What Drives Interactive Improvement from Feedback?
Pith reviewed 2026-07-01 02:33 UTC · model grok-4.3
The pith
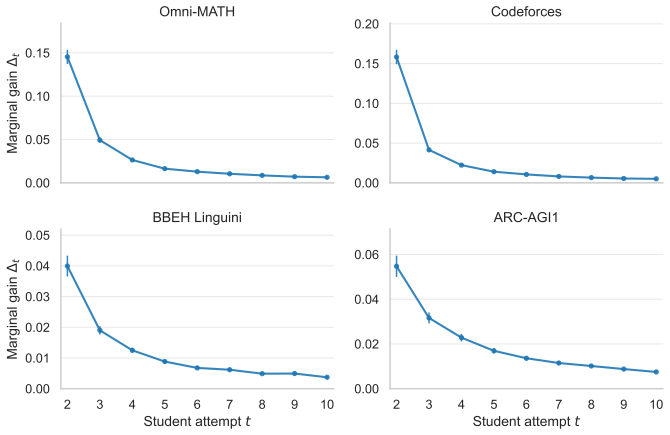
Multi-turn gains from feedback often come from retries rather than the feedback itself.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
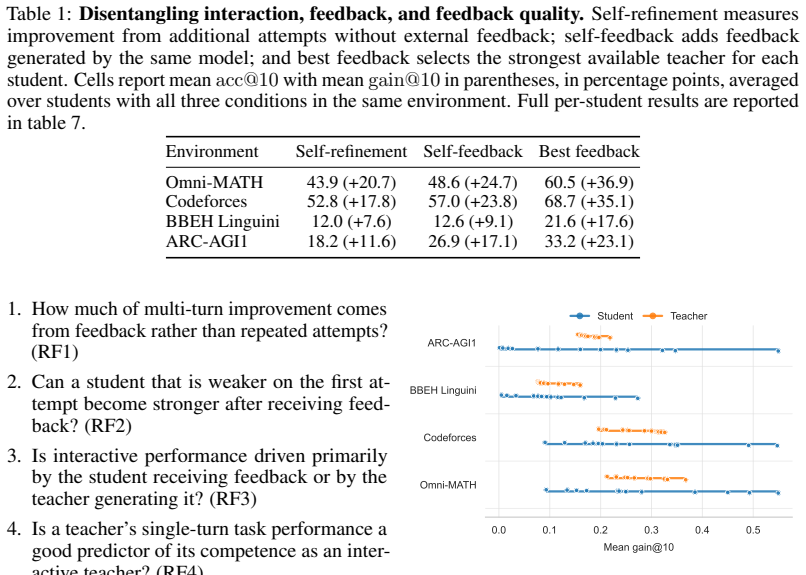
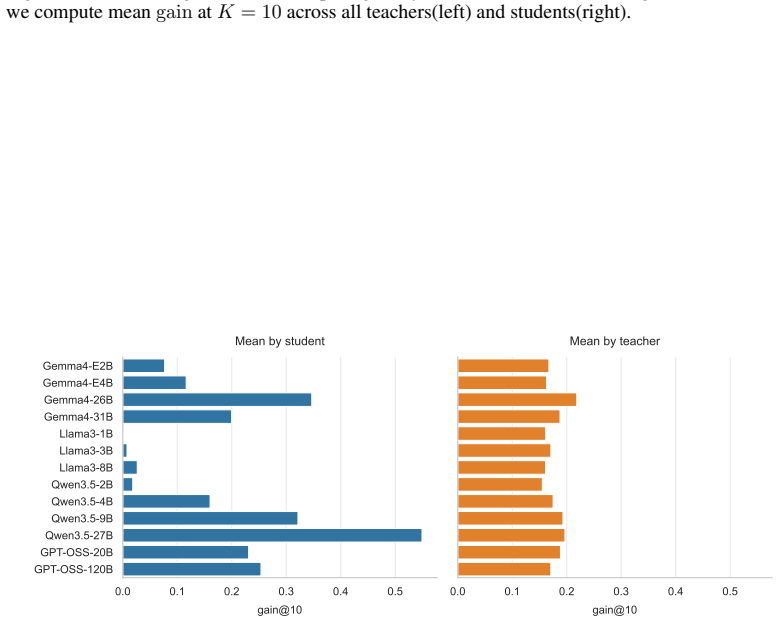
Across Omni-MATH, Codeforces, BBEH Linguini, and ARC-AGI1 with thirteen open-weight models, multi-turn improvement is often not evidence of feedback use: self-generated feedback adds little beyond unguided self-refinement, whereas the strongest external teachers produce substantially larger feedback-specific gains; dense student-teacher interaction matrices further show that interactive gains are driven more by the student's ability to use feedback than by the teacher's identity, although teacher choice remains important for a fixed student.
