The Illusion of Agentic Complexity in README.md Generation: Evaluating Single-Agent vs. Multi-Agent RAG Systems
Pith reviewed 2026-07-02 20:31 UTC · model grok-4.3
The pith
Single-agent RAG matches multi-agent lexical quality for READMEs while cutting tokens by 86 percent and doubling speed.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
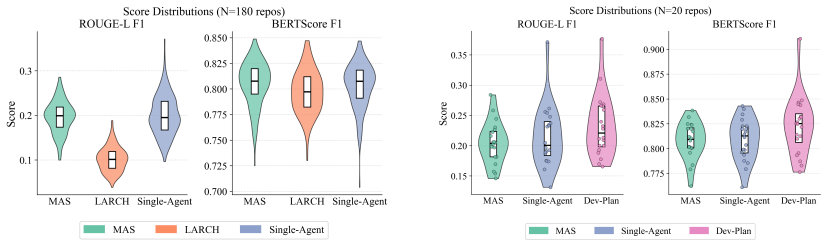
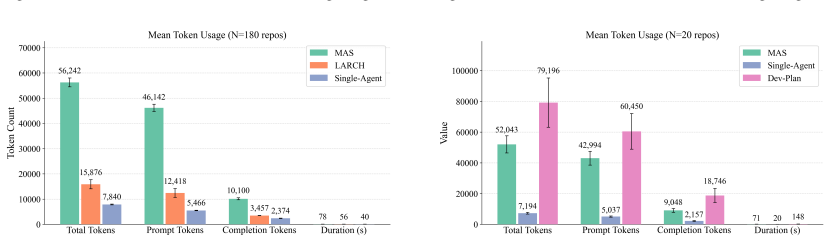
The paper establishes that single-agent pipelines achieve lexical quality comparable to multi-agent systems while reducing token consumption by 86% and operating at twice the speed, whereas multi-agent systems achieve 98% structural consistency. Autonomous planning emerges as the primary bottleneck, and incorporating lightweight developer-guided plans yields the highest documentation quality across all configurations tested against baselines like LARCH.
What carries the argument
The Single-Agent RAG pipeline, specialized Multi-Agent System (MAS), and developer-guided planning (DevPlan) variant, evaluated on lexical quality, structural consistency via manual taxonomy, token consumption, and speed for README generation.
Load-bearing premise
Lexical quality, structural consistency, token consumption, and speed are sufficient proxies for the real-world usefulness of the generated READMEs to developers.
What would settle it
A study in which developers perform real tasks with the generated READMEs and report accuracy, completeness, and time saved compared to ground-truth files.
Figures

read the original abstract
Large Language Models (LLMs) are increasingly utilized to automate several software engineering tasks, including code completion, code summarization, testing, and the generation of repository-level documentation. While Multi-Agent Systems (MAS) are often adopted to support such tasks under the premise that task decomposition improves performance, the impact of architectural complexity on practical efficiency remains under-examined. This study empirically evaluates Retrieval-Augmented Generation (RAG) dependent architectures for the generation of README files for GitHub repositories. In this work, we conducted a systematic comparison between a Single-Agent pipeline, a specialized MAS, and a developer-guided planning (DevPlan) variant, benchmarked against LARCH -- a state-of-the-art baseline -- and the original ground truth. Results indicate a critical architectural trade-off: the Single-Agent pipeline achieves lexical quality comparable to MAS while reducing token consumption by 86% and operating at twice the speed. In contrast, manual taxonomy analysis demonstrates that MAS achieves high structural consistency (98%), resolving formatting issues observed in single-agent approaches. Autonomous planning is identified as the primary pipeline bottleneck; incorporating lightweight developer-guided plans produces the highest overall documentation quality, surpassing all the analyzed configurations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript empirically compares single-agent, multi-agent (MAS), and developer-guided planning (DevPlan) RAG pipelines for generating README.md files, benchmarked against LARCH and ground truth. It claims the single-agent pipeline matches MAS on lexical quality while reducing token use by 86% and doubling speed; MAS reaches 98% structural consistency per manual taxonomy analysis and resolves single-agent formatting issues; autonomous planning is the main bottleneck; and DevPlan produces the highest overall quality.
