Learning from Reliable Latent Prompts for Visual Recognition with Missing Modalities
Pith reviewed 2026-06-30 06:04 UTC · model grok-4.3
The pith
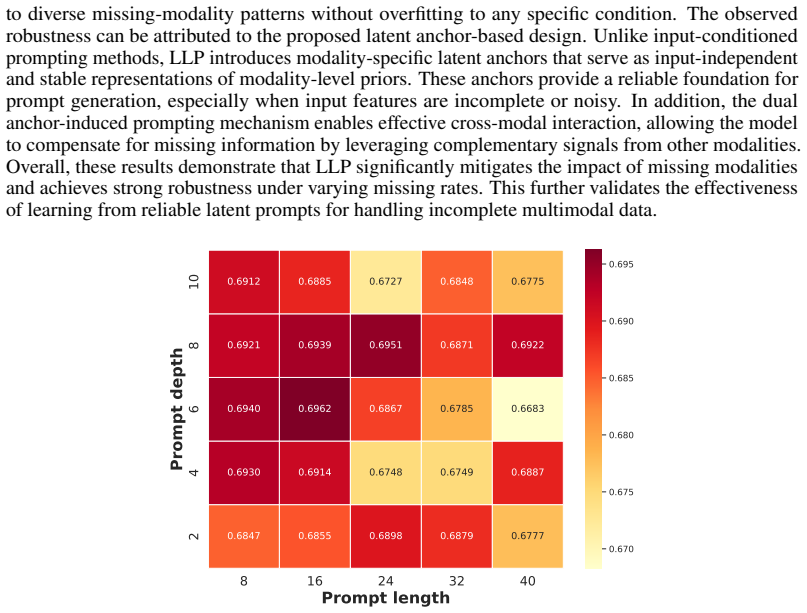
Learnable latent prompts capture stable modality-intrinsic priors that remain reliable even when input modalities are heavily missing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
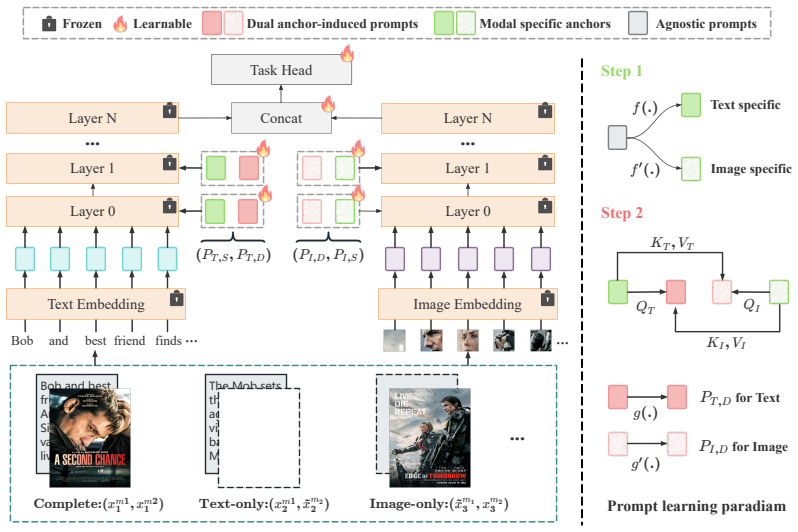
By modeling input-agnostic learnable prompts as stable latent anchors rather than generating them from unreliable instance features, the method supplies robust guidance and effective cross-modal knowledge compensation under high rates of missing modalities.
What carries the argument
Input-agnostic learnable prompts treated as stable latent anchors that encode modality-intrinsic priors independent of corrupted inputs.
If this is right
- The method achieves state-of-the-art accuracy on three benchmark datasets under a wide range of missing-modality conditions.
- Performance remains high even when 90 percent of modalities are absent.
- The paradigm supplies a robust alternative to input-conditioned prompt strategies for the missing-modality problem.
Where Pith is reading between the lines
- The same latent-anchor idea could be tested on other multimodal tasks such as audio-visual or text-image retrieval.
- If the priors prove truly input-agnostic, the approach might reduce reliance on explicit modality imputation or reconstruction steps.
- The design suggests a general route for making prompt-based models more tolerant to noisy or incomplete training signals.
Load-bearing premise
Learnable latent prompts can hold stable, modality-intrinsic information that does not depend on the actual input data being present.
