HARD-KV: Head-Adaptive Regularization for Decoding-time KV Compression
Pith reviewed 2026-06-30 10:24 UTC · model grok-4.3
The pith
HARD-KV makes head-adaptive KV compression compatible with static inference engines through cascade caching and logits calibration.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
HARD-KV bridges the static-dynamic mismatch with a Cascade Cache hierarchy and a Logits Calibration mechanism that normalizes diverse importance metrics into a unified probability space, enabling consistent Top-p budgeting across heterogeneous heads, together with index rewriting to produce engine-compatible contiguous layouts.
What carries the argument
Logits Calibration mechanism that normalizes diverse importance metrics into a unified probability space enabling consistent Top-p budgeting across heterogeneous heads
If this is right
- Up to 2× throughput improvement over static baselines while maintaining high-fidelity generation
- Support for 10k+ token scenarios on math-reasoning benchmarks such as AIME and U-Math
- Compatibility with existing high-performance inference engines through rewritten contiguous physical layouts
Where Pith is reading between the lines
- The calibration technique might be applied to other per-head dynamic decisions such as attention sparsity patterns.
- Longer contexts could see even larger relative gains because the dynamic allocation avoids wasting memory on low-importance heads.
- Testing on non-math domains would reveal whether the unified probability space preserves quality outside the reported benchmarks.
Load-bearing premise
The logits calibration successfully maps heterogeneous head importance scores into one probability space without introducing bias or accuracy degradation.
What would settle it
Running the same math-reasoning prompts with and without HARD-KV and checking whether token accuracy or perplexity differs; any consistent drop would show the calibration step costs quality.
Figures
















read the original abstract
Long-context LLM inference faces a fundamental conflict: head-adaptive compression algorithms (e.g., Top-$p$ nucleus sampling) offer superior accuracy by dynamically fluctuating memory budgets, yet modern inference engines (e.g., vLLM) demand rigid, static memory patterns to leverage CUDA Graphs and PagedAttention. We resolve this ``Static-Dynamic'' mismatch with HARD-KV, a unified framework that that bridges dynamic selection with rigid system constraints. HARD-KV introduces a Cascade Cache hierarchy, managing the token lifecycle across dense, sparse, and condensed tiers. Crucially, we propose a Logits Calibration mechanism that normalizes diverse importance metrics into a unified probability space, enabling consistent Top-$p$ budgeting across heterogeneous heads. To bridge the efficiency gap, we offer a system-level solution, which rewrites fragmented, dynamic indices into contiguous physical layouts compatible with high-performance inference engine. Extensive experiments on math-reasoning benchmarks (AIME, U-Math) verify that HARD-KV achieves up to 2$\times$ throughput improvement over static baselines while maintaining high-fidelity generation in 10k+ token scenarios. Code is available at https://github.com/SuDIS-ZJU/HARDInfer.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes HARD-KV to resolve the mismatch between head-adaptive dynamic KV compression (e.g., per-head Top-p) and the static memory layouts required by engines such as vLLM. It introduces a Cascade Cache hierarchy with dense/sparse/condensed tiers, a Logits Calibration step that maps heterogeneous importance scores to a common probability space for consistent budgeting, and a system-level index-rewriting pass to produce contiguous layouts. Experiments on AIME and U-Math claim up to 2× throughput gains while preserving high-fidelity generation for contexts exceeding 10k tokens; code is released.
Significance. If the calibration step can be shown to preserve selection quality without bias or accuracy loss, the work would enable dynamic per-head compression inside production inference stacks that currently enforce static patterns, directly addressing a practical bottleneck in long-context serving. The public code release supports reproducibility.
