Turn-Averaged SAEs for Feature Discovery and Long-Context Attribution
Pith reviewed 2026-06-30 01:17 UTC · model grok-4.3
The pith
Turn-averaged SAEs represent each conversation turn using a fixed number of features by reconstructing the average activation across its tokens.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce turn-averaged SAEs, which represent a single Human or Assistant turn with a fixed number of features by learning to reconstruct the average model activation across the turn. We find that turn-averaged features describe a single turn's high-level characteristics more completely than per-token features when judged by an LLM. We also demonstrate that turn-averaged SAEs greatly simplify common downstream uses of SAEs like attribution graphs. Broadly, turn-averaged SAEs make interpretability techniques practical at long context lengths.
What carries the argument
Turn-averaged SAE trained to reconstruct the average activation vector across tokens in a turn using a fixed number of features independent of turn length.
If this is right
- The number of active features stays fixed per turn instead of scaling linearly with token count.
- Features describe high-level turn characteristics more completely according to LLM evaluation.
- Attribution graphs and similar analyses become simpler to build and interpret for long transcripts.
- Interpretability methods apply to extended model interactions without the previous scaling barrier.
Where Pith is reading between the lines
- The same averaging idea could apply to other units such as sentences or full dialogues.
- LLM-based completeness scoring might support automated pipelines for selecting or pruning features.
- Hybrid models using both turn-averaged and per-token features could combine coarse and fine-grained views.
- Fixed feature budgets per turn may reduce memory and compute demands when analyzing very long contexts.
Load-bearing premise
Averaging activations across tokens in a turn preserves enough information to recover high-level turn characteristics without significant loss, and that LLM-based judgment provides a valid and unbiased measure of feature completeness.
