Which Tokens Need Context? A Reference-Based Analysis of Translation Responsibility Using Fertility and Entropy
Pith reviewed 2026-06-30 07:30 UTC · model grok-4.3
The pith
Context redistributes generative responsibility in translation from source tokens to context tokens, mainly reducing fertility of function words.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
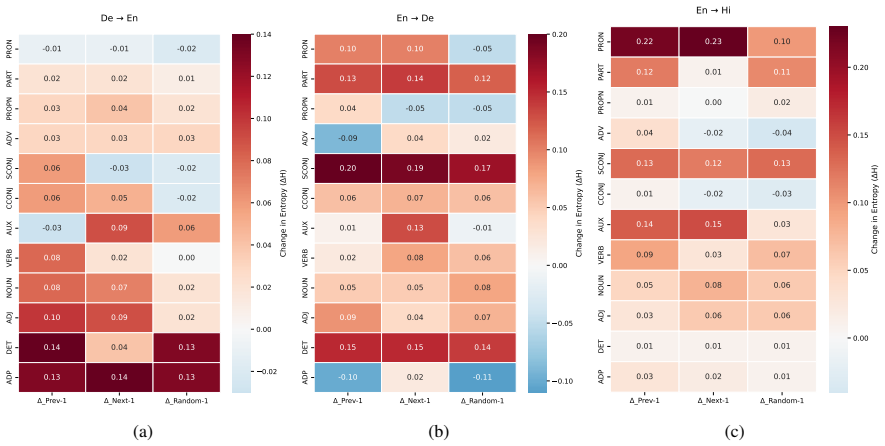
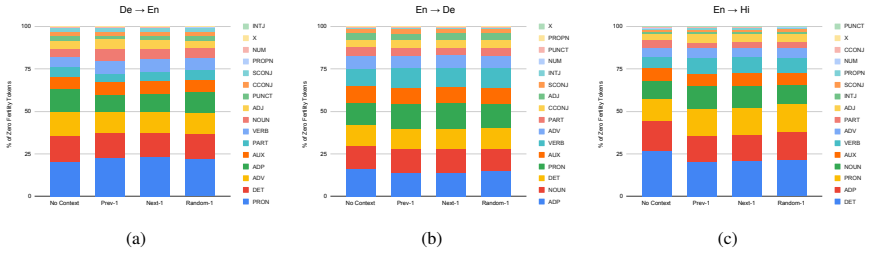
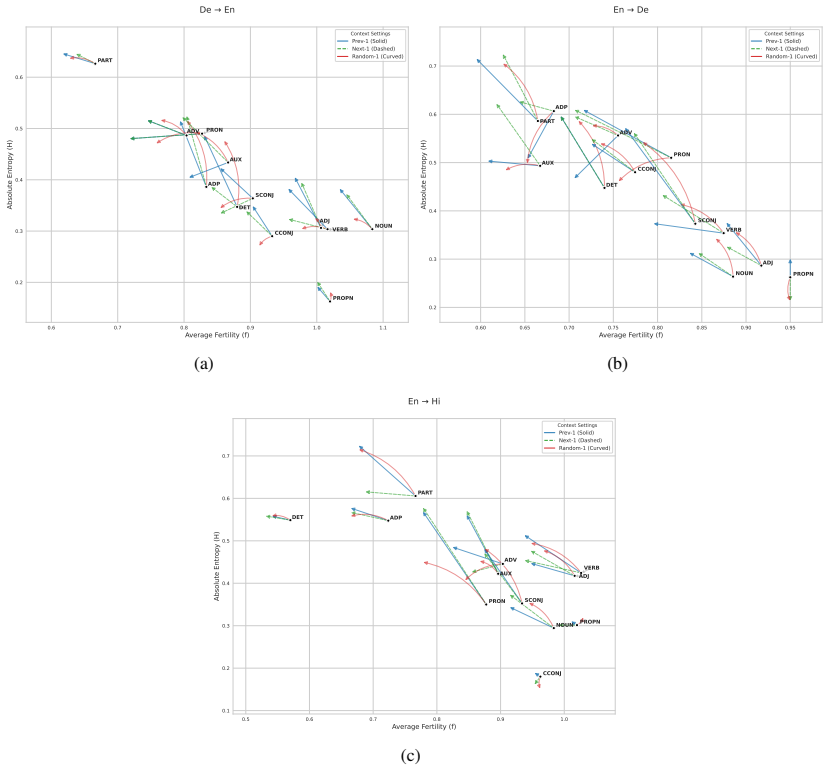
Context selectively redistributes generative responsibility from source to context tokens without altering overall fertility. Function words show the largest fertility reductions while content words remain stable, suggesting that context resolves ambiguity rather than adding new information.