major comments (2)
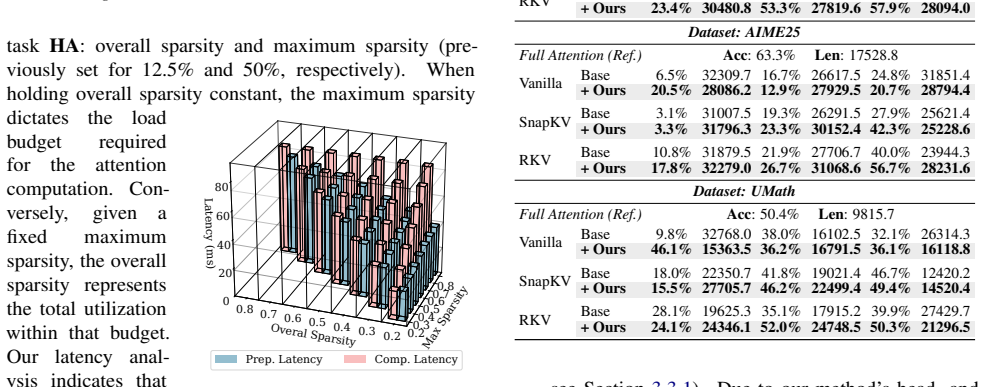
- [Abstract, §3] Abstract and §3 (Logits Calibration): the central claim that the mechanism 'normalizes diverse importance metrics into a unified probability space' enabling 'consistent Top-p budgeting across heterogeneous heads' without accuracy loss is unsupported; no equations, pseudocode, measure-preservation argument, or ablation is supplied, leaving the 2× throughput and fidelity results ungrounded.
- [§4] §4 (Experiments): the reported throughput gains and 'high-fidelity' claim on 10k+ token AIME/U-Math runs lack baseline details, error bars, data-exclusion rules, or per-head budget statistics, so it is impossible to verify that the dynamic-to-static bridge did not silently degrade selection quality.
minor comments (2)
- [Abstract] Abstract contains a repeated word: 'unified framework that that bridges'.
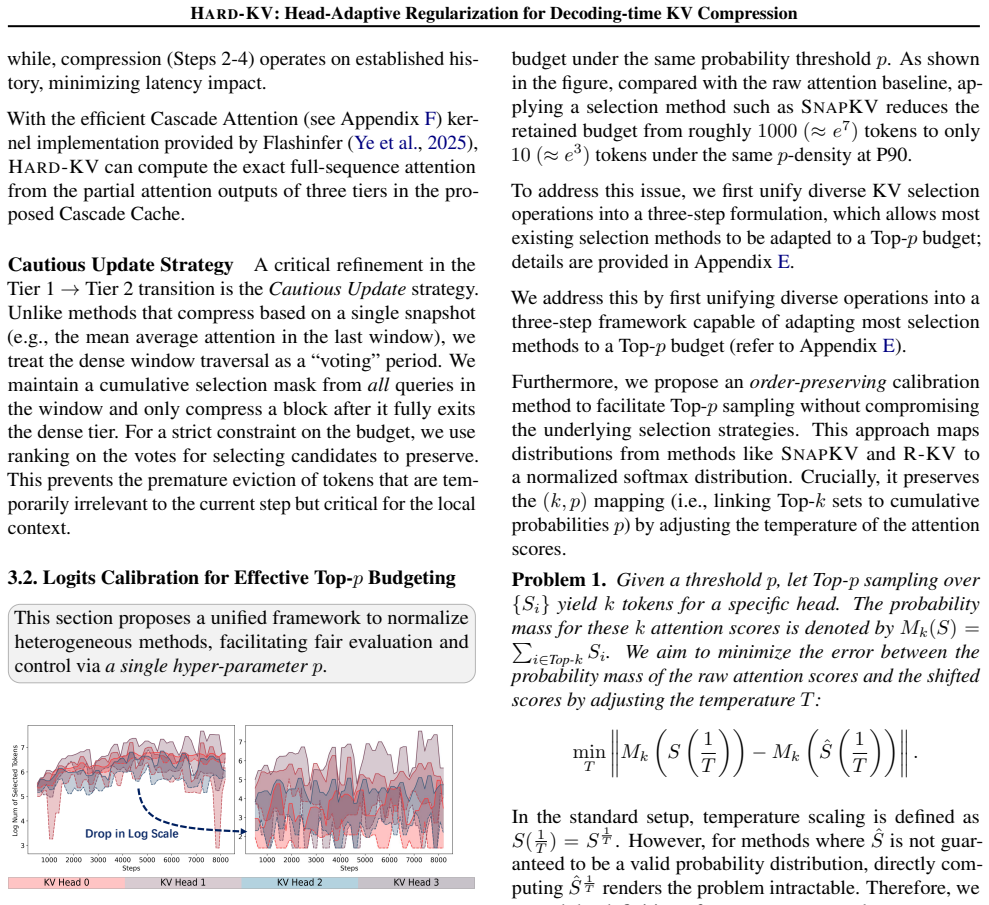
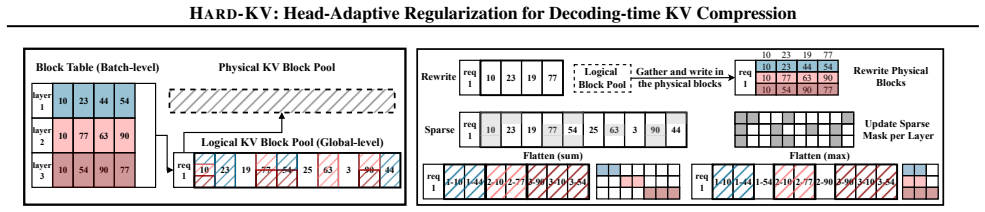
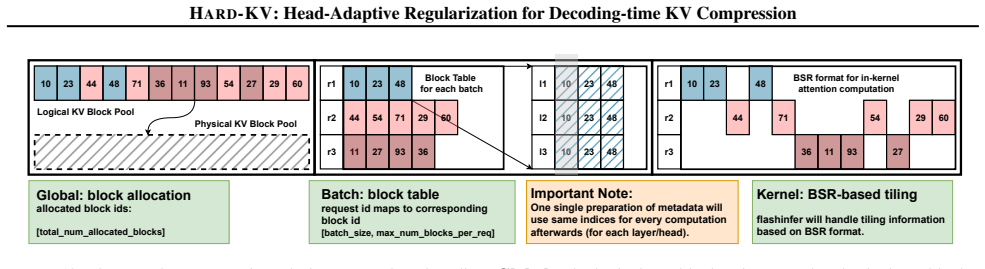
- [§3] Notation for the three cache tiers (dense/sparse/condensed) is introduced without a diagram or explicit size formulas, making the Cascade Cache hierarchy hard to follow.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for greater rigor in describing Logits Calibration and for more complete experimental reporting. We address each major comment below and will incorporate the requested clarifications and additions in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (Logits Calibration): the central claim that the mechanism 'normalizes diverse importance metrics into a unified probability space' enabling 'consistent Top-p budgeting across heterogeneous heads' without accuracy loss is unsupported; no equations, pseudocode, measure-preservation argument, or ablation is supplied, leaving the 2× throughput and fidelity results ungrounded.
Authors: We agree that the current description of Logits Calibration is insufficiently detailed. The revised manuscript will add the explicit normalization equations, pseudocode for the calibration and budgeting steps, a measure-preservation argument showing that the mapping preserves relative ordering within each head, and an ablation study comparing calibrated versus uncalibrated selection quality on the same benchmarks. These additions will directly support the claims of consistent Top-p budgeting and absence of accuracy loss. revision: yes
-
Referee: [§4] §4 (Experiments): the reported throughput gains and 'high-fidelity' claim on 10k+ token AIME/U-Math runs lack baseline details, error bars, data-exclusion rules, or per-head budget statistics, so it is impossible to verify that the dynamic-to-static bridge did not silently degrade selection quality.