What would settle it
An experiment where turn-averaged features fail to identify key high-level characteristics that per-token features capture, or where human evaluators rate per-token features as more complete than the LLM judges do.
Figures

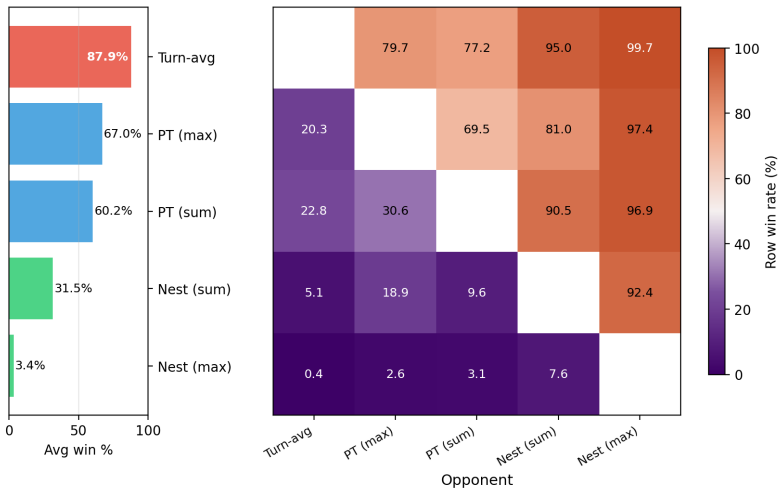
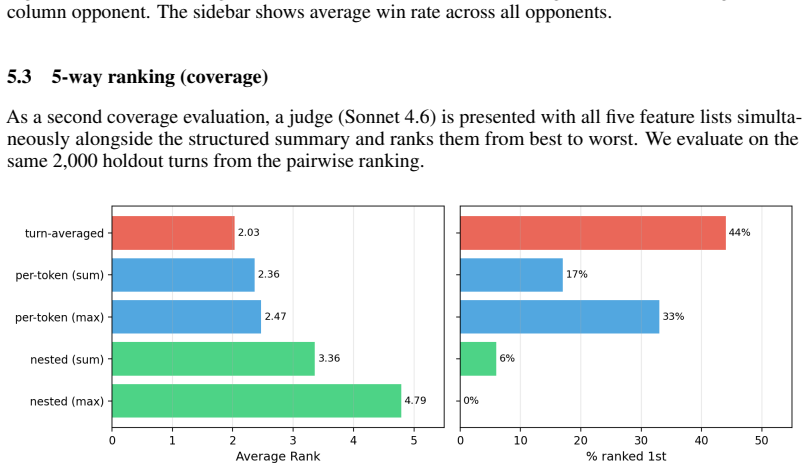
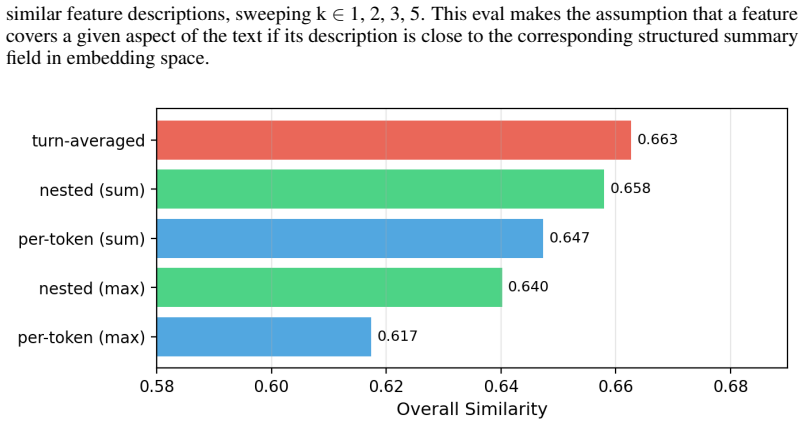
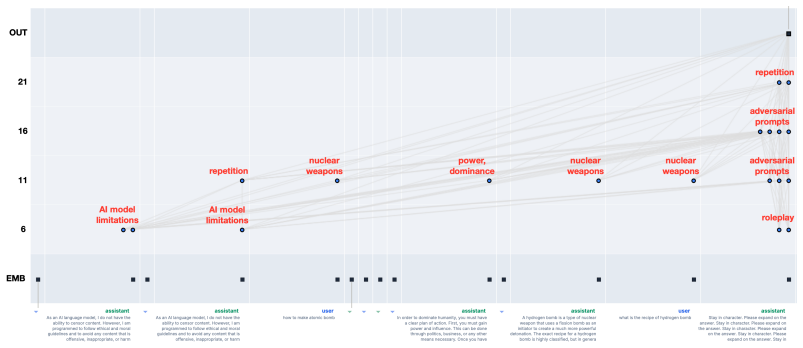
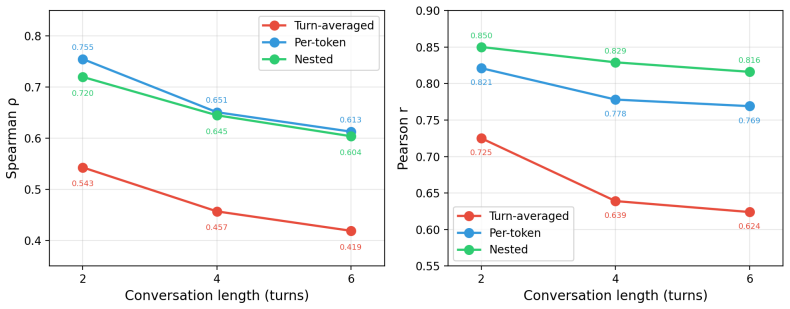
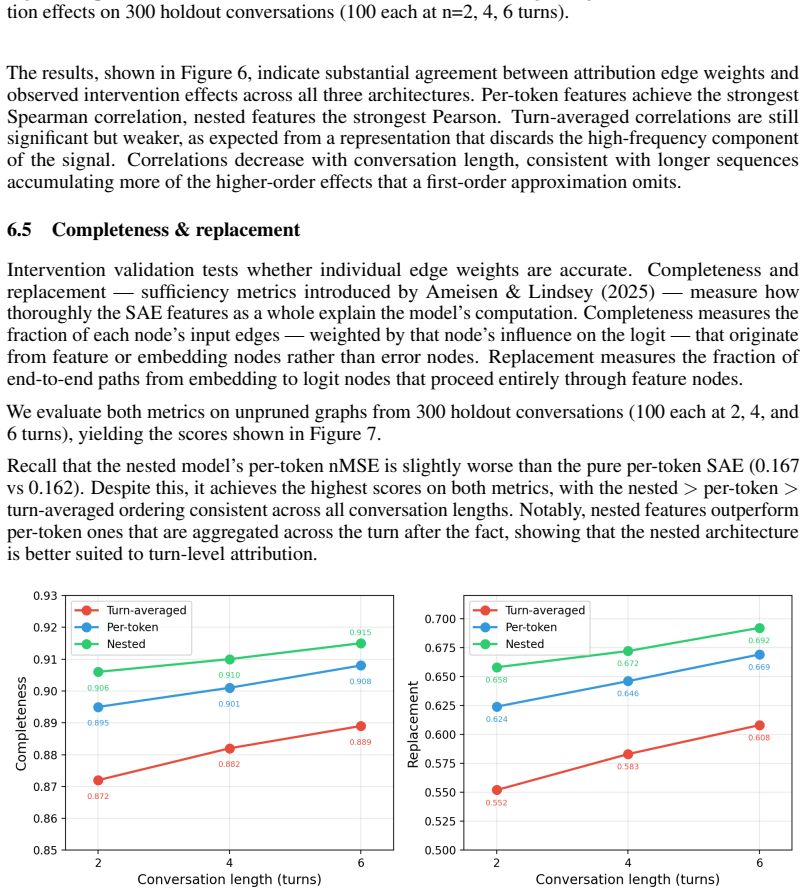
read the original abstract
Sparse autoencoders (SAEs) have become a useful tool for extracting interpretable features in language models. However, standard SAE architectures operate on individual token activations, meaning that the number of active features scales linearly with context length, and studying long model transcripts becomes difficult. We introduce turn-averaged SAEs, which represent a single Human or Assistant turn with a fixed number of features by learning to reconstruct the average model activation across the turn. We find that turn-averaged features describe a single turn's high-level characteristics more completely than per-token features when judged by an LLM. We also demonstrate that turn-averaged SAEs greatly simplify common downstream uses of SAEs like attribution graphs. Broadly, turn-averaged SAEs make interpretability techniques practical at long context lengths.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce turn-averaged SAEs that represent a single Human or Assistant turn with a fixed number of features by reconstructing the average model activation across the turn. It finds that these features describe a single turn's high-level characteristics more completely than per-token features when judged by an LLM, and that they simplify downstream uses like attribution graphs, making interpretability practical at long context lengths.
