Diagnosing and Mitigating Retrieval Bottlenecks in LLM-Based Cold-Start Recommendation
Pith reviewed 2026-06-30 04:27 UTC · model grok-4.3
The pith
Retrieval coverage is the primary bottleneck for LLM-based cold-start recommendation, not reranker quality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
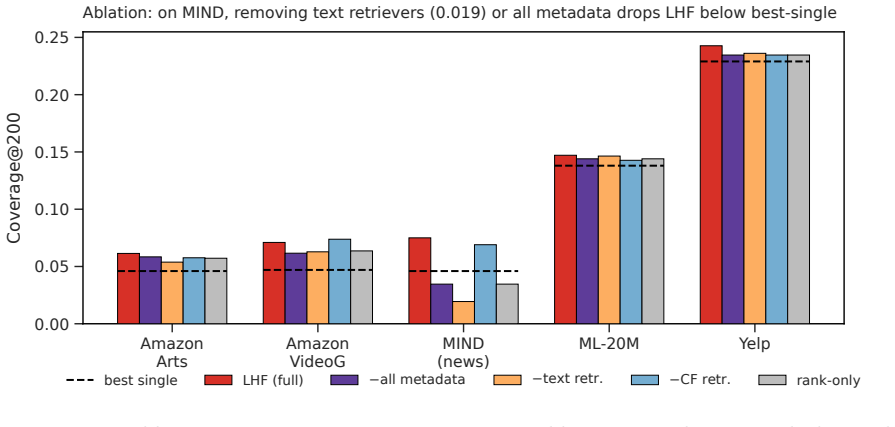
In retrieval-realistic conditions, standard retrievers place the gold item in a 200-item pool only 4.6-22.9% of the time due to 32-91% of targets being brand-new items, while calibrated LLM rerankers fail to consistently outperform baselines even when the item is present; a learned hybrid fusion layer over multi-retriever pools improves coverage but learned non-LLM ranking exploits it better than prompt-level LLM reranking.
What carries the argument
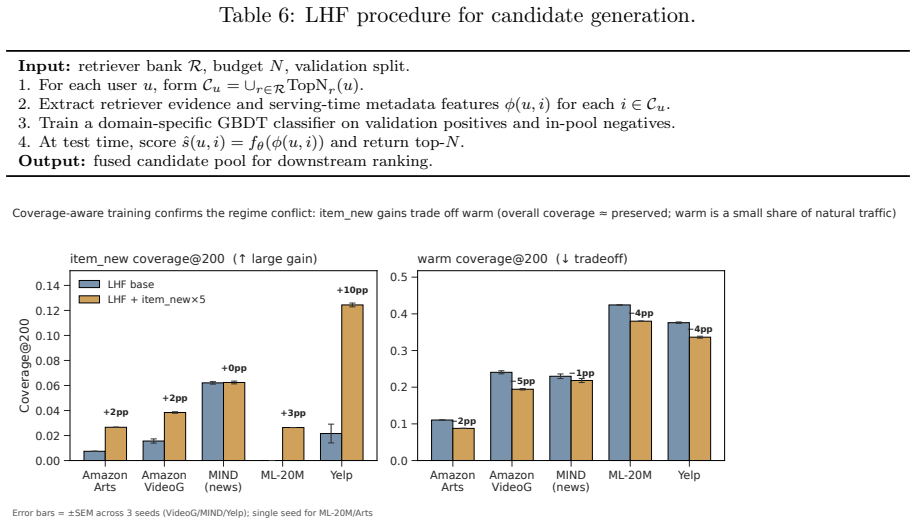
LHF, a validation-trained learned hybrid fusion layer over a multi-retriever union pool, which combines retrieval signals to increase the chance the gold item appears in the candidate set.
If this is right
- LLM rerankers do not consistently beat collaborative and content baselines in positive-controlled regimes across five domains.
