EvLIR: Learning Illumination Residuals from Ordered Events for Low-Light Image Enhancement
Pith reviewed 2026-06-30 07:48 UTC · model grok-4.3
The pith
Preserving the ordered temporal bins of event data allows a ConvGRU module to generate bounded illumination corrections that improve Retinex-based low-light image restoration.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
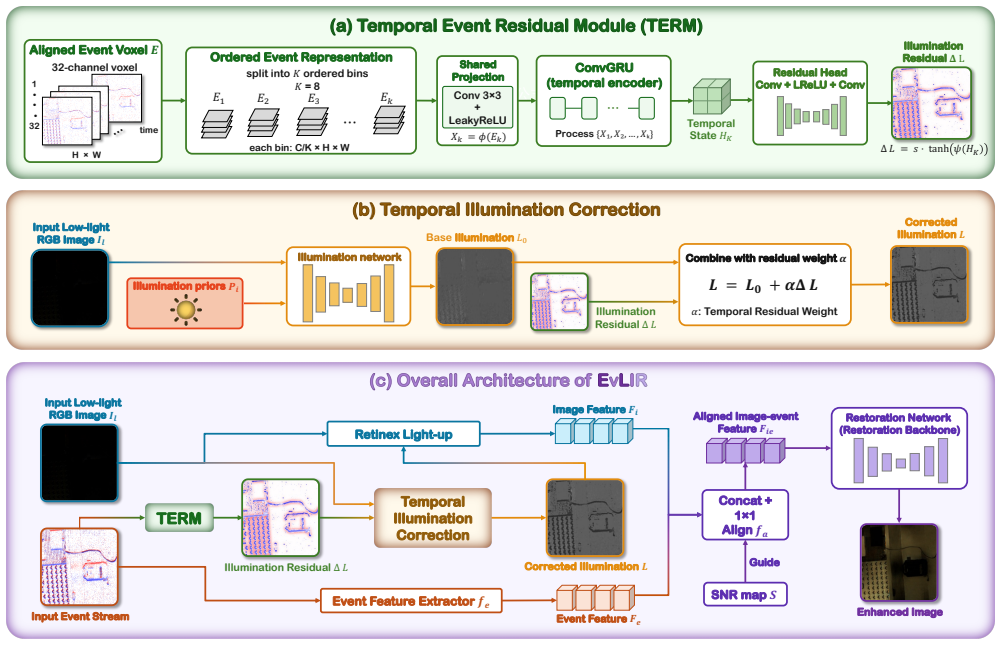
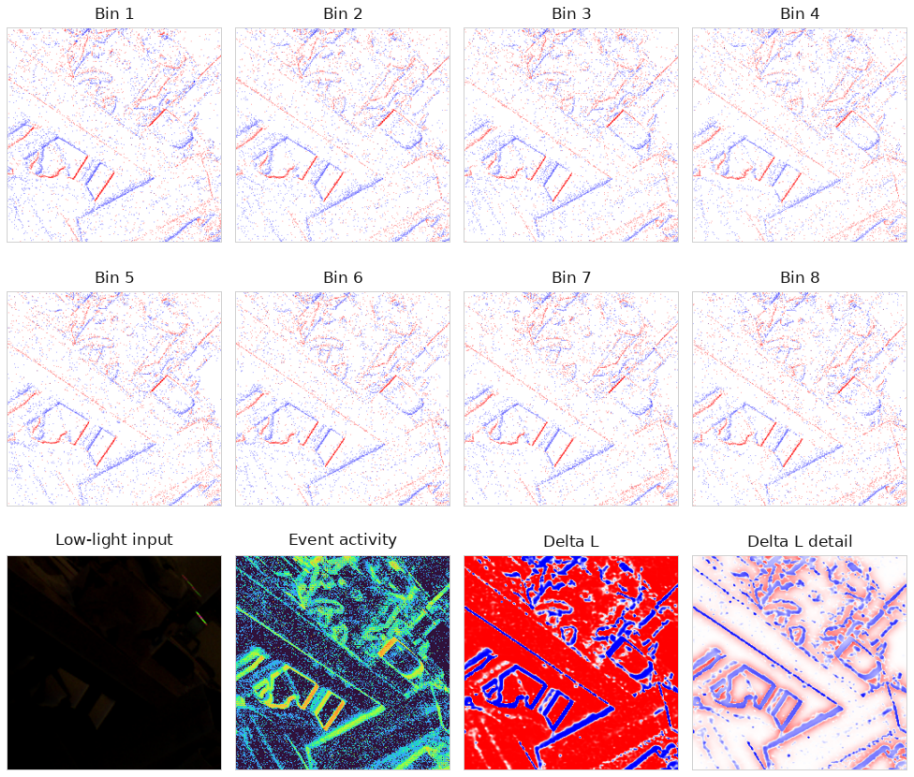
EvLIR preserves the ordered temporal bins of the event stream and introduces a Temporal Event Residual Module (TERM) to encode short-window event dynamics with a lightweight ConvGRU. The resulting temporal state is converted into a bounded illumination correction, which provides spatially adaptive photometric guidance for Retinex-style illumination estimation and subsequent reliability-aware image-event restoration.
