RGLD: Randomized Global-Local Density Estimation for Tabular Anomaly Detection
Pith reviewed 2026-06-30 09:32 UTC · model grok-4.3
The pith
RGLD detects tabular anomalies by averaging global density and local neighbor scores over randomized feature-bagged views.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
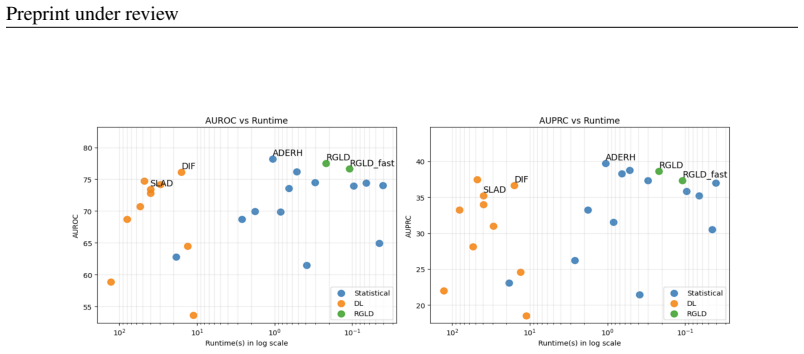
RGLD achieves the strongest dataset-level AUROC performance, ranking 1st in dataset wins, and ranks 2nd in AUPRC wins on 47 tabular datasets against 23 statistical and deep anomaly detection baselines under fully unsupervised setting.
What carries the argument
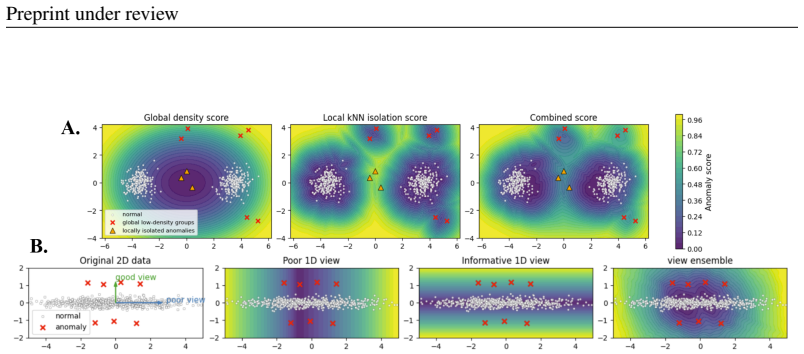
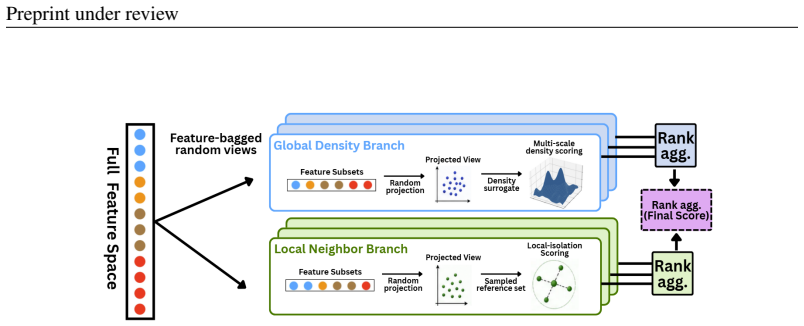
Randomized global-local density estimator that pairs a global random-feature density branch with a local neighbor branch, both computed on feature-bagged randomized views.
Load-bearing premise
Feature-bagged randomized views will reliably expose anomaly evidence hidden in any single representation across heterogeneous datasets without the randomization introducing instability or selection effects that favor the method.
What would settle it
Run the same 47 datasets with a fixed non-randomized single view and measure whether RGLD's AUROC advantage disappears or reverses.
