Repetition-code-based readout error detection and correction across hardware platforms and generations
Pith reviewed 2026-06-30 05:47 UTC · model grok-4.3
The pith
Repetition codes improve readout fidelity on both superconducting and trapped-ion processors across multiple hardware generations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
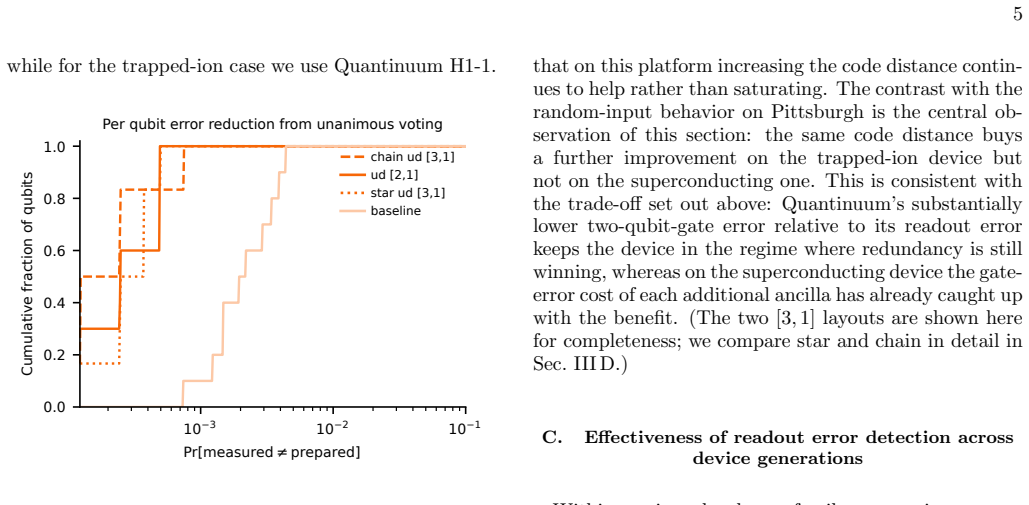
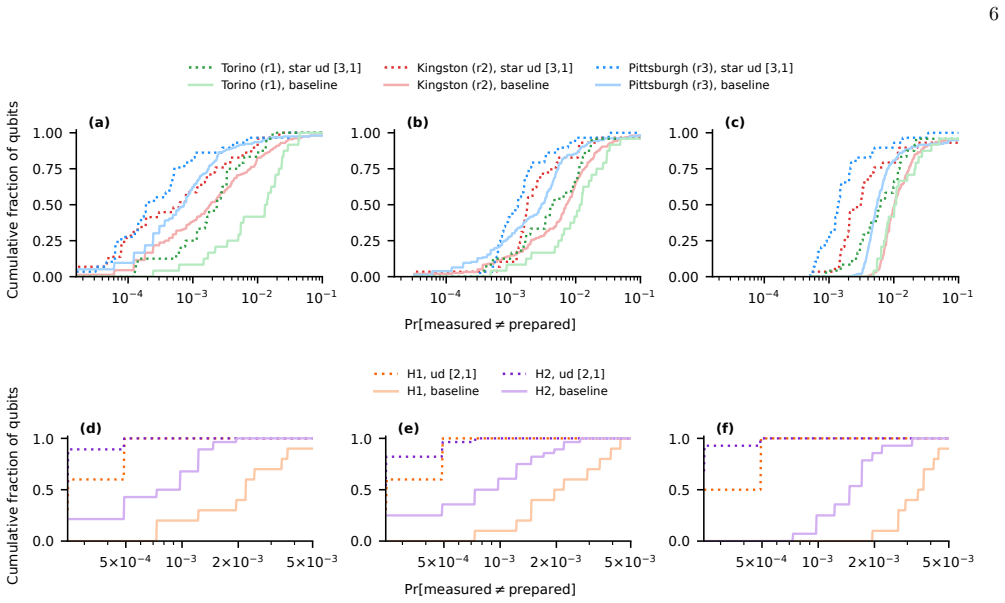
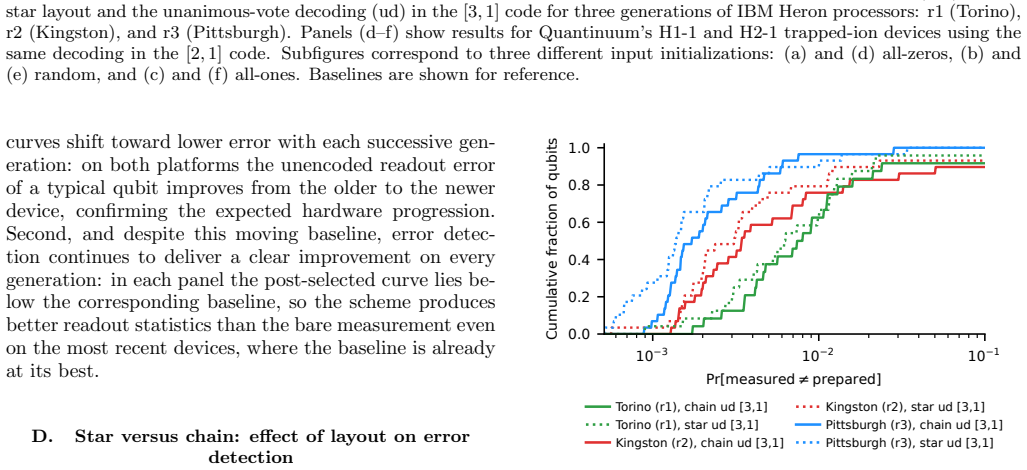
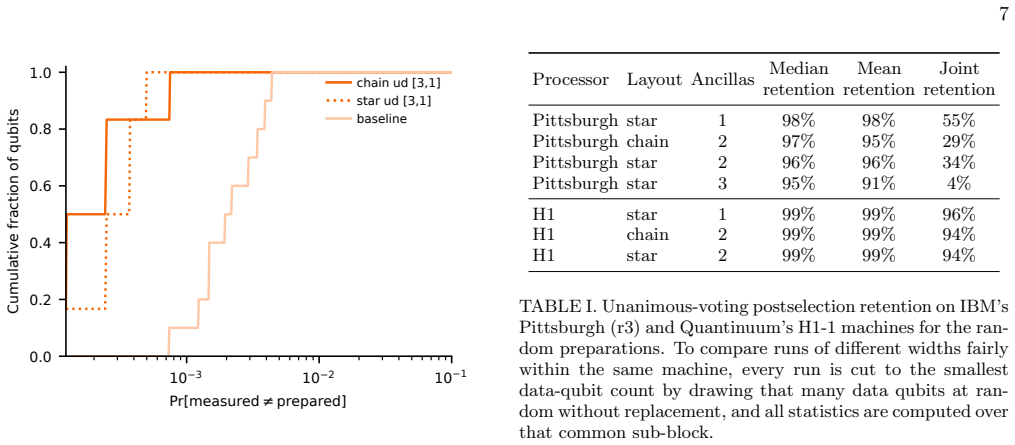
Encoding data qubits with repetition codes immediately before measurement, followed by post-selection or majority-vote decoding, raises readout fidelity on every tested superconducting and trapped-ion processor. The gains hold across hardware generations despite large improvements in the unencoded baseline. On superconducting hardware the extra gates required for encoding quickly offset further redundancy, whereas on trapped-ion hardware the lower gate error rates allow larger code distances to remain advantageous.
What carries the argument
Repetition-code encoding of each data qubit with ancilla qubits before measurement, decoded by post-selection for error detection or majority voting for error correction.
If this is right
- Both error detection by post-selection and error correction by majority vote improve fidelity on every device and generation examined.
- The benefit of the method persists even as unencoded readout fidelity improves across successive hardware releases.
- On superconducting processors the gate errors introduced by encoding limit the useful code distance.
- On trapped-ion processors lower gate errors allow larger code distances to deliver additional gains.
