Domain Adaptation with Adaptive Imagination for Visual Reinforcement Learning under Limited Target Data
Pith reviewed 2026-06-30 06:23 UTC · model grok-4.3
The pith
AIDA augments limited target data for visual RL by truncating unreliable imagined rollouts with a shift-aware discriminator.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
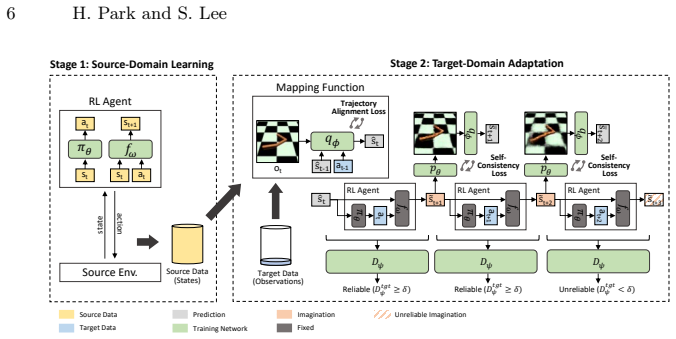
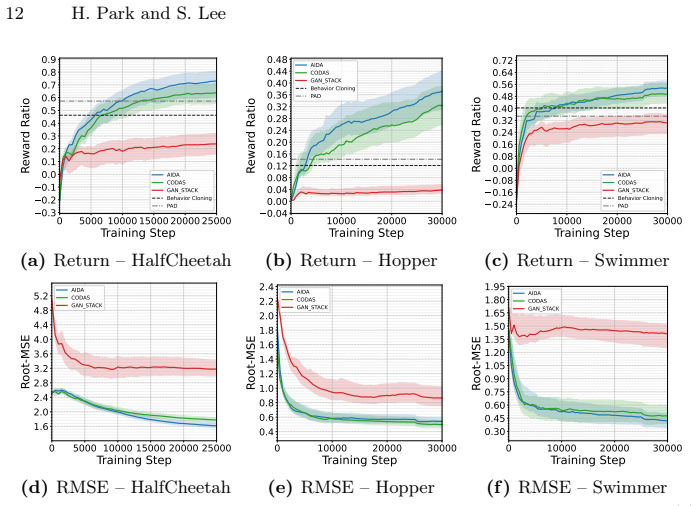
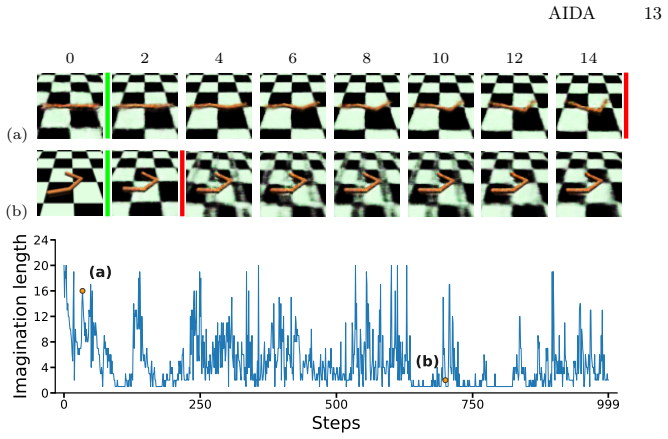
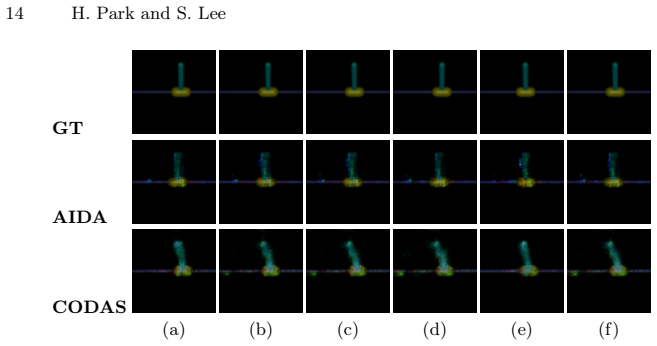
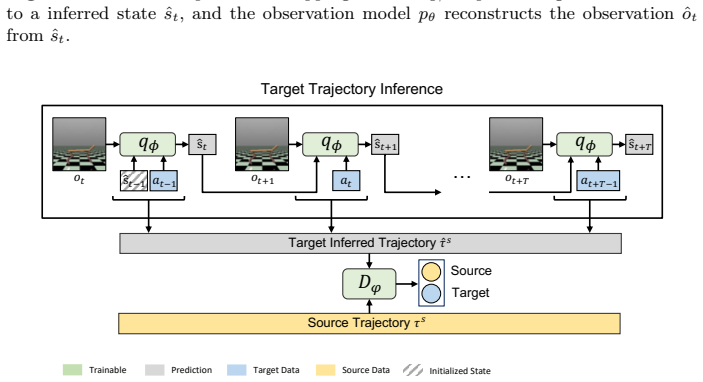
By employing a distribution-shift-aware discriminator that truncates rollouts when imagined transitions drift into low-confidence regions and introducing a self-consistency loss that cycles through state to image observation to state on reliable transitions, AIDA learns semantically meaningful state representations and outperforms baselines across five MuJoCo tasks and two Gymnasium-Robotics tasks under limited target data.