Significance. If the results hold after addressing the reporting gaps, the work would provide concrete evidence of efficiency-quality trade-offs in agentic architectures for repository documentation tasks, showing that added complexity is not always beneficial and that lightweight developer input can improve outcomes. This could inform practical tool design in software engineering by quantifying token and latency savings alongside consistency metrics.
major comments (3)
- [Abstract] Abstract: The central quantitative claims (lexical comparability, 86% token reduction, 2x speed, 98% structural consistency) are reported without any information on the number of repositories in the dataset, statistical tests performed, error bars or variance, or exclusion criteria. These omissions make the architectural trade-off claims unverifiable from the presented text.
- [Abstract / Results] Manual analysis description (appears in Abstract and likely Results): The 98% structural consistency figure for MAS is obtained via manual taxonomy scoring, yet the manuscript provides no details on the number of raters, blinding procedures, or inter-rater agreement (e.g., Cohen's kappa). This directly affects the reliability of the claim that MAS resolves formatting issues observed in single-agent outputs.
- [Discussion / Conclusion] Discussion / Conclusion: The recommendation that DevPlan yields the highest overall quality and that autonomous planning is the primary bottleneck rests on the untested assumption that lexical overlap, manual taxonomy consistency, token count, and speed are valid proxies for real developer utility. No user studies, downstream task performance measures (e.g., comprehension or maintenance tasks), or correlation analyses with external validity criteria are reported.
minor comments (2)
- [Abstract] The abstract would be strengthened by a single sentence stating the scale of the evaluation (number of repositories) to allow readers to immediately contextualize the reported percentages.
- [Introduction / Methodology] Notation for the three pipelines (Single-Agent, MAS, DevPlan) and the LARCH baseline should be introduced consistently in the first paragraph of the introduction or methodology section to avoid any ambiguity in later comparisons.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each of the major comments below and plan to revise the manuscript to improve transparency and acknowledge limitations.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central quantitative claims (lexical comparability, 86% token reduction, 2x speed, 98% structural consistency) are reported without any information on the number of repositories in the dataset, statistical tests performed, error bars or variance, or exclusion criteria. These omissions make the architectural trade-off claims unverifiable from the presented text.
Authors: We agree that the abstract lacks these details. We will revise the abstract to include the number of repositories in the dataset, note the variance and any error bars from the results section, clarify that statistical tests were not performed (as the study is a descriptive comparison), and specify the exclusion criteria used for repository selection. This will make the claims more verifiable. revision: yes
-
Referee: [Abstract / Results] Manual analysis description (appears in Abstract and likely Results): The 98% structural consistency figure for MAS is obtained via manual taxonomy scoring, yet the manuscript provides no details on the number of raters, blinding procedures, or inter-rater agreement (e.g., Cohen's kappa). This directly affects the reliability of the claim that MAS resolves formatting issues observed in single-agent outputs.
Authors: We will update the manuscript to provide the requested details on the manual analysis. The taxonomy scoring was performed by a single researcher with the taxonomy defined a priori; we will explicitly state this, note that no blinding was used, and report that inter-rater agreement was not calculated due to single-rater design. If possible, we will consider adding a second rater for verification in revisions. revision: yes
-
Referee: [Discussion / Conclusion] Discussion / Conclusion: The recommendation that DevPlan yields the highest overall quality and that autonomous planning is the primary bottleneck rests on the untested assumption that lexical overlap, manual taxonomy consistency, token count, and speed are valid proxies for real developer utility. No user studies, downstream task performance measures (e.g., comprehension or maintenance tasks), or correlation analyses with external validity criteria are reported.
