Metadata, Structure, or Strategy? A Decomposition of RAG Context Enrichment
Pith reviewed 2026-06-30 07:33 UTC · model grok-4.3
The pith
Richer RAG context does not yield better answers; alignment with model capabilities does.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
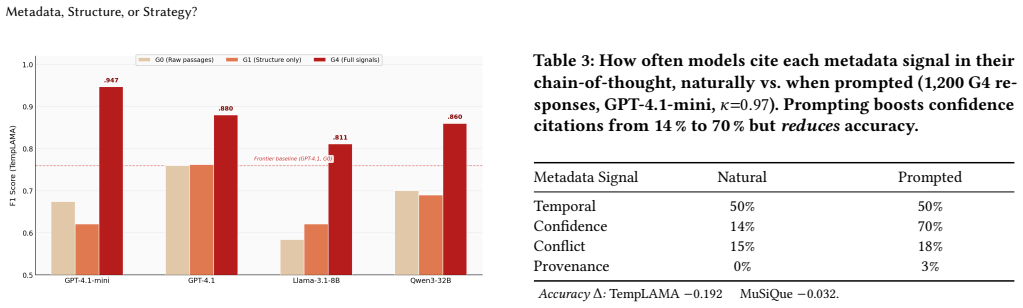
The assumption that richer context yields better answers does not hold. Most enrichment reduces accuracy. Models prompted to use confidence scores comply correctly yet produce worse answers, a gap between utilization and accuracy that no prior work has measured. What determines answer quality is not how much metadata the context carries but whether the model can act on it for the given task. When metadata and retrieval strategy are aligned with model capabilities, a smaller model outperforms a frontier model by 19 F1 points. These findings motivate a processability hierarchy that predicts, from pre-training properties alone, which metadata a model can productively use, reframing RAG design a
What carries the argument
The controlled experiment isolating the effects of metadata, structure, and retrieval strategy across multiple enrichment levels and models.
If this is right
- Most enrichment reduces accuracy on the benchmarks tested.
- Models follow prompts to use confidence scores but this leads to lower answer quality.
- Alignment of metadata and strategy with model capabilities allows smaller models to outperform larger ones by 19 F1 points.
- RAG design should focus on model-context alignment instead of accumulating more metadata.
- A processability hierarchy based on pre-training can predict which metadata will be useful.
Where Pith is reading between the lines
- RAG practitioners could test model processability on sample data before choosing enrichment methods.
- The hierarchy might help select appropriate models for specific retrieval tasks without extensive testing.
- Similar alignment issues may arise in other systems that augment language models with external data.
- Future experiments could vary the models' pre-training to see if the hierarchy holds across different training regimes.
Load-bearing premise
The experiments isolate metadata, structure, and strategy effects without confounding from the specific benchmarks or models used.
What would settle it
Finding that enrichment consistently improves accuracy when tested on additional models or benchmarks not included in the original study would challenge the central claim.
Figures
read the original abstract
Retrieval-augmented generation (RAG) systems increasingly enrich retrieved passages by attaching quality metadata, structuring them into explicit records, and adopting multi-hop retrieval strategies that accumulate evidence across steps. These changes assume that richer context yields better answers, yet existing evaluations cannot test this because they vary all three factors at once. We isolate each factor in a controlled experiment across six benchmarks, four models from three families, and five enrichment levels, totaling over 24,000 evaluated responses. The assumption does not hold. Most enrichment reduces accuracy. Models prompted to use confidence scores comply correctly yet produce worse answers, a gap between utilization and accuracy that no prior work has measured. What determines answer quality is not how much metadata the context carries but whether the model can act on it for the given task. When metadata and retrieval strategy are aligned with model capabilities, a smaller model outperforms a frontier model by 19 F1 points. These findings motivate a processability hierarchy that predicts, from pre-training properties alone, which metadata a model can productively use, reframing RAG design as a question of model-context alignment rather than metadata accumulation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that the common assumption in RAG—that enriching retrieved passages with metadata, explicit structure, or multi-hop strategies improves answer quality—does not hold. In a controlled experiment across six benchmarks, four models from three families, and five enrichment levels (over 24,000 responses), the authors isolate metadata, structure, and strategy effects. They report that most enrichments reduce accuracy, that models correctly utilize prompted confidence scores yet produce worse answers, and that performance depends on alignment between enrichment and model capabilities (with a smaller model outperforming a frontier model by 19 F1 points under alignment). The work proposes a processability hierarchy based on pre-training properties to guide RAG design toward model-context alignment rather than metadata accumulation.
