSS profiles via constraint satisfaction over QoS envelopes followed by RFSS coverage via weighted set cover. Across 930 benchmark runs on six GPT-4.1/5 models, it claims 97% success in structured mode, 90% average on natural-language scenarios, 100% correct rejection of infeasible requests, and a 26 percentage-point reduction in adversarial hallucinations attributable to catalog grounding.
Significance. If the empirical claims hold after verification of catalog completeness, the work would be significant for 6G networking by demonstrating a practical, production-oriented pipeline that combines LLM translation with formal grounding and validation to reduce hallucinations and ensure feasibility—addressing gaps left by prior LLM-only intent approaches. The large-scale benchmark (930 runs) and explicit decomposition mechanics provide a concrete basis for further development in intent-based automation.
major comments (2)
- [Evaluation section (benchmark results paragraph)] Evaluation section (benchmark results paragraph): the reported 97% structured success, 90% NL average, 26pp hallucination reduction, and 100% infeasible rejection across 930 runs provide no per-scenario breakdowns, error bars, or explicit baseline comparisons (with vs. without grounding) on the same prompts; without these, it is impossible to isolate the contribution of the grounding layer from catalog alignment with the test cases.
- [Method section (grounding and validation layers)] Method section (grounding and validation layers): the semantic service catalog and TMF Intent Ontology are assumed complete and up-to-date with no coverage audit, gap analysis versus 3GPP/TMF releases, or sensitivity experiments described; if relevant QoS envelopes, RFSS profiles, or constraint combinations are missing, both the grounding benefit and SHACL validation become circular (in-catalog cases succeed by construction while out-of-catalog cases are never tested), directly undermining the claim that grounding itself drives the measured gains.
minor comments (2)
- [Abstract] Abstract: 'GPT-4.1/5 models' is unclear; specify the exact model versions (e.g., GPT-4o, GPT-4-turbo) used in the 930 runs.
- [Evaluation section] The paper does not state whether the benchmark prompts or adversarial examples are released, which would aid reproducibility of the hallucination-reduction result.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting needs for greater evaluation granularity and methodological transparency. We address each major comment below and will revise the manuscript to incorporate additional details where feasible.
read point-by-point responses
-
Referee: Evaluation section (benchmark results paragraph): the reported 97% structured success, 90% NL average, 26pp hallucination reduction, and 100% infeasible rejection across 930 runs provide no per-scenario breakdowns, error bars, or explicit baseline comparisons (with vs. without grounding) on the same prompts; without these, it is impossible to isolate the contribution of the grounding layer from catalog alignment with the test cases.
Authors: We agree that the current presentation lacks the granularity needed to fully isolate the grounding layer's contribution. In revision we will expand the Evaluation section with per-scenario success breakdowns, standard-deviation error bars across the 930 runs, and explicit ablation results comparing identical prompts with and without catalog grounding. These additions will be presented in new tables and text. revision: yes
-
Referee: Method section (grounding and validation layers): the semantic service catalog and TMF Intent Ontology are assumed complete and up-to-date with no coverage audit, gap analysis versus 3GPP/TMF releases, or sensitivity experiments described; if relevant QoS envelopes, RFSS profiles, or constraint combinations are missing, both the grounding benefit and SHACL validation become circular (in-catalog cases succeed by construction while out-of-catalog cases are never tested), directly undermining the claim that grounding itself drives the measured gains.
Authors: We acknowledge the absence of an explicit coverage audit or gap analysis in the submitted manuscript. We will revise the Method section to document catalog construction from TMF releases, report coverage for the benchmark scenarios, and include sensitivity experiments on QoS envelope and profile availability. While the 100% infeasible-request rejection rate provides supporting evidence that out-of-catalog cases are handled, we will clarify the tested scope to address the circularity concern. revision: partial
Circularity Check
No circularity: empirical results from external benchmarks
full rationale
The paper reports success rates (97% structured, 90% NL average) and hallucination reduction (26pp) from 930 benchmark runs on fixed GPT models and TMF catalogs. These are direct empirical measurements against external artifacts, not quantities derived by the paper's equations or self-citations that reduce to fitted inputs by construction. No load-bearing self-citation chains, ansatzes, or self-definitional steps appear in the described workflow or results. The catalog-completeness assumption affects validity but does not create circularity in the reported derivation or evaluation chain.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption TMF service specifications and Intent Ontology provide a complete and accurate model of 6G service capabilities.