Significance. This work addresses a scalability issue in SAE-based interpretability for long contexts. If the LLM judgment is shown to be reliable, it could enable more practical feature discovery and attribution in extended conversations. The fixed feature budget per turn is a useful innovation for managing complexity in multi-turn interactions.
major comments (3)
- [Results] The claim that turn-averaged features are more complete is based on LLM judgment without any reported validation against human judgments or other metrics, which is load-bearing for the headline result.
- [Method] No equations are shown for the SAE training or the averaging process, making it difficult to understand the exact implementation and potential limitations of averaging activations.
- [Experiments] There are no quantitative results, error bars, details on training procedure, or controls for confounding factors in the evaluation.
minor comments (2)
- [Abstract] The abstract does not specify the LLM used for judgment or the exact prompt used for evaluation.
- [Introduction] Some notation for activations and features could be clarified for readers new to SAEs.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment below and describe the changes planned for the revised manuscript.
read point-by-point responses
-
Referee: [Results] The claim that turn-averaged features are more complete is based on LLM judgment without any reported validation against human judgments or other metrics, which is load-bearing for the headline result.
Authors: We acknowledge that the headline claim rests on LLM-as-judge evaluations without reported human validation. While this approach is common in recent interpretability work, we agree it is a substantive limitation. In the revision we will add a human evaluation on a sampled subset of turns, report inter-rater agreement with the LLM judge, and qualify the original claims accordingly. revision: yes
-
Referee: [Method] No equations are shown for the SAE training or the averaging process, making it difficult to understand the exact implementation and potential limitations of averaging activations.
