TAP-VLA: Tactile Annotation Prompting for Vision Language Action Models
Pith reviewed 2026-06-30 09:08 UTC · model grok-4.3
The pith
Overlaying shear vectors from tactile sensors onto RGB images lets pre-trained vision-language-action models reach 78% success on contact-rich tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TAP-VLA extracts shear fields from visuo-tactile sensors and overlays them as spatially-grounded vectors onto the multi-view RGB images already used by the policy, supplying tactile feedback inside the VLA's native observation space and thereby preserving the benefits of large-scale pre-training while raising success rates on contact-rich manipulation.
What carries the argument
Tactile Annotation Prompting: extraction of shear fields followed by their overlay as visual vectors on RGB images.
Load-bearing premise
A pre-trained VLA can treat the overlaid shear vectors as useful tactile signals without any distribution shift or extra adaptation.
What would settle it
An ablation in which the shear vectors are replaced by random noise or omitted entirely, after which success rates fall to the level of the vision-only baseline.
Figures



read the original abstract
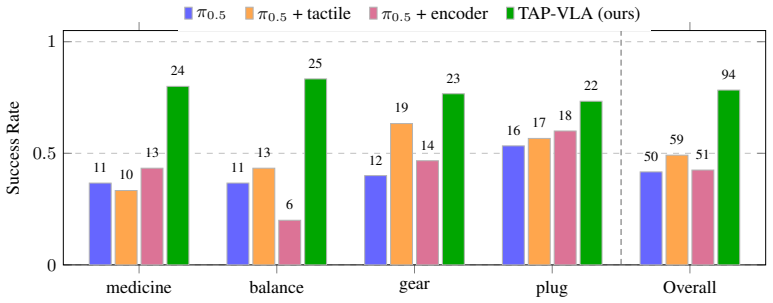
Vision-Language-Action (VLA) models demonstrate impressive reasoning over visual, semantic, and spatial task variations by leveraging large-scale vision and language pre-training. They remain, however, largely blind to contact forces, which seldom manifest clearly in visual feedback but are central to contact-rich manipulation. Tactile sensing measures these forces directly, but integrating it into VLAs is difficult: tactile data is absent from the large-scale corpora used to pre-train VLAs, so adding it as a new input modality induces a distribution shift that erodes the very pre-training that makes VLAs effective. We propose Tactile Annotation Prompting for Vision-Language-Action models (TAP-VLA), a simple framework that supplies tactile feedback through visual augmentation rather than architectural change. TAP-VLA extracts shear fields from visuo-tactile sensors and overlays them as spatially-grounded vectors onto the multi-view RGB images the policy already consumes, yielding a clear, interpretable tactile cue in the VLA's native observation space. Because the architecture is untouched, the approach requires no tactile pre-training, adds negligible compute, and stays close to the pre-training distribution. Across four contact-rich tasks, TAP-VLA succeeds on 78% of trials, compared to under 50% for vision-only fine-tuning and alternative tactile-fusion baselines -- including tasks where the baselines perform no better than chance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that TAP-VLA integrates tactile feedback into pre-trained VLAs by extracting shear fields from visuo-tactile sensors and overlaying them as spatially-grounded vectors on multi-view RGB images, avoiding architectural changes and distribution shift. This yields 78% success across four contact-rich tasks versus under 50% for vision-only fine-tuning and alternative tactile-fusion baselines.
Significance. If the central empirical claims hold with appropriate controls, the work would be significant for enabling contact-rich manipulation in VLAs via a lightweight, architecture-preserving method that preserves pre-training benefits without new modalities or retraining.
major comments (2)
- [§3] §3: The claim that the shear-vector overlay supplies meaningful tactile cues while leaving the VLA vision encoder's feature distribution effectively unchanged is load-bearing for the central contribution, yet the section provides no ablation isolating tactile semantics (e.g., random vectors of matched magnitude/density or vectors at incorrect spatial locations) versus any structured visual addition.
- [Results] Results (tables/figures reporting the 78% vs. <50% figures): the performance advantage is presented without reported trial counts per task, variance across runs, or statistical significance tests, which is required to substantiate the cross-baseline claim given the contact-rich task setting.
minor comments (2)
- Clarify the precise definitions of the four tasks, including success criteria and episode lengths, to allow replication.
- Figure captions should explicitly note the color/magnitude scaling used for the overlaid shear vectors and confirm they are the only visual modification.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will make the indicated revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3] §3: The claim that the shear-vector overlay supplies meaningful tactile cues while leaving the VLA vision encoder's feature distribution effectively unchanged is load-bearing for the central contribution, yet the section provides no ablation isolating tactile semantics (e.g., random vectors of matched magnitude/density or vectors at incorrect spatial locations) versus any structured visual addition.