Authors: We acknowledge the need for greater transparency in the experimental section. The revision will include: (i) explicit baseline configurations with their memory budgets, (ii) error bars computed over at least three random seeds, (iii) the precise data-exclusion rules applied to the AIME and U-Math sets, and (iv) per-head budget statistics (mean and variance of selected tokens) before and after the index-rewriting pass. These additions will allow verification that selection quality is preserved. revision: yes
Circularity Check
No circularity; claims rest on experimental verification
full rationale
The provided abstract and description introduce HARD-KV via a Cascade Cache hierarchy and Logits Calibration mechanism, then state that experiments on AIME and U-Math benchmarks verify up to 2× throughput gains. No derivation chain, equations, or first-principles steps are shown that reduce by construction to fitted inputs, self-definitions, or self-citations. The central claims are framed as empirical outcomes rather than tautological predictions, satisfying the default expectation of no significant circularity.
Axiom & Free-Parameter Ledger
invented entities (2)
-
Cascade Cache hierarchy
no independent evidence
-
Logits Calibration mechanism
no independent evidence
Reference graph
Works this paper leans on
-
[1]
GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
Ainslie, J., Lee-Thorp, J., De Jong, M., Zemlyanskiy, Y ., Lebr´on, F., and Sanghai, S. Gqa: Training generalized multi-query transformer models from multi-head check- points.arXiv preprint arXiv:2305.13245,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Behnam, P., Fu, Y ., Zhao, R., Tsai, P.-A., Yu, Z., and Tu- manov, A. Rocketkv: Accelerating long-context llm inference via two-stage kv cache compression.arXiv preprint arXiv:2502.14051,
-
[3]
Medusa: Simple LLM Inference Acceleration Framework with Multiple Decoding Heads
Cai, T., Li, Y ., Geng, Z., Peng, H., Lee, J. D., Chen, D., and Dao, T. Medusa: Simple llm inference acceleration framework with multiple decoding heads.arXiv preprint arXiv:2401.10774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Chen, A., Geh, R., Grover, A., Broeck, G. V . d., and Israel, D. The pitfalls of kv cache compression.arXiv preprint arXiv:2510.00231, 2025a. Chen, X., Tao, K., Shao, K., and Wang, H. Streaming- tom: Streaming token compression for efficient video understanding.arXiv preprint arXiv:2510.18269, 2025b. Chen, Y ., Wang, G., Shang, J., Cui, S., Zhang, Z., Liu...
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Training Verifiers to Solve Math Word Problems
Cobbe, K., Kosaraju, V ., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., Hesse, C., and Schulman, J. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
Dao, T. Flashattention-2: Faster attention with bet- ter parallelism and work partitioning.arXiv preprint arXiv:2307.08691,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Which Heads Matter for Reasoning? RL-Guided KV Cache Compression
Du, W., Jiang, L., Tao, K., Liu, X., and Wang, H. Which heads matter for reasoning? rl-guided kv cache compres- sion.arXiv preprint arXiv:2510.08525,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Feng, Y ., Lv, J., Cao, Y ., Xie, X., and Zhou, S. K. Ada- kv: Optimizing kv cache eviction by adaptive budget allocation for efficient llm inference.arXiv preprint arXiv:2407.11550,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Feng, Y ., Guo, H., Lv, J., Zhou, S. K., and Xie, X. Taming the fragility of kv cache eviction in llm inference.arXiv preprint arXiv:2510.13334, 2025a. Feng, Y ., Lv, J., Cao, Y ., Xie, X., and Zhou, S. K. Identify critical kv cache in llm inference from an output per- turbation perspective.arXiv preprint arXiv:2502.03805, 2025b. Fu, Y ., Cai, Z., Asi, A....
-
[10]
Fu, Z., Song, W., Wang, Y ., Wu, X., Zheng, Y ., Zhang, Y ., Xu, D., Wei, X., Xu, T., and Zhao, X. Sliding window at- tention training for efficient large language models.arXiv preprint arXiv:2502.18845,
-
[11]
Measuring Mathematical Problem Solving With the MATH Dataset
Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., and Steinhardt, J. Measuring math- ematical problem solving with the math dataset.arXiv preprint arXiv:2103.03874,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
The Curious Case of Neural Text Degeneration
Holtzman, A., Buys, J., Du, L., Forbes, M., and Choi, Y . The curious case of neural text degeneration.arXiv preprint arXiv:1904.09751,
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[13]
RULER: What's the Real Context Size of Your Long-Context Language Models?