What carries the argument
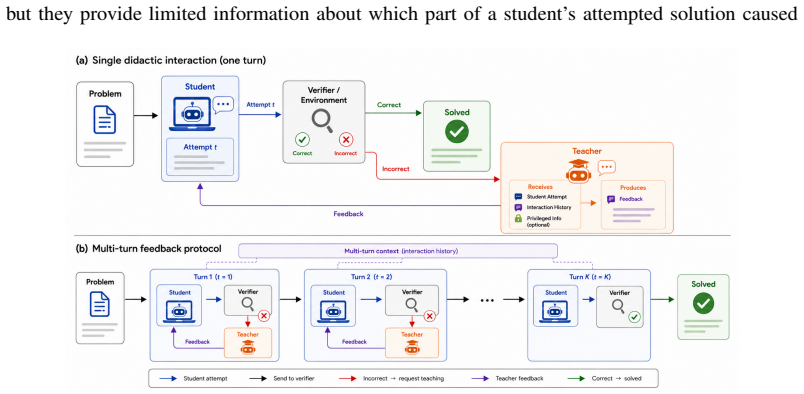
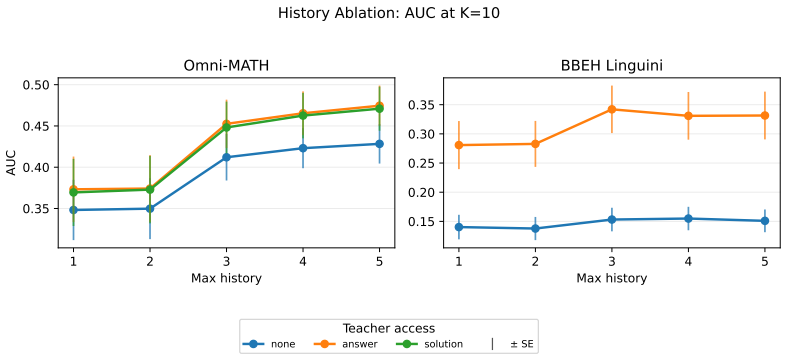
The controlled student-teacher protocol that compares external feedback, self-feedback, and unguided self-refinement while holding constant interaction history, task difficulty, and teacher access to privileged information.
If this is right
- Feedback-based agents should be evaluated against repeated-attempt baselines.
- Ability to act on feedback is a central bottleneck for interactive improvement.
- Self-generated feedback adds little beyond unguided self-refinement.
- Only the strongest external teachers yield substantially larger feedback-specific gains.
- For any fixed student, teacher identity still affects outcomes even though student capability dominates overall.
Where Pith is reading between the lines
- Training models specifically to interpret and apply feedback could yield larger gains than improving feedback generation alone.
- Deployments might benefit more from selecting capable students than from selecting the absolute best teacher.
- The same patterns could be tested with human-provided feedback to check whether model teachers are unusually limited.
- Benchmarks that omit unguided retry controls will systematically overestimate the value of feedback mechanisms.
Load-bearing premise
The protocol isolates the causal effect of natural-language feedback from extra test-time computation, format correction, or resampling.