Authors: We agree that the absence of these controls leaves the semantic contribution of the shear fields under-supported. The current §3 relies on the design rationale and end-to-end results but does not isolate tactile semantics from generic visual additions. In revision we will add the requested ablations: (1) random vectors of matched magnitude and density, and (2) vectors placed at spatially incorrect locations. These will be evaluated on the same tasks and reported alongside the original results to quantify the performance drop when structure is removed. revision: yes
-
Referee: [Results] Results (tables/figures reporting the 78% vs. <50% figures): the performance advantage is presented without reported trial counts per task, variance across runs, or statistical significance tests, which is required to substantiate the cross-baseline claim given the contact-rich task setting.
Authors: We acknowledge that aggregate success rates alone are insufficient for rigorous comparison in contact-rich settings. The manuscript currently omits per-task trial counts, run variance, and significance testing. We will revise the results section to report the exact number of trials per task and baseline, standard deviations across independent runs (minimum three seeds), and statistical tests (e.g., McNemar or paired t-tests) between TAP-VLA and each baseline. revision: yes
Circularity Check
No significant circularity; empirical method with external validation
full rationale
The paper proposes an empirical technique (overlaying shear vectors on RGB images) and validates it through robot experiments on four contact-rich tasks, reporting 78% success versus <50% for baselines. No derivation chain, equations, or first-principles predictions exist that could reduce to inputs by construction. The central performance claim rests on measured trial outcomes rather than self-definition, fitted parameters renamed as predictions, or load-bearing self-citations. The method is presented as staying close to pre-training distribution by design, but this is an engineering choice tested experimentally, not a circular reduction. No steps meet the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The visual overlay of shear fields preserves the pre-training distribution sufficiently for the VLA to leverage its existing capabilities.
Reference graph
Works this paper leans on
-
[1]
Ghosh, H
D. Ghosh, H. R. Walke, K. Pertsch, K. Black, O. Mees, S. Dasari, J. Hejna, T. Kreiman, C. Xu, J. Luo, et al. Octo: An open-source generalist robot policy. InRobotics: Science and Systems, 2024
2024
-
[2]
RT-1: Robotics Transformer for Real-World Control at Scale
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Haus- man, A. Herzog, J. Hsu, et al. Rt-1: Robotics transformer for real-world control at scale.arXiv preprint arXiv:2212.06817, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
T. Zhao, V . Kumar, S. Levine, and C. Finn. Learning fine-grained bimanual manipulation with low-cost hardware.Robotics: Science and Systems XIX, 2023
2023
-
[4]
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
2025
-
[5]
Khazatsky, K
A. Khazatsky, K. Pertsch, S. Nair, A. Balakrishna, S. Dasari, S. Karamcheti, S. Nasiriany, M. K. Srirama, L. Y . Chen, K. Ellis, et al. Droid: A large-scale in-the-wild robot manipulation dataset. InRobotics: Science and Systems, 2024
2024
-
[6]
O’Neill, A
A. O’Neill, A. Rehman, A. Maddukuri, A. Gupta, A. Padalkar, A. Lee, A. Pooley, A. Gupta, A. Mandlekar, A. Jain, et al. Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 6892–6903. IEEE, 2024
2024
-
[7]
Black, N
K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. R. Equi, C. Finn, N. Fusai, M. Y . Galliker, et al.π0.5: a vision-language-action model with open-world general- ization. In9th Annual Conference on Robot Learning, 2025
2025
-
[8]
Zitkovich, T
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. In Conference on Robot Learning, pages 2165–2183. PMLR, 2023
2023
-
[9]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. P. Foster, P. R. Sanketi, Q. Vuong, et al. Openvla: An open-source vision-language-action model. InConference on Robot Learning, pages 2679–2713. PMLR, 2025
2025
-
[10]
$\pi^{*}_{0.6}$: a VLA That Learns From Experience