What carries the argument
The adaptive imagination process driven by a distribution-shift-aware discriminator for rollout truncation combined with a self-consistency loss on retained transitions.
If this is right
- Only reliable transitions from imagination contribute to data augmentation.
- The self-consistency loss supplies adaptation signals beyond the limited target data.
- State representations become semantically meaningful for the target domain.
- Performance gains occur without additional target environment interactions.
Where Pith is reading between the lines
- The truncation strategy might allow scaling to environments where data collection is expensive or dangerous.
- Combining this with other DA techniques could further improve results in low-data regimes.
- Similar consistency losses could be explored in non-visual RL settings.
Load-bearing premise
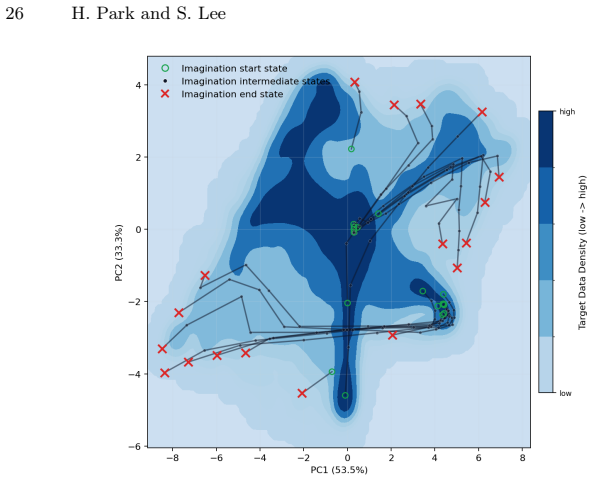
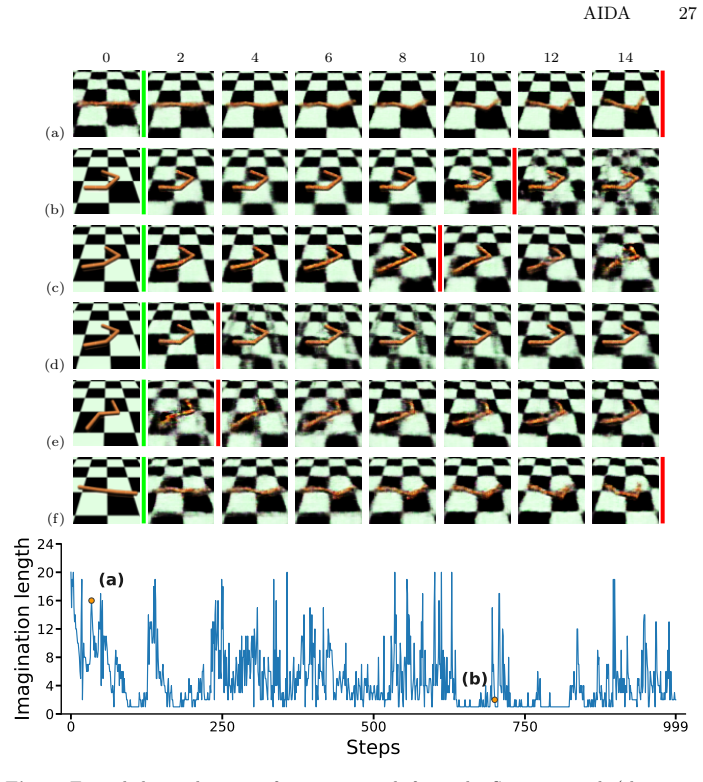
The distribution-shift-aware discriminator reliably detects when imagined transitions enter low-confidence regions so that only trustworthy transitions are retained.
