Fork-Think with Confidence
Pith reviewed 2026-07-01 06:35 UTC · model grok-4.3
The pith
Fork-think uses confidence scores from one seeding path to pick forking points, then samples multiple continuations to match parallel thinking performance with up to 30% fewer tokens and 57% less runtime.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Fork-think with confidence first identifies forking points using model confidence in a single seeding path, then triggers thinking by sampling multiple continuations from those points and aggregating them for the final response. This reverses the think-first-then-decide order of existing parallel methods, which generate many paths before pruning. The approach achieves comparable or better results on reasoning benchmarks with substantially lower token use and runtime.
What carries the argument
Model confidence scores along a single seeding path used to select forking points for multi-continuation sampling and aggregation.
If this is right
- Token consumption drops by up to 30 percent relative to full parallel sampling.
- Runtime drops by up to 57 percent relative to full parallel sampling.
- Final performance matches or exceeds that of parallel thinking across the tested models and benchmarks.
- Sampling at later positions in the seeding path produces substantially better generations than earlier positions.
- Combining Fork-think with early stopping and weighted voting raises performance to levels comparable with existing state-of-the-art methods without requiring training.
Where Pith is reading between the lines
- The method shows that model confidence can serve as a lightweight signal for deciding where to invest additional compute during generation.
- The same confidence-driven forking logic could be tested on non-reasoning generation tasks that currently rely on expensive parallel sampling.
- Varying the number of forks or the confidence threshold at each point may allow further efficiency gains without changing the core procedure.
Load-bearing premise
Confidence scores computed along one seeding path can reliably identify forking points that improve or match the quality of final generations compared with uniform parallel sampling.
What would settle it
On the same three benchmarks and models, replace confidence-selected forking points with randomly chosen positions and check whether final answer accuracy falls below the levels reported for Fork-think.
Figures

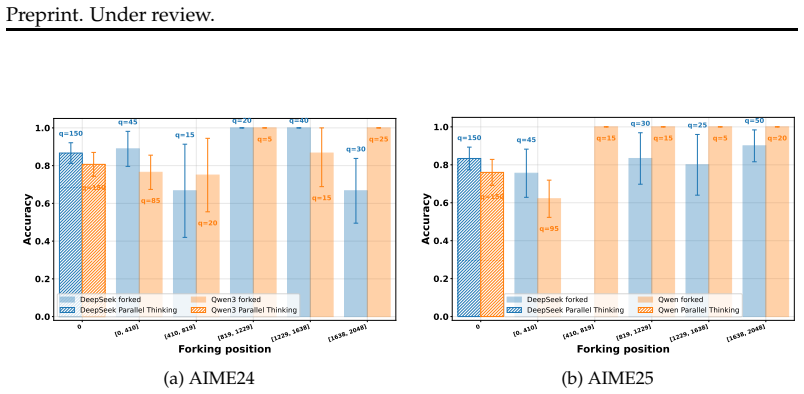
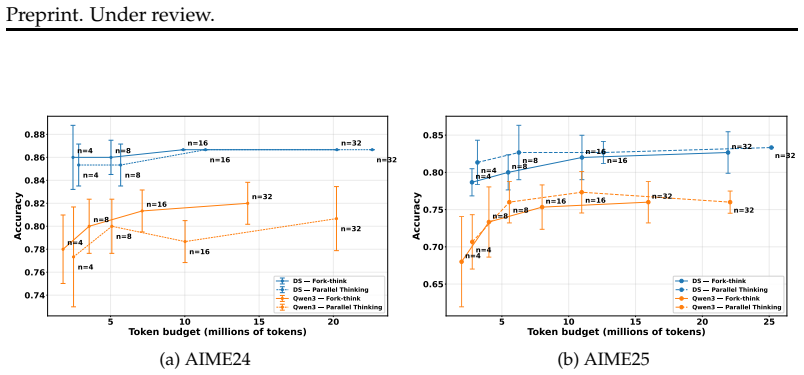
read the original abstract
Parallel thinking has enjoyed great success for boosting LLM performance on reasoning tasks without the need for any re-training. However, existing methods follow a think-first-then-decide paradigm, i.e., they first sample multiple reasoning paths, which inevitably leads to overgeneration, then prune or stop unnecessary paths to compensate. In contrast, decide-first-then-think, i.e., first identifying points that are likely to lead to desirable generations, has been underexplored so far. Following this paradigm, we propose Fork-think with confidence, that first identifies forking points using model confidence in a single seeding path, then triggers thinking, sampling multiple continuations and aggregating them for the final response. Our experiments across three models and three reasoning benchmarks show that Fork-think reduces the token consumption by up to 30% and run-time by up to 57%, while performing comparable to or better than parallel thinking. Our analysis reveals that Fork-think is able to identify forking points that are meaningful with respect to the downstream task and that sampling at later positions can lead to substantially better generations. Finally, we demonstrate how combining Fork-think with existing mechanisms such as early stopping and weighted voting can further boost the performance and perform comparably to existing state-of-the-art methods, without requiring any warm-up or offline training. Our results establish pre-determined forking as a promising research direction for efficient LLM reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Fork-think with confidence, a decide-first-then-think paradigm for LLM reasoning. It uses model confidence scores computed along a single seeding path to identify forking points, then samples multiple continuations from those points and aggregates them. Experiments across three models and three reasoning benchmarks report token reductions of up to 30% and runtime reductions of up to 57% while matching or exceeding standard parallel thinking; further gains are shown when combined with early stopping and weighted voting, without any warm-up or offline training. Analysis claims the selected points are meaningful for the downstream task and that later forking positions yield better generations.