Authors: This is a fair point regarding the scope of our evaluation. While our metrics follow common practices in automated documentation generation research, we acknowledge they are proxies and do not directly assess developer utility. We will revise the discussion and conclusion sections to explicitly discuss this limitation, qualify our claims accordingly, and suggest future work involving user studies or downstream task evaluations to validate the practical utility. revision: yes
Circularity Check
No circularity: purely empirical comparison study
full rationale
The paper presents an empirical evaluation of Single-Agent, Multi-Agent, and DevPlan RAG pipelines for README generation, reporting direct measurements of lexical quality, structural consistency (via manual taxonomy), token use, and speed against baselines and ground truth. No derivations, equations, fitted parameters, predictions, or uniqueness theorems are claimed or invoked. All results are observational comparisons; no step reduces by construction to its own inputs or relies on self-citation chains for load-bearing claims. This matches the default expectation for non-circular empirical measurement work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Lexical similarity metrics and manual structural taxonomy are valid indicators of documentation quality
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Replication package for The Illusion of Agentic Complexity in README.md Generation: Evaluating Single-Agent vs
Anonymous Authors. Replication package for The Illusion of Agentic Complexity in README.md Generation: Evaluating Single-Agent vs. Multi-Agent RAG. https://anonymous.4open.science/r/ML4SE-8268/ README.md, 2026
2026
-
[3]
Understanding the factors that impact the popularity of github repositories
Hudson Borges, Andre Hora, and Marco Tulio Valente. Understanding the factors that impact the popularity of github repositories. In2016 IEEE international conference on software maintenance and evolution (ICSME), pages 334–344. IEEE, 2016
2016
-
[4]
Studying memorization of large language models using answers to stack overflow questions.Transactions on Machine Learning Research, 2025
Laura Caspari, Alexander Trautsch, Michael Granitzer, and Steffen Herbold. Studying memorization of large language models using answers to stack overflow questions.Transactions on Machine Learning Research, 2025
2025
-
[5]
Readmeready: Free and customiz- able code documentation with llms-a fine-tuning approach.Journal of Open Source Software, 10(108):7489, 2025
Sayak Chakrabarty and Souradip Pal. Readmeready: Free and customiz- able code documentation with llms-a fine-tuning approach.Journal of Open Source Software, 10(108):7489, 2025
2025
-
[6]
arXiv preprint arXiv:2502.14425 , year=
Yuxing Cheng, Yi Chang, and Yuan Wu. A survey on data contamination for large language models.arXiv preprint arXiv:2502.14425, 2025
-
[7]
Rmgenie: An llm-based agent framework for open source software readme generation
Xing Cui, Jingzheng Wu, Zhiyuan Li, Tianyue Luo, and Xiang Ling. Rmgenie: An llm-based agent framework for open source software readme generation. In2025 IEEE International Conference on Software Maintenance and Evolution (ICSME), pages 505–516. IEEE, 2025
2025
-
[8]
A comparative analysis of large language models for code documentation generation
Shubhang Shekhar Dvivedi, Vyshnav Vijay, Sai Leela Rahul Pujari, Shoumik Lodh, and Dhruv Kumar. A comparative analysis of large language models for code documentation generation. InProceedings of the 1st ACM international conference on AI-powered software, pages 65–73, 2024
2024
-
[9]
Haoyu Gao, Hong Yi Lin, Christoph Treude, Gregory Gay, and Man- sooreh Zahedi. Does my readme file need to be updated? exploring llm-based readme maintenance.arXiv preprint arXiv:2603.00489, 2026
-
[10]
Single-agent or multi-agent systems? why not both? arXiv preprint arXiv:2505.18286, 2025
Mingyan Gao, Yanzi Li, Banruo Liu, Yifan Yu, Phillip Wang, Ching-Yu Lin, and Fan Lai. Single-agent or multi-agent systems? why not both? arXiv preprint arXiv:2505.18286, 2025
