Cognitive World Models for Process-Level Social Influence Evaluation
Pith reviewed 2026-06-30 06:51 UTC · model grok-4.3
The pith
Cognitive world models track how conversations change users' beliefs, desires, intentions, and emotions instead of scoring final text outputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
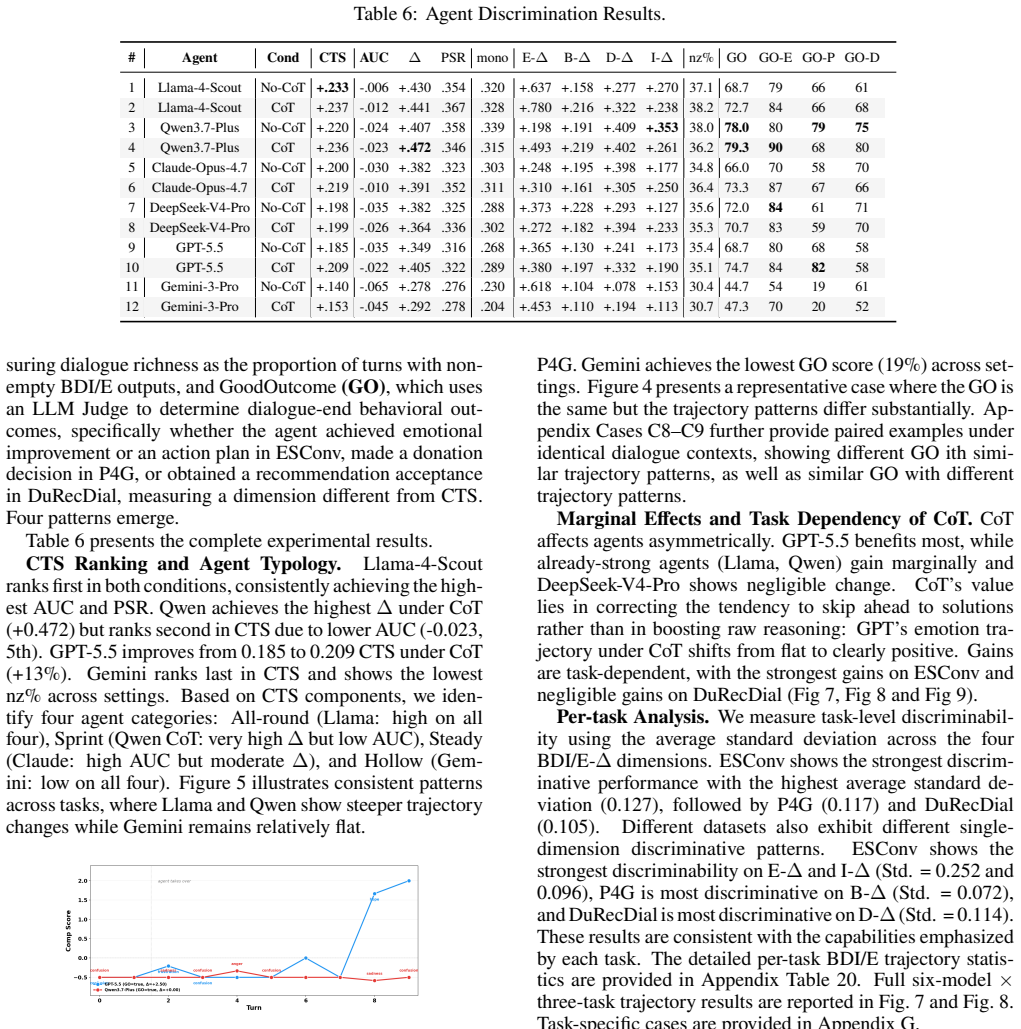