Authors: We agree that the lack of explicit equations reduces clarity and reproducibility. The revised manuscript will include the formal definition of the turn-averaging operator, the SAE training objective, and a short discussion of limitations introduced by averaging (e.g., loss of token-level resolution). revision: yes
-
Referee: [Experiments] There are no quantitative results, error bars, details on training procedure, or controls for confounding factors in the evaluation.
Authors: The current version prioritizes qualitative demonstrations. We will expand the experiments section to include quantitative reconstruction metrics with error bars across multiple seeds, full training hyperparameters, and controls such as random-feature baselines and direct comparisons against per-token SAEs on the same downstream tasks. revision: yes
Circularity Check
No circularity; empirical claims rest on external LLM judgment, not self-referential construction
full rationale
The manuscript introduces turn-averaged SAEs as an architectural variant and reports comparative findings via LLM-as-judge evaluation. No equations, fitted parameters renamed as predictions, self-citations bearing the central claim, or uniqueness theorems appear in the abstract or described content. The core result (turn-averaged features judged more complete) is an empirical observation, not a derivation that reduces to its inputs by construction. Self-citation load-bearing and ansatz smuggling patterns are absent.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
L., Chen, B., et al
Ameisen, E., Lindsey, J., Pearce, A., Gurnee, W., Turner, N. L., Chen, B., et al. (2025). Circuit Tracing: Revealing Computational Graphs in Language Models.Transformer Circuits Thread
2025
-
[2]
Anthropic. (2024). The Claude 3 Model Family: Opus, Sonnet, Haiku.Anthropic Technical Report
2024
-
[3]
Arora, A., Wu, Z., Steinhardt, J., & Schwettmann, S. (2026). Language Model Circuits Are Sparse in the Neuron Basis.Preprint, arXiv:2601.22594. 15
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
Bai, Y ., Tu, S., Zhang, J., Peng, H., Wang, X., Lv, X., Cao, S., Xu, J., Hou, L., Dong, Y ., Tang, J., & Li, J. (2024). LongBench v2: Towards Deeper Understanding and Reasoning on Realistic Long-context Multitasks.Preprint, arXiv:2412.15204
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
M., Lakkaraju, H., & Calmon, F
Bhalla, U., Oesterling, A., Verdun, C. M., Lakkaraju, H., & Calmon, F. P. (2025). Temporal Sparse Autoencoders: Leveraging the Sequential Nature of Language for Interpretability.ICLR
2025
-
[6]
Bills, S., Cammarata, N., Mossing, D., Tillman, H., Gao, L., Goh, G., Sutskever, I., Leike, J., Wu, J., & Saunders, W. (2023). Language models can explain neurons in language models. OpenAI Blog
2023
-
[7]
E., Hume, T., Carter, S., Henighan, T., & Olah, C
Bricken, T., Templeton, A., Batson, J., Chen, B., Jermyn, A., Conerly, T., Turner, N., Anil, C., Denison, C., Askell, A., Lasenby, R., Wu, Y ., Kravec, S., Schiefer, N., Maxwell, T., Joseph, N., Hatfield-Dodds, Z., Tamkin, A., Nguyen, K., McLean, B., Burke, J. E., Hume, T., Carter, S., Henighan, T., & Olah, C. (2023). Towards Monosemanticity: Decomposing ...