What would settle it
If matching the number of attempts without any feedback produces the same accuracy gains as the strongest external feedback conditions, the claim of feedback-specific improvement would be falsified.
Figures










read the original abstract
We study when natural-language feedback produces improvement beyond the gains obtainable from repeated attempts alone. In multi-turn language agent setting, higher final accuracy can reflect useful feedback, but it can also arise from resampling, format correction, or additional test-time computation. To separate these effects, we introduce a controlled student-teacher protocol across Omni-MATH, Codeforces, BBEH Linguini, and ARC-AGI1, evaluating thirteen open-weight models in both student and teacher roles. We compare external feedback, self-feedback, and unguided self-refinement, while varying interaction history, task difficulty, and teacher access to privileged task information. Across settings, we find that multi-turn improvement is often not evidence of feedback use: self-generated feedback adds little beyond unguided self-refinement, whereas the strongest external teachers produce substantially larger feedback-specific gains, suggesting that useful feedback must provide guidance beyond generic retry. Dense student-teacher interaction matrices further show that interactive gains are driven more by the student's ability to use feedback than by the teacher's identity, although teacher choice remains important for a fixed student. These results suggest that feedback-based agents should be evaluated against repeated-attempt baselines, and that ability to act on feedback, not merely feedback availability, is a central bottleneck for interactive improvement. We release our controlled student-teacher evaluation framework at https://j-lojek.github.io/feedback-generation-is-a-bottleneck/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that multi-turn improvement in language agents from natural-language feedback is often not evidence of actual feedback utilization. Using a controlled student-teacher protocol on Omni-MATH, Codeforces, BBEH Linguini, and ARC-AGI1 with thirteen open-weight models in student and teacher roles, the authors compare external feedback, self-feedback, and unguided self-refinement while varying interaction history, task difficulty, and teacher access to privileged information. They find self-generated feedback adds little beyond unguided self-refinement, while the strongest external teachers produce substantially larger feedback-specific gains; interactive gains are driven more by the student's ability to use feedback than by teacher identity. The work recommends evaluating feedback-based agents against repeated-attempt baselines and releases the evaluation framework.
Significance. If the central empirical findings hold after confirming the protocol controls, the paper makes a useful contribution by providing a large-scale, multi-benchmark comparison that challenges the interpretation of multi-turn gains as feedback-driven. The release of the controlled evaluation framework is a clear strength that supports reproducibility. The distinction between self-refinement and external feedback effects, and the emphasis on student utilization ability as the bottleneck, offers actionable guidance for designing and evaluating interactive agents.
major comments (2)
- [Abstract] Abstract (protocol description): the central claim that higher accuracy reflects feedback-specific gains rather than repeated-attempt or compute effects requires that the unguided self-refinement baseline exactly matches feedback conditions in total model calls, context length, and any format-correction steps. The provided description states the protocol separates these effects but does not detail the equalization procedure; this is load-bearing because unequal compute would inflate apparent feedback-specific gains from strong teachers and undermine the conclusion that self-feedback adds little beyond unguided refinement.
- [Results] Results on dense student-teacher interaction matrices: the claim that gains are driven more by student ability than teacher identity is presented as a key finding, but without reported variance decomposition, statistical tests for relative effect sizes, or controls for student-teacher pairing imbalances, it is difficult to assess whether this holds after accounting for the varying teacher strengths already shown in the external vs. self conditions.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The two major comments identify areas where additional clarity would strengthen the manuscript. We address each below and outline the revisions we will make.
read point-by-point responses
-
Referee: [Abstract] Abstract (protocol description): the central claim that higher accuracy reflects feedback-specific gains rather than repeated-attempt or compute effects requires that the unguided self-refinement baseline exactly matches feedback conditions in total model calls, context length, and any format-correction steps. The provided description states the protocol separates these effects but does not detail the equalization procedure; this is load-bearing because unequal compute would inflate apparent feedback-specific gains from strong teachers and undermine the conclusion that self-feedback adds little beyond unguided refinement.