Significance. If the isolation and aggregate findings hold, the result is significant: it provides large-scale empirical evidence against the default 'more context is better' heuristic in RAG, reframing design around alignment and introducing a predictive hierarchy. The scale (24k responses, multiple models and benchmarks) and the novel measurement of the utilization-accuracy gap are strengths that could influence both system building and evaluation practices.
major comments (2)
- [Abstract / Experimental Design] Abstract and experimental design description: the claim that the five enrichment levels 'successfully isolate' the individual effects of metadata, structure, and strategy is load-bearing for the central finding that 'most enrichment reduces accuracy.' No interaction tests, per-benchmark breakdowns, or controls for benchmark properties (question type, retrieval difficulty) are reported, leaving open the possibility that aggregate results are driven by benchmark-specific interactions rather than general effects.
- [Abstract] Abstract: the support for all quantitative claims (accuracy reductions, utilization-accuracy gap, 19 F1 outperformance) rests on a large experiment, yet the abstract provides no details on statistical methods, error bars, exact isolation procedure, or data exclusion rules. This directly affects verifiability of the central claim that enrichment mostly harms performance.
minor comments (2)
- [Abstract] The term 'processability hierarchy' is introduced in the abstract without a concise definition or reference to its derivation, which reduces immediate clarity for readers.
- [Abstract] The 19 F1 point claim would benefit from explicit identification of the models, enrichment condition, and benchmark(s) involved to allow readers to assess its scope.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed report. The two major comments raise valid points about verifiability and the strength of the isolation claim. We respond to each below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract / Experimental Design] Abstract and experimental design description: the claim that the five enrichment levels 'successfully isolate' the individual effects of metadata, structure, and strategy is load-bearing for the central finding that 'most enrichment reduces accuracy.' No interaction tests, per-benchmark breakdowns, or controls for benchmark properties (question type, retrieval difficulty) are reported, leaving open the possibility that aggregate results are driven by benchmark-specific interactions rather than general effects.
Authors: The experimental design isolates factors by constructing five enrichment levels that add exactly one variable at a time while holding retrieval and prompt structure constant; this procedure is described in Section 3. The full manuscript already reports per-benchmark results (Section 4, Table 2 and Figure 3) showing the accuracy reduction is consistent across all six benchmarks. Interaction tests and explicit controls for question type or retrieval difficulty were not performed, as the primary analysis focused on main effects across a deliberately diverse benchmark set. We agree these additions would strengthen the claim and will include interaction analyses plus a short discussion of benchmark properties in the revised version. revision: yes
-
Referee: [Abstract] Abstract: the support for all quantitative claims (accuracy reductions, utilization-accuracy gap, 19 F1 outperformance) rests on a large experiment, yet the abstract provides no details on statistical methods, error bars, exact isolation procedure, or data exclusion rules. This directly affects verifiability of the central claim that enrichment mostly harms performance.
Authors: The abstract is a concise summary; full methodological details appear in Sections 3 and 4 and the appendix (isolation procedure, paired significance tests with error bars, and exclusion criteria for malformed outputs). We will revise the abstract to add one sentence noting the controlled incremental design, the use of statistical testing, and that full procedures and exclusion rules are provided in the paper body. revision: yes
Circularity Check
Empirical study with no circular derivation
full rationale
The paper reports controlled experiments varying metadata, structure, and strategy across fixed benchmarks and models, measuring accuracy outcomes directly. No equations, fitted parameters, or self-citations are used to derive the central claims; results follow from the experimental measurements themselves. The processability hierarchy is presented as a post-hoc interpretation of the observed alignment effects rather than a deductive step that reduces to prior inputs. No load-bearing step matches any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The factors of metadata, structure, and retrieval strategy can be varied independently in RAG pipelines.
