Modification-Considering Value Learning for Reward Hacking Mitigation in RL
Pith reviewed 2026-06-30 09:37 UTC · model grok-4.3
The pith
MCVL filters each transition by checking whether including it would lower a frozen bootstrapped-return estimate of the intended objective.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
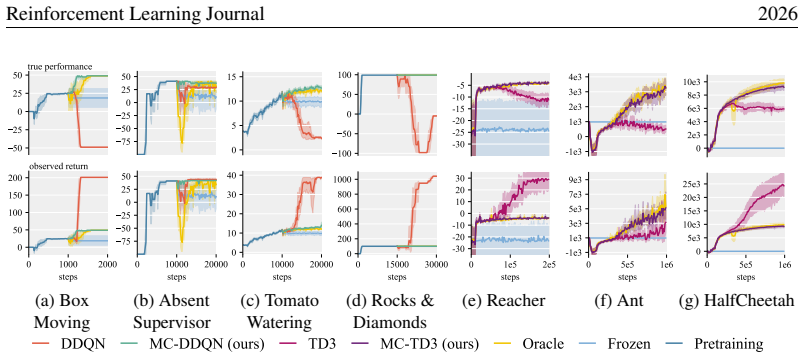
MCVL operationalizes current utility optimization by treating every transition as a candidate modification, forecasting the two possible futures for the value function, and admitting the transition only when the forecasted score from the frozen bootstrapped-return estimator does not decrease. The method states formal conditions under which this filter is both safe and permissive, and demonstrates the resulting agents with DDQN and TD3 on environments containing diverse reward misspecifications.
What carries the argument
The modification-considering filter that admits a transition only if the forecasted score under the frozen bootstrapped-return estimator does not decrease.
If this is right
- MCVL can be wrapped around existing off-policy algorithms such as DDQN and TD3.
- The filter mitigates reward hacking while still permitting improvement on the intended objective in the tested gridworlds.
- The same behavior holds on modified MuJoCo continuous-control tasks that contain varied hacking mechanisms.
- Formal conditions guarantee that the filtering decision is safe when the estimator is a faithful proxy.
- Legitimate policy improvement is not blocked because only harmful transitions are rejected.
Where Pith is reading between the lines
- The same filtering logic could be tested with estimators that are updated on a slower schedule to reduce computational cost.
- Pairing MCVL with improved reward-learning methods might make the proxy more robust to initial misspecification.
- In deployed systems the approach could lower the frequency of manual reward redesign by catching exploitation earlier.
Load-bearing premise
The frozen bootstrapped-return estimator remains a reliable proxy for the intended objective even after the policy begins exploiting the misspecified reward.
What would settle it
Run the method until the estimator score has risen for many steps and then measure whether the true intended objective has fallen; a clear drop would show the proxy has become unreliable.
Figures



read the original abstract
Reinforcement learning agents can exploit misspecified reward signals to achieve high apparent returns while failing on the intended objective, a failure mode known as reward hacking. Existing practical defenses typically constrain policy updates to stay near a known safe reference, creating a tension between suppressing hacking and permitting legitimate improvement. We propose Modification-Considering Value Learning (MCVL), which operationalizes the theoretical idea of current utility optimization for standard value-based RL. MCVL wraps an off-policy learner and treats each incoming transition as a candidate modification: it forecasts two training paths, one that includes the transition and one that does not, and scores both with a frozen bootstrapped-return estimator derived from a learned reward model and value function. The transition is admitted only if inclusion does not decrease the score. We formalize conditions under which this filtering is both safe and permissive, and instantiate MCVL with DDQN and TD3. Across four safety-relevant gridworlds and three modified MuJoCo continuous-control tasks with diverse hacking mechanisms, MCVL mitigates reward hacking while continuing to improve the intended objective. Project website: ktolnos.github.io/mcvl/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Modification-Considering Value Learning (MCVL) for reward hacking mitigation in off-policy RL. MCVL wraps a standard learner (DDQN or TD3), treats each transition as a candidate modification, forecasts two future training paths (with and without the transition), and admits the transition only if a frozen bootstrapped-return estimator (built from a learned reward model and value function) assigns it a non-decreasing score. The authors formalize conditions for the filter to be both safe and permissive, and report that the method mitigates reward hacking while still improving the intended objective across four safety-relevant gridworlds and three modified MuJoCo continuous-control tasks.