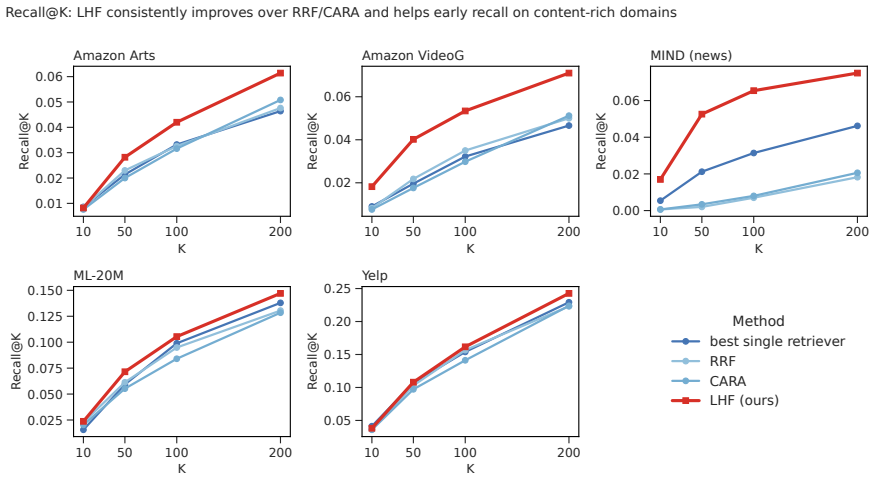
- Single retrievers achieve low coverage of cold-start targets in realistic regimes.
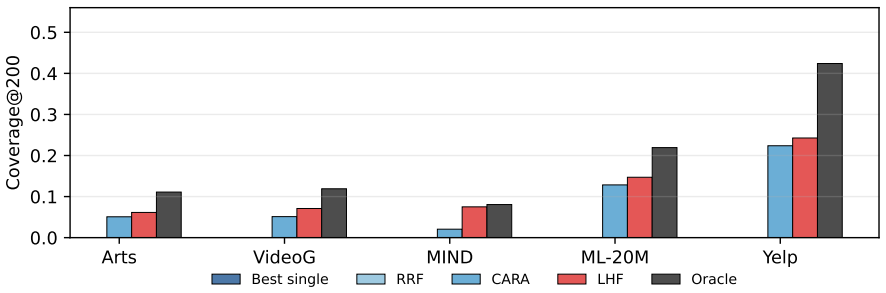
- LHF is the only tested combiner that beats every single retriever on all domains and recovers 17-61% of oracle coverage on content-rich domains.
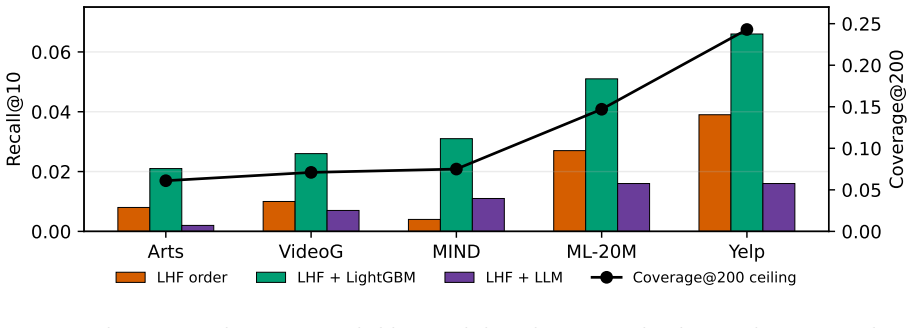
- End-to-end, non-LLM ranking on LHF pools outperforms LLM reranking on the same pools.
- LLMs show semantic advantages mainly in text-rich domains when the item is already retrieved.
Where Pith is reading between the lines
- Recommender pipelines may benefit more from investing in multi-retriever coverage than in LLM reranking layers.
- Future work could test whether fine-tuning LLMs specifically for ranking on these pools closes the gap.
- Domains with strong collaborative signals may need different retrieval strategies than text-rich ones.
Load-bearing premise
The positive-controlled and retrieval-realistic regimes on the five-domain benchmark isolate reranking performance from retrieval coverage without being affected by domain selection or prompt choices.
What would settle it
An experiment showing a single retriever achieving over 50% gold-item coverage in the retrieval-realistic regime on multiple domains, or an LLM reranker that consistently outperforms all baselines in the positive-controlled regime across domains.