- The approach produces corrected individual measurement shots rather than only corrected aggregate statistics.
Where Pith is reading between the lines
- Platform-specific optimization of code distance may be required rather than a single universal repetition-code choice.
- The shot-level correction could be layered with other mitigation techniques for sampling-based algorithms where individual outcomes matter.
- Hardware generations that further reduce two-qubit gate errors would likely expand the range of useful code distances on superconducting platforms.
- The same encoding idea could be tested on other error sources that act only at the measurement stage.
Load-bearing premise
The fidelity gains are caused by the repetition-code encoding and decoding steps rather than by differences in calibration, crosstalk, or measurement settings between the encoded and unencoded runs.
What would settle it
An interleaved comparison on one device, with identical calibration and settings for encoded and unencoded shots, that shows no fidelity difference between the two would falsify the central claim.
Figures



read the original abstract
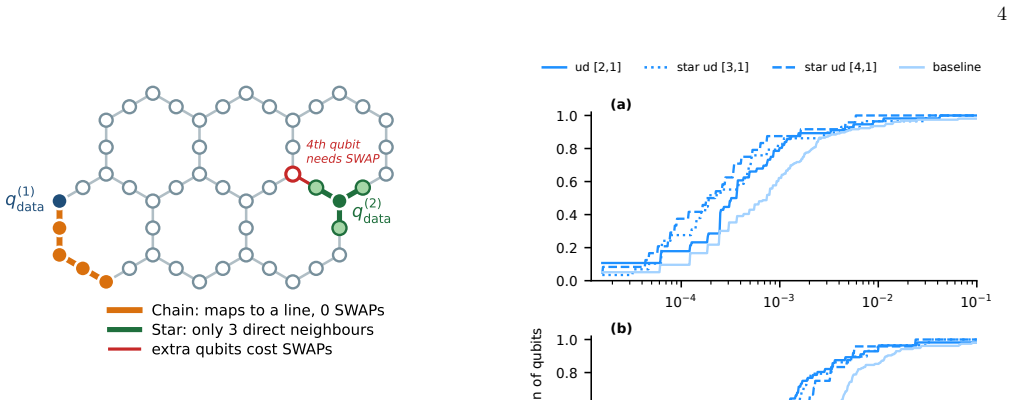
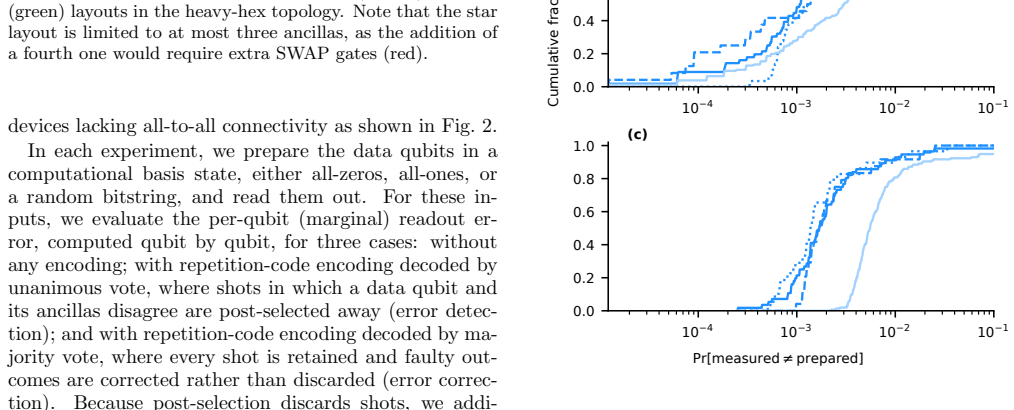
Readout errors are one of the dominant sources of noise in current quantum processors, limiting both expectation-value estimation and sampling-based applications. Since they affect only the classical measurement outcomes, they can be addressed using classical coding techniques: immediately before measurement, each data qubit is redundantly encoded with ancilla qubits, and the resulting bit string is decoded either by post-selection or by majority voting. Unlike conventional readout error mitigation, which corrects only aggregate quantities such as expectation values, this approach operates on individual measurement shots and can therefore produce approximately corrected samples. We present a systematic cross-platform and cross-generation experimental evaluation of repetition-code readout error detection and correction. We benchmark the same protocol on IBM Heron r1-r3 superconducting processors and Quantinuum H1 and H2 trapped-ion processors while independently varying the code distance, hardware generation, and encoding layout. We find that both error detection and correction improve readout fidelity on every device and generation tested, even as the unencoded baseline improves substantially across successive hardware releases. At the same time, the value of additional redundancy depends strongly on the underlying hardware. On superconducting processors, the extra gate errors introduced by the encoding rapidly offset its benefits, whereas on trapped-ion processors the much lower gate error rates allow larger code distances to remain advantageous.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a cross-platform experimental benchmark of repetition-code-based readout error detection (via post-selection) and correction (via majority voting) on IBM Heron r1-r3 superconducting processors and Quantinuum H1/H2 trapped-ion processors. The central empirical claim is that both techniques improve readout fidelity on every device and generation tested, even while unencoded baselines improve across hardware releases, with the utility of additional code distance being strongly hardware-dependent (rapidly offset by gate errors on superconductors but advantageous on ion traps).
