The FIL Hypothesis: Inductive Biases Help with Kernel Engineering
Pith reviewed 2026-06-30 06:04 UTC · model grok-4.3
The pith
Incorporating inductive biases outperforms purely data-driven methods in tasks with long feedback loops like GPU kernel engineering.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes the FIL Hypothesis, which posits that as Feedback Information Loop durations increase in real-world applications, purely data-driven methods face practical limits due to insufficient verification signals, and that incorporating inductive biases from human knowledge yields superior performance, as demonstrated in GPU kernel engineering.
What carries the argument
The Feedback Information Loop (FIL), defined as the time required for a system to receive a verification signal after generating a prediction, which serves as a new scaling dimension limiting data-driven approaches and motivating the use of inductive biases to constrain solutions.
If this is right
- Purely data-driven methods will not scale to tasks with FILs of hours to weeks due to the impossibility of obtaining enough verification steps.
- Inductive biases can be applied orthogonally to data-driven approaches by constraining the solution space with human-inspired expert knowledge.
- In the GPU programming task, which has non-trivial FIL, the bias-incorporating method produces better results than data-driven baselines.
- Future AI applications in science and the physical world will require methods that do not rely solely on scaling verification signals.
Where Pith is reading between the lines
- Hybrid systems that combine large models with explicit domain constraints may become necessary for engineering tasks where testing cycles are slow.
- The GPU kernel domain may highlight a broader class of optimization problems in which solution-space constraints reduce the number of expensive evaluations needed.
- Shortening FIL through faster simulation or proxy signals could complement but not replace the need for inductive biases.
Load-bearing premise
The GPU programming task is representative of the broader class of future AI applications in science and the physical world that will have FILs ranging from hours to weeks.
What would settle it
A demonstration in a task with FIL of days or longer that purely data-driven methods achieve comparable or superior performance to methods that incorporate inductive biases.
Figures

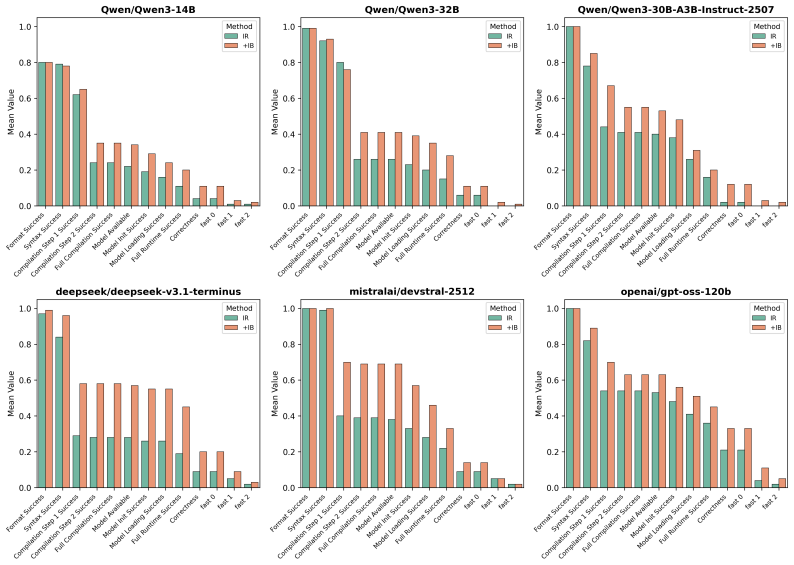
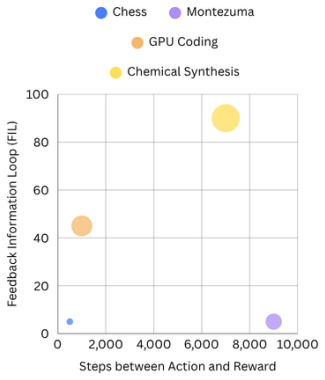
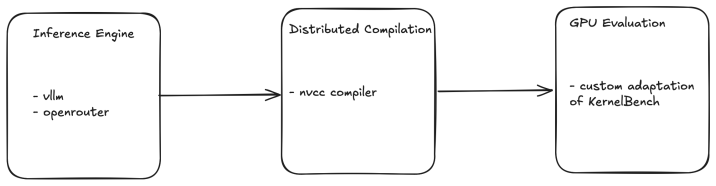


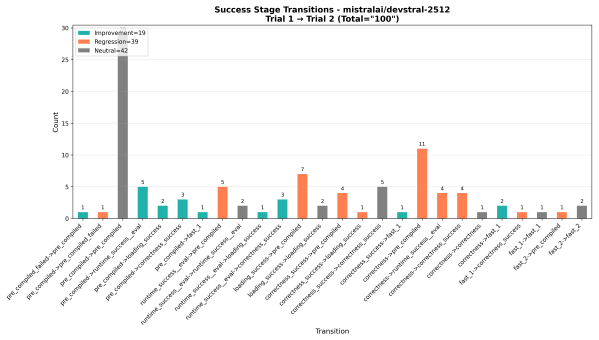

read the original abstract
The Bitter Lesson, which posits that general-purpose methods that scale with computation and data ultimately outperform those with built-in human knowledge, has become a dominant paradigm in the era of Large Language Models. We revisit this principle by observing a new and critical scaling dimension: the duration of the Feedback Information Loop (FIL), the time required for a system to receive a verification signal after generating a prediction. Most historic successes in Artificial Intelligence (AI) have benefited from near instantaneous feedback (e.g., games or classification tasks), but we argue that future AI applications in science and the physical world will inherently involve FILs ranging from hours to weeks. This trend poses a fundamental scaling limit, as obtaining enough verification steps required by purely data-driven