What would settle it
Observing that the method's performance does not exceed baselines when the discriminator is replaced with random truncation, or when tested on tasks where distribution shift is harder to detect, would challenge the central claim.
Figures


read the original abstract
Sim-to-real transfer remains a major obstacle for reinforcement learning (RL), especially for vision-based control where image observations exacerbate the state-distribution shift between simulation and the real world. Domain adaptation (DA) is a promising remedy for this challenge. Prior sim-to-real DA works have demonstrated encouraging results, yet these approaches typically assume substantially more target data, which is not available in practice. Indeed, their performance degrades significantly when the target data budget is reduced. To address this challenge, we propose AIDA (Adaptive Imagination for Domain Adaptation), a domain adaptation framework for visual reinforcement learning that addresses sim-to-real transfer under scarce target data without requiring additional interaction with the target environment. Our key idea is adaptive imagination: generating reliable and semantic imagination rollouts to augment limited target data. Specifically, AIDA employs a distribution-shift-aware discriminator that truncates rollouts when imagined transitions drift into low-confidence regions, so that only reliable transitions contribute to the augmentation. On these reliable transitions, AIDA introduces a self-consistency loss that cycles through state -> image observation -> state, penalizing discrepancies between the original and reconstructed states. This provides additional adaptation signals beyond the scarce target data. Our experiments demonstrate that adaptive imagination effectively truncates unreliable rollouts. By enforcing a self-consistency loss on the resulting reliable transitions, AIDA learns semantically meaningful state representations and outperforms baselines across five MuJoCo tasks and two Gymnasium-Robotics tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes AIDA, a domain adaptation framework for visual RL addressing sim-to-real transfer with scarce target data. It generates reliable imagined rollouts via a distribution-shift-aware discriminator that truncates transitions entering low-confidence regions, then applies a self-consistency loss cycling state → image observation → state on retained transitions to augment data and learn semantic representations. Experiments claim that this yields outperformance over baselines on five MuJoCo tasks and two Gymnasium-Robotics tasks without additional target-environment interaction.
Significance. If the truncation mechanism reliably retains only trustworthy transitions, the approach could meaningfully advance practical sim-to-real visual RL by mitigating performance degradation under limited target data. The adaptive imagination plus cycle-consistency idea is a targeted response to a documented weakness in prior DA methods. The work supplies an empirical framework evaluated on standard benchmarks, but its significance depends on validation that the discriminator's decisions align with actual transition reliability.
major comments (2)
- [Abstract and §3] Abstract and §3 (AIDA framework): The central empirical claim of outperformance under limited target data rests on the distribution-shift-aware discriminator correctly identifying and truncating unreliable imagined transitions. No direct validation, calibration analysis, or ablation isolating the truncation step (e.g., performance with vs. without truncation, or correlation between discriminator confidence and downstream task error) is supplied, leaving the load-bearing reliability assumption untested.
- [§4] §4 (Experiments): The manuscript asserts that adaptive imagination 'effectively truncates unreliable rollouts' and that AIDA outperforms baselines, yet the provided description supplies no quantitative metrics, error bars, baseline implementations, or ablation tables. This prevents assessment of effect sizes or whether the gains are attributable to the proposed mechanisms rather than implementation details.
minor comments (2)
- [§3] The self-consistency loss is described only at a high level; explicit formulation of the cycle (including how the image observation is generated and how the reconstruction penalty is computed) would improve reproducibility.
- [Abstract and §4] Task names, data budgets, and exact baseline references should be listed explicitly in the abstract or early in §4 to allow immediate comparison with prior work.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the validation of the truncation mechanism and the experimental reporting. We address each major comment below and outline revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (AIDA framework): The central empirical claim of outperformance under limited target data rests on the distribution-shift-aware discriminator correctly identifying and truncating unreliable imagined transitions. No direct validation, calibration analysis, or ablation isolating the truncation step (e.g., performance with vs. without truncation, or correlation between discriminator confidence and downstream task error) is supplied, leaving the load-bearing reliability assumption untested.