What carries the argument
Fertility, the number of target tokens aligned to each source token, together with entropy of fertility patterns across different context conditions, both extracted from automatic word alignments on reference translations.
If this is right
- Function words carry less generative responsibility when more context is supplied.
- Content words maintain stable fertility regardless of context amount.
- Overall sentence fertility stays constant across context conditions.
- Context tokens absorb the generative load that source tokens lose.
- The same selective pattern appears across the three language pairs examined.
Where Pith is reading between the lines
- The measures could serve as a diagnostic to check whether a machine translation model reproduces the same fertility shifts that references exhibit.
- The approach might extend to other conditional generation tasks to quantify how much each input token depends on additional conditioning text.
- If the observed patterns prove stable under different alignment tools, the method could become a lightweight way to audit context use without model access.
Load-bearing premise
Automatic word alignments on reference translations accurately reflect the context sensitivity that human translators actually employ.
What would settle it
Recomputing the same measures on the identical references but with manually corrected alignments that produce substantially different fertility shifts for function words.
Figures

read the original abstract
When humans translate, not every word depends equally on the surrounding context. Some tokens, particularly function words like pronouns and auxiliaries, rely heavily on preceding or following sentences, while others, such as proper nouns, do not. Understanding this inherent context sensitivity is essential for evaluating whether machine translation systems use context in human-like ways. However, existing approaches to analysing context usage rely on discourse-specific test sets or model internals, making them narrow or model-dependent. We propose a post-hoc, model-agnostic framework to quantify context sensitivity at lexical and syntactic levels using two measures derived from word alignments: fertility (number of target tokens generated per source token) and entropy (stability of fertility patterns across contexts). Using reference translations for three language pairs (German $\leftrightarrow$ English, English $\rightarrow$ Hindi) under four context conditions, we show that context selectively redistributes generative responsibility from source to context tokens without altering overall fertility. Function words show the largest fertility reductions, while content words remain stable, suggesting that context resolves ambiguity rather than adding new information. Our framework provides a ground-truth characterisation of selective context usage in human translation, establishing a diagnostic baseline for evaluating machine translation models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a post-hoc, model-agnostic framework that derives fertility (target tokens generated per source token) and entropy (stability of fertility patterns across contexts) from automatic word alignments on reference translations. Applied to German↔English and English→Hindi under four context conditions, it reports that added context redistributes generative responsibility from source to context tokens without changing overall fertility; function words exhibit the largest fertility reductions while content words remain stable, interpreted as evidence that context resolves ambiguity rather than adding new information.
Significance. If the alignment-based measures can be shown to faithfully track human translator behavior, the framework supplies a concrete, reference-grounded baseline for selective context usage that is independent of model internals or discourse-specific test sets. This would be directly useful for diagnosing whether MT systems exhibit human-like context sensitivity across language pairs.
major comments (2)
- [§3 (alignment and fertility computation)] §3 (alignment and fertility computation): The central claim that fertility reductions reflect human context sensitivity rests on the untested assumption that automatic word alignments on references accurately proxy translator intent. Automatic aligners are known to produce systematic errors precisely on function words, pronouns, and ambiguous cases—the categories reported to show the largest effects. No AER scores, alignment error analysis, or human validation of a subset of alignments (especially function-word alignments) is described, leaving open the possibility that the redistribution pattern is an artifact of alignment noise.
- [§4 (results on fertility and entropy)] §4 (results on fertility and entropy): The claim that context 'selectively redistributes generative responsibility ... without altering overall fertility' and that this indicates resolution of ambiguity rather than addition of information requires quantitative support (mean fertility values, standard deviations, statistical tests) that survives controls for alignment quality and language-pair variation. The manuscript must demonstrate that the reported patterns are not driven by the known weaknesses of the aligner on the very token classes driving the effect.
minor comments (2)
- [Abstract / §2] The four context conditions are referenced in the abstract and §2 but never enumerated; a brief explicit list early in the paper would improve readability.