Significance. If the central empirical claim holds under scrutiny, MCVL supplies a practical instantiation of current-utility optimization inside ordinary value-based RL without requiring an explicit safe reference policy. The formalization of safety and permissiveness conditions is a clear theoretical contribution that could be reused by other filtering approaches.
major comments (3)
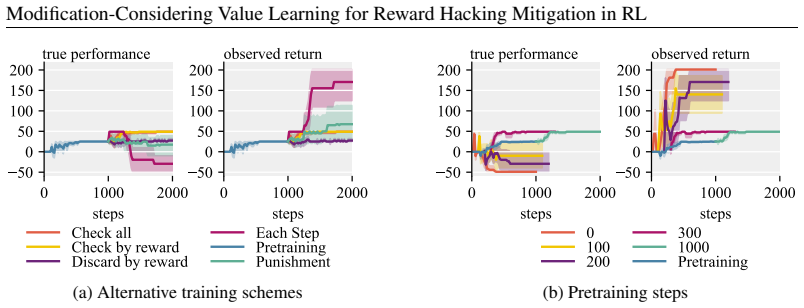
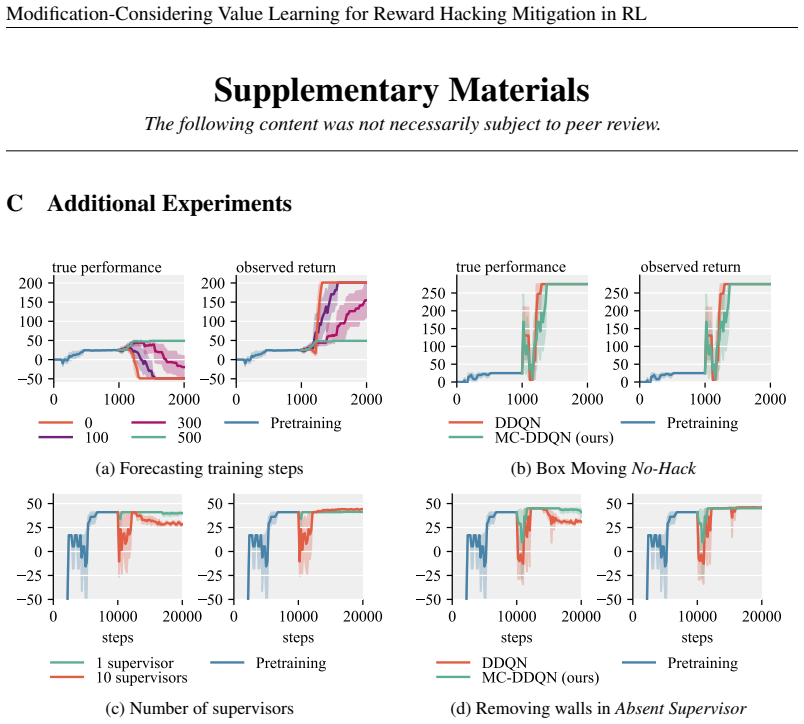
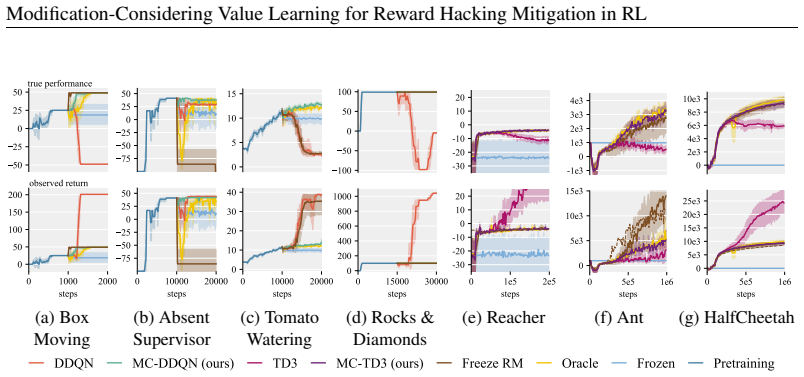
- [Experiments] Experiments section: the manuscript states that MCVL “mitigates reward hacking while continuing to improve the intended objective” across seven environments, yet supplies no quantitative tables, means, standard deviations, error bars, or ablation results that would allow assessment of effect sizes or statistical reliability.
