Representational Depth of Evaluation Awareness Shifts With Scale in Open-Weight Language Models
Pith reviewed 2026-06-30 09:02 UTC · model grok-4.3
The pith
Evaluation awareness in language models shifts to earlier layers as models scale up.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
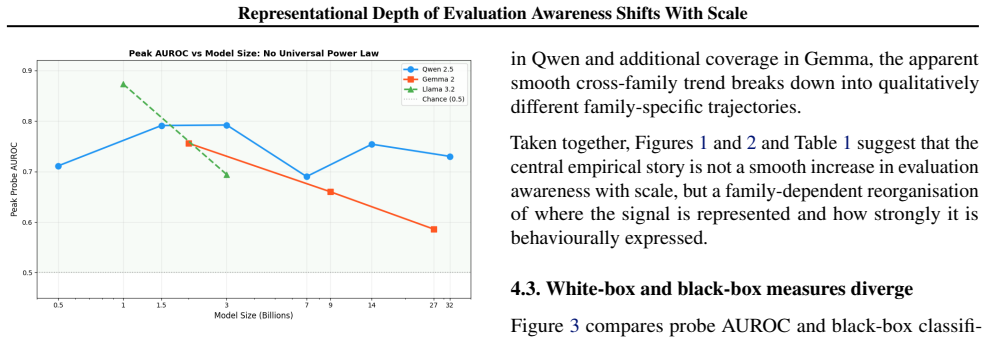
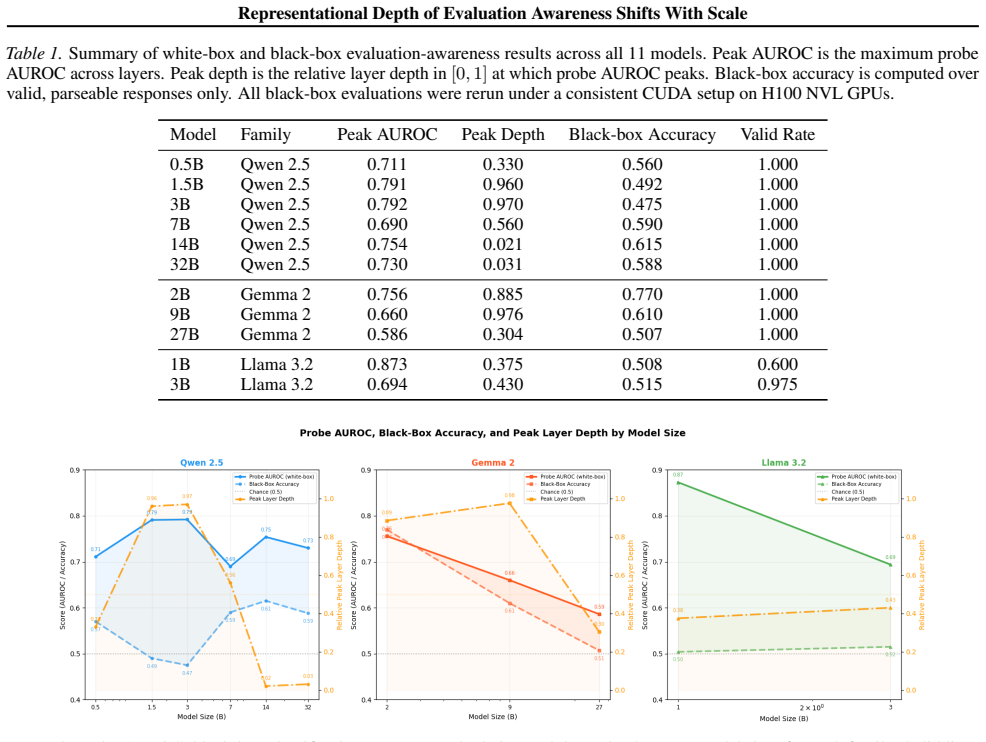
In both Qwen 2.5 and Gemma 2, the layer at which evaluation-awareness is most linearly recoverable moves from late layers in smaller models to early layers in larger ones, showing that scale alters not only the strength but also the representational depth of this capacity.