methods becomes practically impossible. Additionally, we propose a method that is orthogonal to purely data-driven approaches, based on human-inspired expert knowledge. The method relies on inductive biases and constraining the solution space. We provide an initial validation of the hypothesis and the method, by studying the real-world GPU programming task, a domain with non-trivial FIL, and demonstrate that incorporating inductive biases yields superior performance over data-driven approaches. The code is released under: https://github.com/ai-nikolai/robust_kernelbench
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the FIL (Feedback Information Loop) hypothesis, arguing that future AI applications in science and the physical world will face long verification times (hours to weeks) that impose a fundamental scaling limit on purely data-driven methods, unlike near-instantaneous feedback in games or classification. It proposes incorporating human-inspired inductive biases to constrain the solution space as an orthogonal approach, and claims initial validation by showing superior performance of bias-based methods over data-driven ones on a real-world GPU kernel programming task with non-trivial FIL. Code is released at the provided GitHub link.
Significance. If the central claim holds with rigorous validation, the work would highlight a practical limit to scaling laws in long-FIL domains and motivate hybrid methods that embed domain knowledge, potentially influencing AI-for-science research. However, the current validation does not yet establish this, as the chosen task may not instantiate the hypothesized regime.
major comments (2)
- [Abstract] Abstract and validation section: the claim that the GPU programming task instantiates a 'non-trivial FIL' sufficient to demonstrate the hypothesized scaling limit is unsupported, as no measurements or bounds on the actual feedback duration (kernel generation, compilation, correctness testing) are provided; standard GPU workflows yield signals in seconds to minutes rather than hours-to-weeks, creating a mismatch with the hours-to-weeks regime central to the hypothesis.
- [Abstract] Validation section: the abstract asserts superior performance of inductive-bias methods over data-driven approaches, yet provides no details on experimental design, baselines, controls, number of trials, or statistical significance; without these, the empirical claim cannot be evaluated and risks circularity with the task choice.
minor comments (1)
- The manuscript would benefit from explicit discussion of how the released code implements the inductive biases versus the data-driven baseline to allow reproduction.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The comments highlight important areas where the validation can be strengthened. We address each major comment below and commit to revisions that improve clarity and rigor without altering the core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract and validation section: the claim that the GPU programming task instantiates a 'non-trivial FIL' sufficient to demonstrate the hypothesized scaling limit is unsupported, as no measurements or bounds on the actual feedback duration (kernel generation, compilation, correctness testing) are provided; standard GPU workflows yield signals in seconds to minutes rather than hours-to-weeks, creating a mismatch with the hours-to-weeks regime central to the hypothesis.
