Beyond Trajectory Matching: Reflow with Marginal Distribution Alignment
Pith reviewed 2026-06-30 07:59 UTC · model grok-4.3
The pith
Trajectory matching under-determines endpoint marginals in reflow distillation, so a marginal-alignment regularizer is added to control final distribution discrepancy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Trajectory matching can under-determine the endpoint marginal distribution because two student models can attain the same trajectory-matching loss while inducing different endpoint marginal distributions. The marginal-alignment regularizer penalizes the discrepancy between the student-induced marginal and the corresponding teacher marginal at the endpoint of each distillation interval. The regularizer is computed by tracking log-density changes along the ODE induced by the student model and evaluating scores from the frozen teacher model. The framework applies uniformly to the reflow family. A telescoping total-variation bound shows that local marginal alignment controls the final-time discr
What carries the argument
The marginal-alignment regularizer, which penalizes discrepancy between student-induced and teacher marginals at interval endpoints via log-density tracking along the student ODE using frozen teacher scores.
If this is right
- The approach applies uniformly to vanilla reflow and piecewise reflow without modification.
- Local marginal alignment at each interval controls final-time discrepancy through the telescoping total-variation bound.
- Few-step generation quality improves on benchmark backbones when the regularizer is included.
- No auxiliary trainable networks or adversarial optimization are required to compute the regularizer.
Where Pith is reading between the lines
- The same marginal-alignment idea could be tested on distillation methods outside the reflow family that also rely on ODE trajectory matching.
- The telescoping bound suggests that increasing the number of intervals while keeping per-interval alignment tight could systematically reduce final distribution error.
- In practice the method may allow fewer total distillation steps to reach a target distribution match compared to trajectory matching alone.
- The log-density tracking approach might be adapted to other settings where path matching must be supplemented by distribution-level constraints.
Load-bearing premise
The discrepancy between student-induced marginal and teacher marginal at interval endpoints can be accurately and stably computed by tracking log-density changes along the student ODE and evaluating scores from the frozen teacher without material approximation error.
What would settle it
Compare endpoint marginal discrepancy measured by total variation or similar metric between pure trajectory matching and the version with the added regularizer, while holding trajectory loss fixed, across multiple distillation intervals.
Figures

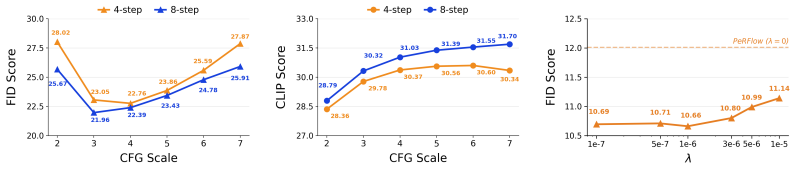
read the original abstract
Diffusion and continuous-flow generative models achieve high-quality generation, and their deterministic sampling can be formulated as solving learned ODE dynamics. However, accurate ODE discretization often requires many steps, making efficient few-step generation a key challenge. Among acceleration strategies, reflow-based distillation simplifies teacher ODE trajectories so that a student model can approximate the teacher transport with fewer steps. We identify a theoretical limitation of this paradigm, namely that trajectory matching can under-determine the distribution induced by the student model. In particular, two student models can attain the same trajectory-matching loss while inducing different endpoint marginal distributions, which may lead to different generation quality. To address this limitation, we introduce a marginal-alignment regularizer that penalizes the discrepancy between the student-induced marginal and the corresponding teacher marginal at the endpoint of each distillation interval. The regularizer is computed by tracking log-density changes along the ODE induced by the student model and evaluating scores from the frozen teacher model, without requiring auxiliary trainable networks or adversarial optimization. The resulting framework applies uniformly to the reflow family, including vanilla reflow and piecewise reflow. We further prove a telescoping total-variation bound showing that local marginal alignment controls the final-time discrepancy between the student-induced and teacher-induced distributions. Experiments on benchmark backbones demonstrate the effectiveness of the proposed method for few-step generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that standard trajectory matching in reflow distillation under-determines the endpoint marginal distribution induced by the student model, allowing different generation qualities despite equal losses. It introduces a marginal-alignment regularizer that penalizes discrepancy between student-induced and teacher marginals at each interval endpoint, computed by tracking log-density changes along the student ODE while querying frozen teacher scores (no auxiliary networks needed). The method applies to the reflow family, and a telescoping total-variation bound is proven to show that local marginal alignment controls final-time discrepancy. Experiments on benchmark backbones demonstrate improved few-step generation.