What carries the argument
The Temporal Event Residual Module (TERM), which encodes ordered short-window event dynamics with a ConvGRU to produce a bounded illumination correction for Retinex estimation.
If this is right
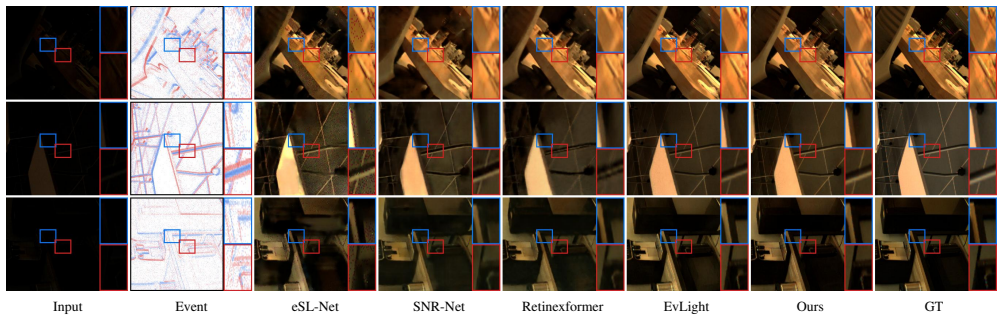
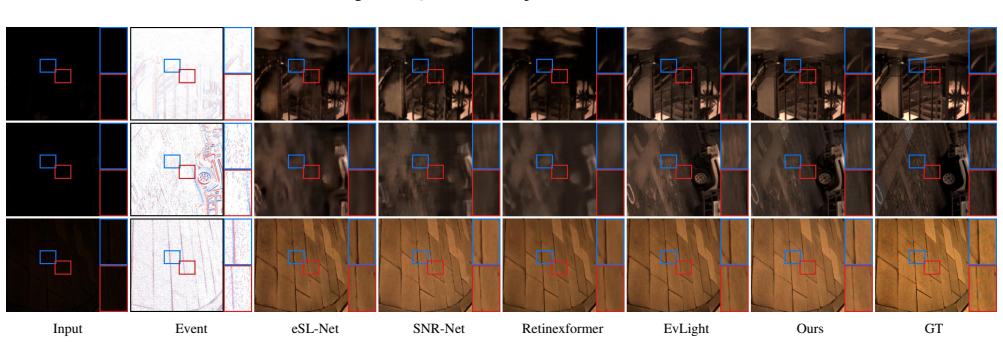
- The method records the best score on eleven of twelve dataset-metric pairs across SDE and SDSD indoor and outdoor sets.
- Average performance reaches 25.63 dB PSNR, 28.30 dB PSNR*, and 0.827 SSIM over the four benchmarks.
- The bounded correction supplies spatially adaptive photometric guidance that standard Retinex pipelines lack.
- Reliability-aware fusion of the image and event-derived correction reduces artifacts from saturated noise and missing structure.
Where Pith is reading between the lines
- The same ordered-event residual idea could be tested on video sequences to enforce temporal consistency across frames.