Authors: We agree that explicit equalization details are necessary for the central claim. The protocol matches total model calls by giving the unguided baseline the same number of generation attempts as the feedback conditions (one initial attempt plus the same number of refinement turns). Context length is equalized by inserting neutral placeholder messages of comparable token length in the unguided condition. Format-correction steps are applied identically across all conditions. We will add a dedicated subsection in the Methods describing these controls with pseudocode and token-count verification. revision: yes
-
Referee: [Results] Results on dense student-teacher interaction matrices: the claim that gains are driven more by student ability than teacher identity is presented as a key finding, but without reported variance decomposition, statistical tests for relative effect sizes, or controls for student-teacher pairing imbalances, it is difficult to assess whether this holds after accounting for the varying teacher strengths already shown in the external vs. self conditions.
Authors: The dense matrices are intended to convey the pattern through direct visual comparison across all 13×13 pairs rather than aggregate statistics. Student rows exhibit substantially larger variance in feedback-specific gains than teacher columns, and strong students paired with weak teachers still outperform weak students paired with strong teachers. While we did not compute formal variance decomposition or paired statistical tests, the raw per-pair results already control for pairing imbalances by enumerating every combination. We will add a supplementary table reporting mean gain differences and standard deviations across student vs. teacher marginals to make the relative effect sizes more quantitative. revision: partial
Circularity Check
No circularity: purely empirical protocol with no derivations or fitted predictions
full rationale
The paper presents an empirical comparison across multiple benchmarks and models, measuring accuracy deltas under controlled conditions (external feedback, self-feedback, unguided self-refinement). No mathematical derivations, first-principles predictions, fitted parameters renamed as outputs, or self-citation chains are used to generate the reported results. The central claims follow directly from the experimental measurements rather than reducing to inputs by construction. The protocol's isolation of feedback effects is an empirical assumption open to falsification by the data, not a definitional or self-referential step.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The chosen benchmarks (Omni-MATH, Codeforces, BBEH Linguini, ARC-AGI1) provide valid measures of the capabilities under study
- domain assumption Differences in final accuracy after feedback can be attributed to feedback use rather than unmeasured factors
Reference graph
Works this paper leans on
-
[1]
On the measure of intelligence.arXiv preprint arXiv:1911.01547,
François Chollet. On the measure of intelligence.arXiv preprint arXiv:1911.01547,
Pith/arXiv arXiv 1911
-
[2]
9 Jonathan Cook, Diego Antognini, Martin Klissarov, Claudiu Musat, and Edward Grefenstette
URLhttps://arxiv.org/abs/2410.05434. 9 Jonathan Cook, Diego Antognini, Martin Klissarov, Claudiu Musat, and Edward Grefenstette. Learning to learn from language feedback with social meta-learning,
-
[3]
Abhimanyu Dubey, Akhil Jauhri, Abhinav Pandey, et al
URL https: //arxiv.org/abs/2602.16488. Abhimanyu Dubey, Akhil Jauhri, Abhinav Pandey, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
-
[4]
URL https://arxiv.org/abs/ 2402.07157. Yibo Gao et al. Omni-math: A universal olympiad level mathematics benchmark for large language models,
-
[5]
doi: 10.1038/s41586-025-09422-z
ISSN 1476-4687. doi: 10.1038/s41586-025-09422-z. URL http://dx.doi.org/10.1038/s41586-025-09422-z. Adit Gupta, Jennifer Reddig, Tommaso Calo, Daniel Weitekamp, and Christopher J. MacLellan. Beyond final answers: Evaluating large language models for math tutoring,