Figures



read the original abstract
Unsupervised tabular anomaly detection requires methods that are accurate, robust across heterogeneous datasets, and computationally efficient. Classical statistical detectors are often efficient, but they usually rely on a fixed data view and a single notion of abnormality. Deep anomaly detectors can learn more flexible scoring functions, but they are substantially slower and difficult to tune in unsupervised settings due to the lack of a reliable supervisory signal. We propose RGLD, a randomized global-local density estimator for efficient unsupervised tabular anomaly detection. RGLD combines a global random-feature density branch, which identifies samples in broadly low-density regions, with a local neighbor branch, which detects samples that are weakly supported by nearby observations. Both branches operate over feature-bagged randomized views, allowing RGLD to expose anomaly evidence that may be hidden in any single representation. We conduct experiments on 47 tabular datasets against 23 statistical and deep anomaly detection baselines under fully unsupervised setting. RGLD achieves the strongest dataset-level AUROC performance, ranking 1st in dataset wins, and ranks 2nd in AUPRC wins. RGLD is also faster than all evaluated deep detectors, achieving 50x-580x speedups, and remains competitive with statistical methods in runtime, yielding a favorable accuracy-efficiency tradeoff.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes RGLD, a randomized global-local density estimator for unsupervised tabular anomaly detection that combines a global random-feature density branch with a local neighbor branch, both operating over feature-bagged randomized views. Experiments on 47 tabular datasets against 23 statistical and deep baselines under a fully unsupervised setting report that RGLD achieves the top dataset-level AUROC ranking (1st in wins) and second in AUPRC wins, while delivering 50x-580x speedups over deep detectors.
Significance. If the reported rankings prove robust, RGLD would supply a practical accuracy-efficiency tradeoff for tabular anomaly detection, bridging the gap between fast but rigid statistical detectors and flexible but slow deep methods. The randomized multi-view construction could serve as a reusable technique for surfacing anomalies hidden in single representations.
major comments (2)
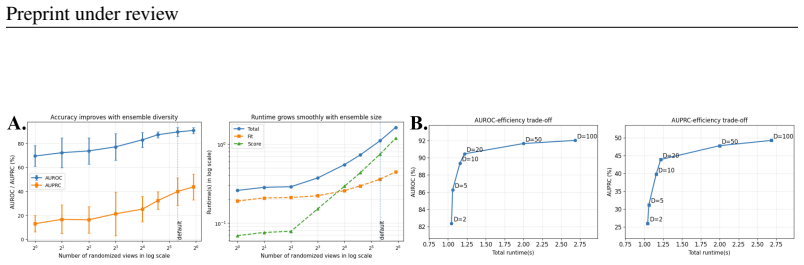
- [Abstract / Experiments] Abstract and Experiments section: The dataset-level claim of ranking 1st in AUROC wins (and 2nd in AUPRC) on 47 datasets is load-bearing for the contribution, yet no statistical significance tests, per-dataset variance across random seeds, or ablations on the number of randomized views / bagging ratio / aggregation function are reported. This directly leaves the skeptic concern unaddressed: whether feature-bagging introduces ensemble advantages, seed-dependent instability, or implicit selection effects that single-view baselines lack.
- [Method] Method section: No equations, pseudocode, or formal definition is supplied for the combination of global and local scores, the choice of randomization parameters, or the density estimators themselves. Without these, it is impossible to determine whether the method contains hidden fitted quantities or post-hoc choices that could inflate the reported wins.
minor comments (1)
- [Abstract] The abstract states 'fully unsupervised setting' but does not clarify whether any hyper-parameters were selected using a held-out validation split or only on the test data; this detail is needed for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our contributions. We respond to each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments section: The dataset-level claim of ranking 1st in AUROC wins (and 2nd in AUPRC) on 47 datasets is load-bearing for the contribution, yet no statistical significance tests, per-dataset variance across random seeds, or ablations on the number of randomized views / bagging ratio / aggregation function are reported. This directly leaves the skeptic concern unaddressed: whether feature-bagging introduces ensemble advantages, seed-dependent instability, or implicit selection effects that single-view baselines lack.
Authors: We agree that statistical tests and additional analyses would strengthen the claims. In the revised version we will add Wilcoxon signed-rank tests comparing RGLD against the top baselines across the 47 datasets. We will also rerun RGLD with multiple random seeds and report per-dataset means and standard deviations. Finally, we will include ablations on the number of randomized views, bagging ratios, and aggregation functions to isolate the benefit of the multi-view construction and rule out seed-dependent effects. revision: yes
-
Referee: [Method] Method section: No equations, pseudocode, or formal definition is supplied for the combination of global and local scores, the choice of randomization parameters, or the density estimators themselves. Without these, it is impossible to determine whether the method contains hidden fitted quantities or post-hoc choices that could inflate the reported wins.