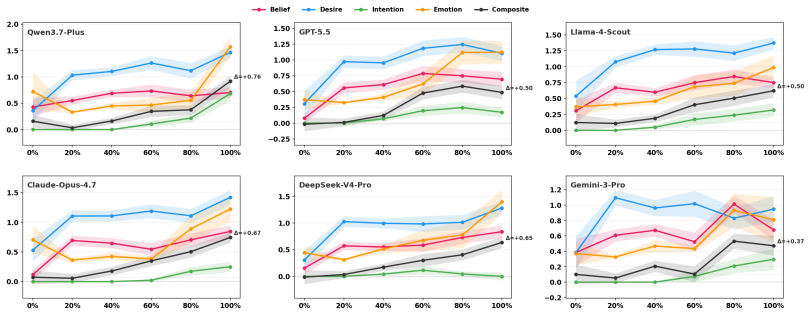
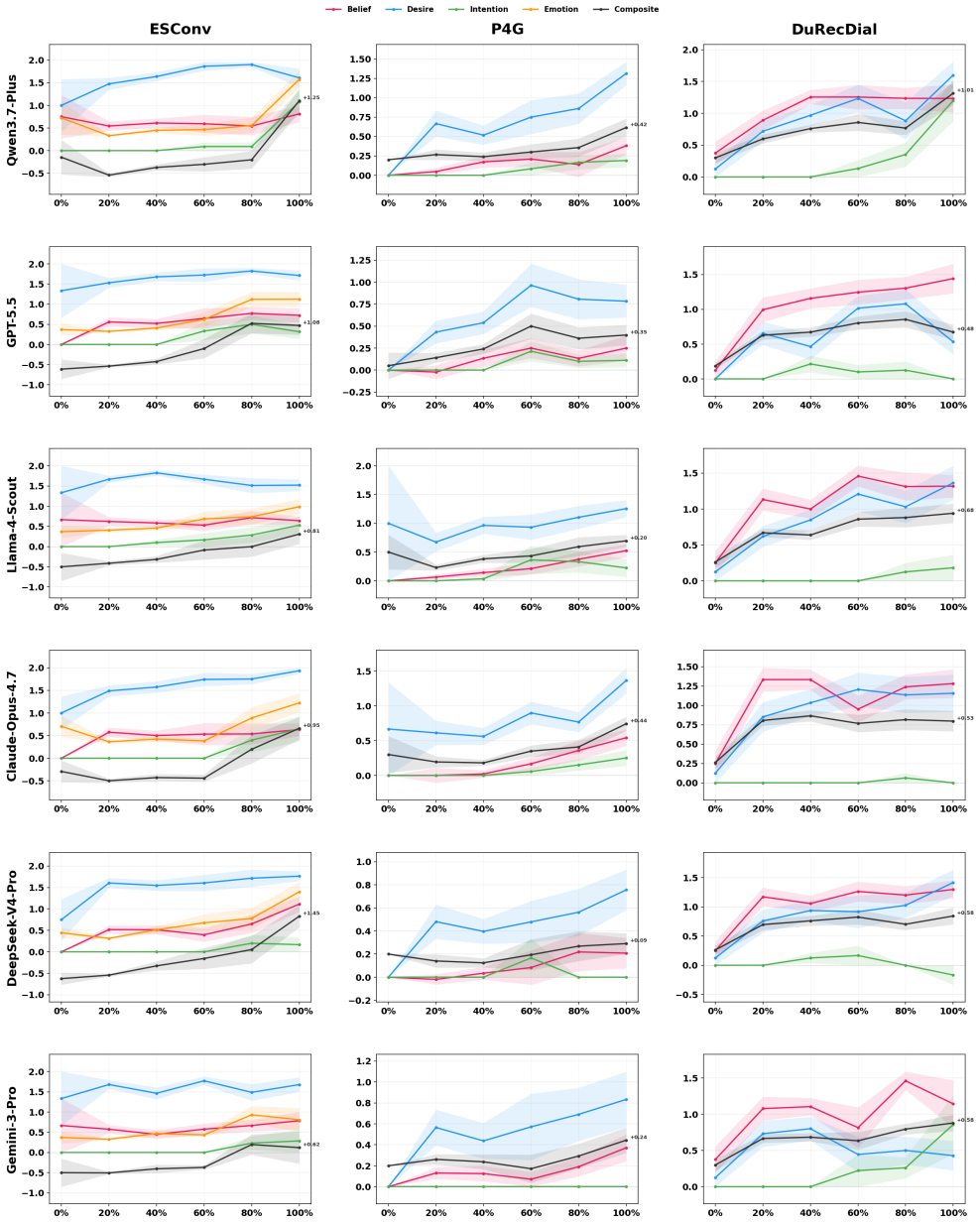
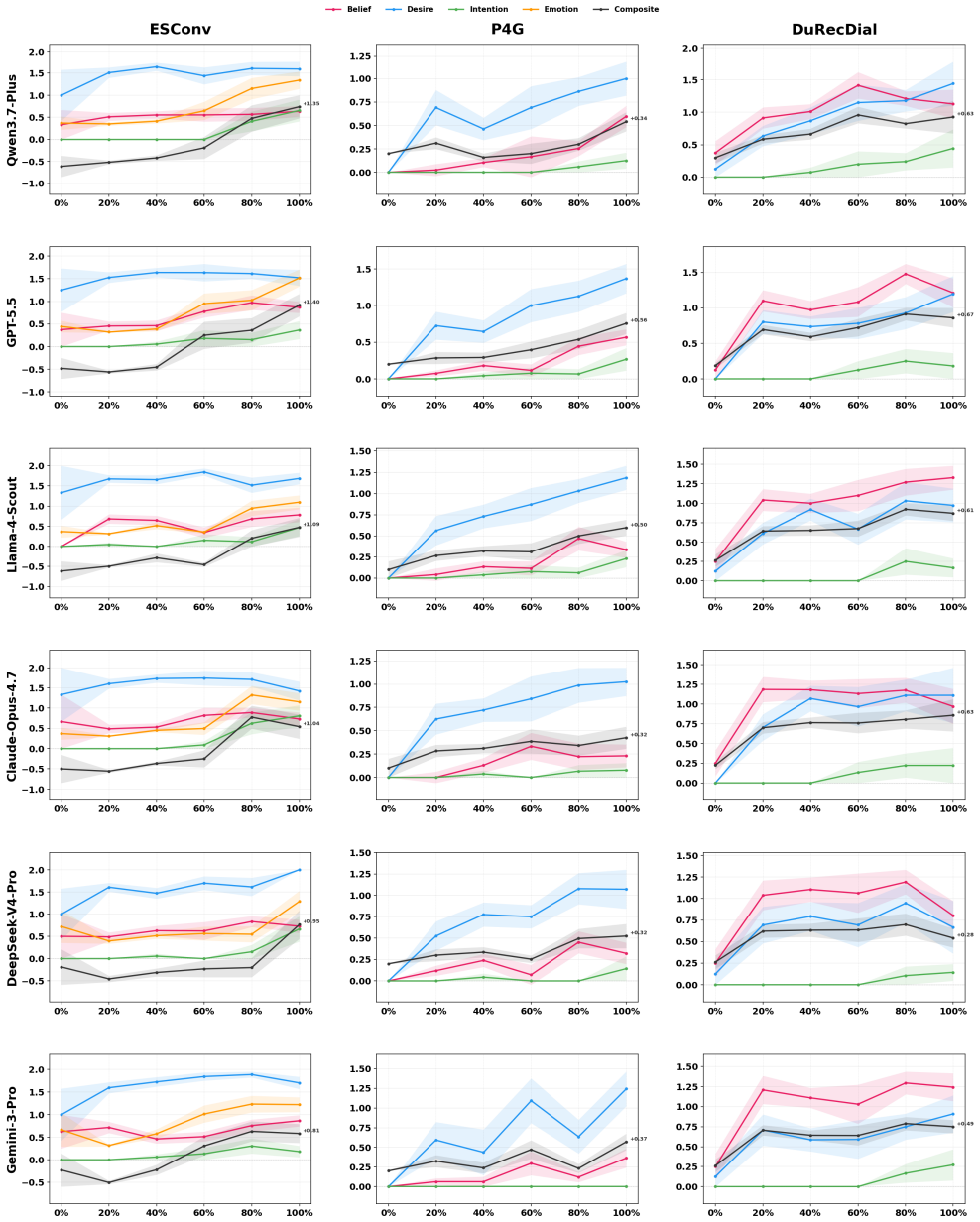
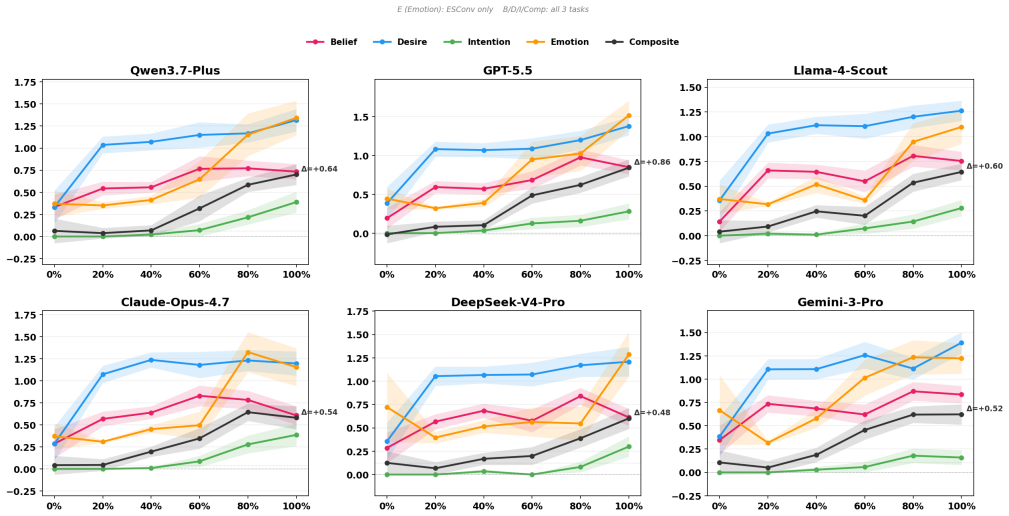
CogWM jointly predicts BDI/E cognitive states and user utterances and serves as both a user simulator and an evaluation platform, using a three-tier evaluation framework that covers turn-level fidelity, trajectory-level state dynamics, and task-level composite scoring. Trained via the SaA annotation pipeline on 150,454 user-turn samples, it achieves 77.6% emotion accuracy and distinguishes six commercial agents by their cognitive influence in 3600 trials, moving evaluation from terminal judgment to process tracking.