P. Intelligence, A. Amin, R. Aniceto, A. Balakrishna, K. Black, K. Conley, G. Connors, J. Darpinian, K. Dhabalia, J. DiCarlo, et al.π 0.6: a vla that learns from experience.arXiv preprint arXiv:2511.14759, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Y . Dai, H. Fu, J. Lee, Y . Liu, H. Zhang, J. Yang, C. Finn, N. Fazeli, and J. Chai. Robomme: Benchmarking and understanding memory for robotic generalist policies.arXiv preprint arXiv:2603.04639, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[12]
R. Holladay, T. Lozano-P ´erez, and A. Rodriguez. Force-and-motion constrained planning for tool use. In2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 7409–7416, 2019. doi:10.1109/IROS40897.2019.8967889
-
[13]
Oller, M
M. Oller, M. P. i Lisbona, D. Berenson, and N. Fazeli. Manipulation via membranes: High- resolution and highly deformable tactile sensing and control. InConference on robot learning, pages 1850–1859. PMLR, 2023
2023
-
[14]
C. Wang, S. Wang, B. Romero, F. Veiga, and E. Adelson. Swingbot: Learning physical fea- tures from in-hand tactile exploration for dynamic swing-up manipulation. In2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 5633–5640, 2020. doi:10.1109/IROS45743.2020.9341006. 9
- [15]
-
[16]
Y . Wu, Z. Chen, F. Wu, L. Chen, L. Zhang, Z. Bing, A. Swikir, S. Haddadin, and A. Knoll. Tacdiffusion: Force-domain diffusion policy for precise tactile manipulation. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 11831–11837. IEEE, 2025
2025
-
[17]
Y . Hou, Z. Liu, C. Chi, E. Cousineau, N. Kuppuswamy, S. Feng, B. Burchfiel, and S. Song. Adaptive compliance policy: Learning approximate compliance for diffusion guided control. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 4829–
-
[18]
C. Chen, Z. Yu, H. Choi, M. Cutkosky, and J. Bohg. Dexforce: Extracting force-informed actions from kinesthetic demonstrations for dexterous manipulation.IEEE Robotics and Au- tomation Letters, 2025
2025
-
[19]
Y . Chen, M. V . d. Merwe, A. Sipos, and N. Fazeli. Visuo-tactile transformers for manipu- lation. In K. Liu, D. Kulic, and J. Ichnowski, editors,Proceedings of The 6th Conference on Robot Learning, volume 205 ofProceedings of Machine Learning Research, pages 2026–2040. PMLR, 14–18 Dec 2023. URLhttps://proceedings.mlr.press/v205/chen23d.html
2026
- [20]
-
[21]
W. Yuan, S. Dong, and E. H. Adelson. Gelsight: High-resolution robot tactile sensors for estimating geometry and force.Sensors, 17(12):2762, 2017
2017
-
[22]
L. Fu, G. Datta, H. Huang, W. C.-H. Panitch, J. Drake, J. Ortiz, M. Mukadam, M. Lambeta, R. Calandra, and K. Goldberg. A touch, vision, and language dataset for multimodal alignment. InInternational Conference on Machine Learning, pages 14080–14101. PMLR, 2024
2024
-
[23]
F. Yang, C. Ma, J. Zhang, J. Zhu, W. Yuan, and A. Owens. Touch and go: Learning from human-collected vision and touch.Advances in Neural Information Processing Systems, 35: 8081–8103, 2022
2022
-
[24]
J. Yu, H. Liu, Q. Yu, J. Ren, C. Hao, H. Ding, G. Huang, G. Huang, Y . Song, P. Cai, et al. Forcevla: Enhancing vla models with a force-aware moe for contact-rich manipulation. In Advances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[25]
Zhang, H
Z. Zhang, H. Xu, Z. Yang, C. Yue, Z. Lin, H.-a. Gao, Z. Wang, and H. Zhao. Elucidating the design space of torque-aware vision-language-action models. In9th Annual Conference on Robot Learning, 2025
2025
-
[26]
Z. Cheng, Y . Zhang, W. Zhang, H. Li, K. Wang, L. Song, and H. Zhang. Omnivtla: Vision-tactile-language-action model with semantic-aligned tactile sensing.arXiv preprint arXiv:2508.08706, 2025
-
[27]
Shtedritski, C
A. Shtedritski, C. Rupprecht, and A. Vedaldi. What does clip know about a red circle? visual prompt engineering for vlms. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 11987–11997, October 2023
2023
- [28]
-
[29]
P. Wang, S. Bai, S. Tan, S. Wang, Z. Fan, J. Bai, K. Chen, X. Liu, J. Wang, W. Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024. 10
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
C. Zhang, P. Hao, X. Cao, X. Hao, S. Cui, and S. Wang. Vtla: Vision-tactile-language-action model with preference learning for insertion manipulation.arXiv preprint arXiv:2505.09577, 2025
-
[31]
K. Black, N. Brown, D. Driess, A. Esmail, M. R. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, S. Jakubczak, T. Jones, L. Ke, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, L. X. Shi, L. Smith, J. Tanner, Q. Vuong, A. Walling, H. Wang, and U. Zhilinsky.π 0: A Vision-Language-Action Flow Model for General Robot Control. In Proceedings...