- [§3] Notation for fertility and entropy is introduced without a compact equation or table summarizing their definitions; adding a small definitional table would aid readers.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The concerns regarding alignment validation and the need for quantitative statistical support are well-taken, and we outline revisions to address them directly.
read point-by-point responses
-
Referee: §3 (alignment and fertility computation): The central claim that fertility reductions reflect human context sensitivity rests on the untested assumption that automatic word alignments on references accurately proxy translator intent. Automatic aligners are known to produce systematic errors precisely on function words, pronouns, and ambiguous cases—the categories reported to show the largest effects. No AER scores, alignment error analysis, or human validation of a subset of alignments (especially function-word alignments) is described, leaving open the possibility that the redistribution pattern is an artifact of alignment noise.
Authors: We agree that the absence of AER scores and targeted validation leaves the proxy assumption untested, particularly for the function-word categories central to the results. In revision we will compute AER on the alignments for all language pairs and context conditions, add a focused error analysis on function words and pronouns, and explicitly discuss how aligner biases could influence the observed fertility shifts. These additions will allow readers to assess whether the patterns survive known alignment weaknesses. revision: yes
-
Referee: §4 (results on fertility and entropy): The claim that context 'selectively redistributes generative responsibility ... without altering overall fertility' and that this indicates resolution of ambiguity rather than addition of information requires quantitative support (mean fertility values, standard deviations, statistical tests) that survives controls for alignment quality and language-pair variation. The manuscript must demonstrate that the reported patterns are not driven by the known weaknesses of the aligner on the very token classes driving the effect.
Authors: The manuscript currently presents aggregate trends without the requested per-condition means, standard deviations, or formal tests. We will expand §4 to report mean fertility (with SD) for source vs. context tokens, broken down by POS class and language pair, together with statistical tests for changes across context conditions. We will also add sensitivity checks that stratify results by alignment quality metrics to show the patterns are not artifacts of the aligner’s known weaknesses on function words. revision: yes
Circularity Check
No significant circularity; measures computed directly from alignments
full rationale
The paper defines fertility as the number of target tokens per source token and entropy as stability of fertility patterns, both computed directly from automatic word alignments on reference translations under different context conditions. The central observation—that context redistributes responsibility selectively—is an empirical pattern extracted from these quantities on held-out references, with no equations, fitted parameters, or self-citations shown that would make the result equivalent to its inputs by construction. The framework is post-hoc and data-driven rather than tautological.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Word alignments derived from reference translations accurately reflect the generative responsibility of source tokens under varying context conditions.
Reference graph
Works this paper leans on
-
[1]
Natural Language Processing , volume=
A survey of context in neural machine translation and its evaluation , author=. Natural Language Processing , volume=. 2025 , publisher=
2025
-
[2]
Language Resources and Evaluation , volume=
DiaBLa: a corpus of bilingual spontaneous written dialogues for machine translation , author=. Language Resources and Evaluation , volume=. 2021 , publisher=
2021
-
[3]
arXiv preprint arXiv:2310.01188 , year=
Quantifying the plausibility of context reliance in neural machine translation , author=. arXiv preprint arXiv:2310.01188 , year=
-
[4]
arXiv preprint arXiv:2304.12959 , year=
Escaping the sentence-level paradigm in machine translation , author=. arXiv preprint arXiv:2304.12959 , year=
-
[5]
Context Is Ubiquitous, but Rarely Changes Judgments: Revisiting Document-Level MT Evaluation
