Online Data Selection for Instruction Tuning via Gaussian Processes
Pith reviewed 2026-06-30 06:58 UTC · model grok-4.3
The pith
GAIA uses global Gaussian Process estimation to select high-utility data during online LLM instruction tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
GAIA formulates data valuation as a global estimation process that employs Gaussian Process regression to model continuous utility manifolds across semantic space. It employs an adaptive strategy fusion mechanism to dynamically prioritize high-utility samples. By casting the strategy-posterior update as an instance of the classical fixed-share Hedge framework, the method inherits a dynamic-regret guarantee that characterizes robustness under non-stationary quality scores, and empirical results on three datasets show significant outperformance over baselines such as GREATs.
What carries the argument
Gaussian Process regression that models the continuous utility manifold in semantic space, updated through an adaptive fusion rule derived from the fixed-share Hedge algorithm.
If this is right
- GAIA significantly outperforms state-of-the-art batch-constrained baselines on three instruction-tuning datasets.
- The method remains robust when quality scores change during the course of training.
- It supplies a scalable procedure for efficient instruction tuning that still carries a dynamic-regret bound.
- The regret analysis directly quantifies how well the selector tracks the best data under non-stationary conditions.
Where Pith is reading between the lines
- The same global-manifold view could be tested on other sequential selection problems where the value of each item drifts over time.
- If the manifold assumption weakens at very large model scales, replacing the Gaussian Process with a neural surrogate would be a direct next experiment.
- The approach suggests a general template for turning any online expert-tracking algorithm into a data-selection procedure by reinterpreting posterior weights as utility estimates.
Load-bearing premise
Data utility forms a continuous manifold in semantic space that Gaussian Process regression can reliably estimate from the observed samples during training.
What would settle it
On a new dataset the data points selected by GAIA produce no measurable gain in final model accuracy or loss compared with random or batch-constrained selection, or the Gaussian Process predictions show no correlation with the actual performance contribution of each sample.
Figures

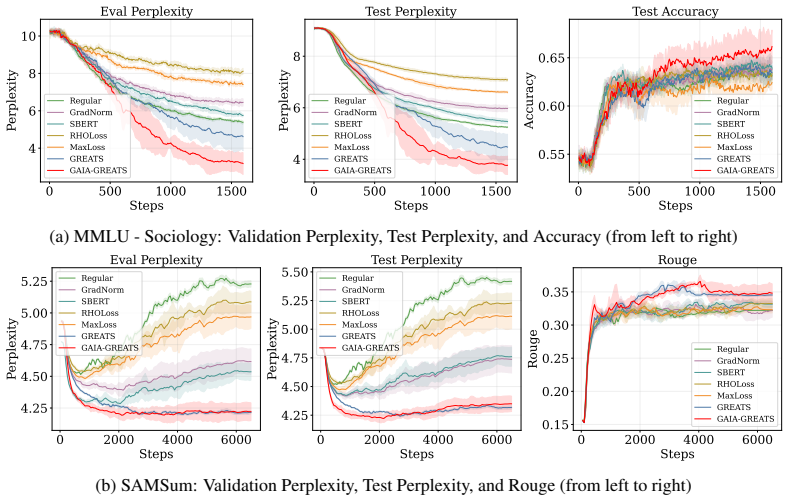
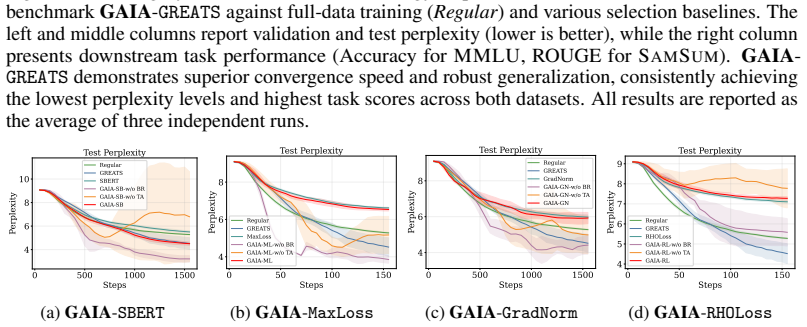



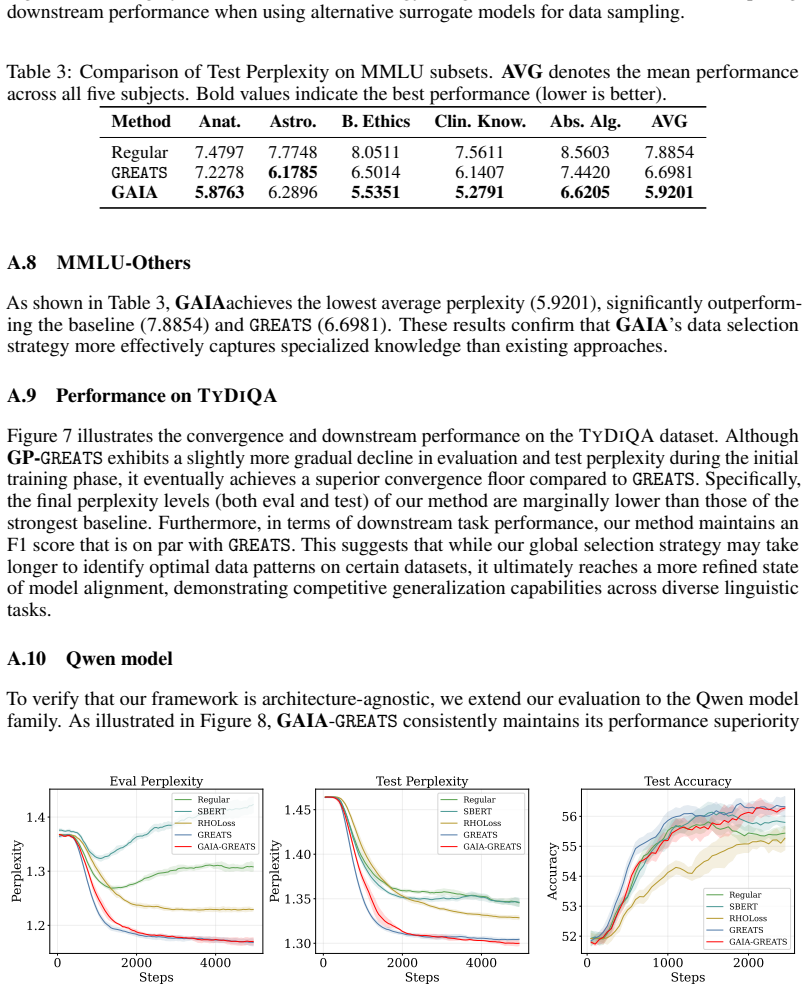





read the original abstract
With Large Language Model (LLM) pre-training and fine-tuning shifting its focus from data volume to data quality, quality data selection has emerged as a critical research topic. Existing online data selection methods for LLM training are typically "batch-constrained", limiting optimization to local utility within random batches. To overcome this, we propose GAIA (Global Adaptive Instruction tuning via GAussian processes), a framework that formulates data valuation as a global estimation process. GAIA employs