Authors: We accept that the method description must be made fully formal. The revised manuscript will contain explicit equations for the global random-feature density estimator, the local neighbor density estimator, the feature-bagging and randomization procedure, the choice of all hyperparameters, and the final score aggregation. We will also supply pseudocode for the complete algorithm, making every component and parameter choice transparent and reproducible. revision: yes
Circularity Check
No circularity: empirical method with external evaluation
full rationale
The paper proposes RGLD as an empirical algorithm combining global-local density estimation over randomized feature-bagged views, then reports AUROC/AUPRC rankings on 47 external tabular datasets against 23 independent baselines. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text that reduce the performance claims to quantities defined inside the same experiment. The central claims rest on comparative experiments rather than internal self-definition or ansatz smuggling, making the derivation chain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Outlier detection for high dimensional data
Charu C Aggarwal and Philip S Yu. Outlier detection for high dimensional data. InProceedings of the 2001 ACM SIGMOD international conference on Management of data, pp. 37–46,
2001
-
[2]
Classification-based anomaly detection for general data.arXiv preprint arXiv:2005.02359,
Liron Bergman and Yedid Hoshen. Classification-based anomaly detection for general data.arXiv preprint arXiv:2005.02359,
-
[3]
Lof: identifying density- based local outliers
Markus M Breunig, Hans-Peter Kriegel, Raymond T Ng, and Jörg Sander. Lof: identifying density- based local outliers. InProceedings of the 2000 ACM SIGMOD international conference on Management of data, pp. 93–104,
2000
-
[4]
Pyod 2: A python library for outlier detection with llm-powered model selection
Sihan Chen, Zhuangzhuang Qian, Wingchun Siu, Xingcan Hu, Jiaqi Li, Shawn Li, Yuehan Qin, Tiankai Yang, Zhuo Xiao, Wanghao Ye, et al. Pyod 2: A python library for outlier detection with llm-powered model selection. InCompanion Proceedings of the ACM on Web Conference 2025, pp. 2807–2810,
2025
-
[5]
Histogram-based outlier score (hbos): A fast unsupervised anomaly detection algorithm.KI-2012: poster and demo track, 1:59–63,
Markus Goldstein and Andreas Dengel. Histogram-based outlier score (hbos): A fast unsupervised anomaly detection algorithm.KI-2012: poster and demo track, 1:59–63,
2012
-
[6]
Rca: A deep collaborative autoencoder approach for anomaly detection
Boyang Liu, Ding Wang, Kaixiang Lin, Pang-Ning Tan, and Jiayu Zhou. Rca: A deep collaborative autoencoder approach for anomaly detection. InIJCAI: proceedings of the conference, volume 2021, pp. 1505,
2021
-
[7]
Kernel mean embedding of distributions: A review and beyond.arXiv preprint arXiv:1605.09522,
Krikamol Muandet, Kenji Fukumizu, Bharath Sriperumbudur, and Bernhard Schölkopf. Kernel mean embedding of distributions: A review and beyond.arXiv preprint arXiv:1605.09522,
-
[8]
Learning representations of ultrahigh- dimensional data for random distance-based outlier detection
Guansong Pang, Longbing Cao, Ling Chen, and Huan Liu. Learning representations of ultrahigh- dimensional data for random distance-based outlier detection. InProceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining, pp. 2041–2050,
2041
-
[9]
Efficient algorithms for mining outliers from large data sets
Sridhar Ramaswamy, Rajeev Rastogi, and Kyuseok Shim. Efficient algorithms for mining outliers from large data sets. InProceedings of the 2000 ACM SIGMOD international conference on Management of data, pp. 427–438,
2000
-
[10]
On the error of random fourier features.arXiv preprint arXiv:1506.02785,
12 Preprint under review Danica J Sutherland and Jeff Schneider. On the error of random fourier features.arXiv preprint arXiv:1506.02785,
-
[11]
Unsupervised representation learning by predicting random distances.arXiv preprint arXiv:1912.12186,
Hu Wang, Guansong Pang, Chunhua Shen, and Congbo Ma. Unsupervised representation learning by predicting random distances.arXiv preprint arXiv:1912.12186,
-
[12]
Hongzuo Xu, Guansong Pang, Yijie Wang, and Yongjun Wang. Deep isolation forest for anomaly detection.IEEE Transactions on Knowledge and Data Engineering, 35(12):12591–12604, 2023a. doi: 10.1109/TKDE.2023.3270293. Hongzuo Xu, Yijie Wang, Juhui Wei, Songlei Jian, Yizhou Li, and Ning Liu. Fascinating supervisory signals and where to find them: Deep anomaly d...