Significance. If the bound holds and the regularizer is stably computable, the work addresses a genuine under-determination issue in reflow-based acceleration of diffusion ODEs, offering a uniform, auxiliary-network-free improvement with a clean theoretical guarantee via the telescoping TV argument. The practical advantage of avoiding extra trainable components or adversarial training is notable, and the uniform applicability across reflow variants strengthens the contribution. However, the low soundness rating and absence of full derivation or error analysis in the available text limit the assessed impact.
major comments (2)
- [Abstract / Regularizer definition] Abstract and the description of the marginal-alignment regularizer: the central claim that local alignment controls final discrepancy via the telescoping TV bound assumes the regularizer exactly (or with controllable error) penalizes the true marginal discrepancy; the implementation via integration of the continuity equation (log-density evolution = -div(v_student)) along student trajectories with frozen teacher scores supplies no error analysis, stability guarantee, or quantification of numerical quadrature/divergence-approximation errors, which directly risks invalidating the premise of the bound.
- [Proof of telescoping TV bound] The weakest assumption identified (accurate and stable computation of discrepancy without material approximation error) is load-bearing for both the regularizer and the bound; without explicit controls or empirical verification of integration accuracy, the theoretical guarantee does not yet follow from the construction.
minor comments (1)
- [Abstract] The abstract states the method works 'without requiring auxiliary trainable networks,' but the manuscript should clarify whether the log-density tracking step introduces any model-specific assumptions (e.g., on score estimation or ODE discretization) that could affect generality.
Simulated Author's Rebuttal
We thank the referee for the thorough review and for identifying key points regarding the numerical aspects of the marginal-alignment regularizer and the telescoping TV bound. We address each major comment below and will incorporate revisions to strengthen the manuscript's presentation of the implementation and its connection to the theory.
read point-by-point responses
-
Referee: [Abstract / Regularizer definition] the central claim assumes the regularizer exactly (or with controllable error) penalizes the true marginal discrepancy; the implementation via integration of the continuity equation supplies no error analysis, stability guarantee, or quantification of numerical quadrature/divergence-approximation errors
Authors: We agree that the manuscript lacks explicit error analysis for the numerical computation of log-density evolution. The regularizer follows directly from the continuity equation, which is exact in the continuous limit. In the discrete implementation we employ standard numerical quadrature and divergence estimation along trajectories. We will revise the paper to add a dedicated subsection discussing the numerical scheme, sources of approximation error, and empirical checks (e.g., consistency of the computed regularizer values across different step sizes and quadrature orders on the reported benchmarks). This will clarify the practical accuracy of the regularizer relative to the scale of the observed discrepancies. revision: yes
-
Referee: [Proof of telescoping TV bound] The weakest assumption (accurate and stable computation of discrepancy without material approximation error) is load-bearing; without explicit controls or empirical verification of integration accuracy, the theoretical guarantee does not yet follow from the construction
Authors: The telescoping TV bound is derived exactly under the assumption that the marginal discrepancies are measured without error. We acknowledge that the current text does not quantify how numerical errors in the regularizer propagate into the bound. In the revision we will (i) state the bound with an additive term that absorbs bounded approximation error and (ii) include empirical evidence that the numerical errors remain small compared with the magnitude of the regularizer on the evaluated models. These additions will make the link between the implemented regularizer and the theoretical guarantee explicit. revision: yes
Circularity Check
No circularity: regularizer and bound defined externally via teacher scores and ODE dynamics
full rationale
The paper's core construction defines the marginal-alignment regularizer directly from the continuity equation along student trajectories and frozen teacher scores (no self-definition or fitted-input renaming). The telescoping TV bound is a separate mathematical inequality whose premise is the true marginal discrepancy, not a quantity constructed from the loss itself. No self-citation load-bearing steps, uniqueness theorems, or ansatz smuggling appear in the derivation chain. The method is presented as a uniform extension of reflow without reducing the claimed improvement to an input by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Existence, uniqueness, and sufficient regularity of solutions to the learned ODE dynamics for both teacher and student models.