Figures

read the original abstract
Large language models (LLMs) are increasingly used as rerankers in recommender systems, with the expectation that semantic understanding will help in cold-start and long-tail regimes. We test this assumption with a five-domain benchmark that explicitly separates reranking quality from retrieval coverage. In a positive-controlled regime where the gold item is guaranteed present, calibrated LLM rerankers fail to consistently outperform strong collaborative and content baselines under natural traffic, and within-family scaling from Qwen3-8B to Qwen3-32B narrows but does not close the gap on most domains. In a retrieval-realistic regime where the gold item is not injected, the bottleneck is more severe: standard single retrievers place the gold item in a 200-item pool only 4.6-22.9% of the time, largely because 32-91% of cold-start targets are brand-new items with no training interactions. We introduce LHF, a validation-trained learned hybrid fusion layer over a multi-retriever union pool, as a retrieval-side realizability baseline. LHF is the only combiner we test that beats every single retriever on all five domains and recovers 17-61% of oracle coverage headroom on content-rich domains, but only 5-7% on collaboratively strong domains. End-to-end experiments reveal the remaining mismatch: learned non-LLM ranking exploits the LHF pool, while prompt-level LLM reranking often degrades it. LLMs exhibit pockets of semantic cold-start advantage, especially in text-rich domains when the item is already present, but this advantage is largely unreachable in current retrieve-then-rerank pipelines. We release the benchmark protocol, splits, prompts, evaluation tooling, and archived reproducibility artifacts: data at https://doi.org/10.5281/zenodo.20991039 and code at https://doi.org/10.5281/zenodo.20993306.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a five-domain benchmark that separates positive-controlled (gold item guaranteed in pool) and retrieval-realistic regimes to diagnose bottlenecks in LLM reranking for cold-start recommendation. It reports that calibrated LLM rerankers do not consistently outperform collaborative and content baselines even when the target is present; in the realistic regime, single retrievers recover the gold item in a 200-item pool only 4.6-22.9% of the time, driven by 32-91% brand-new items with no training interactions. The authors introduce LHF, a validation-trained learned hybrid fusion over multi-retriever unions, which improves coverage over single retrievers on all domains and recovers 17-61% of oracle headroom on content-rich domains (5-7% on collaborative ones). End-to-end results show learned non-LLM ranking benefits from the LHF pool while prompt-based LLM reranking often degrades it, with limited semantic advantages for LLMs in text-rich domains when items are already retrieved. The work releases the benchmark protocol, splits, prompts, evaluation tooling, data, and code.
Significance. If the regime separation holds without domain-selection or prompt-optimization artifacts, the results establish retrieval coverage as the dominant bottleneck in cold-start LLM pipelines and show that LLM semantic advantages remain largely unreachable in standard retrieve-then-rerank setups. The explicit positive-controlled versus realistic comparison, the LHF baseline, and the released artifacts (data at doi:10.5281/zenodo.20991039, code at doi:10.5281/zenodo.20993306) constitute a concrete, reusable contribution that can standardize evaluation in this area.
major comments (1)
- [Abstract] Abstract: The central claim that the five-domain benchmark 'explicitly separates reranking quality from retrieval coverage' is load-bearing for the conclusion that LLM underperformance is not an artifact. However, the reported 32-91% brand-new item rates vary sharply by domain; without explicit ablations on domain-specific cold-start item selection or equalized prompt-engineering effort versus baselines, it remains possible that text-rich domains embed selection effects that favor semantic matching and thereby inflate the apparent retrieval bottleneck relative to collaborative domains.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address the single major comment below.
read point-by-point responses
-
Referee: The central claim that the five-domain benchmark 'explicitly separates reranking quality from retrieval coverage' is load-bearing for the conclusion that LLM underperformance is not an artifact. However, the reported 32-91% brand-new item rates vary sharply by domain; without explicit ablations on domain-specific cold-start item selection or equalized prompt-engineering effort versus baselines, it remains possible that text-rich domains embed selection effects that favor semantic matching and thereby inflate the apparent retrieval bottleneck relative to collaborative domains.