-
[6]
URL https: //arxiv.org/abs/2503.16460. juvi21. Competitive-coding-benchmark. https://github.com/juvi21/ Competitive-Coding-Benchmark/,
-
[7]
Big-bench extra hard.arXiv preprint arXiv:2502.19187,
Seyed Mehran Kazemi et al. Big-bench extra hard.arXiv preprint arXiv:2502.19187,
-
[8]
URLhttps://arxiv.org/abs/2512.00884. Martin Klissarov, Jonathan Cook, Diego Antognini, Hao Sun, Jingling Li, Natasha Jaques, Claudiu Musat, and Edward Grefenstette. Improving interactive in-context learning from natural language feedback,
-
[9]
10 Philippe Laban, Hiroaki Hayashi, Yingbo Zhou, and Jennifer Neville
URLhttps://arxiv.org/abs/2602.16066. 10 Philippe Laban, Hiroaki Hayashi, Yingbo Zhou, and Jennifer Neville. Llms get lost in multi-turn conversation,
-
[10]
URLhttps://arxiv.org/abs/2505.06120. Harrison Lee, Samrat Phatale, Hassan Mansoor, Thomas Mesnard, Johan Ferret, Kellie Lu, Colton Bishop, Ethan Hall, Victor Carbune, Abhinav Rastogi, and Sushant Prakash. Rlaif vs. rlhf: Scaling reinforcement learning from human feedback with ai feedback,
-
[11]
Xiaoyuan Li, Wenjie Wang, Moxin Li, Junrong Guo, Yang Zhang, and Fuli Feng
URL https: //arxiv.org/abs/2309.00267. Xiaoyuan Li, Wenjie Wang, Moxin Li, Junrong Guo, Yang Zhang, and Fuli Feng. Evaluating mathematical reasoning of large language models: A focus on error identification and correc- tion. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Findings of the Associ- ation for Computational Linguistics: ACL 2024, Ban...
Pith/arXiv arXiv 2024
-
[12]
doi: 10.18653/v1/2024.findings-acl.673
Associ- ation for Computational Linguistics. doi: 10.18653/v1/2024.findings-acl.673. URL https: //aclanthology.org/2024.findings-acl.673/. Kevin Lu and Thinking Machines Lab. On-policy distillation.Thinking Machines Lab: Connection- ism,
-
[13]
https://thinkingmachines.ai/blog/on-policy-distillation
doi: 10.64434/tml.20251026. https://thinkingmachines.ai/blog/on-policy-distillation. OpenAI. Gpt-oss: Open-weight reasoning models. Technical report, OpenAI,
-
[14]
Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D
URL https://arxiv.org/abs/2203.02155. Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model,
-
[15]
URL https://arxiv.org/abs/2305.18290. Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathemat- ical reasoning in open language models,
-
[16]
Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao
URLhttps://arxiv.org/abs/2402.03300. Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning,
-
[17]
URL https://arxiv.org/abs/2303.11366. Qwen Team. Qwen 3.5 technical report: Advancements in multilingual and reasoning capabilities. arXiv preprint arXiv:2602.09123,
-
[18]
Xingyao Wang, Zihan Wang, Jiateng Liu, Yangyi Chen, Lifan Yuan, Hao Peng, and Heng Ji
URLhttps://arxiv.org/abs/2211.04325. Xingyao Wang, Zihan Wang, Jiateng Liu, Yangyi Chen, Lifan Yuan, Hao Peng, and Heng Ji. Mint: Evaluating llms in multi-turn interaction with tools and language feedback,
-
[19]
URL https://arxiv.org/abs/2309.10691. Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdh- ery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models,
-
[20]
URLhttps://arxiv.org/abs/2203.11171. Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models,
-
[21]
Wanqiao Xu, Allen Nie, Ruijie Zheng, Aditya Modi, Adith Swaminathan, and Ching-An Cheng
URLhttps://arxiv.org/abs/2201.11903. Wanqiao Xu, Allen Nie, Ruijie Zheng, Aditya Modi, Adith Swaminathan, and Ching-An Cheng. Provably learning from language feedback,
-
[22]
URL https://arxiv.org/abs/2506.10341. 11 A Experimental Setup Details A.1 Protocol Definition Our evaluation protocol follows the didactic feedback loop of Klissarov et al. [2026], but uses it only as a zero-shot evaluation environment. A single episode contains a task instance, a student model, a teacher model, and a maximum number of student attempts. T...
Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.