What carries the argument
CogWM, the LLM-based user model that jointly predicts BDI/E cognitive states and utterances to simulate and evaluate state evolution across dialogue turns.
If this is right
- Dialogue evaluation can move from surface text or terminal scores to explicit tracking of cognitive state trajectories.
- Agents can be ranked by measurable effects on user beliefs, desires, intentions, and emotions rather than response quality alone.
- The three-tier framework supplies turn-level, trajectory-level, and task-level scores that together quantify influence processes.
- CogWM can function as a controllable simulator for testing influence strategies before deployment.
Where Pith is reading between the lines
- The same state-tracking approach could be applied to non-commercial domains such as education or health dialogues to monitor intended mindset shifts.
- Combining CogWM outputs with physiological or behavioral signals from real users would test whether simulated states align with observable influence.
- Process-level metrics might reveal unintended cognitive side effects of persuasive systems that terminal scores overlook.
Load-bearing premise
The Summarize-and-Allocate annotation pipeline on dialogue data produces reliable labels for BDI/E cognitive states that match real user cognition.
What would settle it
Direct comparison of CogWM state trajectories against self-reported or measured BDI/E changes from human participants exposed to the same dialogues.
Figures




read the original abstract
Social influence dialogue changes user behavior by altering internal cognitive states. The central evaluation question is whether the user's beliefs, desires, intentions, and emotions measurably change over the course of conversation, a process-oriented criterion that neither surface-level text metrics (BLEU/ROUGE) nor single-score LLM judgments can capture. We propose the \textbf{Cog}nitive \textbf{W}orld \textbf{M}odel \textbf{(CogWM)}, an LLM-based user model that reframes multi-turn dialogue evaluation from ``what did the user say'' to ``how did the user's internal cognitive state evolves.'' CogWM jointly predicts BDI/E cognitive states and user utterances and serves as both a user simulator and an evaluation platform, using a three-tier evaluation framework that covers turn-level fidelity, trajectory-level state dynamics, and task-level composite scoring. Trained via our \textbf{S}ummarize-\textbf{a}nd-\textbf{A}llocate \textbf{(SaA)} annotation pipeline on 150,454 user-turn samples across four social influence scenarios, CogWM achieves 77.6\% emotion accuracy (2.1$\times$ over GPT-5.5). In 3600 multi-agent discrimination trials, it distinguishes six commercial agents by their cognitive influence, with Llama-4-Scout ranking first (CTS +0.233). CogWM moves social influence dialogue evaluation from terminal judgment to process tracking. We have released our code\footnote{\scriptsize Code: https://github.com/lucianma05-create/CogWM} and models\footnote{Model: https://www.modelscope.cn/models/LucianMa/CogWM-14B}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CogWM, an LLM-based user model that jointly predicts BDI/E cognitive states and user utterances to reframe social influence dialogue evaluation from surface text metrics to process-level tracking of internal state evolution. It introduces a SaA annotation pipeline applied to 150,454 turns across four scenarios, a three-tier evaluation framework (turn-level fidelity, trajectory-level dynamics, task-level scoring), reports 77.6% emotion accuracy (2.1× GPT-5.5) and successful discrimination of six commercial agents in 3600 trials (e.g., Llama-4-Scout CTS +0.233), and releases code and models.