Reference graph
Works this paper leans on
-
[1]
Stochastic interpolants: A unifying framework for flows and diffusions.Journal of Machine Learning Research, 26(209): 1–80, 2025
Michael Albergo, Nicholas M Boffi, and Eric Vanden-Eijnden. Stochastic interpolants: A unifying framework for flows and diffusions.Journal of Machine Learning Research, 26(209): 1–80, 2025
2025
-
[2]
Align your latents: High-resolution video synthesis with latent diffusion models
Andreas Blattmann, Robin Rombach, Huan Ling, Tim Dockhorn, Seung Wook Kim, Sanja Fidler, and Karsten Kreis. Align your latents: High-resolution video synthesis with latent diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22563–22575, 2023
2023
-
[3]
Instructpix2pix: Learning to follow image editing instructions
Tim Brooks, Aleksander Holynski, and Alexei A Efros. Instructpix2pix: Learning to follow image editing instructions. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18392–18402, 2023
2023
-
[4]
Flash diffusion: Accel- erating any conditional diffusion model for few steps image generation
Clement Chadebec, Onur Tasar, Eyal Benaroche, and Benjamin Aubin. Flash diffusion: Accel- erating any conditional diffusion model for few steps image generation. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 15686–15695, 2025
2025
-
[5]
Neural ordinary differential equations.Advances in Neural Information Processing Systems, 31, 2018
Ricky TQ Chen, Yulia Rubanova, Jesse Bettencourt, and David K Duvenaud. Neural ordinary differential equations.Advances in Neural Information Processing Systems, 31, 2018
2018
-
[6]
Flow matching in latent space.arXiv preprint arXiv:2307.08698, 2023
Quan Dao, Hao Phung, Binh Nguyen, and Anh Tran. Flow matching in latent space.arXiv preprint arXiv:2307.08698, 2023
-
[7]
One step diffusion via shortcut models
Kevin Frans, Danijar Hafner, Sergey Levine, and Pieter Abbeel. One step diffusion via shortcut models. InInternational Conference on Learning Representations, 2025
2025
-
[8]
Ffjord: Free-form continuous dynamics for scalable reversible generative models
Will Grathwohl, Ricky TQ Chen, Jesse Bettencourt, Ilya Sutskever, and David Duvenaud. Ffjord: Free-form continuous dynamics for scalable reversible generative models. InInternational Conference on Learning Representations, 2019
2019
-
[9]
Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in Neural Information Processing Systems, 30, 2017
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in Neural Information Processing Systems, 30, 2017
2017
-
[10]
Denoising diffusion probabilistic models.Advances in Neural Information Processing Systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in Neural Information Processing Systems, 33:6840–6851, 2020
2020
-
[11]
Video diffusion models.Advances in Neural Information Processing Systems, 35:8633–8646, 2022
Jonathan Ho, Tim Salimans, Alexey Gritsenko, William Chan, Mohammad Norouzi, and David J Fleet. Video diffusion models.Advances in Neural Information Processing Systems, 35:8633–8646, 2022. 10
2022
-
[12]
Elucidating the design space of diffusion-based generative models.Advances in Neural Information Processing Systems, 35: 26565–26577, 2022
Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine. Elucidating the design space of diffusion-based generative models.Advances in Neural Information Processing Systems, 35: 26565–26577, 2022
2022
-
[13]
Bk-sdm: A lightweight, fast, and cheap version of stable diffusion
Bo-Kyeong Kim, Hyoung-Kyu Song, Thibault Castells, and Shinkook Choi. Bk-sdm: A lightweight, fast, and cheap version of stable diffusion. InEuropean Conference on Computer Vision, pages 381–399, 2024
2024
-
[14]
Consistency trajectory models: Learning probability flow ode trajectory of diffusion
Dongjun Kim, Chieh-Hsin Lai, Wei-Hsiang Liao, Naoki Murata, Yuhta Takida, Toshimitsu Uesaka, Yutong He, Yuki Mitsufuji, and Stefano Ermon. Consistency trajectory models: Learning probability flow ode trajectory of diffusion. InInternational Conference on Learning Representations, 2024
2024
-
[15]
Understanding diffusion objectives as the elbo with simple data augmentation.Advances in Neural Information Processing Systems, 36:65484–65516, 2023
Diederik Kingma and Ruiqi Gao. Understanding diffusion objectives as the elbo with simple data augmentation.Advances in Neural Information Processing Systems, 36:65484–65516, 2023
2023
-
[16]