Kim, Ahrii. Context Is Ubiquitous, but Rarely Changes Judgments: Revisiting Document-Level MT Evaluation. Proceedings of the Tenth Conference on Machine Translation. 2025. doi:10.18653/v1/2025.wmt-1.5
-
[6]
Transactions on Machine Learning Research , issn=
IndicTrans2: Towards High-Quality and Accessible Machine Translation Models for all 22 Scheduled Indian Languages , author=. Transactions on Machine Learning Research , issn=. 2023 , url=
2023
-
[7]
ACM Computing Surveys (CSUR) , volume=
A survey on document-level neural machine translation: Methods and evaluation , author=. ACM Computing Surveys (CSUR) , volume=. 2021 , publisher=
2021
-
[8]
arXiv preprint arXiv:2410.08143 , year=
Delta: An online document-level translation agent based on multi-level memory , author=. arXiv preprint arXiv:2410.08143 , year=
-
[9]
arXiv preprint arXiv:2401.06468 , year=
Adapting large language models for document-level machine translation , author=. arXiv preprint arXiv:2401.06468 , year=
-
[10]
21st Annual Conference of the European Association for Machine Translation , pages=
Contextual handling in neural machine translation: Look behind, ahead and on both sides , author=. 21st Annual Conference of the European Association for Machine Translation , pages=
-
[11]
New directions in empirical translation process research: Exploring the CRITT TPR-DB , pages=
The CRITT translation process research database , author=. New directions in empirical translation process research: Exploring the CRITT TPR-DB , pages=. 2016 , publisher=
2016
-
[12]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
A survey on non-autoregressive generation for neural machine translation and beyond , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=. 2023 , publisher=
2023
-
[13]
Non-Autoregressive Neural Machine Translation
Non-autoregressive neural machine translation , author=. arXiv preprint arXiv:1711.02281 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Journal of Memory and Language , volume=
The role of discourse structure in understanding anaphora , author=. Journal of Memory and Language , volume=. 1985 , publisher=
1985
-
[15]
The On-line Study of Sentence Comprehension , pages=
Sentence comprehension in a wider discourse: Can we use ERPs to keep track of things? , author=. The On-line Study of Sentence Comprehension , pages=. 2004 , publisher=
2004
-
[16]
The construction of mental representations during reading , pages=
Context models in discourse processing , author=. The construction of mental representations during reading , pages=
-
[17]
Context-Aware Neural Machine Translation Learns Anaphora Resolution
Voita, Elena and Serdyukov, Pavel and Sennrich, Rico and Titov, Ivan. Context-Aware Neural Machine Translation Learns Anaphora Resolution. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2018. doi:10.18653/v1/P18-1117
-
[18]
Document Context Neural Machine Translation with Memory Networks
Maruf, Sameen and Haffari, Gholamreza. Document Context Neural Machine Translation with Memory Networks. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2018. doi:10.18653/v1/P18-1118
-
[19]
Improving the Transformer Translation Model with Document-Level Context
Zhang, Jiacheng and Luan, Huanbo and Sun, Maosong and Zhai, Feifei and Xu, Jingfang and Zhang, Min and Liu, Yang. Improving the Transformer Translation Model with Document-Level Context. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 2018. doi:10.18653/v1/D18-1049
-
[20]
Contextual Handling in Neural Machine Translation: Look behind, ahead and on both sides
Agrawal, Ruchit and Turchi, Marco and Negri, Matteo. Contextual Handling in Neural Machine Translation: Look behind, ahead and on both sides. Proceedings of the 21st Annual Conference of the European Association for Machine Translation. 2018
2018
-
[21]
Amin and Bawden, Rachel and Zhang, Michael and Martins, Andr \'e F
Lopes, Ant \'o nio and Farajian, M. Amin and Bawden, Rachel and Zhang, Michael and Martins, Andr \'e F. T. Document-level Neural MT : A Systematic Comparison. Proceedings of the 22nd Annual Conference of the European Association for Machine Translation. 2020
2020
-
[22]
Diverse Pretrained Context Encodings Improve Document Translation
Donato, Domenic and Yu, Lei and Dyer, Chris. Diverse Pretrained Context Encodings Improve Document Translation. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). 2021. doi:10.18653/v1/2021.acl-long.104
-
[23]
When and Why is Document-level Context Useful in Neural Machine Translation?