Authors: We agree that the manuscript does not supply a direct calibration analysis or isolated ablation of the truncation step, leaving the reliability assumption supported primarily by end-to-end task performance rather than component-level evidence. In revision we will add (i) an ablation comparing AIDA with and without the truncation mechanism and (ii) a plot or table correlating discriminator confidence with downstream reconstruction error and task return, thereby directly testing the truncation decisions. revision: yes
-
Referee: [§4] §4 (Experiments): The manuscript asserts that adaptive imagination 'effectively truncates unreliable rollouts' and that AIDA outperforms baselines, yet the provided description supplies no quantitative metrics, error bars, baseline implementations, or ablation tables. This prevents assessment of effect sizes or whether the gains are attributable to the proposed mechanisms rather than implementation details.
Authors: The experimental section reports results on five MuJoCo and two Gymnasium-Robotics tasks, yet we acknowledge that the current write-up lacks explicit quantitative tables with error bars, seed counts, baseline code references, and component ablations. In the revised manuscript we will expand §4 with full tables of mean returns ± standard deviation over 5–10 seeds, explicit baseline implementation details, and ablation tables isolating the discriminator truncation and self-consistency loss contributions. revision: yes
Circularity Check
No circularity: empirical framework validated on external benchmarks
full rationale
The paper presents AIDA as an empirical domain adaptation method for visual RL, relying on a distribution-shift-aware discriminator for rollout truncation and a self-consistency loss on reliable transitions. No equations, derivations, or predictions are shown that reduce to fitted quantities defined from the same data by construction. Performance claims rest on experiments across five MuJoCo and two Gymnasium-Robotics tasks, which are independent external benchmarks. No load-bearing self-citations or ansatzes imported via prior work are evident in the provided text. This is a standard non-circular empirical contribution.
Axiom & Free-Parameter Ledger
invented entities (1)
-
distribution-shift-aware discriminator
no independent evidence
Reference graph
Works this paper leans on
-
[1]
IEEE Transactions on Intelligent Transportation Systems 23(6), 5068--5078 (2021)
Chen, J., Li, S.E., Tomizuka, M.: Interpretable end-to-end urban autonomous driving with latent deep reinforcement learning. IEEE Transactions on Intelligent Transportation Systems 23(6), 5068--5078 (2021)
2021
-
[2]
Advances in Neural Information Processing Systems 34, 12520--12532 (2021)
Chen, X.H., Jiang, S., Xu, F., Zhang, Z., Yu, Y.: Cross-modal domain adaptation for cost-efficient visual reinforcement learning. Advances in Neural Information Processing Systems 34, 12520--12532 (2021)
2021
-
[3]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Choi, H., Lee, H., Jeong, S., Min, D.: Environment agnostic representation for visual reinforcement learning. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 263--273 (2023)
2023
-
[4]
In: International conference on machine learning
Haarnoja, T., Zhou, A., Abbeel, P., Levine, S.: Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In: International conference on machine learning. pp. 1861--1870. Pmlr (2018)
2018
-
[5]
In: International Conference on Learning Representations (2020)
Hafner, D., Lillicrap, T., Ba, J., Norouzi, M.: Dream to control: Learning behaviors by latent imagination. In: International Conference on Learning Representations (2020)
2020
-
[6]
In: International Conference on Learning Representations (2021)
Hansen, N., Jangir, R., Sun, Y., Aleny \`a , G., Abbeel, P., Efros, A.A., Pinto, L., Wang, X.: Self-supervised policy adaptation during deployment. In: International Conference on Learning Representations (2021)
2021
-
[7]
In: 2021 IEEE International Conference on Robotics and Automation (ICRA)
Hansen, N., Wang, X.: Generalization in reinforcement learning by soft data augmentation. In: 2021 IEEE International Conference on Robotics and Automation (ICRA). pp. 13611--13617. IEEE (2021)
2021
-
[8]
In: Proceedings of the European conference on computer vision (ECCV)
Huang, X., Liu, M.Y., Belongie, S., Kautz, J.: Multimodal unsupervised image-to-image translation. In: Proceedings of the European conference on computer vision (ECCV). pp. 172--189 (2018)
2018
-
[9]
In: Conference on Robot Learning
