AURORA: Asymmetry and Update-Induced Rotation for Robust Hallucination Detection in Large Language Models
Pith reviewed 2026-06-30 07:20 UTC · model grok-4.3
The pith
Hallucinated answers induce asymmetric and misaligned gradient updates on LLM weights that faithful answers do not.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
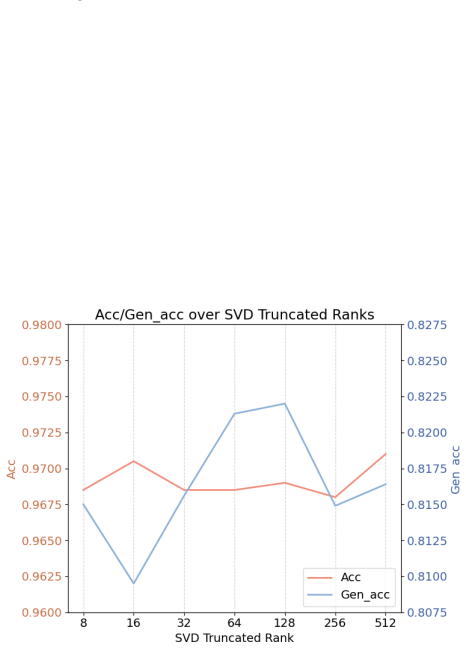
Hallucinated and faithful answers induce qualitatively different gradient update patterns on the model's parameters. Specifically, hallucinated samples trigger asymmetric and structurally misaligned gradients, which can be captured through two complementary features: the skewness of the cosine similarity distribution between weight matrices and their gradient update directions, and the rotation ratio, which quantifies how much the gradient update reorients the singular-vector basis of weight matrices via SVD.
What carries the argument
Skewness of the cosine-similarity distribution between weight matrices and their gradients, together with the SVD rotation ratio of singular vectors induced by those gradients.
If this is right
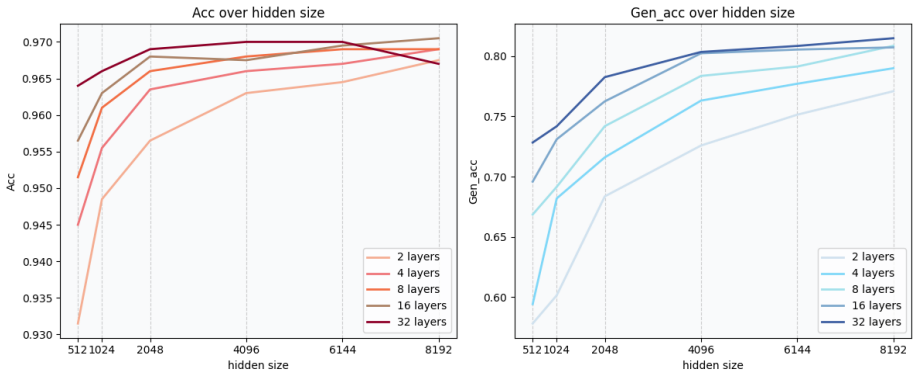
- Strong detection performance holds across four model families and four benchmark datasets.
- Performance scales with model size.
- The same features transfer to out-of-domain tasks including mathematical reasoning and vision-language scenarios.
- Cross-dataset degradation is reduced compared with output-level or static-probe baselines.
Where Pith is reading between the lines
- The features could be computed on a single forward-backward pass during inference without needing multiple samples.
- Similar gradient signatures might mark other kinds of output errors such as logical inconsistencies or arithmetic mistakes.
- If the patterns prove stable, parameter-update statistics could become a general probe for output quality in deployed systems.
- The approach implies that training-like signals remain informative even after pre-training is complete.
Load-bearing premise
Observed differences in gradient patterns are caused by hallucination status rather than response length, topic, or model architecture.
What would settle it
Computing the skewness and rotation-ratio features on a new dataset where hallucinated and faithful answers produce statistically indistinguishable gradient statistics would falsify the claim that the features discriminate hallucination status.