Significance. If the SaA labels validly capture cognitive changes, CogWM would provide a novel process-oriented evaluation platform for social influence that goes beyond BLEU/ROUGE or single-score judgments. The explicit release of code (https://github.com/lucianma05-create/CogWM) and models is a clear strength for reproducibility.
major comments (2)
- [Methods (SaA annotation pipeline)] Methods section on SaA pipeline and training data: The central claim that CogWM tracks real process-level influence by modeling BDI/E state evolution requires the SaA annotations (on 150,454 turns) to produce labels that reflect actual internal cognitive changes. No direct validation against human self-reports, psychological scales, or controlled cognitive measurements is described; all metrics including the 77.6% emotion accuracy and agent discrimination results are computed against these labels. This risks the three-tier framework evaluating annotation consistency rather than ground-truth influence processes.
- [Results (multi-agent discrimination)] Results section on multi-agent discrimination trials: The claim that CogWM distinguishes six commercial agents by cognitive influence in 3600 trials is load-bearing for the evaluation platform contribution, yet the abstract and reported results provide no details on statistical significance testing, variance across trials, or comparison to non-cognitive baselines for the composite task-level scoring.
minor comments (2)
- [Abstract] Abstract: The baseline comparison '2.1× over GPT-5.5' lacks specification of the exact model variant, prompting strategy, and whether the same SaA labels were used for the GPT evaluation.
- [Introduction] Notation: BDI/E is used throughout without an explicit expansion or definition on first use, which may reduce clarity for readers outside cognitive modeling.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment point by point below.
read point-by-point responses
-
Referee: [Methods (SaA annotation pipeline)] Methods section on SaA pipeline and training data: The central claim that CogWM tracks real process-level influence by modeling BDI/E state evolution requires the SaA annotations (on 150,454 turns) to produce labels that reflect actual internal cognitive changes. No direct validation against human self-reports, psychological scales, or controlled cognitive measurements is described; all metrics including the 77.6% emotion accuracy and agent discrimination results are computed against these labels. This risks the three-tier framework evaluating annotation consistency rather than ground-truth influence processes.
Authors: We agree this is a substantive limitation: the SaA pipeline generates labels via LLM summarization and allocation without direct anchoring to human self-reports or validated psychological instruments, so reported metrics reflect fidelity to those labels rather than independently verified cognitive change. The BDI/E framework itself is drawn from established psychology literature, but that does not substitute for empirical validation of the annotations. In revision we will add an explicit Limitations subsection that states this gap and sketches a protocol for future human-subject validation studies. revision: partial
-
Referee: [Results (multi-agent discrimination)] Results section on multi-agent discrimination trials: The claim that CogWM distinguishes six commercial agents by cognitive influence in 3600 trials is load-bearing for the evaluation platform contribution, yet the abstract and reported results provide no details on statistical significance testing, variance across trials, or comparison to non-cognitive baselines for the composite task-level scoring.
Authors: We accept the criticism. The current manuscript reports only point estimates for the composite task-level scores. In the revised version we will supply (i) p-values from appropriate significance tests across the 3600 trials, (ii) standard deviations or confidence intervals to indicate variance, and (iii) direct comparisons against non-cognitive baselines (surface metrics and standard LLM judges) so readers can assess the incremental value of the cognitive-state tracking. revision: yes
Circularity Check
No circularity; derivation is self-contained via supervised training on annotations and separate evaluation.
full rationale
The abstract and provided text describe CogWM as trained via the SaA annotation pipeline on 150,454 samples, then evaluated on separate 3600 multi-agent trials for metrics like 77.6% emotion accuracy. No equations, self-citations, or load-bearing steps are quoted that reduce any prediction or claim to its own inputs by construction (e.g., no fitted parameter renamed as prediction, no uniqueness theorem from self-citation, no ansatz smuggled in). The three-tier framework measures against held-out labels and trials, keeping the chain independent of the target results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
, title =
Bratman, Michael E. , title =. 1987 , publisher =
1987
-
[2]
and Georgeff, Michael P
Rao, Anand S. and Georgeff, Michael P. , title =. Proceedings of the Second International Conference on Principles of Knowledge Representation and Reasoning (KR) , year =
-
[3]
Bordini, Rafael H. and H\". Programming Multi-Agent Systems in. 2007 , publisher =
2007
-
[4]
arXiv preprint arXiv:2302.02083 , year =
Kosinski, Michal , title =. arXiv preprint arXiv:2302.02083 , year =