What would settle it
A controlled comparison at 90 percent missing rate where replacing the latent-prompt module with a standard input-conditioned prompt generator produces equal or better accuracy.
Figures





read the original abstract
Large-scale multimodal models (LMMs) have achieved superior performance in visual recognition by synergizing information across diverse, massive-scale paired modalities. In real-world scenarios, however, missing-modality inputs are ubiquitous, causing models optimized for modality-complete data to exhibit precipitous performance degradation. Existing research has introduced prompt learning to mitigate this issue, typically by generating dynamic prompts from instance-level features, regardless of whether the input modalities are complete or partially absent. However, such input-conditioned strategies are hindered by the escalating unreliability of instance-level features; as higher missing rates increase the proportion of incomplete modalities, the resulting instability in prompt learning limits the model's performance. To address this limitation, we hypothesize that learnable latent prompts themselves encapsulate stable, modality-intrinsic priors that are decoupled from corrupted inputs. Consequently, we propose a novel paradigm: Learning from Reliable Latent Prompts. Unlike prior methods, we model input-agnostic learnable prompts as stable latent anchors that enable robust guidance and effective cross-modal knowledge compensation, even under extreme missing rates (e.g., 90%). Empirical results across three benchmark datasets demonstrate that our "learn-from-latent-prompts" approach achieves state-of-the-art performance across a wide range of missing-modality scenarios. Extensive experiments further confirm the effectiveness of this paradigm in providing a robust solution to the missing-modality problem.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper hypothesizes that learnable latent prompts encapsulate stable, modality-intrinsic priors decoupled from corrupted inputs. It proposes a 'Learning from Reliable Latent Prompts' paradigm that models input-agnostic prompts as stable latent anchors for robust cross-modal compensation under missing modalities (including extreme rates like 90%). It claims this yields state-of-the-art performance on three benchmark datasets across a wide range of missing-modality scenarios, outperforming prior input-conditioned prompt-learning methods.
Significance. If the empirical claims hold with proper validation, the approach could address a practical limitation in multimodal models by avoiding instability from instance-level feature conditioning at high missing rates, offering a more reliable paradigm for real-world visual recognition tasks.
major comments (2)
- Abstract: The manuscript asserts SOTA empirical results across three benchmark datasets and a wide range of missing-modality scenarios but supplies no methods, baselines, error bars, dataset details, ablation studies, or quantitative evidence, rendering the central performance claim unverifiable from the provided text.
- Abstract (paragraph 2): The claim that input-conditioned strategies are limited by 'escalating unreliability of instance-level features' at higher missing rates is presented as motivation, but no supporting analysis, equations, or preliminary results are shown to establish this as the load-bearing limitation versus other factors.
minor comments (1)
- Abstract: The term 'learn-from-latent-prompts' is introduced in quotes without a clear definition or distinction from standard prompt learning in the opening paragraphs.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments on the abstract below. The full manuscript contains the requested details in Sections 3–5; we propose targeted revisions to the abstract for improved clarity.
read point-by-point responses
-
Referee: Abstract: The manuscript asserts SOTA empirical results across three benchmark datasets and a wide range of missing-modality scenarios but supplies no methods, baselines, error bars, dataset details, ablation studies, or quantitative evidence, rendering the central performance claim unverifiable from the provided text.
Authors: The abstract is intentionally concise and summarizes the contribution; the full manuscript supplies all requested elements (methods in Sec. 3, baselines/results with error bars in Sec. 4, dataset details in Sec. 4.1, ablations in Sec. 5). To make the abstract more self-contained, we will revise it to name the three benchmarks and note the consistent outperformance margin. revision: yes
-
Referee: Abstract (paragraph 2): The claim that input-conditioned strategies are limited by 'escalating unreliability of instance-level features' at higher missing rates is presented as motivation, but no supporting analysis, equations, or preliminary results are shown to establish this as the load-bearing limitation versus other factors.