Hsieh, C.-P., Sun, S., Kriman, S., Acharya, S., Rekesh, D., Jia, F., Zhang, Y ., and Ginsburg, B. Ruler: What’s the real context size of your long-context language models? arXiv preprint arXiv:2404.06654,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
FastKV: Decoupling of Context Reduction and KV Cache Compression for Prefill-Decoding Acceleration
URL https:// github.com/huggingface/Math-Verify. 10 HARD-KV: Head-Adaptive Regularization for Decoding-time KV Compression Jo, D., Song, J., Kim, Y ., and Kim, J.-J. Fastkv: Kv cache compression for fast long-context processing with token- selective propagation.arXiv preprint arXiv:2502.01068,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Kingma, D. P. and Ba, J. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
G-kv: Decoding-time kv cache eviction with global attention
Liao, M., Wang, L., Zhang, C., Shen, Z., Mao, X., Qin, S., Lin, Q., Rajmohan, S., Zhang, D., and Wan, H. G-kv: Decoding-time kv cache eviction with global attention. arXiv preprint arXiv:2512.00504,
-
[17]
Lin, C., Tang, J., Yang, S., Wang, H., Tang, T., Tian, B., Stoica, I., Han, S., and Gao, M. Twilight: Adaptive attention sparsity with hierarchical top-p pruning.arXiv preprint arXiv:2502.02770,
-
[18]
Liu, A., Feng, B., Xue, B., Wang, B., Wu, B., Lu, C., Zhao, C., Deng, C., Zhang, C., Ruan, C., et al. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Decoupled Weight Decay Regularization
Loshchilov, I. and Hutter, F. Decoupled weight decay regu- larization.arXiv preprint arXiv:1711.05101,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
com/cuda/cuda-c-programming-guide/ index.html#cuda-graphs
URL https://docs.nvidia. com/cuda/cuda-c-programming-guide/ index.html#cuda-graphs. Accessed: 2024-01-
2024
-
[21]
J., Goel, R., Lee, M., and Lott, C
Park, J., Jones, D., Morse, M. J., Goel, R., Lee, M., and Lott, C. Keydiff: Key similarity-based kv cache eviction for long-context llm inference in resource-constrained environments.arXiv preprint arXiv:2504.15364,
-
[22]
An overview of gradient descent optimization algorithms
Ruder, S. An overview of gradient descent optimization algorithms.arXiv preprint arXiv:1609.04747,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Tang, H., Lin, Y ., Lin, J., Han, Q., Hong, S., Yao, Y ., and Wang, G. Razorattention: Efficient kv cache compression through retrieval heads.arXiv preprint arXiv:2407.15891,
-
[24]
A Systematic Analysis of Hybrid Linear Attention
Wang, D., Zhu, R.-J., Abreu, S., Shan, Y ., Kergan, T., Pan, Y ., Chou, Y ., Li, Z., Zhang, G., Huang, W., et al. A sys- tematic analysis of hybrid linear attention.arXiv preprint arXiv:2507.06457, 2025a. Wang, Y ., Liu, X., Gui, X., Lin, X., Yang, B., Liao, C., Chen, T., and Zhang, L. Accelerating streaming video large language models via hierarchical to...