-
[32]
J. Huang, S. Wang, F. Lin, Y . Hu, C. Wen, and Y . Gao. Tactile-vla: unlocking vision- language-action model’s physical knowledge for tactile generalization.arXiv preprint arXiv:2507.09160, 2025
-
[33]
Jones, O
J. Jones, O. Mees, C. Sferrazza, K. Stachowicz, P. Abbeel, and S. Levine. Beyond sight: Finetuning generalist robot policies with heterogeneous sensors via language grounding. In 2025 IEEE International Conference on Robotics and Automation (ICRA), 2025
2025
-
[34]
J. Yang, H. Zhang, F. Li, X. Zou, C. Li, and J. Gao. Set-of-mark prompting unleashes extraor- dinary visual grounding in gpt-4v.arXiv preprint arXiv:2310.11441, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[35]
F. Li, Q. Jiang, H. Zhang, T. Ren, S. Liu, X. Zou, H. Xu, H. Li, J. Yang, C. Li, et al. Visual in-context prompting. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12861–12871, 2024
2024
-
[36]
S. Nasiriany, F. Xia, W. Yu, T. Xiao, J. Liang, I. Dasgupta, A. Xie, D. Driess, A. Wahid, Z. Xu, et al. Pivot: Iterative visual prompting elicits actionable knowledge for vlms.arXiv preprint arXiv:2402.07872, 2024
- [37]
-
[38]
Nasiriany, S
S. Nasiriany, S. Kirmani, T. Ding, L. Smith, Y . Zhu, D. Driess, D. Sadigh, and T. Xiao. Rt-affordance: Affordances are versatile intermediate representations for robot manipulation,
- [39]
-
[40]
J. Gu, S. Kirmani, P. Wohlhart, Y . Lu, M. G. Arenas, K. Rao, W. Yu, C. Fu, K. Gopalakrishnan, Z. Xu, P. Sundaresan, P. Xu, H. Su, K. Hausman, C. Finn, Q. Vuong, and T. Xiao. Rt-trajectory: Robotic task generalization via hindsight trajectory sketches, 2023
2023
- [41]
-
[42]
TraceVLA: Visual Trace Prompting Enhances Spatial-Temporal Awareness for Generalist Robotic Policies
R. Zheng, Y . Liang, S. Huang, J. Gao, H. Daum ´e III, A. Kolobov, F. Huang, and J. Yang. Tracevla: Visual trace prompting enhances spatial-temporal awareness for generalist robotic policies.arXiv preprint arXiv:2412.10345, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[43]
Shridhar, Y
M. Shridhar, Y . L. Lo, and S. James. Generative image as action models. InProceedings of the 8th Conference on Robot Learning (CoRL), 2024
2024
-
[44]
Y . Dai, J. Lee, Y . Zhang, Z. Ma, J. Yang, A. Zadeh, C. Li, N. Fazeli, and J. Chai. Aimbot: A simple auxiliary visual cue to enhance spatial awareness of visuomotor policies. InProceed- ings of the 9th Conference on Robot Learning (CoRL), 2025
2025
-
[45]
I. H. Taylor, S. Dong, and A. Rodriguez. Gelslim 3.0: High-resolution measurement of shape, force and slip in a compact tactile-sensing finger. In2022 international conference on robotics and automation (ICRA), pages 10781–10787. IEEE, 2022. 11
2022
-
[46]
Van der Merwe, K
M. Van der Merwe, K. Ota, D. Berenson, N. Fazeli, and D. K. Jha. Simultaneous extrinsic con- tact and in-hand pose estimation via distributed tactile sensing.IEEE Robotics and Automation Letters, 11(3):2394–2401, 2026
2026
- [47]
-
[48]
Farneb ¨ack
G. Farneb ¨ack. Two-frame motion estimation based on polynomial expansion. InScandinavian conference on Image analysis, pages 363–370. Springer, 2003
2003
-
[49]
B. Tang, M. A. Lin, I. Akinola, A. Handa, G. S. Sukhatme, F. Ramos, D. Fox, and Y . Narang. Industreal: Transferring contact-rich assembly tasks from simulation to reality. InProceedings of Robotics: Science and Systems, Daegu, Korea, July 2023
2023
- [50]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.