-
[5]
Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
Sap, Maarten and LeBras, Ronan and Fried, Daniel and Choi, Yejin , title =. Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
-
[6]
Proceedings of the 8th SIGdial Workshop on Discourse and Dialogue (SIGdial) , year =
Schatzmann, Jost and Thomson, Blaise and Young, Steve , title =. Proceedings of the 8th SIGdial Workshop on Discourse and Dialogue (SIGdial) , year =
-
[7]
Ma, Minghui and Guo, Bin and Yang, Runze and Chen, Mengqi and Liu, Yan and Liu, Jingqi and Pei, Yahan and Ma, Xuehao and Zhang, Qiuyun and Yu, Zhiwen , title =. arXiv preprint arXiv:2605.22602 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
and Yu, Zhou and Gratch, Jonathan , title =
Chawla, Kushal and Shi, Weiyan and Zhang, Jingwen and Lucas, Gale M. and Yu, Zhou and Gratch, Jonathan , title =. Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics (EACL) , year =
-
[9]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL) , year =
Kong, Lingzhen and Jin, Chuhao , title =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL) , year =
-
[11]
Frontiers of Computer Science , volume =
Chen, Mengqi and Guo, Bin and Wang, Hao and Li, Haoyu and Zhao, Qian and Liu, Jingqi and Ding, Yasan and Pan, Yan and Yu, Zhiwen , title =. Frontiers of Computer Science , volume =. 2025 , number =
2025
-
[12]
LLMs-as-Judges: A Comprehensive Survey on LLM-based Evaluation Methods
Li, Haitao and Dong, Qian and Chen, Junjie and Su, Huixue and Zhou, Yujia and Ai, Qingyao and Ye, Ziyi and Liu, Yiqun , title =. arXiv preprint arXiv:2412.05579 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Findings of the Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
Xu, Yan and Jiang, Jie , title =. Findings of the Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
-
[14]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL) , year =
Deng, Yang and Zhang, Wenxuan and Yuan, Yifei and Lam, Wai , title =. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL) , year =
-
[15]
Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics (ACL) , year =
Papineni, Kishore and Roukos, Salim and Ward, Todd and Zhu, Wei-Jing , title =. Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics (ACL) , year =
-
[16]
Proceedings of the ACL-04 Workshop: Text Summarization Branches Out , year =
Lin, Chin-Yew , title =. Proceedings of the ACL-04 Workshop: Text Summarization Branches Out , year =
-
[17]
, title =
Belz, Anya and Mille, Simon and Howcroft, David M. , title =. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL) , year =
-
[18]
Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics (ACL) , year =
Liu, Siyang and Zheng, Chujie and Demasi, Orianna and Sabour, Sahand and Li, Yu and Yu, Zhou and Jiang, Yong and Huang, Minlie , title =. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics (ACL) , year =
-
[19]
Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL) , year =
Wang, Xuewei and Shi, Weiyan and Kim, Richard and Oh, Yoojung and Yang, Sijia and Zhang, Jingwen and Yu, Zhou , title =. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL) , year =
-
[20]
Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL) , year =
Liu, Zeming and Wang, Haifeng and Niu, Zheng-Yu and Wu, Hua and Che, Wanxiang and Liu, Ting , title =. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL) , year =
-
[21]
Proceedings of the Eighth International Joint Conference on Natural Language Processing (IJCNLP) , year =
Li, Yanran and Su, Hui and Shen, Xiaoyu and Li, Wenjie and Cao, Ziqiang and Niu, Shuzi , title =. Proceedings of the Eighth International Joint Conference on Natural Language Processing (IJCNLP) , year =
-
[22]
Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING) , year =
Luo, Xiang and Tang, Zhiwen and Wang, Jin and Zhang, Xuejie , title =. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING) , year =
2024
-
[23]
, title =
Chang, Serina and Anderson, Ashton and Hofman, Jake M. , title =. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL) , year =
-
[24]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL) , year =
Kong, Chuyi and Fan, Yaxin and Wan, Xiang and Jiang, Feng and Wang, Benyou , title =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL) , year =
-
[25]
and Zhang, Hao and Gonzalez, Joseph E
Zheng, Lianmin and Chiang, Wei-Lin and Sheng, Ying and Zhuang, Siyuan and Wu, Zhanghao and Zhuang, Yonghao and Lin, Zi and Li, Zhuohan and Li, Dacheng and Xing, Eric P. and Zhang, Hao and Gonzalez, Joseph E. and Stoica, Ion , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[26]
Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL) , year =
Tu, Quan and Li, Yanran and Cui, Jianwei and Wang, Bin and Wen, Ji-Rong and Yan, Rui , title =. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL) , year =
-
[27]
Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence (IJCAI) , year =
Peng, Wei and Hu, Yue and Xing, Luxi and Xie, Yuqiang and Sun, Yajing and Li, Yunpeng , title =. Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence (IJCAI) , year =
-
[28]
Yang, An and Li, Anfeng and Yang, Baosong and Zhang, Beichen and Hui, Binyuan and Zheng, Bo and Yu, Bowen and Gao, Chang and Huang, Chengren and Lv, Chenxu and Zheng, Chujie and Liu, Dayiheng and Zhou, Fan and Huang, Fei and Hu, Feng and Ge, Hao and Wei, Haoran and Lin, Huan and Tang, Jialong and Yang, Jian and Tu, Jianhong and Zhang, Jianwei and Yang, Ji...