Kim, Yunsu and Tran, Duc Thanh and Ney, Hermann. When and Why is Document-level Context Useful in Neural Machine Translation?. Proceedings of the Fourth Workshop on Discourse in Machine Translation (DiscoMT 2019). 2019. doi:10.18653/v1/D19-6503
-
[24]
Does Multi-Encoder Help? A Case Study on Context-Aware Neural Machine Translation
Li, Bei and Liu, Hui and Wang, Ziyang and Jiang, Yufan and Xiao, Tong and Zhu, Jingbo and Liu, Tongran and Li, Changliang. Does Multi-Encoder Help? A Case Study on Context-Aware Neural Machine Translation. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.322
-
[25]
Investigating the Translation Performance of a Large Multilingual Language Model: the Case of BLOOM
Bawden, Rachel and Yvon, Fran c ois. Investigating the Translation Performance of a Large Multilingual Language Model: the Case of BLOOM. Proceedings of the 24th Annual Conference of the European Association for Machine Translation. 2023
2023
-
[26]
A Case Study on Context Encoding in Multi-Encoder based Document-Level Neural Machine Translation
Appicharla, Ramakrishna and Gain, Baban and Pal, Santanu and Ekbal, Asif. A Case Study on Context Encoding in Multi-Encoder based Document-Level Neural Machine Translation. Proceedings of Machine Translation Summit XIX, Vol. 1: Research Track. 2023
2023
-
[27]
Voita, Elena and Sennrich, Rico and Titov, Ivan. When a Good Translation is Wrong in Context: Context-Aware Machine Translation Improves on Deixis, Ellipsis, and Lexical Cohesion. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019. doi:10.18653/v1/P19-1116
-
[28]
When Does Translation Require Context? A Data-driven, Multilingual Exploration
Fernandes, Patrick and Yin, Kayo and Liu, Emmy and Martins, Andr \'e and Neubig, Graham. When Does Translation Require Context? A Data-driven, Multilingual Exploration. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.36
-
[29]
m OSCAR : A Large-scale Multilingual and Multimodal Document-level Corpus
Futeral, Matthieu and Zebaze, Armel Randy and Ortiz Suarez, Pedro and Abadji, Julien and Lacroix, R \'e mi and Schmid, Cordelia and Bawden, Rachel and Sagot, Beno \^i t. m OSCAR : A Large-scale Multilingual and Multimodal Document-level Corpus. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.180
-
[30]
M. A Large-Scale Test Set for the Evaluation of Context-Aware Pronoun Translation in Neural Machine Translation. Proceedings of the Third Conference on Machine Translation: Research Papers. 2018. doi:10.18653/v1/W18-6307
-
[31]
Evaluating Discourse Phenomena in Neural Machine Translation
Bawden, Rachel and Sennrich, Rico and Birch, Alexandra and Haddow, Barry. Evaluating Discourse Phenomena in Neural Machine Translation. Proceedings of the 2018 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers). 2018. doi:10.18653/v1/N18-1118
-
[32]
Yin, Kayo and Fernandes, Patrick and Pruthi, Danish and Chaudhary, Aditi and Martins, Andr \'e F. T. and Neubig, Graham. Do Context-Aware Translation Models Pay the Right Attention?. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: ...
-
[33]
Fernandes, Patrick and Yin, Kayo and Neubig, Graham and Martins, Andr \'e F. T. Measuring and Increasing Context Usage in Context-Aware Machine Translation. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). 2021. doi:10...
-
[34]
On Measuring Context Utilization in Document-Level MT Systems
Mohammed, Wafaa and Niculae, Vlad. On Measuring Context Utilization in Document-Level MT Systems. Findings of the Association for Computational Linguistics: EACL 2024. 2024. doi:10.18653/v1/2024.findings-eacl.113
-
[35]
Context-Aware or Context-Insensitive? Assessing LLM s' Performance in Document-Level Translation
Mohammed, Wafaa and Niculae, Vlad. Context-Aware or Context-Insensitive? Assessing LLM s' Performance in Document-Level Translation. Proceedings of Machine Translation Summit XX: Volume 1. 2025
2025
-
[36]
Analyzing the Attention Heads for Pronoun Disambiguation in Context-aware Machine Translation Models
M a ka, Pawe and Semerci, Yusuf Can and Scholtes, Jan and Spanakis, Gerasimos. Analyzing the Attention Heads for Pronoun Disambiguation in Context-aware Machine Translation Models. Proceedings of the 31st International Conference on Computational Linguistics. 2025
2025
-
[37]
and Della Pietra, Stephen A
Brown, Peter F. and Della Pietra, Stephen A. and Della Pietra, Vincent J. and Mercer, Robert L. The Mathematics of Statistical Machine Translation: Parameter Estimation. Computational Linguistics. 1993
1993
-
[38]
Neural Machine Translation with Extended Context
Tiedemann, J. Neural Machine Translation with Extended Context. Proceedings of the Third Workshop on Discourse in Machine Translation. 2017. doi:10.18653/v1/W17-4811
-
[39]
