FiRe: Frequency Reparameterization as a Preconditioner for Periodic Implicit Neural Representations
Pith reviewed 2026-06-30 08:01 UTC · model grok-4.3
The pith
FiRe gives each neuron in periodic INRs its own bounded input-dependent frequency through a low-rank gate that preconditions the Neural Tangent Kernel.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
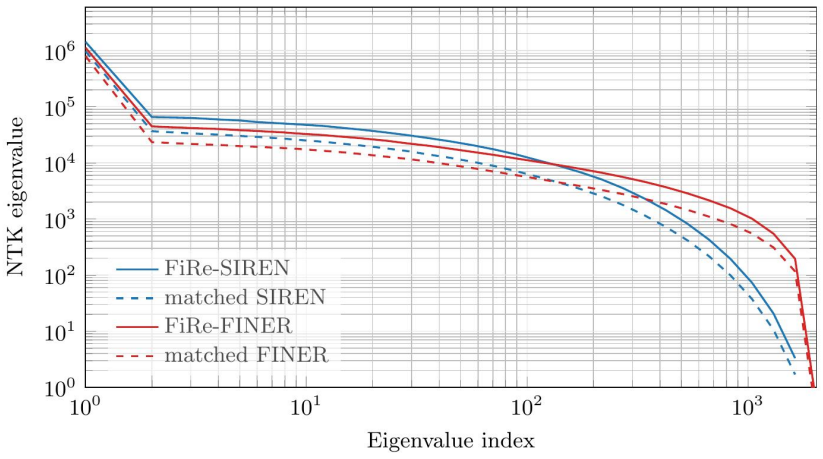
FiRe reparameterizes the frequency of each neuron in any periodic INR by routing the input through a separate low-rank gating path that produces a bounded, input-dependent frequency multiplier; the gate functions as an implicit preconditioner that raises the smallest eigenvalues of the Neural Tangent Kernel at initialization, yielding faster convergence and closer tracking of high-frequency target content without modifying the underlying activation function.
What carries the argument
The low-rank gating path that produces a bounded, input-dependent frequency multiplier for each neuron.
If this is right
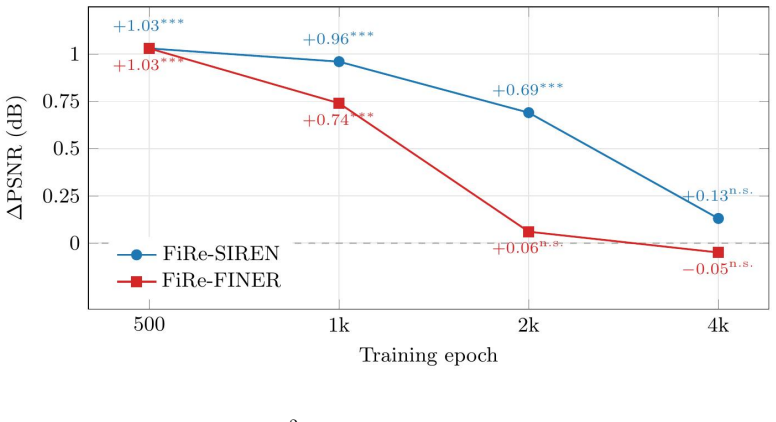
- Optimization of periodic INRs reaches a given reconstruction quality in fewer steps.