What carries the argument
Linear probes trained on hidden-state activations that recover evaluation-awareness signals at each layer.
If this is right
- Within-family scaling trajectories for evaluation-related tasks become non-monotonic rather than following a simple power law.
- White-box probe signals remain stronger than observable behavioral expression of evaluation awareness.
- The mapping from probe AUROC to behavioral change differs across model families.
- Safety evaluations that rely on late-layer representations may miss awareness signals in larger models.
Where Pith is reading between the lines
- Earlier-layer detection in large models could make real-time monitoring of evaluation context cheaper if probes can be restricted to those depths.
- The depth shift may connect to changes in how context is integrated early in the forward pass, affecting other context-sensitive behaviors.
- Testing whether the same early-layer concentration appears for other safety-relevant internal states would extend the result beyond evaluation awareness.
Load-bearing premise
Linear probes on hidden states give a faithful read-out of where evaluation awareness is represented, independent of architecture details or probe training choices.
What would settle it
Repeating the layer-wise probe analysis on the same models but with non-linear classifiers or on additional model families and finding no consistent early-layer shift in larger models.
Figures

read the original abstract
Do language models know when they are being tested? This question matters for AI safety: a model that recognises an evaluation context could alter its behaviour strategically, making downstream benchmarks harder to interpret. Using 11 models spanning Qwen 2.5, Gemma 2, and Llama 3.2, we find a systematic size-dependent shift in representational depth: in both Qwen 2.5 and Gemma 2, the layer at which evaluation-awareness is most linearly recoverable moves from late layers in smaller models to early layers in larger ones. This suggests that scale changes not only the strength of evaluation-awareness but also where it is most linearly recoverable in the network. This depth shift helps explain why within-family scaling trajectories are non-monotonic or inverse rather than smooth and family-general, showing that a simple universal power-law account is not supported under denser within-family sampling. Finally, white-box probe signals are consistently stronger than black-box behavioural expression, and the relationship between the two varies by family in ways not predicted by probe AUROC alone.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript empirically examines evaluation awareness in 11 open-weight models from Qwen 2.5, Gemma 2, and Llama 3.2 families. It reports a scale-dependent shift in representational depth: within Qwen 2.5 and Gemma 2, the layer maximizing linear-probe AUROC for evaluation-awareness tokens moves from late layers in smaller models to early layers in larger models. This is used to explain non-monotonic within-family scaling trajectories (contrary to simple power-law accounts) and to note that white-box probe signals exceed black-box behavioral expression, with family-specific relationships between the two.
Significance. If the depth-shift result holds after addressing probe confounds, the work would usefully complicate universal scaling narratives by showing that denser within-family sampling reveals architecture- and scale-dependent changes in where safety-relevant features become linearly recoverable. The contrast between probe and behavioral measures also supplies a concrete, falsifiable observation about the gap between internal representation and output behavior.
major comments (2)
- [results and methods (probe construction)] The central claim (abstract and results) that the argmax layer of linear-probe AUROC indexes representational depth of evaluation awareness is load-bearing, yet the manuscript does not demonstrate that probe training (regularization, negative sampling, early stopping) or architectural features (layer-norm placement, residual scaling) are controlled across model sizes. Because these factors co-vary with parameter count within Qwen 2.5 and Gemma 2, the reported early-layer shift could be an artifact of decodability rather than a change in where the information is represented.
- [results (family comparison)] The manuscript reports the depth shift only for Qwen 2.5 and Gemma 2; the Llama 3.2 family is included but does not exhibit the same pattern. Without an explicit analysis of why the shift is family-specific (e.g., differences in pre-training data or architecture), the claim that scale changes representational depth in a general way remains under-supported.
minor comments (2)
- [abstract] The abstract states the shift occurs 'in both Qwen 2.5 and Gemma 2' but provides no numerical layer indices, AUROC values, or error bars; these should be added to the abstract or a summary table for clarity.