-
[11]
CodeWiki: Evaluating AI's Ability to Generate Holistic Documentation for Large-Scale Codebases
Anh Nguyen Hoang, Minh Le-Anh, Bach Le, and Nghi DQ Bui. Codewiki: Evaluating ai’s ability to generate holistic documentation for large-scale codebases.arXiv preprint arXiv:2510.24428, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Metagpt: Meta programming for a multi-agent collaborative framework
Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, et al. Metagpt: Meta programming for a multi-agent collaborative framework. InThe twelfth international conference on learning representations, 2023
2023
-
[13]
Correlating automated and human evaluation of code documentation generation quality.ACM Transactions on Software Engineering and Methodology (TOSEM), 31(4):1–28, 2022
Xing Hu, Qiuyuan Chen, Haoye Wang, Xin Xia, David Lo, and Thomas Zimmermann. Correlating automated and human evaluation of code documentation generation quality.ACM Transactions on Software Engineering and Methodology (TOSEM), 31(4):1–28, 2022
2022
-
[14]
A survey on large language models for code generation.ACM Transactions on Software Engineering and Methodology, 35(2):1–72, 2026
Juyong Jiang, Fan Wang, Jiasi Shen, Sungju Kim, and Sunghun Kim. A survey on large language models for code generation.ACM Transactions on Software Engineering and Methodology, 35(2):1–72, 2026
2026
-
[15]
Automatic code documentation generation using gpt-3
Junaed Younus Khan and Gias Uddin. Automatic code documentation generation using gpt-3. InProceedings of the 37th IEEE/ACM Inter- national Conference on Automated Software Engineering, pages 1–6, 2022
2022
-
[16]
Larch: Large language model-based automatic readme creation with heuristics
Yuta Koreeda, Terufumi Morishita, Osamu Imaichi, and Yasuhiro So- gawa. Larch: Large language model-based automatic readme creation with heuristics. InProceedings of the 32nd ACM International Con- ference on Information and Knowledge Management, pages 5066–5070, 2023
2023
-
[17]
LangChain
LangChain. LangChain. https://www.langchain.com/, 2026. [Online; accessed May 6, 2026]
2026
-
[18]
Comparing code explanations created by students and large language models
Juho Leinonen, Paul Denny, Stephen MacNeil, Sami Sarsa, Seth Bern- stein, Joanne Kim, Andrew Tran, and Arto Hellas. Comparing code explanations created by students and large language models. InProceed- ings of the 2023 Conference on Innovation and Technology in Computer Science Education V . 1, pages 124–130, 2023
2023
-
[19]
How readme files are structured in open source java projects.Information and Software Technology, 148:106924, 2022
Yuyang Liu, Ehsan Noei, and Kelly Lyons. How readme files are structured in open source java projects.Information and Software Technology, 148:106924, 2022
2022
-
[20]
Qinyu Luo, Yining Ye, Shihao Liang, Zhong Zhang, Yujia Qin, Yaxi Lu, Yesai Wu, Xin Cong, Yankai Lin, Yingli Zhang, et al. Repoagent: An llm-powered open-source framework for repository-level code doc- umentation generation.arXiv preprint arXiv:2402.16667, 2024
-
[21]
Curating github for engineered software projects.Empirical Software Engineering, 22(6):3219–3253, 2017
Nuthan Munaiah, Steven Kroh, Craig Cabrey, and Meiyappan Nagappan. Curating github for engineered software projects.Empirical Software Engineering, 22(6):3219–3253, 2017
2017
-
[22]
Using an llm to help with code understanding
Daye Nam, Andrew Macvean, Vincent Hellendoorn, Bogdan Vasilescu, and Brad Myers. Using an llm to help with code understanding. InProceedings of the IEEE/ACM 46th International Conference on Software Engineering, pages 1–13, 2024
2024
-
[23]
Teamwork makes the dream work: Llms-based agents for github readme
Duc SH Nguyen, Bach G Truong, Phuong T Nguyen, Juri Di Rocco, and Davide Di Ruscio. Teamwork makes the dream work: Llms-based agents for github readme. md summarization. InProceedings of the 33rd ACM International Conference on the Foundations of Software Engineering, pages 621–625, 2025
2025
-
[24]