Figures

read the original abstract
Large Language Models (LLMs) have demonstrated remarkable capabilities across a wide range of natural language processing tasks. However, their tendency to generate hallucinations, namely factually incorrect or unfaithful outputs, poses a critical obstacle to their deployment in high-stakes applications. Although recent hallucination detection methods have made encouraging progress, they typically rely on costly output-level consistency checks or static hidden-state probes that capture shallow dataset-specific patterns, leading to substantial degradation under cross-dataset evaluation. In this work, we propose AURORA, a novel hallucination detection framework that shifts the focus from static representations to the weight-gradient dynamics of LLMs. Our key insight is that hallucinated and faithful answers induce qualitatively different gradient update patterns on the model's parameters. Specifically, hallucinated samples trigger asymmetric and structurally misaligned gradients, which can be captured through two complementary features: (1) the skewness of the cosine similarity distribution between weight matrices and their gradient update directions, and (2) the rotation ratio, which quantifies how much the gradient update reorients the singular-vector basis of weight matrices via SVD. AURORA achieves strong hallucination detection performance across four model families and four benchmark datasets. Further analyses demonstrate that our method scales effectively across model sizes and transfers to out-of-domain tasks, including mathematical reasoning and vision-language scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes AURORA, a hallucination detection framework for LLMs that shifts focus from output consistency or static hidden states to weight-gradient dynamics during inference. The central claim is that hallucinated responses induce asymmetric and misaligned gradient updates, captured by two features: (1) skewness of the cosine-similarity distribution between weight matrices and gradient directions, and (2) a rotation ratio quantifying reorientation of the singular-vector basis via SVD. The authors report strong detection performance across four model families and four benchmarks, with scaling across model sizes and transfer to out-of-domain tasks such as mathematical reasoning and vision-language scenarios.
Significance. If the results hold after controlling for confounds, the work would introduce a dynamics-based approach to hallucination detection that could improve robustness over existing methods reliant on dataset-specific patterns. The use of SVD-derived rotation and distributional skewness on gradients is a novel technical angle; credit is due for attempting cross-model and cross-task evaluation, though the absence of parameter-free derivations or machine-checked elements limits the strength of the contribution.
major comments (2)
- [Experiments / Analysis sections (referenced via abstract claims)] The central attribution of the skewness and rotation-ratio features specifically to hallucination status (rather than response length, token entropy, or prediction difficulty) is load-bearing for all cross-dataset and cross-task claims in the abstract. No section demonstrates that these metrics remain discriminative after matching or regressing out length/entropy; if the separation collapses under such controls, the claimed robustness would not follow.
- [Abstract and claimed analyses] The abstract asserts transfer to mathematical reasoning and vision-language tasks, but without quantitative results, ablation tables, or confound analysis in the provided text, it is impossible to assess whether the gradient features generalize or merely track task difficulty. This directly affects the load-bearing claim of qualitative difference induced by factual incorrectness.
minor comments (2)
- [Method] Notation for the rotation ratio and SVD procedure should be formalized with explicit equations early in the method section to avoid ambiguity in how the singular-vector basis reorientation is quantified.
- [Experiments] The manuscript would benefit from explicit comparison tables against recent gradient- or uncertainty-based baselines to clarify incremental gains.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The two major comments highlight important gaps in controlling for potential confounds and in providing quantitative support for out-of-domain transfer claims. We agree that these elements are necessary to substantiate the robustness assertions and will revise the manuscript to address them directly.
read point-by-point responses
-
Referee: [Experiments / Analysis sections (referenced via abstract claims)] The central attribution of the skewness and rotation-ratio features specifically to hallucination status (rather than response length, token entropy, or prediction difficulty) is load-bearing for all cross-dataset and cross-task claims in the abstract. No section demonstrates that these metrics remain discriminative after matching or regressing out length/entropy; if the separation collapses under such controls, the claimed robustness would not follow.
Authors: We agree that demonstrating the features' specificity to hallucination status, independent of response length, token entropy, and prediction difficulty, is essential. The current manuscript does not include explicit matching or regression controls for these variables. In the revision we will add new experiments that (i) match hallucinated and faithful samples on length and entropy, (ii) regress out these factors from the skewness and rotation-ratio scores, and (iii) report the resulting AUROC/AUPRC to confirm that discriminative power is retained. revision: yes
-
Referee: [Abstract and claimed analyses] The abstract asserts transfer to mathematical reasoning and vision-language tasks, but without quantitative results, ablation tables, or confound analysis in the provided text, it is impossible to assess whether the gradient features generalize or merely track task difficulty. This directly affects the load-bearing claim of qualitative difference induced by factual incorrectness.