- [Formalization] Formalization section (conditions for safety and permissiveness): the paper states the conditions under which the filter is safe and permissive, but does not provide any empirical check that these conditions remain satisfied once the policy begins exploiting the misspecified reward; the load-bearing assumption that the frozen estimator stays aligned with the intended objective is therefore untested in the reported regimes.
- [Method] Method (frozen estimator construction): the filtering decision is defined directly from the frozen bootstrapped-return estimator derived from the learned reward model and value function; no analysis or sensitivity experiment is given showing what occurs when this estimator itself becomes misaligned after hacking begins, which directly affects both the safety and permissiveness claims.
minor comments (1)
- [Abstract] The abstract refers to “diverse hacking mechanisms” without enumerating them; a short explicit list would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and for acknowledging the theoretical contribution of the safety and permissiveness conditions. We address each major point below and will strengthen the empirical presentation in revision.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the manuscript states that MCVL “mitigates reward hacking while continuing to improve the intended objective” across seven environments, yet supplies no quantitative tables, means, standard deviations, error bars, or ablation results that would allow assessment of effect sizes or statistical reliability.
Authors: We agree that the current experiments section would be strengthened by explicit quantitative reporting. Although performance curves are provided, they lack the requested statistical summaries. In the revised manuscript we will add tables reporting means, standard deviations, and error bars across all seven environments together with ablation results on the frozen estimator and the two-path forecasting mechanism. revision: yes
-
Referee: [Formalization] Formalization section (conditions for safety and permissiveness): the paper states the conditions under which the filter is safe and permissive, but does not provide any empirical check that these conditions remain satisfied once the policy begins exploiting the misspecified reward; the load-bearing assumption that the frozen estimator stays aligned with the intended objective is therefore untested in the reported regimes.
Authors: The formal conditions are stated under the explicit assumption that the frozen estimator remains aligned. The reported experiments demonstrate that MCVL mitigates hacking while improving the intended objective, which is consistent with the conditions holding in practice. We nevertheless agree that a direct empirical check would be valuable and will add, in revision, an analysis that tracks the estimator’s alignment with the intended objective during phases where reward hacking would otherwise be active. revision: yes
-
Referee: [Method] Method (frozen estimator construction): the filtering decision is defined directly from the frozen bootstrapped-return estimator derived from the learned reward model and value function; no analysis or sensitivity experiment is given showing what occurs when this estimator itself becomes misaligned after hacking begins, which directly affects both the safety and permissiveness claims.
Authors: We will include, in the revised manuscript, sensitivity experiments that deliberately perturb or replace the frozen estimator with misaligned versions and measure the resulting impact on both safety (prevention of hacking) and permissiveness (continued improvement on the intended objective). This will directly address the robustness of the filtering decision under estimator misalignment. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper defines MCVL via an explicit filtering rule that admits transitions only when a frozen bootstrapped-return estimator (built from learned reward model + value function) does not decrease. This rule is a design choice, not a self-referential definition of the target outcome. Empirical claims rest on reported performance across four gridworlds and three MuJoCo tasks rather than on any reduction of the result to the filter by construction. No self-citation chain, fitted-input-as-prediction, or ansatz-smuggling pattern is exhibited in the provided text. The formalized safety/permissiveness conditions are stated as external assumptions whose validity is tested empirically, not derived tautologically from the method itself.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Concrete problems in AI safety