Repository-level code understanding by llms via hierarchical summarization: Improving code search and bug localiza- tion
Amirkia Rafiei Oskooei, Selcan Yukcu, Mehmet Cevheri Bozoglan, and Mehmet S Aktas. Repository-level code understanding by llms via hierarchical summarization: Improving code search and bug localiza- tion. InInternational Conference on Computational Science and Its Applications, pages 88–105. Springer, 2025
2025
-
[25]
Chatdev: Communicative agents for software development
Chen Qian, Wei Liu, Hongzhang Liu, Nuo Chen, Yufan Dang, Jiahao Li, Cheng Yang, Weize Chen, Yusheng Su, Xin Cong, et al. Chatdev: Communicative agents for software development. InProceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers), pages 15174–15186, 2024
2024
-
[26]
Automated and context- aware code documentation leveraging advanced llms
Swapnil Sharma Sarker and Tanzina Taher Ifty. Automated and context- aware code documentation leveraging advanced llms. InProceedings of the 18th International Natural Language Generation Conference, pages 486–498, 2025
2025
-
[27]
Judging the judges: A systematic study of position bias in llm-as-a-judge
Lin Shi, Chiyu Ma, Wenhua Liang, Xingjian Diao, Weicheng Ma, and Soroush V osoughi. Judging the judges: A systematic study of position bias in llm-as-a-judge. InProceedings of the 14th International Joint Conference on Natural Language Processing and the 4th Conference of the Asia-Pacific Chapter of the Association for Computational Linguis- tics, pages 2...
2025
-
[28]
Repository- level prompt generation for large language models of code
Disha Shrivastava, Hugo Larochelle, and Daniel Tarlow. Repository- level prompt generation for large language models of code. InInterna- tional Conference on Machine Learning, pages 31693–31715. PMLR, 2023
2023
-
[29]
Context-aware code summary generation.arXiv preprint arXiv:2408.09006, 2024
Chia-Yi Su, Aakash Bansal, Yu Huang, Toby Jia-Jun Li, and Collin McMillan. Context-aware code summary generation.arXiv preprint arXiv:2408.09006, 2024
-
[30]
Magis: Llm-based multi-agent framework for github issue resolution.Advances in Neural Information Processing Systems, 37:51963–51993, 2024
Wei Tao, Yucheng Zhou, Yanlin Wang, Wenqiang Zhang, Hongyu Zhang, and Yu Cheng. Magis: Llm-based multi-agent framework for github issue resolution.Advances in Neural Information Processing Systems, 37:51963–51993, 2024
2024
-
[31]
A survey on large language model based autonomous agents.Frontiers of Computer Science, 18(6):186345, 2024
Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, et al. A survey on large language model based autonomous agents.Frontiers of Computer Science, 18(6):186345, 2024
2024
-
[32]
Study the correlation between the readme file of github projects and their popularity.Journal of Systems and Software, 205:111806, 2023
Tianlei Wang, Shaowei Wang, and Tse-Hsun Peter Chen. Study the correlation between the readme file of github projects and their popularity.Journal of Systems and Software, 205:111806, 2023
2023
- [33]
-
[34]
Autogen: Enabling next-gen llm applications via multi-agent conversations
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, et al. Autogen: Enabling next-gen llm applications via multi-agent conversations. In First conference on language modeling, 2024
2024
-
[35]
Dayu Yang, Antoine Simoulin, Xin Qian, Xiaoyi Liu, Yuwei Cao, Zhaopu Teng, and Grey Yang. Docagent: A multi-agent system for auto- mated code documentation generation.arXiv preprint arXiv:2504.08725, 2025
-
[36]
Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information processing systems, 36:46595–46623, 2023
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhang- hao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information processing systems, 36:46595–46623, 2023
2023
-
[37]
Yifeng Zhu, Xianlin Zhao, Xutian Li, Yanzhen Zou, Haizhuo Yuan, Yue Wang, and Bing Xie. Reposummary: Feature-oriented summarization and documentation generation for code repositories.arXiv preprint arXiv:2510.11039, 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.