Significance. If the attribution of gains to the encoding/decoding protocol holds, the work supplies concrete, hardware-specific guidance on when classical repetition coding is a net win for shot-level readout mitigation. The cross-generation and cross-platform scope is a strength, as is the direct comparison to unencoded baselines measured on the same devices. The results are relevant to near-term algorithms that rely on individual measurement samples rather than aggregate expectation values.
major comments (1)
- [Experimental methods / abstract] The experimental design (described in the abstract and implied methods) does not state that qubit calibrations, readout frequencies, pulse amplitudes, or crosstalk-suppression settings were held identical between encoded and unencoded runs on the same device. This is load-bearing for the central claim that observed fidelity gains arise from the repetition-code protocol rather than from undocumented changes in hardware state or measurement settings between the two classes of circuits.
minor comments (2)
- Error-bar details, number of shots per data point, and any post-selection rates or raw data tables are not referenced in the provided abstract; inclusion of these would strengthen auditability of the fidelity gains.
- The abstract states that layouts were varied but does not indicate whether the same physical qubits were used for encoded and baseline measurements; clarifying this would help rule out spatial variation as a confound.
Simulated Author's Rebuttal
We thank the referee for their constructive review and for identifying this important point about experimental controls. We address the comment below and have revised the manuscript to include the requested clarification.
read point-by-point responses
-
Referee: The experimental design (described in the abstract and implied methods) does not state that qubit calibrations, readout frequencies, pulse amplitudes, or crosstalk-suppression settings were held identical between encoded and unencoded runs on the same device. This is load-bearing for the central claim that observed fidelity gains arise from the repetition-code protocol rather than from undocumented changes in hardware state or measurement settings between the two classes of circuits.
Authors: We agree that explicit confirmation of unchanged hardware settings is required to support the attribution of fidelity gains to the encoding protocol. The original manuscript did not include this statement. In the revised version we have added a new paragraph to the Experimental Methods section stating that, for each device, all qubit calibrations, readout frequencies, pulse amplitudes, and crosstalk-suppression settings were held fixed between the encoded and unencoded circuits. These parameters are set by the hardware provider’s automated calibration routines and were not altered between the two classes of experiments. This addition directly addresses the concern and strengthens the central claim. revision: yes
Circularity Check
No circularity: experimental benchmarking with direct hardware comparisons
full rationale
The paper is a cross-platform experimental study that measures readout fidelity for repetition-code encoded circuits versus unencoded baselines on the same devices. No mathematical derivation, parameter fitting, or prediction is claimed; results are obtained by direct execution and post-processing on IBM and Quantinuum hardware. The central claim rests on empirical comparison rather than any self-referential definition or self-citation chain. No load-bearing step reduces to an input by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Measurement outcomes can be treated as classical bit strings after the final gates.