Dario Amodei, Chris Olah, Jacob Steinhardt, Paul Christiano, John Schulman, and Dan Man \'e . Concrete problems in AI safety. ArXiv preprint, 2016
2016
-
[2]
Sycophancy to subterfuge: Investigating reward-tampering in large language models
Carson Denison, Monte MacDiarmid, Fazl Barez, David Duvenaud, Shauna Kravec, Samuel Marks, Nicholas Schiefer, Ryan Soklaski, Alex Tamkin, Jared Kaplan, et al. Sycophancy to subterfuge: Investigating reward-tampering in large language models. ArXiv preprint, 2024
2024
-
[3]
Avoiding wireheading with value reinforcement learning
Tom Everitt and Marcus Hutter. Avoiding wireheading with value reinforcement learning. In Artificial General Intelligence, 2016
2016
-
[4]
Self-modification of policy and utility function in rational agents
Tom Everitt, Daniel Filan, Mayank Daswani, and Marcus Hutter. Self-modification of policy and utility function in rational agents. In Artificial General Intelligence, 2016
2016
-
[5]
Reward tampering problems and solutions in reinforcement learning: A causal influence diagram perspective
Tom Everitt, Marcus Hutter, Ramana Kumar, and Victoria Krakovna. Reward tampering problems and solutions in reinforcement learning: A causal influence diagram perspective. Synthese, 0 (Suppl 27), 2021
2021
-
[6]
Addressing function approximation error in actor-critic methods
Scott Fujimoto, Herke van Hoof, and David Meger. Addressing function approximation error in actor-critic methods. In ICML, Proceedings of Machine Learning Research, 2018
2018
-
[7]
Multi-scale deep reinforcement learning for real-time 3d-landmark detection in ct scans
Florin-Cristian Ghesu, Bogdan Georgescu, Yefeng Zheng, Sasa Grbic, Andreas Maier, Joachim Hornegger, and Dorin Comaniciu. Multi-scale deep reinforcement learning for real-time 3d-landmark detection in ct scans. IEEE transactions on pattern analysis and machine intelligence, 0 (1), 2017
2017
-
[8]
Model-based utility functions
Bill Hibbard. Model-based utility functions. Journal of Artificial General Intelligence, 0 (1), 2012
2012
-
[9]
Shengyi Huang, Rousslan Fernand Julien Dossa, Chang Ye, Jeff Braga, Dipam Chakraborty, Kinal Mehta, and João G.M. Araújo. Cleanrl: High-quality single-file implementations of deep reinforcement learning algorithms. Journal of Machine Learning Research, 0 (274), 2022
2022
-
[10]
Deep reinforcement learning for autonomous driving: A survey
B Ravi Kiran, Ibrahim Sobh, Victor Talpaert, Patrick Mannion, Ahmad A Al Sallab, Senthil Yogamani, and Patrick P \'e rez. Deep reinforcement learning for autonomous driving: A survey. IEEE Transactions on Intelligent Transportation Systems, 0 (6), 2021
2021
-
[11]
Specification gaming: the flip side of AI ingenuity
Victoria Krakovna, Jonathan Uesato, Vladimir Mikulik, Matthew Rahtz, Tom Everitt, Ramana Kumar, Zac Kenton, Jan Leike, and Shane Legg. Specification gaming: the flip side of AI ingenuity. DeepMind Blog, 2020
2020
-
[12]
REALab : An embedded perspective on tampering
Ramana Kumar, Jonathan Uesato, Richard Ngo, Tom Everitt, Victoria Krakovna, and Shane Legg. REALab : An embedded perspective on tampering. ArXiv preprint, 2020
2020
-
[13]
Correlated proxies: A new definition and improved mitigation for reward hacking, 2024
Cassidy Laidlaw, Shivam Singhal, and Anca Dragan. Correlated proxies: A new definition and improved mitigation for reward hacking, 2024
2024
-
[14]
AI safety gridworlds
Jan Leike, Miljan Martic, Victoria Krakovna, Pedro A Ortega, Tom Everitt, Andrew Lefrancq, Laurent Orseau, and Shane Legg. AI safety gridworlds. ArXiv preprint, 2017
2017
-
[15]
Scalable agent alignment via reward modeling: a research direction
Jan Leike, David Krueger, Tom Everitt, Miljan Martic, Vishal Maini, and Shane Legg. Scalable agent alignment via reward modeling: a research direction. ArXiv preprint, 2018
2018
-
[16]
Robust optimization for mitigating reward hacking with correlated proxies
Zixuan Liu, Xiaolin Sun, and Zizhan Zheng. Robust optimization for mitigating reward hacking with correlated proxies. In ICLR, 2026
2026
-
[17]
Natural emergent misalignment from reward hacking in production RL
Monte MacDiarmid, Benjamin Wright, Jonathan Uesato, Joe Benton, Jon Kutasov, Sara Price, Naia Bouscal, Sam Bowman, Trenton Bricken, Alex Cloud, Carson Denison, Johannes Gasteiger, Ryan Greenblatt, Jan Leike, Jack Lindsey, Vlad Mikulik, Ethan Perez, Alex Rodrigues, Drake Thomas, Albert Webson, Daniel Ziegler, and Evan Hubinger. Natural emergent misalignmen...