Authors: We agree that explicit measurements of FIL durations are needed to substantiate the claim. In the revised manuscript we will add timing data for kernel generation, compilation, and correctness testing across the evaluated tasks, including bounds and distributions. While many simple kernels compile quickly, the tasks in our benchmark involve iterative optimization and multi-input verification that routinely require minutes per trial; we will report these values directly. The GPU domain is presented as an initial, accessible proxy for non-instantaneous feedback rather than a literal hours-to-weeks example; we will clarify this distinction and discuss how the observed advantage is expected to grow with longer FILs. revision: yes
-
Referee: [Abstract] Validation section: the abstract asserts superior performance of inductive-bias methods over data-driven approaches, yet provides no details on experimental design, baselines, controls, number of trials, or statistical significance; without these, the empirical claim cannot be evaluated and risks circularity with the task choice.
Authors: The validation section of the full manuscript specifies the inductive-bias methods, data-driven baselines, benchmark kernels, and evaluation metrics. To make the abstract self-contained we will add a concise summary of the experimental protocol, number of independent trials, and statistical tests performed. The task was selected for its practical relevance to GPU programming and its measurable (non-zero) FIL before the hypothesis was formulated; we will add an explicit statement of this ordering to address any appearance of circularity. revision: yes
Circularity Check
No circularity: FIL hypothesis and GPU validation are logically independent of inputs
full rationale
The paper defines FIL as a new observable scaling dimension drawn from historical AI examples with short feedback, extrapolates its impact on future long-FIL domains, and offers the GPU kernel task as an initial empirical illustration rather than a derivation. No equations, parameter fits, self-citations, or ansatzes are invoked that would make any claim equivalent to its own inputs by construction. The central argument rests on external reasoning about verification timescales and is not forced by renaming, self-definition, or load-bearing self-reference.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Jie An, De Wang, Pengsheng Guo, Jiebo Luo, and Alex Schwing. 2025. On Inductive Biases That Enable Generalization in Diffusion Transformers. InThe Thirty-ninth Annual Confer- ence on Neural Information Processing Systems. https://openreview.net/forum?id= lE2cD7C9fk
2025
-
[2]
Arjona-Medina, Michael Gillhofer, Michael Widrich, Thomas Unterthiner, Johannes Brandstetter, and Sepp Hochreiter
Jose A. Arjona-Medina, Michael Gillhofer, Michael Widrich, Thomas Unterthiner, Johannes Brandstetter, and Sepp Hochreiter. 2019.RUDDER: return decomposition for delayed rewards. Curran Associates Inc., Red Hook, NY , USA
2019
-
[3]
Randall Balestriero and Yann LeCun. 2025. LeJEPA: Provable and Scalable Self- Supervised Learning Without the Heuristics.ArXivabs/2511.08544 (2025). https: //api.semanticscholar.org/CorpusID:282922448
Pith/arXiv arXiv 2025
-
[4]
Carlo Baronio, Pietro Marsella, Ben Pan, Simon Guo, and Silas Alberti. 2025. Kevin: Multi- Turn RL for Generating CUDA Kernels.ArXivabs/2507.11948 (2025). https://api. semanticscholar.org/CorpusID:280232580
arXiv 2025
-
[5]
Carlo Baronio, Pietro Marsella, Ben Pan, Simon Guo, and Silas Alberti. 2026. Kevin: Multi-Turn RL for Generating CUDA Kernels. InThe Fourteenth International Conference on Learning Representations.https://openreview.net/forum?id=xu1XwVZtDi
2026
-
[6]
Peter W. Battaglia, Jessica B. Hamrick, Victor Bapst, Alvaro Sanchez-Gonzalez, Vinicius Zambaldi, Mateusz Malinowski et al. 2018. Relational inductive biases, deep learning, and graph networks. arXiv:1806.01261 [cs.LG]https://arxiv.org/abs/1806.01261