- domain assumption Gate errors introduced by the encoding circuit are the dominant additional noise source on superconducting hardware.
Reference graph
Works this paper leans on
-
[1]
F. B. Maciejewski, Z. Zimbor´ as, and M. Oszmaniec, Mit- igation of readout noise in near-term quantum devices by classical post-processing based on detector tomography, Quantum4, 257 (2020)
2020
-
[2]
Bravyi, S
S. Bravyi, S. Sheldon, A. Kandala, D. C. Mckay, and J. M. Gambetta, Mitigating measurement errors in mul- tiqubit experiments, Physical Review A103, 042605 (2021)
2021
-
[3]
Y. Chen, M. Farahzad, S. Yoo, and T.-C. Wei, Detector tomography on ibm quantum computers and mitigation of an imperfect measurement, Physical Review A100, 052315 (2019)
2019
-
[4]
M. R. Geller, Rigorous measurement error correction, Quantum Science & Technology5, 03LT01 (2020)
2020
-
[5]
Nachman, M
B. Nachman, M. Urbanek, W. A. de Jong, and C. W. Bauer, Unfolding quantum computer readout noise, npj Quantum Information6, 84 (2020)
2020
-
[6]
P. D. Nation, H. Kang, N. Sundaresan, and J. M. Gambetta, Scalable mitigation of measurement errors on quantum computers, PRX Quantum2, 040326 (2021)
2021
-
[7]
F. B. Maciejewski, F. Baccari, Z. Zimbor´ as, and M. Osz- maniec, Modeling and mitigation of cross-talk effects in readout noise with applications to the quantum approx- imate optimization algorithm, Quantum5, 464 (2021)
2021
-
[8]
A. W. Smith, K. E. Khosla, C. N. Self, and M. Kim, Qubit readout error mitigation with bit-flip averaging, Science advances7, eabi8009 (2021)
2021
-
[9]
B. Yang, R. Raymond, and S. Uno, Efficient quantum readout-error mitigation for sparse measurement out- comes of near-term quantum devices, Physical Review A106, 012423 (2022)
2022
-
[10]
Cosco, F
F. Cosco, F. Plastina, and N. Lo Gullo, Bayesian miti- gation of measurement errors in multiqubit experiments, Physical Review A112, 042621 (2025)
2025
-
[11]
Tensor network characterization and mitigation of readout errors
Y. Guo and S. Yang, Tensor network characterization and mitigation of readout errors (2026), arXiv:2606.25974 [quant-ph]
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[12]
J. M. G¨ unther, F. Tacchino, J. R. Wootton, I. Tavernelli, and P. K. Barkoutsos, Improving readout in quantum simulations with repetition codes, Quantum Science and Technology7, 015009 (2021)
2021
-
[13]
Hicks, B
R. Hicks, B. Kobrin, C. W. Bauer, and B. Nachman, Ac- tive readout-error mitigation, Phys. Rev. A105, 012419 (2022)
2022
-
[14]
van den Berg, S
E. van den Berg, S. Bravyi, J. M. Gambetta, P. Jurce- vic, D. Maslov, and K. Temme, Single-shot error mitiga- tion by coherent pauli checks, Phys. Rev. Res.5, 033193 (2023)
2023
-
[15]
Ouyang, Robust projective measurements through measuring code-inspired observables, npj Quantum In- formation10, 104 (2024)
Y. Ouyang, Robust projective measurements through measuring code-inspired observables, npj Quantum In- formation10, 104 (2024)
2024
-
[16]
Linden and P
N. Linden and P. Skrzypczyk, How to use arbitrary mea- suring devices to perform almost-perfect measurements, Physical Review A112, 022405 (2025)
2025
-
[17]
Reducing measurement error with adaptivity
J. Byrne, N. Linden, and P. Skrzypczyk, Reduc- ing measurement error with adaptivity, arXiv preprint arXiv:2606.21283 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[18]
V. V. Albert and P. Faist, Handbook of error-correcting codes (2026), arXiv:2606.11484 [quant-ph]
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.