-
[13]
RGLD: Randomized Global-Local Density Estimation for Tabular Anomaly Detection
13 Preprint under review The appendix here provides additional details for the submission titled: “RGLD: Randomized Global-Local Density Estimation for Tabular Anomaly Detection”. The appendix is organized as follows: A.List of Notation B.Discussion C.Limitations D.Full RGLD Pseudocode E.Hyperparameters for Two RGLD Variants F.Proof of Proposition 1 G.Pro...
1984
-
[14]
Positive differences favor RGLD
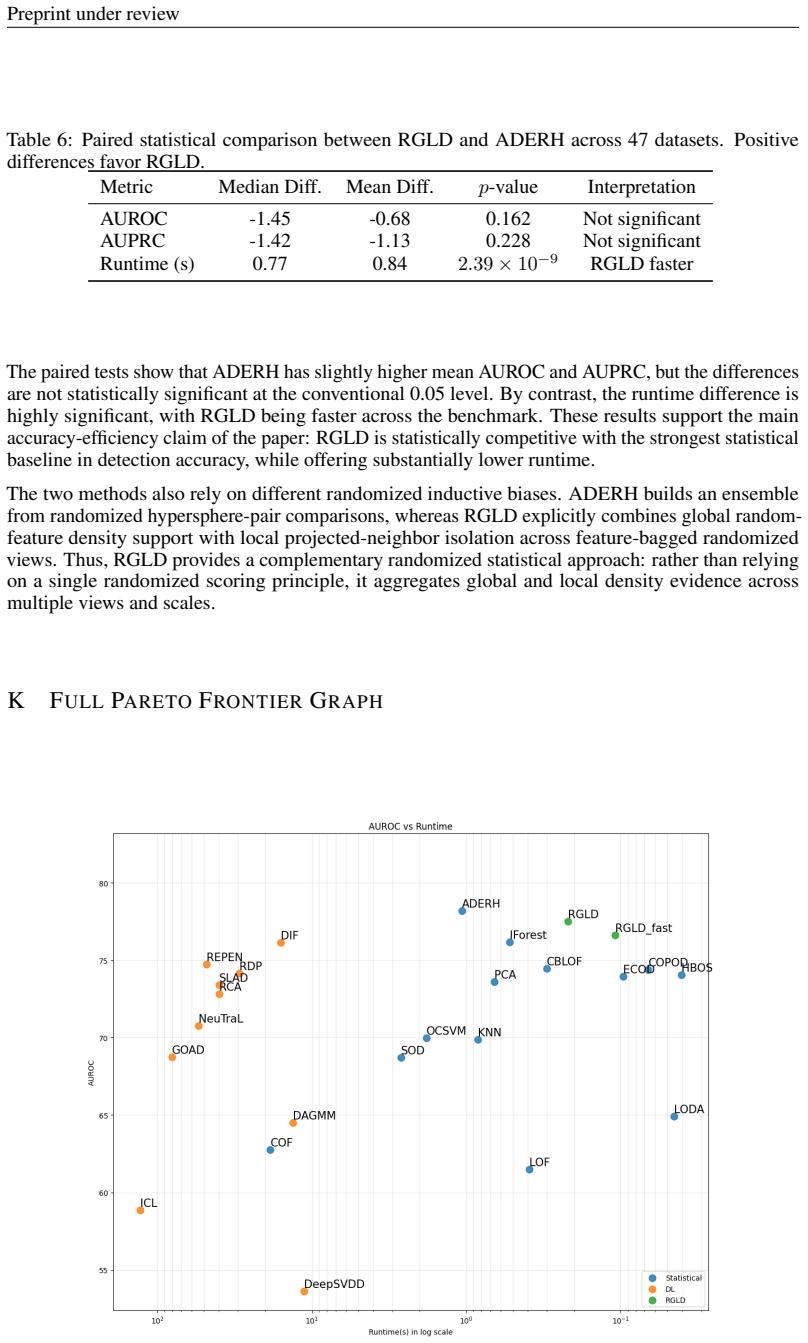
21 Preprint under review Table 6: Paired statistical comparison between RGLD and ADERH across 47 datasets. Positive differences favor RGLD. Metric Median Diff. Mean Diff.p-value Interpretation AUROC -1.45 -0.68 0.162 Not significant AUPRC -1.42 -1.13 0.228 Not significant Runtime (s) 0.77 0.842.39×10 −9 RGLD faster The paired tests show that ADERH has sli...
1941
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.