Gaussian Process regression to model continuous utility manifolds across the semantic space, utilizing an adaptive strategy fusion mechanism to dynamically prioritize high-utility samples. By casting the strategy-posterior update as an instance of the classical fixed-share Hedge framework for tracking the best expert, we inherit a dynamic-regret guarantee that characterizes GAIA's robustness under non-stationary quality scores during training. Empirical evaluations on three datasets demonstrate that GAIA significantly outperforms state-of-the-art baselines like \greats, establishing our method as a scalable and robust solution for efficient instruction tuning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes GAIA for online data selection in LLM instruction tuning. It models data utility as a continuous manifold in semantic space via Gaussian Process regression for global estimation, uses an adaptive strategy fusion mechanism to prioritize samples, and reduces the strategy-posterior update to the classical fixed-share Hedge framework to inherit a dynamic-regret guarantee under non-stationary quality scores. Empirical results on three datasets claim significant outperformance over baselines including GREATs.
Significance. If the GP regression reliably produces global utility estimates from the limited online observations and the reduction to fixed-share Hedge is exact (without hidden bias from the GP posterior), the work would supply a theoretically grounded global alternative to batch-constrained selection methods together with a dynamic-regret bound. The explicit inheritance of an existing regret guarantee is a positive feature when the mapping is shown to preserve the required conditions.
major comments (1)
- [Abstract] Abstract: the central claim that Gaussian Process regression yields reliable global utility estimates across semantic space (used both for prioritization and to justify the exact fixed-share Hedge reduction) rests on the unexamined assumption that the utility surface is sufficiently smooth and that sparse online samples suffice for accurate extrapolation. No derivation, kernel specification, or error analysis is supplied to support this step; if the GP estimates are no better than local heuristics, the dynamic-regret bound applies only to a noisy expert and the reported gains over GREATs cannot be attributed to the global formulation.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on the Gaussian Process assumptions. We address the concern point-by-point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that Gaussian Process regression yields reliable global utility estimates across semantic space (used both for prioritization and to justify the exact fixed-share Hedge reduction) rests on the unexamined assumption that the utility surface is sufficiently smooth and that sparse online samples suffice for accurate extrapolation. No derivation, kernel specification, or error analysis is supplied to support this step; if the GP estimates are no better than local heuristics, the dynamic-regret bound applies only to a noisy expert and the reported gains over GREATs cannot be attributed to the global formulation.