- Because the correction is bounded, the module might be inserted as a lightweight plug-in into existing Retinex networks without retraining the entire pipeline.
- Real-world event streams with higher noise or larger motion could be used to check whether the ConvGRU state remains stable outside the controlled benchmarks.
- The approach implies that event cameras could serve as an auxiliary sensor for mobile low-light capture rather than requiring new hardware.
Load-bearing premise
That keeping the ordered temporal bins of events and encoding them with a ConvGRU will produce a bounded illumination correction that meaningfully improves Retinex-style estimation.
What would settle it
An ablation that replaces the ordered TERM module with an unordered event stack and shows no gain or a drop in PSNR and SSIM on the SDE and SDSD benchmarks would falsify the claim.
Figures










read the original abstract
Low-light image enhancement is severely ill-posed when the input frame contains missing structure, saturated noise, and weak local contrast. Event cameras provide asynchronous brightness-change observations with high temporal resolution, but prior works often treat voxel channels as an unordered or static feature stack before fusion, rather than explicitly modeling their within-window temporal evolution, weakening the temporal evidence that makes events useful. We propose EvLIR, a temporal-residual enhancement framework that learns illumination residuals from ordered events for low-light image enhancement. Given a low-light frame and its aligned event voxel, EvLIR preserves the ordered temporal bins of the event stream and introduces a Temporal Event Residual Module (TERM) to encode short-window event dynamics with a lightweight ConvGRU. The resulting temporal state is converted into a bounded illumination correction, which provides spatially adaptive photometric guidance for Retinex-style illumination estimation and subsequent reliability-aware image-event restoration. On SDE and SDSD indoor/outdoor benchmarks, EvLIR achieves the best result on eleven of twelve dataset-metric pairs, with average scores of 25.63~dB PSNR, 28.30~dB PSNR*, and 0.827 SSIM across the four benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes EvLIR, a temporal-residual framework for low-light image enhancement that takes a low-light frame and aligned event voxel as input. It preserves the ordered temporal bins of the event stream and introduces a Temporal Event Residual Module (TERM) that encodes short-window dynamics via a lightweight ConvGRU; the resulting state is mapped to a bounded illumination correction that supplies spatially adaptive guidance to a Retinex-style estimator followed by reliability-aware restoration. On the SDE and SDSD indoor/outdoor benchmarks the method reports the best score on eleven of twelve dataset-metric pairs, with aggregate figures of 25.63 dB PSNR, 28.30 dB PSNR*, and 0.827 SSIM.
Significance. If the performance numbers are reproducible and the temporal modeling component is shown to be responsible for the gains, the work would supply a concrete mechanism for exploiting the high-temporal-resolution brightness-change signal of event cameras inside an illumination-estimation pipeline. The explicit use of ordered bins and a recurrent state (ConvGRU) distinguishes the approach from prior event-voxel methods that collapse the temporal axis before fusion.
major comments (2)
- [Experiments section] Ablation experiments (Experiments section): no table or figure isolates the contribution of ordered temporal bins plus ConvGRU inside TERM. A controlled comparison that (i) shuffles the temporal order, (ii) replaces ConvGRU with static aggregation, or (iii) disables the residual path while freezing the rest of the pipeline is required to attribute the reported 11/12 best scores to the stated mechanism rather than to the restoration network or training protocol.
- [§3] §3 (Method), TERM description: the conversion of the ConvGRU hidden state into a “bounded illumination correction” is asserted but the bounding operation, its range, and the precise way it is injected into the Retinex illumination estimator are not formalized (no equation or pseudocode). Without this, it is unclear whether the correction is a true residual or an arbitrary additive field.
minor comments (2)
- [Abstract] Abstract and §4: reported averages lack error bars or per-benchmark standard deviations; inclusion would strengthen the claim that the method is consistently superior across the four benchmarks.