Authors: The motivation is substantiated by analysis and preliminary experiments in Sec. 3.2 of the full manuscript, which quantify the instability of instance-level conditioning at high missing rates. We will add a brief parenthetical reference to this analysis in the revised abstract. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper articulates a hypothesis that input-agnostic latent prompts provide stable modality-intrinsic priors, proposes a corresponding paradigm, and reports empirical SOTA results on three benchmarks. No equations, fitted parameters renamed as predictions, or self-citation chains are present in the supplied text that would reduce the central claim to a definitional tautology or construction from its own inputs. The derivation is self-contained as a standard empirical proposal whose validity rests on external benchmark performance rather than internal reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Alayrac, J
J.-B. Alayrac, J. Donahue, P. Luc, A. Miech, I. Barr, Y . Hasson, K. Lenc, A. Mensch, K. Millican, M. Reynolds, et al. Flamingo: a visual language model for few-shot learning.Advances in neural information processing systems, 35:23716–23736, 2022
2022
-
[2]
Gated Multimodal Units for Information Fusion
J. Arevalo, T. Solorio, M. Montes-y Gómez, and F. A. González. Gated multimodal units for information fusion.arXiv preprint arXiv:1702.01992, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[3]
Arnab, M
A. Arnab, M. Dehghani, G. Heigold, C. Sun, M. Luˇci´c, and C. Schmid. Vivit: A video vision transformer. InProceedings of the IEEE/CVF international conference on computer vision, pages 6836–6846, 2021
2021
-
[4]
J. L. Ba, J. R. Kiros, and G. E. Hinton. Layer normalization.arXiv preprint arXiv:1607.06450, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[5]
Brown, B
T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, et al. Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020
1901
-
[6]
T. Chen and Y . Cheung. Tyrppg: Uncomplicated and enhanced learning capability rppg for remote heart rate estimation.arXiv preprint arXiv:2511.05833, 2025
- [7]
-
[8]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Min- derer, G. Heigold, S. Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[9]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
A. Gu and T. Dao. Mamba: Linear-time sequence modeling with selective state spaces.arXiv preprint arXiv:2312.00752, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
Guo and X
Y . Guo and X. Gu. Mmrl: Multi-modal representation learning for vision-language models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 25015–25025, 2025
2025
-
[11]
Gaussian Error Linear Units (GELUs)
D. Hendrycks and K. Gimpel. Gaussian error linear units (gelus).arXiv preprint arXiv:1606.08415, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[12]
L. Hu, T. Shi, W. Feng, F. Shang, and L. Wan. Deep correlated prompting for visual recognition with missing modalities.Advances in Neural Information Processing Systems, 37:67446–67466, 2024
2024
-
[13]
Huang, A
W. Huang, A. Wu, Y . Yang, X. Luo, Y . Yang, U. Naseem, C. Wang, Q. Dai, X. Dai, D. Chen, et al. Llm2clip: Powerful language model unlocks richer cross-modality representation. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 5131–5139, 2026
2026
-
[14]
Iashin and E
V . Iashin and E. Rahtu. Multi-modal dense video captioning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops, pages 958–959, 2020
2020
-
[15]
Jiang and M
D. Jiang and M. Ye. Cross-modal implicit relation reasoning and aligning for text-to-image person retrieval. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2787–2797, 2023
2023
-
[16]
M. U. Khattak, H. Rasheed, M. Maaz, S. Khan, and F. S. Khan. Maple: Multi-modal prompt learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 19113–19122, 2023
2023
-
[17]
Kiela, H
D. Kiela, H. Firooz, A. Mohan, V . Goswami, A. Singh, P. Ringshia, and D. Testuggine. The hateful memes challenge: Detecting hate speech in multimodal memes.Advances in neural information processing systems, 33:2611–2624, 2020
2020
-
[18]
W. Kim, B. Son, and I. Kim. Vilt: Vision-and-language transformer without convolution or region supervision. InInternational conference on machine learning, pages 5583–5594. PMLR, 2021
2021
-
[19]
J. Lang, R. Hong, Z. Cheng, T. Zhong, Y . Wang, and F. Zhou. Redeeming modality information loss: Retrieval-guided conditional generation for severely modality missing learning. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 2, pages 1241–1252, 2025. 10
2025
-
[20]
Lee, Y .-H
Y .-L. Lee, Y .-H. Tsai, W.-C. Chiu, and C.-Y . Lee. Multimodal prompting with missing modalities for visual recognition. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14943–14952, 2023