Variational diffusion models
Diederik Kingma, Tim Salimans, Ben Poole, and Jonathan Ho. Variational diffusion models. Advances in Neural Information Processing Systems, 34:21696–21707, 2021
2021
-
[17]
Improving the training of rectified flows.Advances in Neural Information Processing Systems, 37:63082–63109, 2024
Sangyun Lee, Zinan Lin, and Giulia Fanti. Improving the training of rectified flows.Advances in Neural Information Processing Systems, 37:63082–63109, 2024
2024
-
[18]
SDXL-Lightning: Progressive Adversarial Diffusion Distillation
Shanchuan Lin, Anran Wang, and Xiao Yang. Sdxl-lightning: Progressive adversarial diffusion distillation.arXiv preprint arXiv:2402.13929, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. InEuropean Conference on Computer Vision, pages 740–755, 2014
2014
-
[20]
Flow matching for generative modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling. InInternational Conference on Learning Representations, 2023
2023
-
[21]
Flow straight and fast: Learning to generate and transfer data with rectified flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. InInternational Conference on Learning Representations, 2023
2023
-
[22]
Instaflow: One step is enough for high-quality diffusion-based text-to-image generation
Xingchao Liu, Xiwen Zhang, Jianzhu Ma, Jian Peng, et al. Instaflow: One step is enough for high-quality diffusion-based text-to-image generation. InInternational Conference on Learning Representations, 2023
2023
-
[23]
Simplifying, stabilizing and scaling continuous-time consistency models
Cheng Lu and Yang Song. Simplifying, stabilizing and scaling continuous-time consistency models. InInternational Conference on Learning Representations, 2025
2025
-
[24]
Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps.Advances in Neural Information Processing Systems, 35:5775–5787, 2022
Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu. Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps.Advances in Neural Information Processing Systems, 35:5775–5787, 2022
2022
-
[25]
Dpm-solver++: Fast solver for guided sampling of diffusion probabilistic models.Machine Intelligence Re- search, 22(4):730–751, 2025
Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu. Dpm-solver++: Fast solver for guided sampling of diffusion probabilistic models.Machine Intelligence Re- search, 22(4):730–751, 2025
2025
-
[26]
Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference
Simian Luo, Yiqin Tan, Longbo Huang, Jian Li, and Hang Zhao. Latent consistency models: Synthesizing high-resolution images with few-step inference.arXiv preprint arXiv:2310.04378, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[27]
Lcm-lora: A universal stable-diffusion acceleration module,
Simian Luo, Yiqin Tan, Suraj Patil, Daniel Gu, Patrick V on Platen, Apolinário Passos, Longbo Huang, Jian Li, and Hang Zhao. Lcm-lora: A universal stable-diffusion acceleration module. arXiv preprint arXiv:2311.05556, 2023
-
[28]
Diff- instruct: A universal approach for transferring knowledge from pre-trained diffusion models
Weijian Luo, Tianyang Hu, Shifeng Zhang, Jiacheng Sun, Zhenguo Li, and Zhihua Zhang. Diff- instruct: A universal approach for transferring knowledge from pre-trained diffusion models. Advances in Neural Information Processing Systems, 36:76525–76546, 2023. 11
2023
-
[29]
Sdedit: Guided image synthesis and editing with stochastic differential equations
Chenlin Meng, Yutong He, Yang Song, Jiaming Song, Jiajun Wu, Jun-Yan Zhu, and Stefano Ermon. Sdedit: Guided image synthesis and editing with stochastic differential equations. In International Conference on Learning Representations, 2022
2022
-
[30]
Sdxl: Improving latent diffusion models for high-resolution image synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis. InInternational Conference on Learning Representations, 2024
2024
-
[31]
Dreamfusion: Text-to-3d using 2d diffusion
Ben Poole, Ajay Jain, Jonathan T Barron, and Ben Mildenhall. Dreamfusion: Text-to-3d using 2d diffusion. InInternational Conference on Learning Representations, 2023
2023
-
[32]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational Conference on Machine Learning, pages 8748–8763, 2021
2021
-
[33]
Hyper-sd: Trajectory segmented consistency model for efficient image synthesis.Advances in Neural Information Processing Systems, 37:117340–117362, 2024