A Simple and Effective Unified Encoder for Document-Level Machine Translation
Ma, Shuming and Zhang, Dongdong and Zhou, Ming. A Simple and Effective Unified Encoder for Document-Level Machine Translation. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.321
-
[40]
Zhang, Xuan and Rajabi, Navid and Duh, Kevin and Koehn, Philipp. Machine Translation with Large Language Models: Prompting, Few-shot Learning, and Fine-tuning with QL o RA. Proceedings of the Eighth Conference on Machine Translation. 2023. doi:10.18653/v1/2023.wmt-1.43
-
[41]
Validation of an Automatic Metric for the Accuracy of Pronoun Translation ( APT )
Miculicich Werlen, Lesly and Popescu-Belis, Andrei. Validation of an Automatic Metric for the Accuracy of Pronoun Translation ( APT ). Proceedings of the Third Workshop on Discourse in Machine Translation. 2017. doi:10.18653/v1/W17-4802
-
[42]
G -Transformer for Document-Level Machine Translation
Bao, Guangsheng and Zhang, Yue and Teng, Zhiyang and Chen, Boxing and Luo, Weihua. G -Transformer for Document-Level Machine Translation. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). 2021. doi:10.18653/v1/2021.acl-long.267
-
[43]
Encouraging Lexical Translation Consistency for Document-Level Neural Machine Translation
Lyu, Xinglin and Li, Junhui and Gong, Zhengxian and Zhang, Min. Encouraging Lexical Translation Consistency for Document-Level Neural Machine Translation. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021. doi:10.18653/v1/2021.emnlp-main.262
-
[44]
BlonDe : An Automatic Evaluation Metric for Document-level Machine Translation
Jiang, Yuchen and Liu, Tianyu and Ma, Shuming and Zhang, Dongdong and Yang, Jian and Huang, Haoyang and Sennrich, Rico and Cotterell, Ryan and Sachan, Mrinmaya and Zhou, Ming. BlonDe : An Automatic Evaluation Metric for Document-level Machine Translation. Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational...
-
[45]
Vernikos, Giorgos and Thompson, Brian and Mathur, Prashant and Federico, Marcello. Embarrassingly Easy Document-Level MT Metrics: How to Convert Any Pretrained Metric into a Document-Level Metric. Proceedings of the Seventh Conference on Machine Translation (WMT). 2022. doi:10.18653/v1/2022.wmt-1.6
-
[46]
Multilingual Denoising Pre-training for Neural Machine Translation
Liu, Yinhan and Gu, Jiatao and Goyal, Naman and Li, Xian and Edunov, Sergey and Ghazvininejad, Marjan and Lewis, Mike and Zettlemoyer, Luke. Multilingual Denoising Pre-training for Neural Machine Translation. Transactions of the Association for Computational Linguistics. 2020. doi:10.1162/tacl_a_00343
-
[47]
Predicting Human Translation Difficulty Using Automatic Word Alignment
Lim, Zheng Wei and Cohn, Trevor and Kemp, Charles and Vylomova, Ekaterina. Predicting Human Translation Difficulty Using Automatic Word Alignment. Findings of the Association for Computational Linguistics: ACL 2023. 2023. doi:10.18653/v1/2023.findings-acl.736
-
[48]
Entropy as a measurement of cognitive load in translation
Wei, Yuxiang. Entropy as a measurement of cognitive load in translation. Proceedings of the 15th biennial conference of the Association for Machine Translation in the Americas (Workshop 1: Empirical Translation Process Research). 2022
2022
-
[49]
Predicting Human Translation Difficulty with Neural Machine Translation
Lim, Zheng Wei and Vylomova, Ekaterina and Kemp, Charles and Cohn, Trevor. Predicting Human Translation Difficulty with Neural Machine Translation. Transactions of the Association for Computational Linguistics. 2024. doi:10.1162/tacl_a_00714
-
[50]
Song, Jongyoon and Kim, Sungwon and Yoon, Sungroh. A lig NART : Non-autoregressive Neural Machine Translation by Jointly Learning to Estimate Alignment and Translate. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021. doi:10.18653/v1/2021.emnlp-main.1
-
[51]
S tanza: A Python Natural Language Processing Toolkit for Many Human Languages
Qi, Peng and Zhang, Yuhao and Zhang, Yuhui and Bolton, Jason and Manning, Christopher D. S tanza: A Python Natural Language Processing Toolkit for Many Human Languages. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics: System Demonstrations. 2020. doi:10.18653/v1/2020.acl-demos.14
-
[52]
Maruf, Sameen and Martins, Andr \'e F. T. and Haffari, Gholamreza. Selective Attention for Context-aware Neural Machine Translation. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019. doi:10.18653/v1/N19-1313
-
[53]
Word Alignment by Fine-tuning Embeddings on Parallel Corpora
Dou, Zi-Yi and Neubig, Graham. Word Alignment by Fine-tuning Embeddings on Parallel Corpora. Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume. 2021. doi:10.18653/v1/2021.eacl-main.181
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.