Authors: We agree the abstract is concise and omits explicit kernel details and error bounds. The method section specifies a Gaussian Process with RBF kernel over semantic embeddings, where the posterior mean provides the global utility estimate used for prioritization and strategy fusion. The fixed-share Hedge reduction is exact on the sequence of fused posteriors and the dynamic-regret guarantee holds irrespective of GP accuracy (it bounds regret against the best dynamic expert sequence). Empirical gains over GREATs are shown via ablations that isolate the global component. In revision we will add a subsection with kernel specification, the standard GP smoothness assumption, and a reference to posterior convergence rates under accumulating observations to justify extrapolation from sparse samples. revision: yes
Circularity Check
No circularity: external inheritance of regret bound and independent GP modeling
full rationale
The paper's derivation casts the strategy-posterior update explicitly as an instance of the classical fixed-share Hedge framework (an external result) to inherit its dynamic-regret guarantee, while using Gaussian Process regression to model utility as a continuous manifold. Neither step reduces a claimed prediction or result to its own inputs by definition, nor relies on load-bearing self-citation, ansatz smuggling, or renaming of known results. The outperformance claim is presented as an empirical outcome rather than a mathematical necessity forced by the method's construction. The chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025. 9
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
arXiv preprint arXiv:2504.00993 (2025)
Juncheng Wu, Wenlong Deng, Xingxuan Li, Sheng Liu, Taomian Mi, Yifan Peng, Ziyang Xu, Yi Liu, Hyunjin Cho, Chang-In Choi, et al. Medreason: Eliciting factual medical reasoning steps in llms via knowledge graphs.arXiv preprint arXiv:2504.00993, 2025
-
[4]
Should chatgpt be biased? challenges and risks of bias in large language models
Emilio Ferrara. Should chatgpt be biased? challenges and risks of bias in large language models. Challenges and Risks of Bias in Large Language Models (October 26, 2023), 2023
2023
-
[5]
Data shapley: Equitable valuation of data for machine learning
Amirata Ghorbani and James Zou. Data shapley: Equitable valuation of data for machine learning. InICML, 2019
2019
-
[6]
Understanding black-box predictions via influence functions
Pang Wei Koh and Percy Liang. Understanding black-box predictions via influence functions. InICML, 2017
2017
-
[7]
Greats: Online selection of high-quality data for llm training in every iteration.Advances in Neural Information Processing Systems, 37:131197–131223, 2024
Jiachen T Wang, Tong Wu, Dawn Song, Prateek Mittal, and Ruoxi Jia. Greats: Online selection of high-quality data for llm training in every iteration.Advances in Neural Information Processing Systems, 37:131197–131223, 2024
2024
-
[8]
Lava: Data valuation without pre-specified learning algorithms
Hoang Anh Just, Feiyang Kang, Tianhao Wang, Yi Zeng, Myeongseob Ko, Ming Jin, and Ruoxi Jia. Lava: Data valuation without pre-specified learning algorithms. InThe Eleventh International Conference on Learning Representations. OpenReview, 2023
2023
-
[9]
Sava: Scalable learning-agnostic data valuation
Samuel Kessler, Tam Le, and Vu Nguyen. Sava: Scalable learning-agnostic data valuation. In The Thirteenth International Conference on Learning Representations, 2025
2025
-
[10]
Kairos: Scalable model-agnostic data valuation.Advances in Neural Information Processing Systems, 2025
Jiongli Zhu, Parjanya Prajakta Prashant, Alex Cloninger, and Babak Salimi. Kairos: Scalable model-agnostic data valuation.Advances in Neural Information Processing Systems, 2025
2025
-
[11]
Shapley-based data valuation for weighted k-nearest neighbors
Guangyi Zhang, Qiyu Liu, and Aristides Gionis. Shapley-based data valuation for weighted k-nearest neighbors. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
-
[12]
What is your data worth to gpt? llm-scale data valuation with influence functions
Sang Keun Choe, Hwijeen Ahn, Juhan Bae, Kewen Zhao, Minsoo Kang, Youngseog Chung, Adithya Pratapa, Willie Neiswanger, Emma Strubell, Teruko Mitamura, et al. What is your data worth to gpt? llm-scale data valuation with influence functions. 2025