James, S., Davison, A.J., Johns, E.: Transferring end-to-end visuomotor control from simulation to real world for a multi-stage task. In: Conference on Robot Learning. pp. 334--343. PMLR (2017)
2017
-
[10]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
James, S., Wohlhart, P., Kalakrishnan, M., Kalashnikov, D., Irpan, A., Ibarz, J., Levine, S., Hadsell, R., Bousmalis, K.: Sim-to-real via sim-to-sim: Data-efficient robotic grasping via randomized-to-canonical adaptation networks. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 12627--12637 (2019)
2019
-
[11]
In: International Conference on Learning Representations (2020)
Kaiser, L., Babaeizadeh, M., Milos, P., Osinski, B., Campbell, R.H., Czechowski, K., Erhan, D., Finn, C., Kozakowski, P., Levine, S., et al.: Model-based reinforcement learning for atari. In: International Conference on Learning Representations (2020)
2020
-
[13]
In: NeurIPS 2024 Workshop on Open-World Agents (2024)
Niu, H., Chen, Q., Liu, T., Li, J., Zhou, G., ZHANG, Y., HU, J., Zhan, X.: xted: Cross-domain adaptation via diffusion-based trajectory editing. In: NeurIPS 2024 Workshop on Open-World Agents (2024)
2024
-
[14]
Advances in neural information processing systems 29 (2016)
Nowozin, S., Cseke, B., Tomioka, R.: f-gan: Training generative neural samplers using variational divergence minimization. Advances in neural information processing systems 29 (2016)
2016
-
[15]
In: Robotics: Science and Systems (2018)
Pinto, L., Andrychowicz, M., Welinder, P., Zaremba, W., Abbeel, P.: Asymmetric actor critic for image-based robot learning. In: Robotics: Science and Systems (2018)
2018
-
[16]
In: International Conference on Learning Representations (2022)
Sun, Y., Zheng, R., Wang, X., Cohen, A., Huang, F.: Transfer rl across observation feature spaces via model-based regularization. In: International Conference on Learning Representations (2022)
2022
-
[17]
ACM Sigart Bulletin 2(4), 160--163 (1991)
Sutton, R.S.: Dyna, an integrated architecture for learning, planning, and reacting. ACM Sigart Bulletin 2(4), 160--163 (1991)
1991
-
[18]
In: 2017 IEEE/RSJ international conference on intelligent robots and systems (IROS)
Tobin, J., Fong, R., Ray, A., Schneider, J., Zaremba, W., Abbeel, P.: Domain randomization for transferring deep neural networks from simulation to the real world. In: 2017 IEEE/RSJ international conference on intelligent robots and systems (IROS). pp. 23--30. IEEE (2017)
2017
-
[19]
In: 2012 IEEE/RSJ international conference on intelligent robots and systems
Todorov, E., Erez, T., Tassa, Y.: Mujoco: A physics engine for model-based control. In: 2012 IEEE/RSJ international conference on intelligent robots and systems. pp. 5026--5033. IEEE (2012)
2012
-
[20]
In: 6th Annual Learning for Dynamics & Control Conference
Wang, W., Fang, X., Hager, G.: Adapting image-based rl policies via predicted rewards. In: 6th Annual Learning for Dynamics & Control Conference. pp. 324--336. PMLR (2024)
2024
-
[21]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Wang, X., Lian, L., Yu, S.X.: Unsupervised visual attention and invariance for reinforcement learning. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 6677--6687 (2021)
2021
-
[22]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Xia, F., Zamir, A.R., He, Z., Sax, A., Malik, J., Savarese, S.: Gibson env: Real-world perception for embodied agents. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 9068--9079 (2018)
2018
-
[23]
In: Proceedings of the aaai conference on artificial intelligence
Yarats, D., Zhang, A., Kostrikov, I., Amos, B., Pineau, J., Fergus, R.: Improving sample efficiency in model-free reinforcement learning from images. In: Proceedings of the aaai conference on artificial intelligence. vol. 35, pp. 10674--10681 (2021)
2021
-
[24]
In: 2020 IEEE symposium series on computational intelligence (SSCI)
Zhao, W., Queralta, J.P., Westerlund, T.: Sim-to-real transfer in deep reinforcement learning for robotics: a survey. In: 2020 IEEE symposium series on computational intelligence (SSCI). pp. 737--744. IEEE (2020)
2020
-
[25]
Advances in neural information processing systems 30 (2017)
Zhu, J.Y., Zhang, R., Pathak, D., Darrell, T., Efros, A.A., Wang, O., Shechtman, E.: Toward multimodal image-to-image translation. Advances in neural information processing systems 30 (2017)
2017
-
[26]
In: Proceedings of the ieee/cvf conference on computer vision and pattern recognition