- domain assumption Constraint satisfaction over QoS envelopes and weighted set cover produce feasible infrastructure mappings.
Reference graph
Works this paper leans on
-
[1]
SWIFT: Semantic web intent framework for intent translation
Alcock, P., Anand, R., Rotsos, C., and Race, N. SWIFT: Semantic web intent framework for intent translation. In 2025 IEEE/IFIP Network Operations and Manage- ment Symposium (NOMS). IEEE,
2025
-
[2]
doi: 10.1109/ NOMS57970.2025.11073618. Boutouchent, A., Mekrache, A., Ksentini, A., Ad- hane, G., Fonseca, J., McNamara, J., Ramantas, K., Palena, M., Iordache, M., Lo Cigno, R., Mostafa, S., Roy, S., and Verikoukis, C. 6G-INTENSE: Intent-driven native AI architecture supporting network- compute abstraction and sensing at the deep edge. 6 Intent-Driven 6G...
-
[3]
Brenes, J., Piscione, P., Kolobov, M., and Ferrigno, G
Preprint: https://6g-intense.eu/wp-content/ uploads/2025/01/Intense_VTM.pdf. Brenes, J., Piscione, P., Kolobov, M., and Ferrigno, G. Uni- fied intent-based management across standards: Archi- tecture and prototype realizations. In 2025 IEEE Confer- ence on Standards for Communications and Networking (CSCN). IEEE,
2025
-
[4]
doi: 10.1109/CSCN67557.2025. 11230699. Clemm, J., Ciavaglia, L., Granville, L., and Tantsura, J. RFC 9315: Intent-Based Networking - Concepts and Definitions. Rfc, IETF,
-
[5]
Ficzere, D., Holl´osi, G., and Varga, P
URL V1.1.1. Ficzere, D., Holl´osi, G., and Varga, P. Beyond intent transla- tion: Research gaps in the application of generative AI for intent-based networking. In 2025 IEEE Network Opera- tions and Management Symposium (NOMS) Workshops — Workshop on Generative AI in Network Management (GAIN). IEEE,
2025
-
[6]
doi: 10.1109/NOMS57970.2025. 11073701. Guo, L., Zhang, L., Wang, J., Wu, J., Yan, Y ., Sun, H., He, B., Qi, Q., and Liao, J. Intent-based autonomous net- work framework guided by large language model. IEEE Transactions on Automation Science and Engineering, 22: 22185–22197,
-
[7]
doi: 10.1109/TASE.2025.3610906. Jacobs, A. S., Pfitscher, R. J., Ribeiro, R. H., Granville, L. Z., Ferreira, R. A., Willinger, W., and Rao, S. G. Establishing trust for using natural language for intent- based networking. IEEE Transactions on Network and Service Management , 22(5):4775–4787,
-
[8]
Kapoor, S., Gurbilek, G., Parra-Ullauri, J., Jangra, P
doi: 10.1109/TNSM.2025.3574626. Kapoor, S., Gurbilek, G., Parra-Ullauri, J., Jangra, P. K., Khan, T. A., Duke, A., Hey, A., McHugh, D., and Corston-Petrie, A. GenAI-powered intent-based au- tonomous networks: Standardisation landscape and emerging industry trends. TechRxiv,
- [9]
-
[10]
TIO-SHACL: Comprehensive SHACL validation for TMF Intent Ontologies
URL https://arxiv.org/abs/2604.27359. Open- source implementation: https://github.com/ EricssonResearch/tio-shacl. Mehmood, K., Kralevska, K., and Palma, D. Knowledge- based intent modeling for next generation cellular net- works. In IEEE International Mediterranean Conference on Communications and Networking (MeditCom). IEEE,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Evolving Service Management Toward Intent-Driven Autonomous Networks
Niem¨oller, J., M¨uller, E., Maggiari, M., and Maghsoudlou, K. Evolving Service Management Toward Intent-Driven Autonomous Networks. Ericsson Technology Review, 2024(3):2–7,
2024
-
[12]
Tageldien, M., Selim, B., and Sboui, L
doi: 10.23919/ETR.2024.10759715. Tageldien, M., Selim, B., and Sboui, L. Large language mod- els in intent-based networking: A comprehensive survey across the intent lifecycle. In 2025 International Telecom- munications Conference (ITC-Egypt). IEEE,
-
[13]
doi: 10.1109/ITC-EGYPT66095.2025.11186656. TM Forum. IG1253: Intent in Autonomous Networks. Introductory guide, TM Forum,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.