Authors: The regime separation is implemented by construction within each domain: the positive-controlled regime injects the gold item into every candidate pool, enabling measurement of reranking quality conditional on presence, while the realistic regime uses unmodified retrieval output. This within-domain contrast holds irrespective of cross-domain variation in brand-new item rates (which we report transparently as a domain characteristic). The design therefore isolates the two factors without requiring additional domain-specific selection ablations. On prompting, we apply the same calibrated prompt templates and few-shot examples to all LLM rerankers across domains (see Section 4.2); equalizing optimization effort against non-LLM baselines would require an orthogonal experimental axis that falls outside the scope of evaluating standard retrieve-then-rerank pipelines. The observed LLM underperformance in the positive-controlled regime is therefore not an artifact of unequal tuning. We see no need to revise the manuscript on this point. revision: no
Circularity Check
No circularity; purely empirical benchmark study
full rationale
The paper reports experimental results from a five-domain benchmark comparing LLM rerankers against baselines in controlled and realistic retrieval regimes. All central claims (e.g., retrieval coverage rates of 4.6-22.9%, LHF recovering 17-61% headroom) are direct measurements or comparisons on held-out data, with no equations, fitted parameters renamed as predictions, self-definitional constructs, or load-bearing self-citations. The derivation chain is absent; the work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
invented entities (1)
-
LHF
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Recommendation as language processing (rlp): A unified pretrain, personalized prompt and predict paradigm (p5)
Shijie Geng, Shuchang Liu, Zuohui Fu, Yingqiang Ge, and Yongfeng Zhang. Recommendation as language processing (rlp): A unified pretrain, personalized prompt and predict paradigm (p5). InProceedings of the 16th ACM Conference on Recommender Systems, pages 299–315,
-
[2]
doi: 10.1145/3523227.3546767
-
[3]
Keqin Bao, Jizhi Zhang, Yang Zhang, Wenjie Wang, Fuli Feng, and Xiangnan He. Tallrec: An effective and efficient tuning framework to align large language model with recommendation. InProceedings of the 17th ACM Conference on Recommender Systems, pages 1007–1014, 2023. doi: 10.1145/3604915.3608857
-
[4]
Large language models are zero-shot rankers for recommender systems
Yupeng Hou, Junjie Zhang, Zihan Lin, Hongyu Lu, Ruobing Xie, Julian McAuley, and Wayne Xin Zhao. Large language models are zero-shot rankers for recommender systems. In Advances in Information Retrieval: 46th European Conference on Information Retrieval, pages 364–381, 2024
2024
-
[5]
Sichun Luo, Bowei He, Haohan Zhao, Wei Shao, Yanlin Qi, Yinya Huang, Aojun Zhou, Yuxuan Yao, Zongpeng Li, Yuanzhang Xiao, Mingjie Zhan, and Linqi Song. Recranker: Instruction tuning large language model as ranker for top-k recommendation.arXiv preprint arXiv:2312.16018, 2024
arXiv 2024
-
[6]
Is chatgpt a good recommender? a preliminary study.arXiv preprint arXiv:2304.10149, 2023
Junling Liu, Chao Liu, Peilin Zhou, Renjie Lv, Kang Zhou, and Yan Zhang. Is chatgpt a good recommender? a preliminary study.arXiv preprint arXiv:2304.10149, 2023
arXiv 2023
-
[7]
A survey on large language models for recommendation.World Wide Web, 27:1–49, 2024
Likang Wu, Zhi Zheng, Zhaopeng Qiu, Hao Wang, Hongchao Gu, Tingjia Shen, Chuan Qin, Chen Zhu, Hengshu Zhu, Qi Liu, Hui Xiong, and Enhong Chen. A survey on large language models for recommendation.World Wide Web, 27:1–49, 2024. doi: 10.1007/s11280-024-01291-2
-
[8]
Jianghao Lin, Xinyi Dai, Yunjia Xi, Weiwen Liu, Bo Chen, Hao Zhang, Yong Liu, Chuhan Wu, Xiangyang Li, Chenxu Zhu, Huifeng Guo, Yong Yu, Ruiming Tang, and Weinan Zhang. How can recommender systems benefit from large language models: A survey.ACM Transactions on Information Systems, 43(2):28:1–28:47, 2025. doi: 10.1145/3678004
-
[9]
Dropoutnet: Addressing cold start in recommender systems
Maksims Volkovs, Guang Wei Yu, and Tomi Poutanen. Dropoutnet: Addressing cold start in recommender systems. InAdvances in Neural Information Processing Systems, volume 30, 2017
2017
-
[10]
Yongchun Zhu, Ruobing Xie, Fuzhen Zhuang, Kaikai Ge, Ying Sun, Xu Zhang, Leyu Lin, and Juan Cao. Learning to warm up cold item embeddings for cold-start recommendation with 14 meta scaling and shifting networks. InProceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 1167–1176, 2021. doi: 10...