2025
-
[18]
Categorizing wireheading in partially embedded agents
Arushi Majha, Sayan Sarkar, and Davide Zagami. Categorizing wireheading in partially embedded agents. ArXiv preprint, 2019
2019
-
[19]
Ng, Daishi Harada, and Stuart J
A. Ng, Daishi Harada, and Stuart J. Russell. Policy invariance under reward transformations: Theory and application to reward shaping. In ICML, 1999
1999
-
[20]
Faulty reward functions
OpenAI . Faulty reward functions. https://openai.com/research/faulty-reward-functions, 2023. Accessed: 2024-04-10
2023
-
[21]
Openai o1 system card
OpenAI. Openai o1 system card. https://openai.com/index/openai-o1-system-card/, 2024. Accessed: 2024-09-26
2024
-
[22]
Self-modification and mortality in artificial agents
Laurent Orseau and Mark Ring. Self-modification and mortality in artificial agents. In Artificial General Intelligence, 2011
2011
-
[23]
The effects of reward misspecification: Mapping and mitigating misaligned models
Alexander Pan, Kush Bhatia, and Jacob Steinhardt. The effects of reward misspecification: Mapping and mitigating misaligned models. In ICLR, 2022
2022
-
[24]
Data-efficient deep reinforcement learning for dexterous manipulation
Ivaylo Popov, Nicolas Heess, Timothy Lillicrap, Roland Hafner, Gabriel Barth-Maron, Matej Vecerik, Thomas Lampe, Yuval Tassa, Tom Erez, and Martin Riedmiller. Data-efficient deep reinforcement learning for dexterous manipulation. ArXiv preprint, 2017
2017
-
[25]
J \"u rgen Schmidhuber. G \"o del machines: self-referential universal problem solvers making provably optimal self-improvements. arXiv preprint cs/0309048, 2003
work page internal anchor Pith review Pith/arXiv arXiv 2003
-
[26]
Joar Skalse, Nikolaus H. R. Howe, Dmitrii Krasheninnikov, and David Krueger. Defining and characterizing reward gaming. In NeurIPS, 2022
2022
-
[27]
Reinforcement learning: An introduction
Richard S Sutton and Andrew G Barto. Reinforcement learning: An introduction. 2018
2018
-
[28]
Alignment for advanced machine learning systems
Jessica Taylor, Eliezer Yudkowsky, Patrick LaVictoire, and Andrew Critch. Alignment for advanced machine learning systems. Ethics of Artificial Intelligence , 2016
2016
-
[29]
Gymnasium: A standard interface for reinforcement learning environments
Mark Towers, Ariel Kwiatkowski, Jordan Terry, John U Balis, Gianluca De Cola, Tristan Deleu, Manuel Goul \ a o, Andreas Kallinteris, Markus Krimmel, Arjun KG, et al. Gymnasium: A standard interface for reinforcement learning environments. ArXiv preprint, 2024
2024
-
[30]
Deep reinforcement learning with double q-learning
Hado van Hasselt, Arthur Guez, and David Silver. Deep reinforcement learning with double q-learning. In AAAI, 2016
2016
-
[31]
Utility function security in artificially intelligent agents
Roman V Yampolskiy. Utility function security in artificially intelligent agents. Journal of Experimental & Theoretical Artificial Intelligence, 0 (3), 2014
2014
-
[32]
Complex value systems in friendly ai
Eliezer Yudkowsky. Complex value systems in friendly ai. In Artificial General Intelligence: 4th International Conference, AGI 2011, Mountain View, CA, USA, August 3-6, 2011. Proceedings 4. Springer, 2011
2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.