Guo, T., Xu, C., Huang, J., Wang, Y., Shi, B., Xu, C., Tao, D.: On positive-unlabeled classification in gan. In: Proceedings of the ieee/cvf conference on computer vision and pattern recognition. pp. 8385--8393 (2020)
2020
-
[27]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 770--778 (2016)
2016
-
[28]
In: Conference on Robot Learning
Xu, J., Heiden, E., Akinola, I., Fox, D., Macklin, M., Narang, Y.: Neural robot dynamics. In: Conference on Robot Learning. pp. 3915--3935. PMLR (2025)
2025
-
[29]
2017 IEEE/RSJ international conference on intelligent robots and systems (IROS) , pages=
Domain randomization for transferring deep neural networks from simulation to the real world , author=. 2017 IEEE/RSJ international conference on intelligent robots and systems (IROS) , pages=. 2017 , organization=
2017
-
[30]
Conference on Robot Learning , pages=
Transferring end-to-end visuomotor control from simulation to real world for a multi-stage task , author=. Conference on Robot Learning , pages=. 2017 , organization=
2017
-
[31]
Robotics: Science and Systems , year=
Asymmetric actor critic for image-based robot learning , author=. Robotics: Science and Systems , year=
-
[32]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Sim-to-real via sim-to-sim: Data-efficient robotic grasping via randomized-to-canonical adaptation networks , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[33]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Environment agnostic representation for visual reinforcement learning , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[34]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Unsupervised visual attention and invariance for reinforcement learning , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[35]
2021 IEEE International Conference on Robotics and Automation (ICRA) , pages=
Generalization in reinforcement learning by soft data augmentation , author=. 2021 IEEE International Conference on Robotics and Automation (ICRA) , pages=. 2021 , organization=
2021
-
[36]
International Conference on Learning Representations , year=
Self-supervised policy adaptation during deployment , author=. International Conference on Learning Representations , year=
-
[37]
6th Annual Learning for Dynamics & Control Conference , pages=
Adapting image-based RL policies via predicted rewards , author=. 6th Annual Learning for Dynamics & Control Conference , pages=. 2024 , organization=
2024
-
[38]
Advances in Neural Information Processing Systems , volume=
Cross-modal domain adaptation for cost-efficient visual reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[39]
International Conference on Learning Representations , year=
Transfer RL across observation feature spaces via model-based regularization , author=. International Conference on Learning Representations , year=
-
[40]
2020 IEEE symposium series on computational intelligence (SSCI) , pages=
Sim-to-real transfer in deep reinforcement learning for robotics: a survey , author=. 2020 IEEE symposium series on computational intelligence (SSCI) , pages=. 2020 , organization=
2020
-
[41]
NeurIPS 2024 Workshop on Open-World Agents , year=
xTED: Cross-Domain Adaptation via Diffusion-Based Trajectory Editing , author=. NeurIPS 2024 Workshop on Open-World Agents , year=
2024
-
[42]
International Conference on Learning Representations , year=
Model-based reinforcement learning for atari , author=. International Conference on Learning Representations , year=
-
[43]
Proceedings of the aaai conference on artificial intelligence , volume=
Improving sample efficiency in model-free reinforcement learning from images , author=. Proceedings of the aaai conference on artificial intelligence , volume=
-
[44]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Gibson env: Real-world perception for embodied agents , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[45]
Proceedings of the European conference on computer vision (ECCV) , pages=
Multimodal unsupervised image-to-image translation , author=. Proceedings of the European conference on computer vision (ECCV) , pages=
-
[46]
Advances in neural information processing systems , volume=
Toward multimodal image-to-image translation , author=. Advances in neural information processing systems , volume=
-
[47]
International conference on machine learning , pages=
Transfer learning for related reinforcement learning tasks via image-to-image translation , author=. International conference on machine learning , pages=. 2019 , organization=
2019
-
[48]
Advances in neural information processing systems , volume=