-
[11]
Warm up cold-start advertisements: Improving ctr predictions via learning to learn id embeddings
Feiyang Pan, Shuokai Li, Xiang Ao, Pingzhong Tang, and Qing He. Warm up cold-start advertisements: Improving ctr predictions via learning to learn id embeddings. InProceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 695–704, 2019. doi: 10.1145/3331184.3331268
-
[12]
Melu: Meta-learned user preference estimator for cold-start recommendation
Hoyeop Lee, Jinbae Im, Seongwon Jang, Hyunsouk Cho, and Sehee Chung. Melu: Meta-learned user preference estimator for cold-start recommendation. InProceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pages 1073–1082,
-
[13]
doi: 10.1145/3292500.3330859
-
[14]
Con- trastive learning for cold-start recommendation
Yinwei Wei, Xiang Wang, Qi Li, Liqiang Nie, Yan Li, Xuanping Li, and Tat-Seng Chua. Con- trastive learning for cold-start recommendation. InProceedings of the 29th ACM International Conference on Multimedia, pages 5382–5390, 2021. doi: 10.1145/3474085.3475665
-
[15]
Vbpr: Visual bayesian personalized ranking from implicit feedback
Ruining He and Julian McAuley. Vbpr: Visual bayesian personalized ranking from implicit feedback. InProceedings of the Thirtieth AAAI Conference on Artificial Intelligence, pages 144–150, 2016
2016
-
[16]
Bpr: Bayesian personalized ranking from implicit feedback
Steffen Rendle, Christoph Freudenthaler, Zeno Gantner, and Lars Schmidt-Thieme. Bpr: Bayesian personalized ranking from implicit feedback. InProceedings of the Twenty-Fifth Conference on Uncertainty in Artificial Intelligence, pages 452–461, 2009
2009
-
[17]
Neural graph collaborative filtering
Xiang Wang, Xiangnan He, Meng Wang, Fuli Feng, and Tat-Seng Chua. Neural graph collaborative filtering. InProceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 165–174, 2019. doi: 10.1145/3331184. 3331267
-
[18]
Lightgcn: Simplifying and powering graph convolution network for recommendation
Xiangnan He, Kuan Deng, Xiang Wang, Yan Li, Yongdong Zhang, and Meng Wang. Lightgcn: Simplifying and powering graph convolution network for recommendation. InProceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 639–648, 2020. doi: 10.1145/3397271.3401063
-
[19]
Self-attentive sequential recommendation
Wang-Cheng Kang and Julian McAuley. Self-attentive sequential recommendation. In2018 IEEE International Conference on Data Mining, pages 197–206, 2018
2018
-
[20]
Nils Reimers and Iryna Gurevych. Sentence-bert: Sentence embeddings using siamese bert- networks. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, pages 3982–3992, 2019. doi: 10.18653/v1/D19-1410
-
[21]
C-pack: Packed resources for general chinese embeddings.arXiv preprint arXiv:2309.07597, 2023
Shitao Xiao, Zheng Liu, Peitian Zhang, Niklas Muennighoff, Defu Lian, and Jian-Yun Nie. C-pack: Packed resources for general chinese embeddings.arXiv preprint arXiv:2309.07597, 2023
Pith/arXiv arXiv 2023
-
[22]
Jianlv Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu. Bge m3- embedding: Multi-lingual, multi-functionality, multi-granularity text embeddings through self-knowledge distillation.arXiv preprint arXiv:2402.03216, 2024. 15
Pith/arXiv arXiv 2024
-
[23]
Text embeddings by weakly-supervised contrastive pre-training
Liang Wang, Nan Yang, Xiaolong Huang, Binxing Jiao, Linjun Yang, Daxin Jiang, Rangan Majumder, and Furu Wei. Text embeddings by weakly-supervised contrastive pre-training. arXiv preprint arXiv:2212.03533, 2022
Pith/arXiv arXiv 2022
-
[24]
Dense passage retrieval for open-domain ques- tion answering,