Pith/arXiv arXiv 2018
-
[7]
Heraldo Borges, Juliana Alves Pereira, Djamel Eddine Khelladi, and Mathieu Acher. 2025. Linux Kernel Configurations at Scale: A Dataset for Performance and Evolution Analysis. arXiv:2505.07487 [cs.SE]https://arxiv.org/abs/2505.07487
arXiv 2025
-
[8]
Yuri Burda, Harrison Edwards, Amos Storkey, and Oleg Klimov. 2018. Exploration by Random Network Distillation. arXiv:1810.12894 [cs.LG]https://arxiv.org/abs/1810.12894
Pith/arXiv arXiv 2018
-
[9]
Yuri Burda, Harrison Edwards, Amos Storkey, and Oleg Klimov. 2019. Exploration by random network distillation. InInternational Conference on Learning Representations. https:// openreview.net/forum?id=H1lJJnR5Ym 10
2019
-
[10]
Jun Shern Chan, Neil Chowdhury, Oliver Jaffe, James Aung, Dane Sherburn, Evan Mays et al
-
[11]
In The Thirteenth International Conference on Learning Representations.https://openreview
MLE-bench: Evaluating Machine Learning Agents on Machine Learning Engineering. In The Thirteenth International Conference on Learning Representations.https://openreview. net/forum?id=6s5uXNWGIh
-
[12]
Yingshan Chang and Yonatan Bisk. 2025. Language Models Need Inductive Biases to Count Inductively. InThe Thirteenth International Conference on Learning Representations. https: //openreview.net/forum?id=s3IBHTTDYl
2025
-
[13]
Chang Chen, Jaesik Yoon, Yi-Fu Wu, and Sungjin Ahn. 2021. TransDreamer: Reinforcement Learning with Transformer World Models. InDeep RL Workshop NeurIPS 2021. https: //openreview.net/forum?id=sVrzVAL90sA
2021
-
[14]
2023.Unsloth
Michael Han Daniel Han and Unsloth team. 2023.Unsloth. https://github.com/ unslothai/unsloth
2023
-
[15]
DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang et al
-
[16]
arXiv:2501.12948 [cs.CL]https://arxiv.org/abs/2501.12948
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. arXiv:2501.12948 [cs.CL]https://arxiv.org/abs/2501.12948
-
[17]
Rati Devidze, Parameswaran Kamalaruban, and Adish Singla. 2022. Exploration- Guided Reward Shaping for Reinforcement Learning under Sparse Rewards. InAd- vances in Neural Information Processing Systems, S. Koyejo, S. Mohamed, A. Agar- wal, D. Belgrave, K. Cho, and A. Oh (Eds.), V ol. 35. Curran Associates, Inc., 5829–5842. https://proceedings.neurips.cc/p...
2022
-
[18]
Jingtao Ding, Yunke Zhang, Yu Shang, Yuheng Zhang, Zefang Zong, Jie Feng et al . 2025. Understanding World or Predicting Future? A Comprehensive Survey of World Models.ACM Comput. Surv.58, 3, Article 57 (Sept. 2025), 38 pages. doi:10.1145/3746449
-
[19]
Subhabrata Dutta, Timo Kaufmann, Goran Glavaš, Ivan Habernal, Kristian Kersting, Frauke Kreuter et al . 2025. Problem Solving Through Human–AI Preference-based Cooperation. Computational Linguistics51, 4 (12 2025), 1337–1372. arXiv:https://direct.mit.edu/coli/article- pdf/51/4/1337/2539252/coli.a.19.pdf doi:10.1162/COLI.a.19
-
[20]
Ben Eysenbach, Russ R Salakhutdinov, and Sergey Levine. 2019. Search on the Replay Buffer: Bridging Planning and Reinforcement Learning. InAdvances in Neural Information Processing Systems, H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alché-Buc, E. Fox, and R. Garnett (Eds.), V ol. 32. Curran Associates, Inc. https://proceedings.neurips.cc/ paper_files...
2019
-
[21]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu et al . 2025. DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning.Nature645, 8081 (01 Sep 2025), 633–638. doi:10.1038/s41586-025-09422-z
-
[22]
David Ha and Jürgen Schmidhuber. 2018. Recurrent World Models Facilitate Policy Evo- lution. InAdvances in Neural Information Processing Systems, S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett (Eds.), V ol. 31. Curran As- sociates, Inc. https://proceedings.neurips.cc/paper_files/paper/2018/file/ 2de5d16682c3c35007e4e9298...