f-gan: Training generative neural samplers using variational divergence minimization , author=. Advances in neural information processing systems , volume=
-
[49]
International Conference on Learning Representations , year=
Dream to control: Learning behaviors by latent imagination , author=. International Conference on Learning Representations , year=
-
[50]
ACM Sigart Bulletin , volume=
Dyna, an integrated architecture for learning, planning, and reacting , author=. ACM Sigart Bulletin , volume=. 1991 , publisher=
1991
-
[51]
2012 IEEE/RSJ international conference on intelligent robots and systems , pages=
Mujoco: A physics engine for model-based control , author=. 2012 IEEE/RSJ international conference on intelligent robots and systems , pages=. 2012 , organization=
2012
-
[52]
2024 IEEE International Conference on Robotics and Automation (ICRA) , pages=
Domain adaptation of visual policies with a single demonstration , author=. 2024 IEEE International Conference on Robotics and Automation (ICRA) , pages=. 2024 , organization=
2024
-
[53]
2018 IEEE international conference on robotics and automation (ICRA) , pages=
Sim-to-real transfer of robotic control with dynamics randomization , author=. 2018 IEEE international conference on robotics and automation (ICRA) , pages=. 2018 , organization=
2018
-
[54]
International Conference on Learning Representations , year=
Single episode policy transfer in reinforcement learning , author=. International Conference on Learning Representations , year=
-
[55]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Rl-cyclegan: Reinforcement learning aware simulation-to-real , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[56]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Adversarial discriminative domain adaptation , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[57]
International conference on machine learning , pages=
Darla: Improving zero-shot transfer in reinforcement learning , author=. International conference on machine learning , pages=. 2017 , organization=
2017
-
[58]
International conference on machine learning , pages=
Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor , author=. International conference on machine learning , pages=. 2018 , organization=
2018
-
[59]
Playing Atari with Deep Reinforcement Learning
Playing atari with deep reinforcement learning , author=. arXiv preprint arXiv:1312.5602 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[60]
IEEE Transactions on Intelligent Transportation Systems , volume=
Interpretable end-to-end urban autonomous driving with latent deep reinforcement learning , author=. IEEE Transactions on Intelligent Transportation Systems , volume=. 2021 , publisher=
2021
-
[61]
Asymmetric Actor Critic for Image-Based Robot Learning
Asymmetric actor critic for image-based robot learning , author=. arXiv preprint arXiv:1710.06542 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[62]
Self-supervised policy adaptation during deployment.arXiv preprint arXiv:2007.04309, 2020
Self-supervised policy adaptation during deployment , author=. arXiv preprint arXiv:2007.04309 , year=
-
[63]
arXiv preprint arXiv:2201.00248 , year=
Transfer RL across observation feature spaces via model-based regularization , author=. arXiv preprint arXiv:2201.00248 , year=
-
[64]
arXiv preprint arXiv:2409.08687 , year=
xTED: Cross-Domain Adaptation via Diffusion-Based Trajectory Editing , author=. arXiv preprint arXiv:2409.08687 , year=
-
[65]
arXiv preprint arXiv:1903.00374 , year=
Model-based reinforcement learning for atari , author=. arXiv preprint arXiv:1903.00374 , year=
-
[66]
Dream to Control: Learning Behaviors by Latent Imagination
Dream to control: Learning behaviors by latent imagination , author=. arXiv preprint arXiv:1912.01603 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1912
-
[67]
arXiv preprint arXiv:1910.07719 , year=
Single episode policy transfer in reinforcement learning , author=. arXiv preprint arXiv:1910.07719 , year=
-
[68]
Proceedings of the ieee/cvf conference on computer vision and pattern recognition , pages=
On positive-unlabeled classification in GAN , author=. Proceedings of the ieee/cvf conference on computer vision and pattern recognition , pages=
-
[69]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Deep residual learning for image recognition , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[70]
Conference on Robot Learning , pages=
Neural Robot Dynamics , author=. Conference on Robot Learning , pages=. 2025 , organization=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.