Yuxi Ren, Xin Xia, Yanzuo Lu, Jiacheng Zhang, Jie Wu, Pan Xie, Xing Wang, and Xuefeng Xiao. Hyper-sd: Trajectory segmented consistency model for efficient image synthesis.Advances in Neural Information Processing Systems, 37:117340–117362, 2024
2024
-
[34]
High- resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High- resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10684–10695, 2022
2022
-
[35]
Progressive distillation for fast sampling of diffusion models
Tim Salimans and Jonathan Ho. Progressive distillation for fast sampling of diffusion models. InInternational Conference on Learning Representations, 2022
2022
-
[36]
Fast high-resolution image synthesis with latent adversarial diffusion distillation
Axel Sauer, Frederic Boesel, Tim Dockhorn, Andreas Blattmann, Patrick Esser, and Robin Rombach. Fast high-resolution image synthesis with latent adversarial diffusion distillation. In SIGGRAPH Asia 2024 Conference Papers, pages 1–11, 2024
2024
-
[37]
Adversarial diffusion distillation
Axel Sauer, Dominik Lorenz, Andreas Blattmann, and Robin Rombach. Adversarial diffusion distillation. InEuropean Conference on Computer Vision, pages 87–103, 2024
2024
-
[38]
Laion- 5b: An open large-scale dataset for training next generation image-text models.Advances in Neural Information Processing Systems, 35:25278–25294, 2022
Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Wortsman, et al. Laion- 5b: An open large-scale dataset for training next generation image-text models.Advances in Neural Information Processing Systems, 35:25278–25294, 2022
2022
-
[39]
Denoising diffusion implicit models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. In International Conference on Learning Representations, 2021
2021
-
[40]
Score-based generative modeling through stochastic differential equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. In International Conference on Learning Representations, 2021
2021
-
[41]
Consistency models
Yang Song, Prafulla Dhariwal, Mark Chen, and Ilya Sutskever. Consistency models. In International Conference on Machine Learning, pages 32211–32252, 2023
2023
-
[42]
Phased consistency models.Advances in Neural Information Processing Systems, 37:83951–84009, 2024
Fu-Yun Wang, Zhaoyang Huang, Alexander W Bergman, Dazhong Shen, Peng Gao, Michael Lingelbach, Keqiang Sun, Weikang Bian, Guanglu Song, Yu Liu, et al. Phased consistency models.Advances in Neural Information Processing Systems, 37:83951–84009, 2024
2024
-
[43]
Rectified diffusion: Straightness is not your need in rectified flow
Fu-Yun Wang, Ling Yang, Zhaoyang Huang, Mengdi Wang, and Hongsheng Li. Rectified diffusion: Straightness is not your need in rectified flow. InInternational Conference on Learning Representations, 2025
2025
-
[44]
Pro- lificdreamer: High-fidelity and diverse text-to-3d generation with variational score distillation
Zhengyi Wang, Cheng Lu, Yikai Wang, Fan Bao, Chongxuan Li, Hang Su, and Jun Zhu. Pro- lificdreamer: High-fidelity and diverse text-to-3d generation with variational score distillation. Advances in Neural Information Processing Systems, 36:8406–8441, 2023
2023
-
[45]
Normalizing flow neural networks by jko scheme
Chen Xu, Xiuyuan Cheng, and Yao Xie. Normalizing flow neural networks by jko scheme. Advances in Neural Information Processing Systems, 36:47379–47405, 2023. 12
2023
-
[46]
Perflow: Piecewise rectified flow as universal plug-and-play accelerator.Advances in Neural Information Processing Systems, 37:78630–78652, 2024
Hanshu Yan, Xingchao Liu, Jiachun Pan, Jun Hao Liew, Qiang Liu, and Jiashi Feng. Perflow: Piecewise rectified flow as universal plug-and-play accelerator.Advances in Neural Information Processing Systems, 37:78630–78652, 2024
2024
-
[47]
Improved distribution matching distillation for fast image synthesis
Tianwei Yin, Michaël Gharbi, Taesung Park, Richard Zhang, Eli Shechtman, Fredo Durand, and William T Freeman. Improved distribution matching distillation for fast image synthesis. Advances in Neural Information Processing Systems, 37:47455–47487, 2024
2024
-
[48]
Tianwei Yin, Michaël Gharbi, Richard Zhang, Eli Shechtman, Fredo Durand, William T Freeman, and Taesung Park. One-step diffusion with distribution matching distillation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6613–6623, 2024. 13 A Proofs A.1 Standing Assumptions The following assumptions are used throug...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.