- [Table 1] Figure captions and Table 1: dataset sizes (number of frames or sequences per indoor/outdoor split) and exact metric definitions (PSNR vs. PSNR*) should be stated explicitly for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight areas where the manuscript can be strengthened through additional experiments and formalization. We address each major comment below.
read point-by-point responses
-
Referee: [Experiments section] Ablation experiments (Experiments section): no table or figure isolates the contribution of ordered temporal bins plus ConvGRU inside TERM. A controlled comparison that (i) shuffles the temporal order, (ii) replaces ConvGRU with static aggregation, or (iii) disables the residual path while freezing the rest of the pipeline is required to attribute the reported 11/12 best scores to the stated mechanism rather than to the restoration network or training protocol.
Authors: We agree that the current manuscript does not include ablations that isolate the ordered temporal bins and ConvGRU within TERM. In the revised version we will add a dedicated ablation table in the Experiments section reporting results for (i) temporally shuffled event bins, (ii) replacement of ConvGRU by static aggregation (e.g., mean or max pooling across bins), and (iii) removal of the residual path while keeping the remainder of the pipeline fixed. These controlled comparisons will clarify the contribution of the temporal modeling components to the reported performance. revision: yes
-
Referee: [§3] §3 (Method), TERM description: the conversion of the ConvGRU hidden state into a “bounded illumination correction” is asserted but the bounding operation, its range, and the precise way it is injected into the Retinex illumination estimator are not formalized (no equation or pseudocode). Without this, it is unclear whether the correction is a true residual or an arbitrary additive field.
Authors: We acknowledge that the conversion step from the ConvGRU hidden state to the bounded illumination correction is described only at a high level and lacks equations. In the revised manuscript we will insert formal equations in Section 3 that define (a) the bounding function applied to the hidden state (including its explicit range), and (b) the precise additive injection of this correction into the Retinex illumination estimator. This will make explicit that the output functions as a spatially adaptive residual term. revision: yes
Circularity Check
No circularity; empirical architecture with no self-referential derivations
full rationale
The paper proposes a neural architecture (EvLIR with TERM module) that processes ordered event voxels via ConvGRU to produce an illumination residual for Retinex-style enhancement. No equations, uniqueness theorems, or derivations appear in the provided text that reduce any claimed output to a fitted input or self-citation by construction. Benchmark results (11/12 best scores on SDE/SDSD) are presented as empirical outcomes on external datasets, not as consequences of a closed definitional loop. The central mechanism is a designed module whose contribution would require ablation for attribution but does not exhibit circularity in its formulation.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Event voxels are temporally ordered and aligned with the input low-light frame
- domain assumption Retinex-style illumination estimation benefits from an external bounded correction derived from event dynamics
Reference graph
Works this paper leans on
-
[1]
A dynamic his- togram equalization for image contrast enhancement.IEEE transactions on consumer electronics, 53(2):593–600, 2007
Mohammad Abdullah-Al-Wadud, Md Hasanul Kabir, M Ali Akber Dewan, and Oksam Chae. A dynamic his- togram equalization for image contrast enhancement.IEEE transactions on consumer electronics, 53(2):593–600, 2007. 2