2025
-
[13]
Dataset distillation
Tongzhou Wang, Jun-Yan Zhu, Antonio Torralba, and Alexei A Efros. Dataset distillation. In ICML, 2018
2018
-
[14]
Coresets for data-efficient training of machine learning models
Baharan Mirzasoleiman, Jeff Bilmes, and Jure Leskovec. Coresets for data-efficient training of machine learning models. InInternational Conference on Machine Learning, pages 6950–6960. PMLR, 2020
2020
-
[15]
Estimating training data influence by tracing gradient descent.Advances in Neural Information Processing Systems, 33: 19920–19930, 2020
Garima Pruthi, Frederick Liu, Satyen Kale, and Mukund Sundararajan. Estimating training data influence by tracing gradient descent.Advances in Neural Information Processing Systems, 33: 19920–19930, 2020
2020
-
[16]
Rethinking data shapley for data selection tasks: Misleads and merits
Jiachen T Wang, Tianji Yang, James Zou, Yongchan Kwon, and Ruoxi Jia. Rethinking data shapley for data selection tasks: Misleads and merits. InInternational Conference on Machine Learning, pages 52033–52063. PMLR, 2024
2024
-
[17]
Doremi: Optimizing data mixtures speeds up language model pretraining.Advances in Neural Information Processing Systems, 36: 69798–69818, 2023
Sang Michael Xie, Hieu Pham, Xuanyi Dong, Nan Du, Hanxiao Liu, Yifeng Lu, Percy S Liang, Quoc V Le, Tengyu Ma, and Adams Wei Yu. Doremi: Optimizing data mixtures speeds up language model pretraining.Advances in Neural Information Processing Systems, 36: 69798–69818, 2023
2023
-
[18]
Less: selecting influential data for targeted instruction tuning
Mengzhou Xia, Sadhika Malladi, Suchin Gururangan, Sanjeev Arora, and Danqi Chen. Less: selecting influential data for targeted instruction tuning. InProceedings of the 41st International Conference on Machine Learning, pages 54104–54132, 2024
2024
-
[19]
Qurating: Selecting high- quality data for training language models
Alexander Wettig, Aatmik Gupta, Saumya Malik, and Danqi Chen. Qurating: Selecting high- quality data for training language models. InForty-first International Conference on Machine Learning. 10
-
[20]
An empirical study of example forgetting during deep neural network learning
Mariya Toneva, Alessandro Sordoni, Remi Tachet des Combes, Adam Trischler, Yoshua Bengio, and Geoffrey J Gordon. An empirical study of example forgetting during deep neural network learning. InInternational Conference on Learning Representations, 2019
2019
-
[21]
Deep learning on a data diet: Finding important examples early in training.Advances in neural information processing systems, 34:20596–20607, 2021
Mansheej Paul, Surya Ganguli, and Gintare Karolina Dziugaite. Deep learning on a data diet: Finding important examples early in training.Advances in neural information processing systems, 34:20596–20607, 2021
2021
-
[22]
Beyond neural scaling laws: beating power law scaling via data pruning.Advances in Neural Information Processing Systems, 35:19523–19536, 2022
Ben Sorscher, Robert Geirhos, Shashank Shekhar, Surya Ganguli, and Ari Morcos. Beyond neural scaling laws: beating power law scaling via data pruning.Advances in Neural Information Processing Systems, 35:19523–19536, 2022
2022
-
[23]
Tracking the best expert.Machine Learning, 32(2): 151–178, 1998
Mark Herbster and Manfred K Warmuth. Tracking the best expert.Machine Learning, 32(2): 151–178, 1998
1998
-
[24]
Cambridge University Press, 2006
Nicolò Cesa-Bianchi and Gábor Lugosi.Prediction, Learning, and Games. Cambridge University Press, 2006
2006
-
[25]
Measuring massive multitask language understanding.Proceedings of the International Conference on Learning Representations (ICLR), 2021
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding.Proceedings of the International Conference on Learning Representations (ICLR), 2021
2021
-
[26]
SAMSum corpus: A human-annotated dialogue dataset for abstractive summarization
Bogdan Gliwa, Iwona Mochol, Maciej Biesek, and Aleksander Wawer. SAMSum corpus: A human-annotated dialogue dataset for abstractive summarization. InProceedings of the 2nd Workshop on New Frontiers in Summarization, pages 70–79. Association for Computational Linguistics, November 2019
2019
-
[27]
Clark, Eunsol Choi, Michael Collins, Dan Garrette, Tom Kwiatkowski, Vitaly Nikolaev, and Jennimaria Palomaki