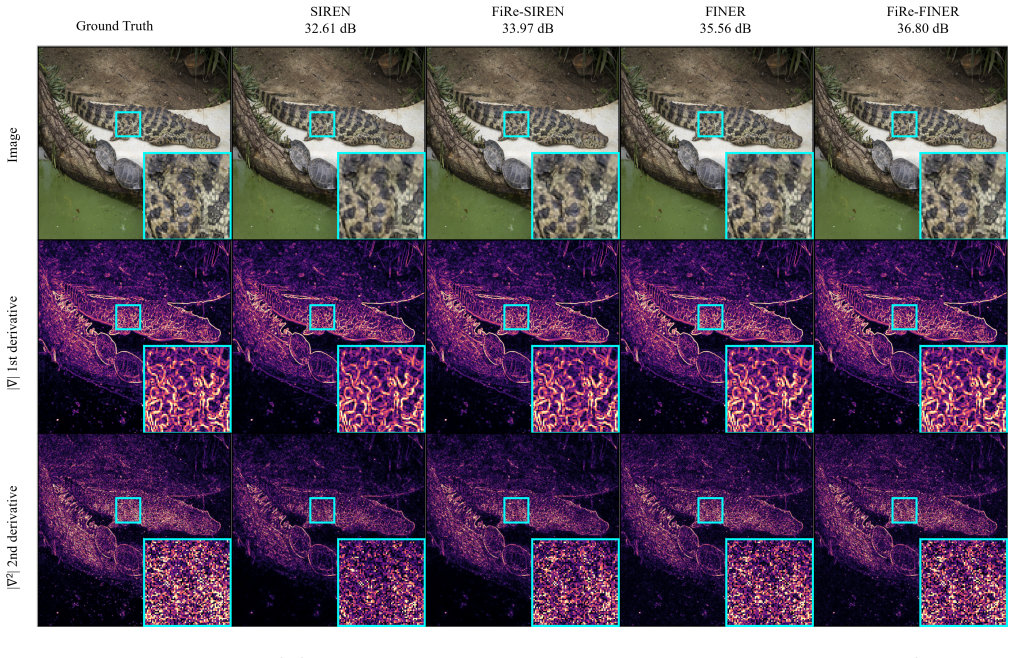
- High-frequency components of the target signal are recovered earlier in training.
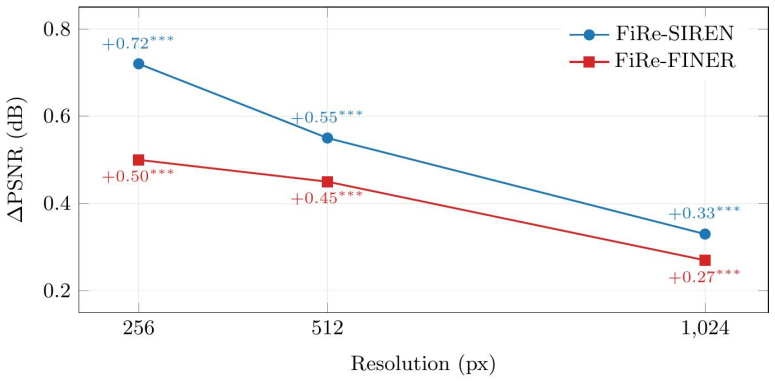
- PSNR gains of up to 1 dB appear on 2D image fitting tasks when training budgets are short.
- The size of the gains changes with image resolution and with the rank chosen for the gate.
- The advantage shrinks once training continues until full convergence.
Where Pith is reading between the lines
- The same low-rank frequency modulation could be attached to other periodic activations beyond those tested.
- Similar preconditioning effects might appear if the gate were replaced by any mechanism that locally rescales the frequency scale at initialization.
- The resolution dependence suggests that FiRe may be most useful for fitting signals whose frequency content varies sharply across space.
Load-bearing premise
The low-rank gate improves Neural Tangent Kernel conditioning specifically at initialization, and this conditioning improvement (rather than extra parameters or altered initialization variance) is what produces the measured speed-up and better high-frequency tracking.
What would settle it
An experiment in which the input dependence is removed from the gate while the total parameter count and initialization statistics are held fixed, yet the early-training PSNR advantage and NTK eigenvalue distribution both disappear.