2007
-
[2]
A his- togram modification framework and its application for image contrast enhancement.IEEE Transactions on image process- ing, 18(9):1921–1935, 2009
Tarik Arici, Salih Dikbas, and Yucel Altunbasak. A his- togram modification framework and its application for image contrast enhancement.IEEE Transactions on image process- ing, 18(9):1921–1935, 2009. 2
1921
-
[3]
Drwkv: Focusing on object edges for low-light image en- hancement
Xuecheng Bai, Yuxiang Wang, Boyu Hu, Qinyuan Jie, Chuanzhi Xu, Kechen Li, Hongru Xiao, and Vera Chung. Drwkv: Focusing on object edges for low-light image en- hancement. InProceedings of the IEEE/CVF Winter Confer- ence on Applications of Computer Vision, pages 1554–1564,
-
[4]
Evrwkv: A continuous interactive rwkv frame- work for effective event-guided low-light image enhance- ment.IEEE Transactions on Circuits and Systems for Video Technology, 2026
Wenjie Cai, Qingguo Meng, Zhenyu Wang, Xingbo Dong, and Zhe Jin. Evrwkv: A continuous interactive rwkv frame- work for effective event-guided low-light image enhance- ment.IEEE Transactions on Circuits and Systems for Video Technology, 2026. 11
2026
-
[5]
Retinexformer: One-stage retinex- based transformer for low-light image enhancement
Yuanhao Cai, Hao Bian, Jing Lin, Haoqian Wang, Radu Tim- ofte, and Yulun Zhang. Retinexformer: One-stage retinex- based transformer for low-light image enhancement. InPro- ceedings of the IEEE/CVF international conference on com- puter vision, pages 12504–12513, 2023. 2, 5
2023
-
[6]
Contextual and variational contrast enhancement.IEEE Transactions on Image Process- ing, 20(12):3431–3441, 2011
Turgay Celik and Tardi Tjahjadi. Contextual and variational contrast enhancement.IEEE Transactions on Image Process- ing, 20(12):3431–3441, 2011. 2
2011
-
[7]
Fracevent: Event-camera simulation via fractional-relaxation pixel dynamics, 2026
Langyi Chen, Chuanzhi Xu, Haoxian Zhou, Pengfei Ye, Ziyu Luo, Haodong Chen, Qiang Qu, Xiaoming Chen, and Weidong Cai. Fracevent: Event-camera simulation via fractional-relaxation pixel dynamics, 2026. 2
2026
-
[8]
Event-based vision: A survey.IEEE transactions on pattern analysis and machine intelligence, 44(1):154–180, 2020
Guillermo Gallego, Tobi Delbr ¨uck, Garrick Orchard, Chiara Bartolozzi, Brian Taba, Andrea Censi, Stefan Leutenegger, Andrew J Davison, J ¨org Conradt, Kostas Daniilidis, et al. Event-based vision: A survey.IEEE transactions on pattern analysis and machine intelligence, 44(1):154–180, 2020. 2
2020
-
[9]
Low-latency auto- motive vision with event cameras.Nature, 629(8014):1034– 1040, 2024
Daniel Gehrig and Davide Scaramuzza. Low-latency auto- motive vision with event cameras.Nature, 629(8014):1034– 1040, 2024. 2
2024
-
[10]
Low cost and latency event camera background activity denoising.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(1):785– 795, 2022
Shasha Guo and Tobi Delbruck. Low cost and latency event camera background activity denoising.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(1):785– 795, 2022. 2
2022
-
[11]
Lime: Low-light im- age enhancement via illumination map estimation.IEEE Transactions on image processing, 26(2):982–993, 2016
Xiaojie Guo, Yu Li, and Haibin Ling. Lime: Low-light im- age enhancement via illumination map estimation.IEEE Transactions on image processing, 26(2):982–993, 2016. 2
2016
-
[12]
Eretinex: Event camera meets retinex theory for low-light image enhancement
Xuejian Guo, Zhiqiang Tian, Yuehang Wang, Siqi Li, Yu Jiang, Shaoyi Du, and Yue Gao. Eretinex: Event camera meets retinex theory for low-light image enhancement. In 2025 IEEE International Conference on Robotics and Au- tomation (ICRA), pages 3759–3765. IEEE, 2025. 3
2025
-
[13]
v2e: From video frames to realistic dvs events
Yuhuang Hu, Shih-Chii Liu, and Tobi Delbruck. v2e: From video frames to realistic dvs events. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1312–1321, 2021. 11