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. Dense passage retrieval for open-domain question answering. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, pages 6769–6781, 2020. doi: 10.18653/v1/2020.emnlp-main.550
-
[25]
Xinyang Yi, Ji Yang, Lichan Hong, Derek Zhiyuan Cheng, Lukasz Heldt, Aditee Kumthekar, Zhe Zhao, Li Wei, and Ed H. Chi. Sampling-bias-corrected neural modeling for large corpus item recommendations. InProceedings of the 13th ACM Conference on Recommender Systems, pages 269–277, 2019. doi: 10.1145/3298689.3346996
-
[26]
Gordon V. Cormack, Charles L. A. Clarke, and Stefan Buettcher. Reciprocal rank fusion outperforms condorcet and individual rank learning methods. InProceedings of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 758–759, 2009. doi: 10.1145/1571941.1572114
-
[27]
Lightgbm: A highly efficient gradient boosting decision tree
Guolin Ke, Qi Meng, Thomas Finley, Taifeng Wang, Wei Chen, Weidong Ma, Qiwei Ye, and Tie-Yan Liu. Lightgbm: A highly efficient gradient boosting decision tree. InAdvances in Neural Information Processing Systems, volume 30, 2017
2017
-
[28]
Are we really making much progress? a worrying analysis of recent neural recommendation approaches
Maurizio Ferrari Dacrema, Paolo Cremonesi, and Dietmar Jannach. Are we really making much progress? a worrying analysis of recent neural recommendation approaches. InProceedings of the 13th ACM Conference on Recommender Systems, pages 101–109, 2019. doi: 10.1145/ 3298689.3347058
arXiv 2019
-
[29]
Maurizio Ferrari Dacrema, Simone Boglio, Paolo Cremonesi, and Dietmar Jannach. A troubling analysis of reproducibility and progress in recommender systems research.ACM Transactions on Information Systems, 39(2):20:1–20:49, 2021. doi: 10.1145/3434185
-
[30]
On target item sampling in offline recommender system evaluation
Rocio Canamares and Pablo Castells. On target item sampling in offline recommender system evaluation. InProceedings of the 14th ACM Conference on Recommender Systems, pages 259–268, 2020. doi: 10.1145/3383313.3412259
-
[31]
Ekaterina Lemdiasova and Nikita Zmanovskii. Diagnosing llm-based rerankers in cold- start recommender systems: Coverage, exposure and practical mitigations.arXiv preprint arXiv:2604.16318, 2026
Pith/arXiv arXiv 2026
-
[32]
Bridging language and items for retrieval and recommendation.arXiv preprint arXiv:2403.03952, 2024
Yupeng Hou, Jiacheng Li, Zhankui He, An Yan, Xiusi Chen, and Julian McAuley. Bridging language and items for retrieval and recommendation.arXiv preprint arXiv:2403.03952, 2024
Pith/arXiv arXiv 2024
-
[33]
Amazon Reviews 2023.https://amazon-reviews-2023.github.io/, 2023
McAuley Lab. Amazon Reviews 2023.https://amazon-reviews-2023.github.io/, 2023
2023
-
[34]
Mind: A large-scale dataset for news recommendation
Fangzhao Wu, Ying Qiao, Jiun-Hung Chen, Chuhan Wu, Tao Qi, Jianxun Lian, Danyang Liu, Xing Xie, Jianfeng Gao, Winnie Wu, and Ming Zhou. Mind: A large-scale dataset for news recommendation. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 3597–3606, 2020. doi: 10.18653/v1/2020.acl-main.331
-
[35]
F. Maxwell Harper and Joseph A. Konstan. The movielens datasets: History and context.ACM Transactions on Interactive Intelligent Systems, 5(4):19:1–19:19, 2015. doi: 10.1145/2827872. 16
-
[36]
Yelp Open Dataset.https://www.yelp.com/dataset, 2024
Yelp Inc. Yelp Open Dataset.https://www.yelp.com/dataset, 2024
2024
-
[37]
Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
An Yang et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
Pith/arXiv arXiv 2025
-
[38]
Llama 3.3 70B Instruct Model Card
Meta AI. Llama 3.3 70B Instruct Model Card. https://huggingface.co/meta-llama/ Llama-3.3-70B-Instruct, 2024. 17
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.