Figures
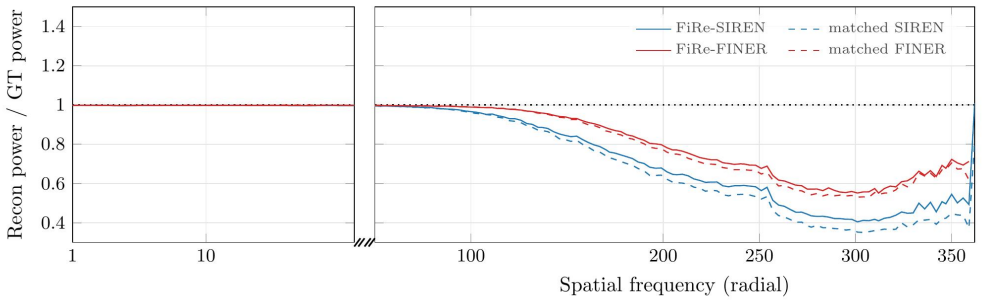



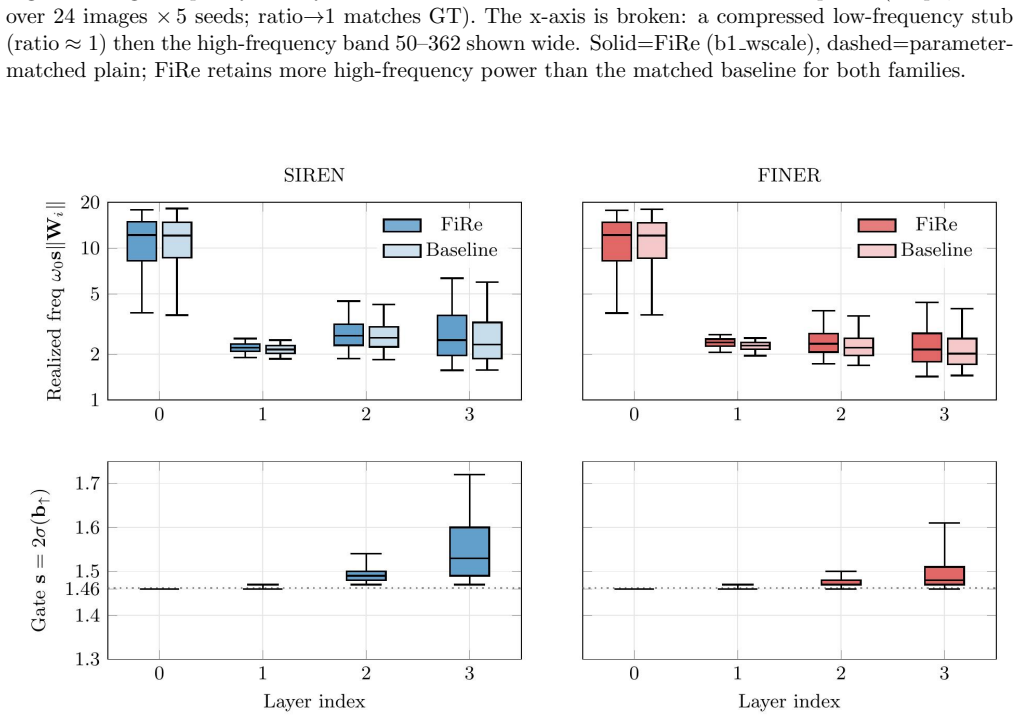

read the original abstract
Periodic Implicit Neural Representations (INRs) such as SIREN and FINER assign every neuron, the same global frequency, spending the representational budget inefficiently when local signal content varies. We introduce FiRe (Frequency Reparameterization), that accelerates optimization by reparameterizing per-neuron frequency of periodic INRs without changing their underlying activation function. FiRe gives each neuron a bounded, input-dependent frequency via a separate low-rank gating path and is applicable to any periodic activation function. The gate acts as an implicit preconditioner that improves optimization conditioning at initialization via the Neural Tangent Kernel (NTK). This better-conditioned initialization makes optimization converge faster, and the high-frequency content of the reconstruction tracks the target more closely at a fixed computational budget. On 2D image fitting, FiRe increases PSNR over a parameter-matched baseline (up to +1 dB at short training budgets), with gains that vary with resolution and diminish at full convergence. We characterize how performance depends on resolution, rank, and training budget, and give an NTK account that predicts these trends.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FiRe, a frequency reparameterization for periodic INRs (e.g., SIREN, FINER) that assigns each neuron a bounded, input-dependent frequency via a separate low-rank gating path without changing the underlying activation. The gate is claimed to act as an implicit preconditioner that improves NTK conditioning at initialization, yielding faster convergence and closer high-frequency tracking at fixed budgets. On 2D image fitting, it reports up to +1 dB PSNR gains over a parameter-matched baseline, with performance characterized as depending on resolution, rank, and training budget; an NTK account is given to predict these trends.