Jonathan H. Clark, Eunsol Choi, Michael Collins, Dan Garrette, Tom Kwiatkowski, Vitaly Nikolaev, and Jennimaria Palomaki. Tydi qa: A benchmark for information-seeking question answering in typologically diverse languages.Transactions of the Association for Computational Linguistics, 2020
2020
-
[28]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chap- lot, Diego de Las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. Mistral 7b.CoRR, abs/2310.06825,
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
doi: 10.48550/ARXIV .2310.06825
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv
-
[33]
Sentence-bert: Sentence embeddings using siamese bert- networks
Nils Reimers and Iryna Gurevych. Sentence-bert: Sentence embeddings using siamese bert- networks. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 11 2019
2019
-
[34]
MIT press Cambridge, MA, 2006
Christopher KI Williams and Carl Edward Rasmussen.Gaussian processes for machine learning, volume 2. MIT press Cambridge, MA, 2006
2006
-
[35]
Tighter bounds on the log marginal likelihood of gaussian process regression using conjugate gradients
Artem Artemev, David R Burt, and Mark van der Wilk. Tighter bounds on the log marginal likelihood of gaussian process regression using conjugate gradients. InInternational Conference on Machine Learning, pages 362–372. PMLR, 2021
2021
-
[36]
Hashimoto
Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. Stanford alpaca: An instruction-following llama model. https://github.com/tatsu-lab/stanford_alpaca, 2023. 11
2023
-
[37]
The flan collection: Designing data and methods for effective instruction tuning
Shayne Longpre, Le Hou, Tu Vu, Albert Webson, Hyung Won Chung, Yi Tay, Denny Zhou, Quoc V Le, Barret Zoph, Jason Wei, et al. The flan collection: Designing data and methods for effective instruction tuning. InInternational Conference on Machine Learning, pages 22631–22648. PMLR, 2023
2023
-
[38]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022
2022
-
[39]
Free dolly: Introducing the world’s first truly open instruction-tuned llm, 2023
Conover Mike, Hayes Matt, Mathur Ankit, Xie Jianwei, Wan Jun, Shah Sam, Ghodsi Ali, Wendell Patrick, Zaharia Matei, and Xin Reynold. Free dolly: Introducing the world’s first truly open instruction-tuned llm, 2023
2023
-
[40]
Openassistant conversations-democratizing large language model alignment.Advances in neural information processing systems, 36:47669–47681, 2023
Andreas Köpf, Yannic Kilcher, Dimitri V on Rütte, Sotiris Anagnostidis, Zhi Rui Tam, Keith Stevens, Abdullah Barhoum, Duc Nguyen, Oliver Stanley, Richárd Nagyfi, et al. Openassistant conversations-democratizing large language model alignment.Advances in neural information processing systems, 36:47669–47681, 2023
2023
-
[41]
Gpytorch: Blackbox matrix-matrix gaussian process inference with gpu acceleration.Advances in neural information processing systems, 31, 2018
Jacob Gardner, Geoff Pleiss, Kilian Q Weinberger, David Bindel, and Andrew G Wilson. Gpytorch: Blackbox matrix-matrix gaussian process inference with gpu acceleration.Advances in neural information processing systems, 31, 2018
2018
-
[42]
Not all samples are created equal: Deep learning with importance sampling
Angelos Katharopoulos and François Fleuret. Not all samples are created equal: Deep learning with importance sampling. In Jennifer G. Dy and Andreas Krause, editors,Proceedings of the 35th International Conference on Machine Learning, ICML 2018, volume 80, pages 2530–2539. PMLR, 2018
2018
-
[43]
Online Batch Selection for Faster Training of Neural Networks
Ilya Loshchilov and Frank Hutter. Online batch selection for faster training of neural networks. CoRR, abs/1511.06343, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[44]
Gomez, Adrien Morisot, Sebastian Farquhar, and Yarin Gal
Sören Mindermann, Jan Markus Brauner, Muhammed Razzak, Mrinank Sharma, Andreas Kirsch, Winnie Xu, Benedikt Höltgen, Aidan N. Gomez, Adrien Morisot, Sebastian Farquhar, and Yarin Gal. Prioritized training on points that are learnable, worth learning, and not yet learnt. InInternational Conference on Machine Learning, ICML 2022, volume 162, pages 15630–1564...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.