2018
-
[23]
Danijar Hafner, Timothy Lillicrap, Jimmy Ba, and Mohammad Norouzi. 2020. Dream to Control: Learning Behaviors by Latent Imagination.https://arxiv.org/pdf/1912.01603.pdf
Pith/arXiv arXiv 2020
-
[24]
Danijar Hafner, Timothy Lillicrap, Ian Fischer, Ruben Villegas, David Ha, Honglak Lee, and James Davidson. 2019. Learning Latent Dynamics for Planning from Pixels. InProceedings of the 36th International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 97), Kamalika Chaudhuri and Ruslan Salakhutdinov (Eds.). PMLR, 2555–2565. ...
2019
-
[25]
Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. 2025. Mastering diverse control tasks through world models.Nature640, 8059 (01 Apr 2025), 647–653. doi: 10.1038/ s41586-025-08744-2 11
2025
-
[26]
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford et al. 2022. Training compute-optimal large language models. InProceedings of the 36th International Conference on Neural Information Processing Systems(New Orleans, LA, USA)(NIPS ’22). Curran Associates Inc., Red Hook, NY , USA, Article 2176, 15 pages
2022
-
[27]
Horváth, Goran Žuži´c, Eric Wieser et al
Thomas Hubert, Rishi Mehta, Laurent Sartran, Miklós Z. Horváth, Goran Žuži´c, Eric Wieser et al. 2025. Olympiad-level formal mathematical reasoning with reinforcement learning.Nature (12 Nov 2025). doi:10.1038/s41586-025-09833-y
-
[28]
Humaid Ibrahim, Nikolai Rozanov, and Marek Rei. 2025. Fine-tuning with RAG for Improving LLM Learning of New Skills. arXiv:2510.01375 [cs.AI] https://arxiv.org/abs/2510. 01375
arXiv 2025
-
[29]
John Jumper, Richard Evans, Alexander Pritzel, Tim Green, Michael Figurnov, Olaf Ron- neberger et al. 2021. Highly accurate protein structure prediction with AlphaFold.Nature596, 7873 (01 Aug 2021), 583–589. doi:10.1038/s41586-021-03819-2
-
[30]
Nayak, Jack Merullo, Stephen H
Apoorv Khandelwal, Tian Yun, Nihal V . Nayak, Jack Merullo, Stephen H. Bach, Chen Sun, and Ellie Pavlick. 2024. $100K or 100 Days: Trade-offs when Pre-Training with Academic Resources.CoRRabs/2410.23261 (2024). arXiv:2410.23261 doi: 10.48550/ARXIV.2410. 23261
-
[31]
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu et al
-
[32]
InProceedings of the 29th Symposium on Operating Systems Principles(Koblenz, Germany) (SOSP ’23)
Efficient Memory Management for Large Language Model Serving with PagedAttention. InProceedings of the 29th Symposium on Operating Systems Principles(Koblenz, Germany) (SOSP ’23). Association for Computing Machinery, New York, NY , USA, 611–626. doi:10. 1145/3600006.3613165
-
[33]
Anne Lauscher, Olga Majewska, Leonardo F. R. Ribeiro, Iryna Gurevych, Nikolai Rozanov, and Goran Glavaš. 2020. Common Sense or World Knowledge? Investigating Adapter-Based Knowledge Injection into Pretrained Transformers. InProceedings of Deep Learning Inside Out (DeeLIO): The First Workshop on Knowledge Extraction and Integration for Deep Learning Archit...
-
[34]
Chris Lu, Cong Lu, Robert Tjarko Lange, Jakob Foerster, Jeff Clune, and David Ha
-
[35]
arXiv:2408.06292 [cs.AI]https://arxiv.org/abs/2408.06292
The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery. arXiv:2408.06292 [cs.AI]https://arxiv.org/abs/2408.06292
-
[36]
Xianzhen Luo, Wenzhen Zheng, Qingfu Zhu, Rongyi Zhang, Houyi Li, Siming Huang et al
-
[37]
arXiv:2510.08702 [cs.CL] https://arxiv.org/abs/2510.08702
Scaling Laws for Code: A More Data-Hungry Regime. arXiv:2510.08702 [cs.CL] https://arxiv.org/abs/2510.08702
-
[38]
Vincent Micheli, Eloi Alonso, and François Fleuret. 2024. Efficient World Models with Context- Aware Tokenization. InProceedings of the 41st International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 235), Ruslan Salakhutdinov, Zico Kolter, Katherine Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berken...