Significance. If the central mechanism holds, FiRe would provide a general, activation-agnostic way to improve optimization conditioning in periodic INRs, with practical value for short-budget signal fitting tasks. The low-rank design and cross-resolution characterization are strengths, and the NTK framing offers a potential route to principled INR design if the conditioning claim is verified.
major comments (2)
- [NTK account and experimental results] The central claim that the low-rank gating path improves NTK conditioning specifically at initialization (and that this drives the observed +1 dB gains) is load-bearing, yet the manuscript does not report explicit condition-number or eigenvalue-spread measurements of the NTK matrix for FiRe networks versus the parameter-matched baseline at t=0. Without these direct diagnostics on the actual experimental architectures, alternative explanations (altered frequency-parameter variance or auxiliary capacity from the gating path) cannot be ruled out.
- [NTK account] The NTK account is described as predicting the observed trends with resolution and budget, but the manuscript does not state whether the NTK derivation was performed independently before seeing the PSNR curves or was constructed post-hoc to match them; this affects the strength of the mechanistic explanation.
minor comments (1)
- [Abstract and experiments] The abstract states applicability to any periodic activation function, but the experimental section should explicitly list which activations beyond SIREN/FINER were tested to support the generality claim.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for identifying the points that require stronger empirical and procedural clarification. We respond to each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [NTK account and experimental results] The central claim that the low-rank gating path improves NTK conditioning specifically at initialization (and that this drives the observed +1 dB gains) is load-bearing, yet the manuscript does not report explicit condition-number or eigenvalue-spread measurements of the NTK matrix for FiRe networks versus the parameter-matched baseline at t=0. Without these direct diagnostics on the actual experimental architectures, alternative explanations (altered frequency-parameter variance or auxiliary capacity from the gating path) cannot be ruled out.
Authors: We agree that direct NTK diagnostics at initialization would strengthen the mechanistic claim. The current manuscript relies on the closed-form NTK derivation for the gated architecture to argue improved conditioning, but does not report numerical condition numbers or eigenvalue spreads on the exact networks used in the 2D experiments. In the revision we will add these measurements (or a feasible approximation thereof) for FiRe versus the parameter-matched baseline at t=0, together with a brief discussion of why the low-rank gating is unlikely to act merely through auxiliary capacity or variance changes. revision: yes
-
Referee: [NTK account] The NTK account is described as predicting the observed trends with resolution and budget, but the manuscript does not state whether the NTK derivation was performed independently before seeing the PSNR curves or was constructed post-hoc to match them; this affects the strength of the mechanistic explanation.