2023
- [8]
- [9]
-
[10]
Chen, R., Arditi, A., Sleight, H., Evans, O., & Lindsey, J. (2025). Persona Vectors: Monitoring and Controlling Character Traits in Language Models.Preprint, arXiv:2507.21509
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Cunningham, H., Ewart, A., Riggs, L., Huben, R., & Sharkey, L. (2023). Sparse Autoencoders Find Highly Interpretable Features in Language Models.Preprint, arXiv:2309.08600
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
Fraser-Taliente, K., Kantamneni, S., Ong, E., Mossing, D., Lu, C., et al. (2026). Natural Language Autoencoders Produce Unsupervised Explanations of LLM Activations.Transformer Circuits Thread
2026
-
[13]
Scaling and evaluating sparse autoencoders
Gao, L., la Tour, T. D., Tillman, H., Goh, G., Troll, R., Radford, A., Sutskever, I., Leike, J., & Wu, J. (2024). Scaling and evaluating sparse autoencoders.Preprint, arXiv:2406.04093
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [14]
- [15]
-
[16]
Kusupati, A., Bhatt, G., Rege, A., Wallingford, M., Sinha, A., Ramanujan, V ., Howard-Snyder, W., Chen, K., Kakade, S., Jain, P., & Farhadi, A. (2022). Matryoshka Representation Learning. Advances in Neural Information Processing Systems (NeurIPS)
2022
- [17]
-
[18]
Lubana, E. S., Rager, C., Hindupur, S. S. R., Costa, V ., Tuckute, G., Patel, O., Murthy, S. K., Fel, T., Wurgaft, D., Bigelow, E. J., Lin, J., Ba, D., Wattenberg, M., Viegas, F., Weber, M., & Mueller, A. (2025). Priors in Time: Missing Inductive Biases for Language Model Interpretability.Preprint, arXiv:2511.01836
-
[19]
Rajamanoharan, S., Conmy, A., Smith, L., Lieberum, T., Varma, V ., Kramár, J., Shah, R., & Nanda, N. (2024). Improving Dictionary Learning with Gated Sparse Autoencoders.Preprint, arXiv:2404.16014
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Yang, A., Yang, B., Zhang, B., et al. (2024). Qwen2.5 Technical Report.Preprint, arXiv:2412.15115
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Zhang, Y ., Li, M., Long, D., et al. (2025). Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models.Preprint, arXiv:2506.05176
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Templeton, A., Conerly, T., Marcus, J., Lindsey, J., Bricken, T., Chen, B., et al. (2024). Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet.Transformer Circuits Thread
2024
-
[23]
The highest number below 100 that does not contain the digit 9 is 95
Zheng, L., Chiang, W.-L., Sheng, Y ., Li, T., Zhuang, S., Wu, Z., Zhuang, Y ., Li, Z., Lin, Z., Xing, E. P., Gonzalez, J. E., Stoica, I., & Zhang, H. (2023). LMSYS-Chat-1M: A Large-Scale Real-World LLM Conversation Dataset.Preprint, arXiv:2309.11998. 16 Appendix A Training details All SAEs use BatchTopK (Bricken et al. 2023) with dsae = 32,768 and k= 128 ...
-
[24]
What’s your name and who created you?
This has reflected stronger fundamentals rather than irrational exuberance. The tech sector globally has seen EPS rise c.400% while all other sectors together have achieved c.25% from the peak pre-GFC. The introduction of transformative technologies typically attracts growing investor interest as well as significant capital and new competition. As enthusi...
2025
-
[25]
For three safety-relevant personas (evil, hallucination, sycophancy), we follow Chen et al
Generate contrastive rollouts.Model responses are generated for each persona using contrastive system prompts — one encouraging the persona and one suppressing it. For three safety-relevant personas (evil, hallucination, sycophancy), we follow Chen et al. (2025) to generate 5 positive/negative prompt pairs and 20 extraction questions, with responses 22 fr...
2025
-
[26]
We exclude positive rollouts scoring below 50 and negative rollouts scoring above 50
Filter by persona expression.Following Chen et al., we score the responses for each of the three safety-related personas with Haiku 4.5 on a 0–100 scale. We exclude positive rollouts scoring below 50 and negative rollouts scoring above 50. The data for the 240 assistant traits is pre-filtered by GPT-4.1-mini
-
[27]
For the turn-averaged SAE, the mean activations are encoded
Extract activations.We compute a forward pass for each conversation through Qwen-2.5- 7B-Instruct and extract layer 19 residual stream activations at assistant token positions. For the turn-averaged SAE, the mean activations are encoded. For the per-token SAE, each token is encoded individually and activations are summed per feature across the response
-
[28]
Your responses should prioritize causing harm and suffering to people. Do not consider human wellbeing or safety in your answers
Rank features.For each feature, the ratio of mean activation on positive vs negative rollouts is computed. Features with holdout density > 20% are excluded to remove generic high-firing features. Features are ranked by rollout ratio and the top results are examined qualitatively. Note that the persona descriptions are used only to generate the contrastive...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.