2024
-
[39]
Tom Michael Mitchell. 2007. The Need for Biases in Learning Generalizations. https: //api.semanticscholar.org/CorpusID:3237155
2007
-
[40]
Ian Osband, Charles Blundell, Alexander Pritzel, and Benjamin Van Roy. 2016. Deep explo- ration via bootstrapped DQN. InProceedings of the 30th International Conference on Neural Information Processing Systems(Barcelona, Spain)(NIPS’16). Curran Associates Inc., Red Hook, NY , USA, 4033–4041
2016
-
[41]
Zhang, William Hu, Christopher Ré, and Azalia Mirhoseini
Anne Ouyang, Simon Guo, Simran Arora, Alex L. Zhang, William Hu, Christopher Ré, and Azalia Mirhoseini. 2025. KernelBench: Can LLMs Write Efficient GPU Kernels? arXiv:2502.10517 [cs.LG]https://arxiv.org/abs/2502.10517
Pith/arXiv arXiv 2025
-
[42]
Nikolai Rozanov. 2026. Multi-task LLMs for Bug Classification: Efficient Inference with Auxiliary Decoding Heads. arXiv:2606.09956 [cs.SE] https://arxiv.org/abs/2606. 09956 12
Pith/arXiv arXiv 2026
-
[43]
Nikolai Rozanov and Marek Rei. 2025. StateAct: Enhancing LLM Base Agents via Self- prompting and State-tracking. arXiv:2410.02810 [cs.AI] https://arxiv.org/abs/2410. 02810
arXiv 2025
-
[44]
Dhruv Sahnan, Subhabrata Dutta, Tanmoy Chakraborty, Preslav Nakov, and Iryna Gurevych
-
[45]
arXiv:2604.13706 [cs.CL] https://arxiv.org/abs/2604
Co-FactChecker: A Framework for Human-AI Collaborative Claim Verification Us- ing Large Reasoning Models. arXiv:2604.13706 [cs.CL] https://arxiv.org/abs/2604. 13706
-
[46]
Marco Dos Santos, Hugues de Saxcé, Haiming Wang, Ran Wang, Mantas Baksys, Mert Unsal et al. 2025. Kimina Lean Server: A High-Performance Lean Server for Large-Scale Verification. arXiv:2504.21230 [cs.LO]https://arxiv.org/abs/2504.21230
arXiv 2025
-
[47]
David Silver, Julian Schrittwieser, Karen Simonyan, Ioannis Antonoglou, Aja Huang, Arthur Guez et al. 2017. Mastering the game of Go without human knowledge.Nature550, 7676 (01 Oct 2017), 354–359. doi:10.1038/nature24270
-
[48]
Vighnesh Subramaniam, David Mayo, Colin Conwell, Tomaso Poggio, Boris Katz, Brian Cheung, and Andrei Barbu. 2025. Training the Untrainable: Introducing Inductive Bias via Representational Alignment. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems.https://openreview.net/forum?id=zvYxXhlQHM
2025
-
[49]
V olk, Robert W
Amanda A. V olk, Robert W. Epps, Daniel T. Yonemoto, Benjamin S. Masters, Felix N. Castel- lano, Kristofer G. Reyes, and Milad Abolhasani. 2023. AlphaFlow: autonomous discov- ery and optimization of multi-step chemistry using a self-driven fluidic lab guided by rein- forcement learning.Nature Communications14, 1 (14 Mar 2023), 1403. doi: 10.1038/ s41467-0...