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , title =
Hu, Edward J. and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , title =. Proceedings of the Tenth International Conference on Learning Representations (ICLR) , year =
-
[30]
2024 , howpublished =
verl: Volcano Engine Reinforcement Learning for. 2024 , howpublished =
2024
-
[31]
arXiv preprint arXiv:2602.15763 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
arXiv preprint , year =
-
[33]
and Oren, Nir , title =
Dennis, Louise A. and Oren, Nir , title =. Proceedings of the 20th International Conference on Autonomous Agents and MultiAgent Systems (AAMAS) , year =
-
[34]
Findings of the Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
Li, Jiangnan and Lin, Zheng and Fu, Peng and Wang, Weiping , title =. Findings of the Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
-
[35]
Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING) , year =
Xu, Wei and others , title =. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING) , year =
2024
-
[36]
arXiv preprint arXiv:2306.15253 , year =
Qiu, Shuwen and Liu, Mingdian and Li, Hengli and Zhu, Song-Chun and Zheng, Zilong , title =. arXiv preprint arXiv:2306.15253 , year =
-
[37]
arXiv preprint arXiv:2501.15355 , year =
Yang, Bo and Guo, Jiaxian and Iwasawa, Yusuke and Matsuo, Yutaka , title =. arXiv preprint arXiv:2501.15355 , year =
-
[38]
Findings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL) , year =
Jafari, Aida and others , title =. Findings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL) , year =
-
[39]
ACM SIGKDD Explorations Newsletter , volume =
Chen, Hongshen and Liu, Xiaorui and Yin, Dawei and Tang, Jiliang , title =. ACM SIGKDD Explorations Newsletter , volume =
-
[40]
Foundations and Trends in Information Retrieval , volume =
Gao, Jianfeng and Galley, Michel and Li, Lihong , title =. Foundations and Trends in Information Retrieval , volume =
-
[41]
and Parikh, Devi and Batra, Dhruv , title =
Lewis, Mike and Yarats, Denis and Dauphin, Yann N. and Parikh, Devi and Batra, Dhruv , title =. Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
-
[42]
2024 , howpublished =
2024
-
[43]
Length-Controlled AlpacaEval: A Simple Way to Debias Automatic Evaluators
Dubois, Yann and Galambosi, Bal. Length-Controlled. arXiv preprint arXiv:2404.04475 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
and Gonzalez, Joseph E
Chiang, Wei-Lin and Zheng, Lianmin and Sheng, Ying and Angelopoulos, Anastasios Nikolas and Li, Tianle and Li, Dacheng and Zhang, Hao and Zhu, Banghua and Jordan, Michael I. and Gonzalez, Joseph E. and Stoica, Ion , title =. Proceedings of the 41st International Conference on Machine Learning (ICML) , year =
-
[45]
Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL) , year =
Bosselut, Antoine and Rashkin, Hannah and Sap, Maarten and Malaviya, Chaitanya and. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL) , year =
-
[46]
IEEE Access , volume =
Poria, Soujanya and Majumder, Navonil and Mihalcea, Rada and Hovy, Eduard , title =. IEEE Access , volume =
-
[47]
and Lansky, Amy L
Georgeff, Michael P. and Lansky, Amy L. , title =. Proceedings of the Sixth National Conference on Artificial Intelligence (AAAI) , year =
-
[48]
Decision-Making in an Embedded Reasoning System , booktitle =
Ingrand, Fran. Decision-Making in an Embedded Reasoning System , booktitle =. 1989 , pages =
1989
-
[49]
Proceedings of the IEEE , volume =
Young, Steve and Ga. Proceedings of the IEEE , volume =
-
[50]
Neural User Simulation for Corpus-based Policy Optimisation of Spoken Dialogue Systems , booktitle =
Kreyssig, Florian and Casanueva, I\. Neural User Simulation for Corpus-based Policy Optimisation of Spoken Dialogue Systems , booktitle =. 2018 , pages =
2018
-
[51]
Shi, Weiyan and Qian, Kun and Wang, Xuewei and Yu, Zhou , title =. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP) , year =
2019
-
[52]
Proceedings of the 18th China National Conference on Computational Linguistics (CCL) , year =
Hou, Yutai and Fang, Meng and Che, Wanxiang and Liu, Ting , title =. Proceedings of the 18th China National Conference on Computational Linguistics (CCL) , year =
-
[53]
Findings of the Association for Computational Linguistics (ACL) , year =