Authors: The abstract references transfer to mathematical reasoning and vision-language scenarios, yet the manuscript currently lacks the corresponding quantitative tables, ablations, and confound controls. We will expand the relevant analysis section with (i) numerical detection performance on these out-of-domain tasks, (ii) ablation studies isolating the contribution of each AURORA feature, and (iii) the same length/entropy regression controls applied to the new tasks, thereby providing the missing evidence for generalization beyond task difficulty. revision: yes
Circularity Check
No circularity: features computed directly from gradients without fitting or self-reference
full rationale
The paper's central derivation defines the two features (skewness of cosine-similarity distribution between weights and gradients; SVD-based rotation ratio) as direct computations on the observed gradient updates induced by hallucinated vs. faithful responses. No parameter is fitted to the target detection labels, no self-citation supplies a uniqueness theorem or ansatz, and the quantities are not renamed versions of known empirical patterns. The method therefore remains self-contained against external benchmarks and does not reduce to its inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[3]
and Zettlemoyer, Luke , title =
Joshi, Mandar and Choi, Eunsol and Weld, Daniel S. and Zettlemoyer, Luke , title =. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics , month =. 2017 , address =
2017
-
[4]
and Salakhutdinov, Ruslan and Manning, Christopher D
Yang, Zhilin and Qi, Peng and Zhang, Saizheng and Bengio, Yoshua and Cohen, William W. and Salakhutdinov, Ruslan and Manning, Christopher D. , booktitle=
-
[7]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[8]
2025 , eprint=
Gemma 3 Technical Report , author=. 2025 , eprint=
2025
-
[9]
2026 , eprint=
Ministral 3 , author=. 2026 , eprint=
2026
-
[13]
Proceedings of the AAAI Conference on Artificial Intelligence , author=
FindTheFlaws: Annotated Errors for Detecting Flawed Reasoning and Scalable Oversight Research , volume=. Proceedings of the AAAI Conference on Artificial Intelligence , author=. 2026 , month=. doi:10.1609/aaai.v40i44.41123 , abstractNote=
-
[14]
2025 , eprint=
gpt-oss-120b & gpt-oss-20b Model Card , author=. 2025 , eprint=
2025
-
[15]
Advances in Neural Information Processing Systems , volume=
A theoretical study on bridging internal probability and self-consistency for LLM reasoning , author=. Advances in Neural Information Processing Systems , volume=
-
[16]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Halloc: Token-level localization of hallucinations for vision language models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[18]
Edward J Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Lu Wang and Weizhu Chen , booktitle=. Lo. 2022 , url=
2022
-
[19]
2025 , eprint=
HARP: Hallucination Detection via Reasoning Subspace Projection , author=. 2025 , eprint=
2025
-
[20]
Proceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence,
Detecting Hallucination in Large Language Models Through Deep Internal Representation Analysis , author =. Proceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence,. 2025 , month =. doi:10.24963/ijcai.2025/929 , url =
-
[21]
LLM-Check: Investigating Detection of Hallucinations in Large Language Models , url =
Sriramanan, Gaurang and Bharti, Siddhant and Sadasivan, Vinu Sankar and Saha, Shoumik and Kattakinda, Priyatham and Feizi, Soheil , booktitle =. LLM-Check: Investigating Detection of Hallucinations in Large Language Models , url =. doi:10.52202/079017-1077 , editor =
-
[22]
Nature , volume=
Detecting hallucinations in large language models using semantic entropy , author=. Nature , volume=. 2024 , publisher=
2024
-
[24]
and Arroyo, Gilberto Gonzalez and Dey, Tamal K
Samaga, Shreyas N. and Arroyo, Gilberto Gonzalez and Dey, Tamal K. H allu Z ig: Hallucination Detection using Zigzag Persistence. Proceedings of the 19th Conference of the E uropean Chapter of the A ssociation for C omputational L inguistics (Volume 1: Long Papers). 2026. doi:10.18653/v1/2026.eacl-long.159
- [26]
-
[27]
Ekaterina Fadeeva, Aleksandr Rubashevskii, Artem Shelmanov, Sergey Petrakov, Haonan Li, Hamdy Mubarak, Evgenii Tsymbalov, Gleb Kuzmin, Alexander Panchenko, Timothy Baldwin, Preslav Nakov, and Maxim Panov. 2024. https://doi.org/10.18653/v1/2024.findings-acl.558 Fact-checking the output of large language models via token-level uncertainty quantification . I...
-
[28]
Sebastian Farquhar, Jannik Kossen, Lorenz Kuhn, and Yarin Gal. 2024. Detecting hallucinations in large language models using semantic entropy. Nature, 630(8017):625--630
2024
-
[29]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. 2024. The llama 3 herd of models. arXiv preprint arXiv:2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2022. https://openreview.net/forum?id=nZeVKeeFYf9 Lo RA : Low-rank adaptation of large language models . In International Conference on Learning Representations
2022
- [31]
-
[32]
Chaoya Jiang, Hongrui Jia, Mengfan Dong, Wei Ye, Haiyang Xu, Ming Yan, Ji Zhang, and Shikun Zhang. 2024. https://doi.org/10.1145/3664647.3680576 Hal-eval: A universal and fine-grained hallucination evaluation framework for large vision language models . In Proceedings of the 32nd ACM International Conference on Multimedia, MM '24, page 525–534, New York, ...