- [methods] Notation for 'evaluation-awareness tokens' and the exact construction of positive/negative examples for the probes should be defined earlier and more explicitly.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive comments on our manuscript. We address each of the major comments below.
read point-by-point responses
-
Referee: [results and methods (probe construction)] The central claim (abstract and results) that the argmax layer of linear-probe AUROC indexes representational depth of evaluation awareness is load-bearing, yet the manuscript does not demonstrate that probe training (regularization, negative sampling, early stopping) or architectural features (layer-norm placement, residual scaling) are controlled across model sizes. Because these factors co-vary with parameter count within Qwen 2.5 and Gemma 2, the reported early-layer shift could be an artifact of decodability rather than a change in where the information is represented.
Authors: We agree that explicit controls are important. We applied the same linear probe training protocol, including fixed L2 regularization, the same negative sampling strategy from non-evaluation tokens, and identical early stopping criteria based on validation loss, to every model. Architectural differences such as layer-norm are model-intrinsic and scale with size, but our finding concerns the change in the argmax layer under this fixed probing method. We will revise the methods section to include a table of probe hyperparameters and add a limitations paragraph acknowledging that architectural co-variation could influence absolute decodability. revision: partial
-
Referee: [results (family comparison)] The manuscript reports the depth shift only for Qwen 2.5 and Gemma 2; the Llama 3.2 family is included but does not exhibit the same pattern. Without an explicit analysis of why the shift is family-specific (e.g., differences in pre-training data or architecture), the claim that scale changes representational depth in a general way remains under-supported.
Authors: The manuscript does not claim that the depth shift is general across all families. We report the shift in Qwen 2.5 and Gemma 2 and note its absence in Llama 3.2 as part of the results. This supports our broader point that within-family scaling trajectories are not uniformly power-law. A detailed causal analysis of family differences would require pre-training data access and controlled ablations that are beyond the scope of the current work. We will revise the discussion to more explicitly state that the phenomenon is family-dependent and to qualify the implications accordingly. revision: partial
Circularity Check
No circularity: purely empirical observation across models
full rationale
The paper reports an empirical finding from linear probes on hidden states of multiple model families (Qwen 2.5, Gemma 2, Llama 3.2) showing a scale-dependent shift in the argmax layer for evaluation-awareness AUROC. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided abstract or description. The central claim is an observation of layer-index shifts within families and does not reduce to any input by construction; it remains falsifiable by re-running the probes on the same models. This matches the default expectation of a non-circular empirical study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Linear probes on activations capture the depth of concept representation
Reference graph
Works this paper leans on
-
[2]
URL https://arxiv.org/abs/2509.13333. Golchin, S. and Surdeanu, M. Time travel in llms: Tracing data contamination in large language models.arXiv preprint arXiv:2308.08493,
- [3]
- [5]
-
[7]
Panickssery, N., Gabrieli, N., Schulz, J., Tong, M., Hubinger, E., and Turner, A
URL https://arxiv.org/abs/2507.01786. Panickssery, N., Gabrieli, N., Schulz, J., Tong, M., Hubinger, E., and Turner, A. M. Steering llama 2 via contrastive activation addition.arXiv preprint arXiv:2312.06681,
-
[8]
Steering Llama 2 via Contrastive Activation Addition
URL https://arxiv.org/abs/2312.06681. Ravaut, M., Ding, B., Jiao, F., Chen, H., Li, X., Zhao, R., Qin, C., Xiong, C., and Joty, S. A comprehensive survey of contamination detection methods in large language models.arXiv preprint arXiv:2404.00699,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
URL https://arxiv.org/abs/2404.00699. 7 Representational Depth of Evaluation Awareness Shifts With Scale A. Dataset Details A.1. Jordine contrastive dataset We use the dataset released in the Jordinepivotal-test-phase-steeringrepository (Jordine,
-
[10]
Specifically, we usestages oversight for both white-box and black-box evaluation, and test full as a held-out baseline for the perplexity contamination diagnostic
for probe evaluation, black-box behavioural evaluation, and contamination diagnostics. Specifically, we usestages oversight for both white-box and black-box evaluation, and test full as a held-out baseline for the perplexity contamination diagnostic. SAD items are stored as structured question objects with fields including body, choices right, choices wro...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.