2023
-
[50]
Laura von Rueden, Sebastian Mayer, Katharina Beckh, Bogdan Georgiev, Sven Giesselbach, Raoul Heese et al. 2023. Informed Machine Learning – A Taxonomy and Survey of Integrat- ing Prior Knowledge into Learning Systems.IEEE Transactions on Knowledge and Data Engineering35, 1 (2023), 614–633. doi:10.1109/TKDE.2021.3079836
-
[51]
Alex Wang, Yada Pruksachatkun, Nikita Nangia, Amanpreet Singh, Julian Michael, Felix Hill et al. 2020. SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems. arXiv:1905.00537 [cs.CL]https://arxiv.org/abs/1905.00537
Pith/arXiv arXiv 2020
-
[52]
Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R. Bow- man. 2019. GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding. arXiv:1804.07461 [cs.CL]https://arxiv.org/abs/1804.07461
Pith/arXiv arXiv 2019
-
[53]
Andrew Gordon Wilson. 2025. Position: Deep Learning is Not So Mysterious or Different. InProceedings of the 42nd International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 267), Aarti Singh, Maryam Fazel, Daniel Hsu, Simon Lacoste-Julien, Felix Berkenkamp, Tegan Maharaj, Kiri Wagstaff, and Jerry Zhu (Eds.). PMLR, 82326–82...
2025
-
[54]
Ziyi Wu, Nikita Dvornik, Klaus Greff, Thomas Kipf, and Animesh Garg. 2023. SlotFormer: Unsupervised Visual Dynamics Simulation with Object-Centric Models. InThe Eleventh Inter- national Conference on Learning Representations. https://openreview.net/forum?id= TFbwV6I0VLg
2023
-
[55]
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. 2023. Tree of Thoughts: Deliberate Problem Solving with Large Language Models. InAdvances in Neural Information Processing Systems, A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine (Eds.), V ol. 36. Curran Associates, Inc., 11809–11822. ht...
2023
-
[56]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. ReAct: Synergizing Reasoning and Acting in Language Models. arXiv:2210.03629 [cs.CL]https://arxiv.org/abs/2210.03629 13
Pith/arXiv arXiv 2023
-
[57]
Yixin Ye, Zhen Huang, Yang Xiao, Ethan Chern, Shijie Xia, and Pengfei Liu. 2025. LIMO: Less is More for Reasoning. InSecond Conference on Language Modeling. https://openreview. net/forum?id=T2TZ0RY4Zk
2025
-
[58]
Tianren Zhang, Guanyu Chen, and Feng Chen. 2025. When do neural networks learn world models?. InProceedings of the 42nd International Conference on Machine Learning (Proceed- ings of Machine Learning Research, Vol. 267), Aarti Singh, Maryam Fazel, Daniel Hsu, Simon Lacoste-Julien, Felix Berkenkamp, Tegan Maharaj, Kiri Wagstaff, and Jerry Zhu (Eds.). PMLR,...
2025
-
[59]
Kaijian Zou, Aaron Xiong, Yunxiang Zhang, Frederick Zhang, Yueqi Ren, Jirong Yang et al
-
[60]
LiveOIBench: Can Large Language Models Outperform Human Contestants in Informat- ics Olympiads?arXiv preprint arXiv:2510.09595(2025). doi: 10.48550/arXiv.2510.09595 A Background A.1 Learning with delayed and sparse feedback The challenge of learning from delayed feedback has been a persistent concern across multiple subfields of machine learning, especial...
-
[61]
Physical and Natural Sciences
introduced learning latent dynamics from pixels for planning. The Dreamer family of algorithms [21; 23] extended this paradigm to scalable reinforcement learning, achieving state-of-the-art per- formance on Atari and continuous control benchmarks by learning behaviors entirely within latent imagination. Recent work has expanded world models to incorporate...
-
[62]
Looking material up (similar to a Web Search) 22
-
[63]
processing existing .csv files for better data analysis)
Simple coding tasks (e.g. processing existing .csv files for better data analysis)
-
[64]
of a paragraph or sentence)
Minimal rewritting help (e.g. of a paragraph or sentence)
-
[65]
we were unable to find the license for the dataset we used
Help with Latex Table formatting. 23 NeurIPS Paper Checklist The checklist is designed to encourage best practices for responsible machine learning research, addressing issues of reproducibility, transparency, research ethics, and societal impact. Do not remove the checklist:The papers not including the checklist will be desk rejected.The checklist should...
-
[66]
Guidelines: • The answer [N/A] means that the paper does not involve crowdsourcing nor research with human subjects
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.