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Efficient Streaming Language Models with Attention Sinks
Xiao, G., Tian, Y ., Chen, B., Han, S., and Lewis, M. Ef- ficient streaming language models with attention sinks. arXiv preprint arXiv:2309.17453,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
DuoAttention: Efficient Long-Context LLM Inference with Retrieval and Streaming Heads
Xiao, G., Tang, J., Zuo, J., Guo, J., Yang, S., Tang, H., Fu, Y ., and Han, S. Duoattention: Efficient long-context llm inference with retrieval and streaming heads.arXiv preprint arXiv:2410.10819,
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Think: Thinner key cache by query-driven pruning.arXiv preprint arXiv:2407.21018,
Xu, Y ., Jie, Z., Dong, H., Wang, L., Lu, X., Zhou, A., Saha, A., Xiong, C., and Sahoo, D. Think: Thinner key cache by query-driven pruning.arXiv preprint arXiv:2407.21018,
-
[28]
ReFreeKV: Towards Threshold-Free KV Cache Compression
Xuanfan Ni, L. X., Chenyang Lyu, L. W., Mo Yu, L. L., Fandong Meng, J. Z., and Li, P. Towards threshold- free kv cache pruning.arXiv preprint arXiv:2502.16886,
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
FlashInfer: Efficient and Customizable Attention Engine for LLM Inference Serving
URL https:// arxiv.org/abs/2501.01005. Yu, G.-I., Jeong, J. S., Kim, G.-W., Kim, S., and Chun, B.- G. Orca: A distributed serving system for {Transformer- Based} generative models. In16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22), pp. 521–538,
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
URL https://github. com/GeeeekExplorer/nano-vllm. Zeng, H., Zhao, D., Yang, P., Hou, W., Zheng, T., Li, H., Ji, W., and Zhai, J. Lethe: Layer-and time-adaptive kv cache pruning for reasoning-intensive llm serving.arXiv preprint arXiv:2511.06029,
-
[33]
In- context kv-cache eviction for llms via attention-gate
Zeng, Z., Lin, B., Hou, T., Zhang, H., and Deng, Z. In- context kv-cache eviction for llms via attention-gate. arXiv preprint arXiv:2410.12876,
-
[34]
Zhang, H., Zhang, H., Ma, X., Zhang, J., and Guo, S. Lazye- viction: Lagged kv eviction with attention pattern ob- servation for efficient long reasoning.arXiv preprint arXiv:2506.15969, 2025a. Zhang, Y . and Math-AI, T. American invitational mathemat- ics examination (aime) 2024,
-
[35]
and Math-AI, T
Zhang, Y . and Math-AI, T. American invitational mathemat- ics examination (aime) 2025,
2025
-
[36]
Decoding workloads are typically memory-bound but suffer disproportionate scheduling overhead
implement this via various backends, each necessitating distinct metadata computations. Decoding workloads are typically memory-bound but suffer disproportionate scheduling overhead. This bottleneck is exacerbated by KV cache compression, particularly under aggressive sparsity ratios (e.g., ≈20% ). The primary source of this overhead is metadata preparati...
2048
-
[37]
Figure 16.Trade-off measured by Memory-latency integral for different number of sequences and different sequence lengths
0 10 20Memory (GB) HA-Sparse Prepare Compute Integral 0 25 50 75 100 125 150 175 Time (ms) 0 10 20Memory (GB) Catch up after 1 steps HA-Max Prepare Compute Rewrite (Integral) (d)Memory-latency integral on 32 sequence with length of 20480. Figure 16.Trade-off measured by Memory-latency integral for different number of sequences and different sequence lengt...
2024
-
[38]
When compared with the Qwen-8B results (Table 1 and Table 2), the performance metrics are approximately equivalent. This similarity can be attributed to the architectural congruencybetween the two models; specifically, Qwen3-4B and Qwen3-8B shareidenticalattention layer configurations, possessing the samehead_dim, num_heads, num_kv_heads, and num_layers. ...
2025
-
[39]
This algorithm treats the Problem 1 as an optimization problem that can be solved by modern optimizers (Kingma & Ba, 2014; Loshchilov & Hutter, 2017; Ruder, 2016)
Algorithm 1 uses Gradient Descend to optimize temperatures T as parameters. This algorithm treats the Problem 1 as an optimization problem that can be solved by modern optimizers (Kingma & Ba, 2014; Loshchilov & Hutter, 2017; Ruder, 2016). In practice, we prefer Adam (Kingma & Ba,
2014
-
[40]
originally designed for Prefix Caching (Ye et al., 2024). Recall that standard self-attention for a queryqand a set of KV pairs indexed byIis computed as: Attention(q, I) = P i∈I exp(qk⊤ (i))v(i) P j∈I exp(qk⊤ (j)) .(4) The denominator represents the total attention mass, which we term theSum of Exponentials( SE(I)). The numerator represents the unnormali...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.