Authors: The NTK analysis was derived from the architectural change (low-rank input-dependent frequency scaling) prior to running the full resolution-and-budget sweeps; the theory indicated the expected dependence on input resolution and training horizon, which the experiments then confirmed. We will add an explicit statement of this chronology in the revised manuscript. revision: yes
Circularity Check
No significant circularity detected in the derivation chain
full rationale
The paper presents FiRe as a low-rank gating reparameterization that supplies bounded input-dependent frequencies to periodic INRs, asserts that the gate functions as an implicit NTK preconditioner at initialization, and supplies an NTK account that predicts the reported resolution- and budget-dependent PSNR trends. No quoted equations, self-citations, or steps reduce the central claim (faster convergence from improved conditioning) to a fitted parameter renamed as a prediction, a self-definitional loop, or a load-bearing citation chain whose premises already embed the target result. The NTK account is offered as an independent explanatory derivation rather than a post-hoc statistical fit, and the empirical comparisons are against explicitly parameter-matched baselines. The derivation therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- rank of gating path
axioms (1)
- domain assumption Neural Tangent Kernel theory applies directly to the reparameterized periodic network and predicts optimization behavior from initialization conditioning
invented entities (1)
-
low-rank input-dependent gating path
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Ntire 2017 challenge on single image super-resolution: Dataset and study
Eirikur Agustsson and Radu Timofte. Ntire 2017 challenge on single image super-resolution: Dataset and study. InProceedings of the IEEE conference on computer vision and pattern recognition workshops, pages 126–135,
2017
-
[2]
FM-SIREN & FM-FINER: Implicit Neural Representation Using Nyquist-based Orthogonality
Mohammed Alsakabi, Wael Mobeirek, John M Dolan, and Ozan K Tonguz. FM-SIREN & FM-FINER: Implicit neural representation using Nyquist-based orthogonality.arXiv preprint arXiv:2509.23438, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Implicit regularization in deep matrix factorization
Sanjeev Arora, Nadav Cohen, Wei Hu, and Yuping Luo. Implicit regularization in deep matrix factorization. Advances in Neural Information Processing Systems, 32, 2019. 1, 2
2019
-
[4]
Learning implicit fields for generative shape modeling
Zhiqin Chen and Hao Zhang. Learning implicit fields for generative shape modeling. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5939–5948, 2019. 2
2019
-
[5]
Multiplicative filter networks
Rizal Fathony, Anit Kumar Sahu, Devin Willmott, and J Zico Kolter. Multiplicative filter networks. In International Conference on Learning Representations, 2021. 2
2021
-
[6]
SASNet: Spatially-adaptive sinusoidal networks for INRs
Haoan Feng, Diana Aldana, Tiago Novello, and Leila De Floriani. SASNet: Spatially-adaptive sinusoidal networks for INRs. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 41964–41973, 2026. 2
2026
-
[7]
Implicit geometric regularization for learning shapes
Amos Gropp, Lior Yariv, Niv Haim, Matan Atzmon, and Yaron Lipman. Implicit geometric regularization for learning shapes. InInternational Conference on Machine Learning, pages 3747–3757. PMLR, 2020. 2
2020
-
[8]
LoRA: Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. InInternational Conference on Learning Representations, 2022. 3
2022
-
[9]
Neural tangent kernel: Convergence and generalization in neural networks.Advances in Neural Information Processing Systems, 31, 2018
Arthur Jacot, Franck Gabriel, and Cl´ ement Hongler. Neural tangent kernel: Convergence and generalization in neural networks.Advances in Neural Information Processing Systems, 31, 2018. 1, 2
2018
-
[10]
Finer: Flexible spectral-bias tuning in implicit neural representation by variable-periodic activation functions
Zhen Liu, Hao Zhu, Qi Zhang, Jingde Fu, Weibing Deng, Zhan Ma, Yanwen Guo, and Xun Cao. Finer: Flexible spectral-bias tuning in implicit neural representation by variable-periodic activation functions. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2713–2722, 2024. 1, 2
2024
-
[11]
Occupancy networks: Learning 3D reconstruction in function space
Lars Mescheder, Michael Oechsle, Michael Niemeyer, Sebastian Nowozin, and Andreas Geiger. Occupancy networks: Learning 3D reconstruction in function space. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4460–4470, 2019. 2 11
2019
-
[12]
NeRF: Representing scenes as neural radiance fields for view synthesis.Communications of the ACM, 65(1):99– 106, 2021