2023
-
[21]
Lester, R
B. Lester, R. Al-Rfou, and N. Constant. The power of scale for parameter-efficient prompt tuning. InProceedings of the 2021 conference on empirical methods in natural language processing, pages 3045–3059, 2021
2021
-
[22]
J. Li, D. Li, S. Savarese, and S. Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InInternational conference on machine learning, pages 19730–19742. PMLR, 2023
2023
-
[23]
L. H. Li, P. Zhang, H. Zhang, J. Yang, C. Li, Y . Zhong, L. Wang, L. Yuan, L. Zhang, J.-N. Hwang, et al. Grounded language-image pre-training. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10965–10975, 2022
2022
-
[24]
X. L. Li and P. Liang. Prefix-tuning: Optimizing continuous prompts for generation. InProceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 4582–4597, 2021
2021
-
[25]
X. Liu, K. Ji, Y . Fu, W. Tam, Z. Du, Z. Yang, and J. Tang. P-tuning: Prompt tuning can be comparable to fine-tuning across scales and tasks. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 61–68, 2022
2022
- [26]
-
[27]
A. Lu, C. Li, J. Zhao, J. Tang, and B. Luo. Modality-missing rgbt tracking: Invertible prompt learning and high-quality benchmarks.International Journal of Computer Vision, 133(5):2599–2619, 2025
2025
-
[28]
M. Ma, J. Ren, L. Zhao, D. Testuggine, and X. Peng. Are multimodal transformers robust to missing modality? InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 18177–18186, 2022
2022
-
[29]
X. Meng, K. Sun, J. Xu, X. He, and D. Shen. Multi-modal modality-masked diffusion network for brain mri synthesis with random modality missing.IEEE Transactions on Medical Imaging, 43(7):2587–2598, 2024
2024
-
[30]
Radford, J
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
2021
-
[31]
Sarto, M
S. Sarto, M. Barraco, M. Cornia, L. Baraldi, and R. Cucchiara. Positive-augmented contrastive learning for image and video captioning evaluation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6914–6924, 2023
2023
-
[32]
C. Sima, K. Renz, K. Chitta, L. Chen, H. Zhang, C. Xie, J. Beißwenger, P. Luo, A. Geiger, and H. Li. Drivelm: Driving with graph visual question answering. InEuropean conference on computer vision, pages 256–274. Springer, 2024
2024
-
[33]
Vaswani, N
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
2017
-
[34]
H. Wang, Y . Chen, C. Ma, J. Avery, L. Hull, and G. Carneiro. Multi-modal learning with missing modality via shared-specific feature modelling. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15878–15887, 2023
2023
-
[35]
X. Wang, D. Kumar, N. Thome, M. Cord, and F. Precioso. Recipe recognition with large multimodal food dataset. In2015 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), pages 1–6. IEEE, 2015
2015
-
[36]
Y . Wang, Z. Cui, and Y . Li. Distribution-consistent modal recovering for incomplete multimodal learning. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 22025–22034, 2023
2023
-
[37]
R. Wu, H. Wang, H.-T. Chen, and G. Carneiro. Deep multimodal learning with missing modality: A survey. arXiv preprint arXiv:2409.07825, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
Z. Wu, J. Zheng, X. Ren, F.-A. Vasluianu, C. Ma, D. P. Paudel, L. Van Gool, and R. Timofte. Single-model and any-modality for video object tracking. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 19156–19166, 2024. 11
2024
- [39]
-
[40]
Y . Yuan, Z. Li, and B. Zhao. A survey of multimodal learning: Methods, applications, and future.ACM Computing Surveys, 57(7):1–34, 2025
2025
-
[41]
Zhang, S
J. Zhang, S. Wu, L. Gao, H. T. Shen, and J. Song. Dept: Decoupled prompt tuning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12924–12933, 2024
2024
-
[42]
Zhang, F
X. Zhang, F. Zhang, and C. Xu. Vqacl: A novel visual question answering continual learning setting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19102– 19112, 2023
2023
-
[43]
Zhang, L
Z. Zhang, L. Dai, Q. Lin, Y . Diao, G. Jin, Y . Guo, J. Zhang, and X. Hao. Synergistic prompting for robust visual recognition with missing modalities. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 1881–1890, 2025
2025
-
[44]
K. Zhou, J. Yang, C. C. Loy, and Z. Liu. Conditional prompt learning for vision-language models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16816–16825, 2022
2022
-
[45]
K. Zhou, J. Yang, C. C. Loy, and Z. Liu. Learning to prompt for vision-language models.International journal of computer vision, 130(9):2337–2348, 2022. 12 A Technical appendices and supplementary material (a) SyP (b) Ours Figure 5: Visualization of concatenated prompt-enhanced features from the two encoders on the Food101 dataset [35] under the missing-b...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.