2021
-
[14]
Scope of va- lidity of psnr in image/video quality assessment.Electronics letters, 44(13):800–801, 2008
Quan Huynh-Thu and Mohammed Ghanbari. Scope of va- lidity of psnr in image/video quality assessment.Electronics letters, 44(13):800–801, 2008. 5
2008
-
[15]
Enlightengan: Deep light enhancement without paired supervision.IEEE transactions on image processing, 30:2340–2349, 2021
Yifan Jiang, Xinyu Gong, Ding Liu, Yu Cheng, Chen Fang, Xiaohui Shen, Jianchao Yang, Pan Zhou, and Zhangyang Wang. Enlightengan: Deep light enhancement without paired supervision.IEEE transactions on image processing, 30:2340–2349, 2021. 2
2021
-
[16]
Event-based low-illumination image enhancement.IEEE Transactions on Multimedia, 26:1920– 1931, 2023
Yu Jiang, Yuehang Wang, Siqi Li, Yongji Zhang, Minghao Zhao, and Yue Gao. Event-based low-illumination image enhancement.IEEE Transactions on Multimedia, 26:1920– 1931, 2023. 2, 3, 5
1920
-
[17]
Event-guided low light image enhancement via a dual branch gan.Journal of Visual Communication and Image Represen- tation, 95:103887, 2023
Haiyan Jin, Qiaobin Wang, Haonan Su, and Zhaolin Xiao. Event-guided low light image enhancement via a dual branch gan.Journal of Visual Communication and Image Represen- tation, 95:103887, 2023. 3
2023
-
[18]
Towards robust event-guided low-light image enhancement: a large-scale real-world event-image dataset and novel approach
Guoqiang Liang, Kanghao Chen, Hangyu Li, Yunfan Lu, and Lin Wang. Towards robust event-guided low-light image enhancement: a large-scale real-world event-image dataset and novel approach. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 23–33, 2024. 2, 3, 5
2024
-
[19]
Towards robust event-guided low-light image enhancement: a large-scale real-world event-image dataset and novel approach
Guoqiang Liang, Kanghao Chen, Hangyu Li, Yunfan Lu, and Lin Wang. Towards robust event-guided low-light image enhancement: a large-scale real-world event-image dataset and novel approach. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 23–33, 2024. 11
2024
-
[20]
Chunxiao Liu, Zelong Wang, Philip Birch, and Xun Wang. Efficient retinex-based framework for low-light image en- hancement without additional networks.IEEE Transactions on Circuits and Systems for Video Technology, 35(5):4896– 4909, 2024. 2
2024
-
[21]
Low-light video enhancement with synthetic event guidance
Lin Liu, Junfeng An, Jianzhuang Liu, Shanxin Yuan, Xi- angyu Chen, Wengang Zhou, Houqiang Li, Yan Feng Wang, and Qi Tian. Low-light video enhancement with synthetic event guidance. InProceedings of the AAAI Conference on Artificial Intelligence, pages 1692–1700, 2023. 5
2023
-
[22]
Ll- net: A deep autoencoder approach to natural low-light image enhancement.Pattern Recognition, 61:650–662, 2017
Kin Gwn Lore, Adedotun Akintayo, and Soumik Sarkar. Ll- net: A deep autoencoder approach to natural low-light image enhancement.Pattern Recognition, 61:650–662, 2017. 2
2017
-
[23]
Yunfan Lu, Xiaogang Xu, Hao Lu, Yanlin Qian, Pengteng Li, Huizai Yao, Bin Yang, Junyi Li, Qianyi Cai, Weiyu Guo, et al. See: See everything every time–adaptive brightness adjustment for broad light range images via events.arXiv preprint arXiv:2502.21120, 2025. 3
-
[24]
Bringing a blurry frame alive at high frame-rate with an event camera
Liyuan Pan, Cedric Scheerlinck, Xin Yu, Richard Hartley, Miaomiao Liu, and Yuchao Dai. Bringing a blurry frame alive at high frame-rate with an event camera. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6820–6829, 2019. 3
2019
-
[25]
Gwretinex-net: Gray world retinex network for low-light image enhancement.IEEE Transac- tions on Circuits and Systems for Video Technology, 2025
Hu Qiang, Yuzhong Zhong, Yiwei Liao, Xingxing You, Yuqi Zhu, and Songyi Dian. Gwretinex-net: Gray world retinex network for low-light image enhancement.IEEE Transac- tions on Circuits and Systems for Video Technology, 2025. 2