-
[33]
Weld, and Luke Zettlemoyer
Mandar Joshi, Eunsol Choi, Daniel S. Weld, and Luke Zettlemoyer. 2017. Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, Canada. Association for Computational Linguistics
2017
-
[34]
Junyi Li, Xiaoxue Cheng, Xin Zhao, Jian-Yun Nie, and Ji-Rong Wen. 2023. https://doi.org/10.18653/v1/2023.emnlp-main.397 H alu E val: A large-scale hallucination evaluation benchmark for large language models . In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 6449--6464, Singapore. Association for Computation...
-
[35]
Alexander H. Liu, Kartik Khandelwal, Sandeep Subramanian, Victor Jouault, Abhinav Rastogi, Adrien Sadé, Alan Jeffares, Albert Jiang, Alexandre Cahill, Alexandre Gavaudan, Alexandre Sablayrolles, Amélie Héliou, Amos You, Andy Ehrenberg, Andy Lo, Anton Eliseev, Antonia Calvi, Avinash Sooriyarachchi, Baptiste Bout, Baptiste Rozière, Baudouin De Monicault, Cl...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[36]
Potsawee Manakul, Adian Liusie, and Mark Gales. 2023. https://doi.org/10.18653/v1/2023.emnlp-main.557 S elf C heck GPT : Zero-resource black-box hallucination detection for generative large language models . In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 9004--9017, Singapore. Association for Computational...
-
[37]
Qwen Team . 2026. https://qwen.ai/blog?id=qwen3.5 Qwen3.5 : Towards native multimodal agents
2026
-
[38]
Pranav Rajpurkar, Robin Jia, and Percy Liang. 2018. https://doi.org/10.18653/v1/P18-2124 Know what you don ' t know: Unanswerable questions for SQ u AD . In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 784--789, Melbourne, Australia. Association for Computational Linguistics
-
[39]
Weihang Su, Changyue Wang, Qingyao Ai, Yiran Hu, Zhijing Wu, Yujia Zhou, and Yiqun Liu. 2024. https://doi.org/10.18653/v1/2024.findings-acl.854 Unsupervised real-time hallucination detection based on the internal states of large language models . In Findings of the Association for Computational Linguistics: ACL 2024, pages 14379--14391, Bangkok, Thailand....
-
[40]
Gemma Team, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ramé, Morgane Rivière, Louis Rouillard, Thomas Mesnard, Geoffrey Cideron, Jean bastien Grill, Sabela Ramos, Edouard Yvinec, Michelle Casbon, Etienne Pot, Ivo Penchev, Gaël Liu, Francesco Visin, Kathleen Kenealy, Lucas Bey...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Cohen, Ruslan Salakhutdinov, and Christopher D
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William W. Cohen, Ruslan Salakhutdinov, and Christopher D. Manning. 2018. HotpotQA : A dataset for diverse, explainable multi-hop question answering. In Conference on Empirical Methods in Natural Language Processing ( EMNLP )
2018
-
[43]
Yakir Yehuda, Itzik Malkiel, Oren Barkan, Jonathan Weill, Royi Ronen, and Noam Koenigstein. 2024. https://doi.org/10.18653/v1/2024.acl-long.506 I nterrogate LLM : Zero-resource hallucination detection in LLM -generated answers . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9333--...
-
[44]
Zhenliang Zhang, Xinyu Hu, Huixuan Zhang, Junzhe Zhang, and Xiaojun Wan. 2025. https://doi.org/10.18653/v1/2025.acl-long.880 ICR probe: Tracking hidden state dynamics for reliable hallucination detection in LLM s . In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 17986--18002, Vienna...
-
[45]
Zhi Zhou, Tan Yuhao, Zenan Li, Yuan Yao, Lan-Zhe Guo, Yu-Feng Li, and Xiaoxing Ma. 2026. A theoretical study on bridging internal probability and self-consistency for llm reasoning. Advances in Neural Information Processing Systems, 38:87380--87413
2026
-
[46]
CoRR , volume =
Joshua Goodman , title =. CoRR , volume =. 2001 , url =
2001
-
[47]
Joshua T. Goodman. A bit of progress in language modeling. Computer Speech & Language. 2001. doi:10.1006/csla.2001.0174
-
[48]
CoRR , volume =
Rebecca Hwa , title =. CoRR , volume =. 1999 , url =
1999
-
[49]
Supervised Grammar Induction using Training Data with Limited Constituent Information
Hwa, Rebecca. Supervised Grammar Induction using Training Data with Limited Constituent Information. Proceedings of the 37th Annual Meeting of the Association for Computational Linguistics. 1999
1999
-
[50]
, title =
Jurafsky, Daniel and Martin, James H. , title =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.