invented entities (1)
-
processability hierarchy
no independent evidence
Reference graph
Works this paper leans on
- [1]
-
[2]
Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. 2023. Self-RAG: Learning to retrieve, generate, and critique through self-reflection. In The Twelfth International Conference on Learning Representations
2023
-
[3]
Wenhu Chen, Xinyi Wang, and William Yang Wang. 2021. A dataset for answer- ing time-sensitive questions. InProceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks
2021
- [4]
-
[5]
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, Dasha Metropolitansky, Robert Osazuwa Ness, and Jonathan Larson. 2025. From local to global: A graph RAG approach to query-focused sum- marization. https://arxiv.org/abs/2404.16130 arXiv preprint arXiv:2404.16130
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Shahul Es, Jithin James, Luis Espinosa Anke, and Steven Schockaert. 2024. RA- GAS: Automated evaluation of retrieval augmented generation. InProceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations. 150–158
2024
-
[7]
Soyeong Jeong, Jinheon Baek, Sukmin Cho, Sung Ju Hwang, and Jong Park
-
[8]
Adaptive-RAG: Learning to adapt retrieval-augmented large language models through question complexity. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). Mexico City, Mexico, 7036–7050. doi:10.18653/v1/2024.naacl-long.389
-
[9]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. 2020. Retrieval-augmented generation for knowledge-intensive NLP tasks. InProceedings of the 34th Inter- national Conference on Neural Information Processing Systems (...
2020
-
[10]
Dong Li, Yichen Niu, Ying Ai, Xiang Zou, Biqing Qi, and Jianxing Liu. 2025. T-GraG: A dynamic GraphRAG framework for resolving temporal conflicts and redundancy in knowledge retrieval. InProceedings of the 33rd ACM International Conference on Multimedia
2025
- [11]
-
[12]
Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2024. Lost in the middle: How language models use long contexts.Transactions of the Association for Computational Linguistics 12 (2024), 157–173
2024
-
[13]
Grégoire Mialon, Clémentine Fourrier, Thomas Wolf, Yann LeCun, and Thomas Scialom. 2023. GAIA: A benchmark for general AI assistants. InThe Twelfth International Conference on Learning Representations
2023
-
[14]
Jon Saad-Falcon, Omar Khattab, Christopher Potts, and Matei Zaharia. [n. d.]. ARES: An automated evaluation framework for retrieval-augmented generation systems. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers)
2024
- [15]
-
[16]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, A. J. Ostrow, Akhila Ananthram, et al
-
[17]
OpenAI GPT-5 system card. arXiv preprint arXiv:2601.03267
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
James Thorne, Andreas Vlachos, Christos Christodoulopoulos, and Arpit Mittal
-
[19]
InPro- ceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers)
FEVER: A large-scale dataset for fact extraction and verification. InPro- ceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 809–819
2018
-
[20]
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabhar- wal. 2022. MuSiQue: Multihop questions via single-hop question composition. Transactions of the Association for Computational Linguistics10 (2022), 539–554
2022
-
[21]
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal
-
[22]
Interleaving retrieval with chain-of-thought reasoning for knowledge- intensive multi-step questions. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Toronto, Canada, 10014–10037. doi:10.18653/v1/2023.acl-long.557
-
[23]
Jason Wei, Nguyen Karina, Hyung Won Chung, Yunxin Joy Jiao, Spencer Papay, Amelia Glaese, John Schulman, and William Fedus. 2024. Measuring short-form factuality in large language models. arXiv preprint arXiv:2411.04368
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [24]
-
[25]
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christopher D Manning. 2018. HotpotQA: A dataset for diverse, explainable multi-hop question answering. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 2369–2380
2018
-
[26]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. 2022. ReAct: Synergizing reasoning and acting in language models. InThe Eleventh International Conference on Learning Representations
2022
- [27]
- [28]
-
[29]
Saber Zerhoudi and Michael Granitzer. 2025. UXSim: Towards a hybrid user search simulation. InProceedings of the 34th ACM International Conference on Information and Knowledge Management (CIKM ’25)
2025
-
[30]
Saber Zerhoudi, Michael Granitzer, and Jelena Mitrović. 2026. NuggetIndex: Governed atomic retrieval for maintainable RAG. InProceedings of the 49th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR ’26)
2026
-
[31]
Saber Zerhoudi, Michael Granitzer, Jörg Schlötterer, and Christin Seifert. 2021. Query change as a contextual Markov model for simulating user search behaviour. InProceedings of the Forum for Information Retrieval Evaluation (FIRE 2021). 43– 51
2021
- [32]
-
[33]
Yujia Zhou, Zheng Liu, Jiajie Jin, Jian-Yun Nie, and Zhicheng Dou. 2024. Metacognitive retrieval-augmented large language models. InProceedings of the ACM Web Conference 2024 (WWW ’24). New York, NY, USA, 1453–1463. doi:10.1145/3589334.3645481
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.