2025
-
[26]
Reducing the sim-to-real gap for event cam- eras
Timo Stoffregen, Cedric Scheerlinck, Davide Scaramuzza, Tom Drummond, Nick Barnes, Lindsay Kleeman, and Robert Mahony. Reducing the sim-to-real gap for event cam- eras. InEuropean Conference on Computer Vision, pages 534–549. Springer, 2020. 3, 5
2020
-
[27]
Low-light image enhancement using event-based illumination estimation
Lei Sun, Yuhan Bao, Jiajun Zhai, Jingyun Liang, Yu- lun Zhang, Kaiwei Wang, Danda Pani Paudel, and Luc Van Gool. Low-light image enhancement using event-based illumination estimation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 6667– 6677, 2025. 3
2025
-
[28]
Event enhanced high-quality image recovery
Bishan Wang, Jingwei He, Lei Yu, Gui-Song Xia, and Wen Yang. Event enhanced high-quality image recovery. In European Conference on Computer Vision, pages 155–171. Springer, 2020. 5
2020
-
[29]
Seeing dynamic scene in the dark: A high-quality video dataset with mechatronic alignment
Ruixing Wang, Xiaogang Xu, Chi-Wing Fu, Jiangbo Lu, Bei Yu, and Jiaya Jia. Seeing dynamic scene in the dark: A high-quality video dataset with mechatronic alignment. In Proceedings of the IEEE/CVF international conference on computer vision, pages 9700–9709, 2021. 5
2021
-
[30]
Seeing dynamic scene in the dark: A high-quality video dataset with mechatronic alignment
Ruixing Wang, Xiaogang Xu, Chi-Wing Fu, Jiangbo Lu, Bei Yu, and Jiaya Jia. Seeing dynamic scene in the dark: A high-quality video dataset with mechatronic alignment. In Proceedings of the IEEE/CVF international conference on computer vision, pages 9700–9709, 2021. 11
2021
-
[31]
Ultra-high-definition low-light image enhancement: A benchmark and transformer-based method
Tao Wang, Kaihao Zhang, Tianrun Shen, Wenhan Luo, Bjorn Stenger, and Tong Lu. Ultra-high-definition low-light image enhancement: A benchmark and transformer-based method. InProceedings of the AAAI conference on artificial intelli- gence, pages 2654–2662, 2023. 2
2023
-
[32]
Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4):600–612, 2004
Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Si- moncelli. Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4):600–612, 2004. 6
2004
-
[33]
Uformer: A general u-shaped transformer for image restoration
Zhendong Wang, Xiaodong Cun, Jianmin Bao, Wengang Zhou, Jianzhuang Liu, and Houqiang Li. Uformer: A general u-shaped transformer for image restoration. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 17683–17693, 2022. 5
2022
-
[34]
Deep Retinex Decomposition for Low-Light Enhancement
Chen Wei, Wenjing Wang, Wenhan Yang, and Jiaying Liu. Deep retinex decomposition for low-light enhancement. arXiv preprint arXiv:1808.04560, 2018. 2
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[35]
Learning semantic-aware knowledge guidance for low-light image enhancement
Yuhui Wu, Chen Pan, Guoqing Wang, Yang Yang, Jiwei Wei, Chongyi Li, and Heng Tao Shen. Learning semantic-aware knowledge guidance for low-light image enhancement. In Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 1662–1671, 2023. 5
2023
-
[36]
Event- gan: An unsupervised low-light grayscale image enhance- ment method based on event camera.IEEE Sensors Journal,
Zehao Wu, Yuanqing Xia, Rui Hu, and Runze Gao. Event- gan: An unsupervised low-light grayscale image enhance- ment method based on event camera.IEEE Sensors Journal,
-
[37]
Towards end-to-end neuromorphic voxel- based 3d object reconstruction without physical priors
Chuanzhi Xu, Langyi Chen, Haodong Chen, Vera Chung, and Vincent Qu. Towards end-to-end neuromorphic voxel- based 3d object reconstruction without physical priors. In 2025 IEEE International Conference on Multimedia and Expo (ICME), pages 1–6, 2025. 2
2025
-
[38]
A survey of 3d reconstruction with event cameras.Computational Visual Media, (99):1–37,