Zheng, Chujie and Sabour, Sahand and Wen, Jiaxin and Zhang, Zheng and Huang, Minlie , title =. Findings of the Association for Computational Linguistics (ACL) , year =
-
[54]
Artificial Intelligence Review , volume =
Mehta, Yash and Majumder, Navonil and Gelbukh, Alexander and Cambria, Erik , title =. Artificial Intelligence Review , volume =
-
[55]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL) , year =
Wang, Kuang and Li, Xianfei and Yang, Shenghao and Zhou, Li and Jiang, Feng and Li, Haizhou , title =. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL) , year =
-
[56]
arXiv preprint arXiv:2502.00640 , note =
Wu, Shirley and others , title =. arXiv preprint arXiv:2502.00640 , note =
-
[57]
Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
Xu, Yangyang and Hu, Jinpeng and Zhao, Zhuoer and Duan, Zhangling and Sun, Xiao and Yang, Xun , title =. Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
-
[58]
Findings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL) , year =
Zhang, Xinjie and Wang, Wenxuan and Jin, Qin , title =. Findings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL) , year =
-
[59]
Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
Li, Dawei and Jiang, Bohan and Huang, Liangjie and Beigi, Alimohammad and Zhao, Chengshuai and Tan, Zhen and Bhattacharjee, Amrita and Jiang, Yuxuan and Chen, Canyu and Wu, Tianhao and Shu, Kai and Cheng, Lu and Liu, Huan , title =. Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
-
[60]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL) , year =
Chen, Ruirui and Jiang, Weifeng and Qin, Chengwei and Tan, Cheston , title =. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL) , year =
-
[61]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Zhang, Xuanming and Chen, Yuxuan and Yeh, Min-Hsuan and Li, Yixuan , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[62]
Proceedings of the 31st International Conference on Computational Linguistics (COLING) , year =
Fu, Yumeng and Wu, Junjie and Wang, Zhongjie and Zhang, Meishan and Shan, Lili and Wu, Yulin and Liu, Bingquan , title =. Proceedings of the 31st International Conference on Computational Linguistics (COLING) , year =
-
[63]
Findings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL) , year =
Feng, Xueyang and Zhang, Jingsen and Tang, Jiakai and Li, Wei and Cai, Guohao and Chen, Xu and Dai, Quanyu and Zhu, Yue and Dong, Zhenhua , title =. Findings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL) , year =
-
[64]
arXiv preprint arXiv:2603.00552 , year =
Zhang, Shiya and others , title =. arXiv preprint arXiv:2603.00552 , year =
-
[65]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL) , year =
Chen, Zhuang and Wu, Jincenzi and Zhou, Jinfeng and Wen, Bosi and Bi, Guanqun and Jiang, Gongyao and Cao, Yaru and Hu, Mengting and Lai, Yunghwei and Xiong, Zexuan and Huang, Minlie , title =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL) , year =
-
[66]
arXiv preprint arXiv:2410.13648 , year =
Gu, Yuling and Tafjord, Oyvind and Kim, Hyunwoo and Moore, Jared and Le Bras, Ronan and Clark, Peter and Choi, Yejin , title =. arXiv preprint arXiv:2410.13648 , year =
-
[67]
Transactions of the Association for Computational Linguistics (TACL) , volume =
Jones, Cameron and Trott, Sean and Bergen, Benjamin , title =. Transactions of the Association for Computational Linguistics (TACL) , volume =
-
[68]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL) , year =
Xiao, Yufan and others , title =. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL) , year =
-
[69]
Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
Bortoletto, Matteo and Ruhdorfer, Constantin and Bulling, Andreas , title =. Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
-
[70]
A Survey of Large Language Models
Zhao, Wayne Xin and Zhou, Kun and Li, Junyi and Tang, Tianyi and Wang, Xiaolei and Hou, Yupeng and Min, Yingqian and Zhang, Beichen and Zhang, Junjie and Dong, Zican and Du, Yifan and Yang, Chen and Chen, Yushuo and Chen, Zhipeng and Jiang, Jinhao and Ren, Ruiyang and Li, Yifan and Tang, Xinyu and Liu, Zikang and Liu, Peiyu and Nie, Jian-Yun and Wen, Ji-R...
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.