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. NeRF: Representing scenes as neural radiance fields for view synthesis.Communications of the ACM, 65(1):99– 106, 2021. 2
2021
-
[13]
Instant neural graphics primitives with a multiresolution hash encoding.ACM Transactions on Graphics, 41(4):1–15, 2022
Thomas M¨ uller, Alex Evans, Christoph Schied, and Alexander Keller. Instant neural graphics primitives with a multiresolution hash encoding.ACM Transactions on Graphics, 41(4):1–15, 2022. 2
2022
-
[14]
Differentiable volumetric rendering: Learning implicit 3D representations without 3D supervision
Michael Niemeyer, Lars Mescheder, Michael Oechsle, and Andreas Geiger. Differentiable volumetric rendering: Learning implicit 3D representations without 3D supervision. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3504–3515, 2020. 2
2020
-
[15]
DeepSDF: Learning continuous signed distance functions for shape representation
Jeong Joon Park, Peter Florence, Julian Straub, Richard Newcombe, and Steven Lovegrove. DeepSDF: Learning continuous signed distance functions for shape representation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 165–174, 2019. 2
2019
-
[16]
On the spectral bias of neural networks
Nasim Rahaman, Aristide Baratin, Devansh Arpit, Felix Draxler, Min Lin, Fred Hamprecht, Yoshua Bengio, and Aaron Courville. On the spectral bias of neural networks. InInternational Conference on Machine Learning, pages 5301–5310. PMLR, 2019. 1, 2
2019
-
[17]
Beyond periodicity: Towards a unifying framework for activations in coordinate-MLPs
Sameera Ramasinghe and Simon Lucey. Beyond periodicity: Towards a unifying framework for activations in coordinate-MLPs. InEuropean Conference on Computer Vision, pages 142–158. Springer, 2022. 2
2022
-
[18]
SL2A-INR: Single-layer learnable activation for implicit neural representation
Reza Rezaeian, Moein Heidari, Reza Azad, Dorit Merhof, Hamid Soltanian-Zadeh, and Ilker Hacihaliloglu. SL2A-INR: Single-layer learnable activation for implicit neural representation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 26065–26074, 2025. 2
2025
-
[19]
Weight normalization: A simple reparameterization to accelerate training of deep neural networks.Advances in Neural Information Processing Systems, 29, 2016
Tim Salimans and Durk P Kingma. Weight normalization: A simple reparameterization to accelerate training of deep neural networks.Advances in Neural Information Processing Systems, 29, 2016. 1, 2
2016
-
[20]
WIRE: Wavelet implicit neural representations
Vishwanath Saragadam, Daniel LeJeune, Jasper Tan, Guha Balakrishnan, Ashok Veeraraghavan, and Richard G Baraniuk. WIRE: Wavelet implicit neural representations. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18507–18516, 2023. 2
2023
-
[21]
Improved implicit neural representation with Fourier reparam- eterized training
Kexuan Shi, Xingyu Zhou, and Shuhang Gu. Improved implicit neural representation with Fourier reparam- eterized training. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 25985–25994, 2024. 3
2024
-
[22]
Implicit neural representations with periodic activation functions.Advances in Neural Information Processing Systems, 33:7462– 7473, 2020
Vincent Sitzmann, Julien Martel, Alexander Bergman, David Lindell, and Gordon Wetzstein. Implicit neural representations with periodic activation functions.Advances in Neural Information Processing Systems, 33:7462– 7473, 2020. 1, 2, 3
2020
-
[23]
Scene representation networks: Continuous 3D- structure-aware neural scene representations.Advances in Neural Information Processing Systems, 32, 2019
Vincent Sitzmann, Michael Zollh¨ ofer, and Gordon Wetzstein. Scene representation networks: Continuous 3D- structure-aware neural scene representations.Advances in Neural Information Processing Systems, 32, 2019. 1, 2
2019
-
[24]
Fourier features let networks learn high frequency functions in low dimensional domains.Advances in Neural Information Processing Systems, 33:7537–7547, 2020
Matthew Tancik, Pratul Srinivasan, Ben Mildenhall, Sara Fridovich-Keil, Nithin Raghavan, Utkarsh Singhal, Ravi Ramamoorthi, Jonathan Barron, and Ren Ng. Fourier features let networks learn high frequency functions in low dimensional domains.Advances in Neural Information Processing Systems, 33:7537–7547, 2020. 2
2020
-
[25]
Hao Zhu, Zhen Liu, Qi Zhang, Jingde Fu, Weibing Deng, Zhan Ma, Yanwen Guo, and Xun Cao. FINER++: Building a family of variable-periodic functions for activating implicit neural representation.arXiv preprint arXiv:2407.19434, 2024. 2 12 A Extended Neural Tangent Kernel Analysis A.1 Setup and notation For a network outputf θ(x)∈Rand parametersθ, the empiric...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.