Chuanzhi Xu, Haoxian Zhou, Langyi Chen, Haodong Chen, Zeke Zexi Hu, Zhicheng Lu, Ying Zhou, Vera Chung, Qiang Qu, and Weidong Cai. A survey of 3d reconstruction with event cameras.Computational Visual Media, (99):1–37,
-
[39]
Ultralight polarity-split neuromor- phic snn for event-stream super-resolution
Chuanzhi Xu, Haoxian Zhou, Langyi Chen, Yuk Ying Chung, and Qiang Qu. Ultralight polarity-split neuromor- phic snn for event-stream super-resolution. InProceedings of the AAAI Conference on Artificial Intelligence, pages 11196– 11204, 2026. 2
2026
-
[40]
Star: A struc- ture and texture aware retinex model.IEEE Transactions on Image Processing, 29:5022–5037, 2020
Jun Xu, Yingkun Hou, Dongwei Ren, Li Liu, Fan Zhu, Mengyang Yu, Haoqian Wang, and Ling Shao. Star: A struc- ture and texture aware retinex model.IEEE Transactions on Image Processing, 29:5022–5037, 2020. 2
2020
-
[41]
Event-illumination collab- orative low-light image enhancement with a high-resolution real-world dataset
Senyan Xu, Zhijing Sun, Kean Liu, Xin Lu, Ruixuan Jiang, Xueyang Fu, and Zheng-Jun Zha. Event-illumination collab- orative low-light image enhancement with a high-resolution real-world dataset. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 22270–22280, 2026. 11
2026
-
[42]
Snr-aware low-light image enhancement
Xiaogang Xu, Ruixing Wang, Chi-Wing Fu, and Jiaya Jia. Snr-aware low-light image enhancement. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 17714–17724, 2022. 5
2022
-
[43]
Bievlight: Bi-level learning of task-aware event refinement for low-light image enhancement
Zishu Yao, Xiang-Xiang Su, Shengning Zhou, Guang-Yong Chen, Guodong Fan, and Xing Chen. Bievlight: Bi-level learning of task-aware event refinement for low-light image enhancement. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 41541– 41550, 2026. 11
2026
-
[44]
Diff-retinex: Rethinking low-light image enhance- ment with a generative diffusion model
Xunpeng Yi, Han Xu, Hao Zhang, Linfeng Tang, and Ji- ayi Ma. Diff-retinex: Rethinking low-light image enhance- ment with a generative diffusion model. InProceedings of the IEEE/CVF international conference on computer vision, pages 12302–12311, 2023. 2
2023
-
[45]
Learning to see in the dark with events
Song Zhang, Yu Zhang, Zhe Jiang, Dongqing Zou, Jimmy Ren, and Bin Zhou. Learning to see in the dark with events. InEuropean Conference on Computer Vision, pages 666–
-
[46]
Springer, 2020. 2, 3
2020
-
[47]
Kindling the darkness: A practical low-light image enhancer
Yonghua Zhang, Jiawan Zhang, and Xiaojie Guo. Kindling the darkness: A practical low-light image enhancer. InPro- ceedings of the 27th ACM international conference on mul- timedia, pages 1632–1640, 2019. 2
2019
-
[48]
Retinexdip: A unified deep framework for low-light image enhancement.IEEE Transactions on Cir- cuits and Systems for Video Technology, 32(3):1076–1088,
Zunjin Zhao, Bangshu Xiong, Lei Wang, Qiaofeng Ou, Lei Yu, and Fa Kuang. Retinexdip: A unified deep framework for low-light image enhancement.IEEE Transactions on Cir- cuits and Systems for Video Technology, 32(3):1076–1088,
-
[49]
Haoxian Zhou, Chuanzhi Xu, Langyi Chen, Pengfei Ye, Haodong Chen, Yuk Ying Chung, and Qiang Qu. Exploiting spatiotemporal properties for efficient event-driven human pose estimation.arXiv preprint arXiv:2512.06306, 2025. 2
-
[50]
Event-based stereo visual odometry.IEEE Transactions on Robotics, 37 (5):1433–1450, 2021
Yi Zhou, Guillermo Gallego, and Shaojie Shen. Event-based stereo visual odometry.IEEE Transactions on Robotics, 37 (5):1433–1450, 2021. 2 Technical Appendices and Supplementary Material A. Additional Experimental Details Dataset protocol.The experiments use the indoor and outdoor subsets of SDE [19] and SDSD [30]. SDE contains 91 spatially and temporally ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.