Significance. If the efficiency claims hold under rigorous controls, the work would establish pre-determined forking as a viable direction for reducing overgeneration in parallel reasoning methods. The absence of training or warm-up phases and the compatibility with existing mechanisms are practical strengths. The approach could influence inference-time optimization research if the confidence heuristic is shown to be reliably superior to uniform sampling.
major comments (3)
- [§5 and §6] §5 (Experiments) and §6 (Analysis): The central efficiency claim depends on the confidence heuristic identifying forking points that are superior to uniform parallel sampling. No ablation is reported that compares confidence-selected points against random or uniform forking locations at matched positions; without this, it is impossible to isolate whether the reported 30% token and 57% runtime savings are caused by the heuristic or by any early forking.
- [§6] §6 (Analysis): The statement that forking points are 'meaningful with respect to the downstream task' rests on qualitative inspection. No quantitative correlation (e.g., Pearson coefficient or accuracy-at-fork metric) is provided between the per-token confidence scores and the correctness of the final aggregated answer; this leaves open the possibility that any observed gains are artifacts of post-hoc selection rather than a causal effect of the confidence signal.
- [§5] §5 (Experiments): Performance numbers are presented without reported variance across random seeds, statistical significance tests, or explicit description of data splits and prompt templates. Given that the method samples from a single seeding path, sensitivity to the choice of that path must be quantified to support the claim of consistent gains across three models and three benchmarks.
minor comments (2)
- [Abstract and §3] Abstract and §3: The term 'run-time' is used inconsistently with 'runtime' elsewhere; standardize notation.
- [§4] §4 (Method): The aggregation step after sampling multiple continuations is described at a high level; an explicit equation or pseudocode for the final aggregation (e.g., majority vote vs. weighted) would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We address each major comment point by point below, indicating where revisions will be made to strengthen the paper.
read point-by-point responses
-
Referee: [§5 and §6] The central efficiency claim depends on the confidence heuristic identifying forking points that are superior to uniform parallel sampling. No ablation is reported that compares confidence-selected points against random or uniform forking locations at matched positions; without this, it is impossible to isolate whether the reported 30% token and 57% runtime savings are caused by the heuristic or by any early forking.
Authors: We agree that an explicit ablation against uniform or random forking at matched positions would better isolate the heuristic's contribution. In the revised manuscript, we will add this ablation study, comparing our confidence-selected forking points to uniform random selection at the average forking positions observed in our experiments, using the same models and benchmarks. revision: yes
-
Referee: [§6] The statement that forking points are 'meaningful with respect to the downstream task' rests on qualitative inspection. No quantitative correlation (e.g., Pearson coefficient or accuracy-at-fork metric) is provided between the per-token confidence scores and the correctness of the final aggregated answer; this leaves open the possibility that any observed gains are artifacts of post-hoc selection rather than a causal effect of the confidence signal.
Authors: We acknowledge that quantitative metrics would provide stronger support for the analysis claims. We will revise Section 6 to include quantitative correlations, such as Pearson coefficients between per-token confidence at forking points and final answer accuracy, as well as an accuracy-at-fork metric aggregated over multiple runs. revision: yes
-
Referee: [§5] Performance numbers are presented without reported variance across random seeds, statistical significance tests, or explicit description of data splits and prompt templates. Given that the method samples from a single seeding path, sensitivity to the choice of that path must be quantified to support the claim of consistent gains across three models and three benchmarks.
Authors: We will update the experimental section to report standard deviations across multiple random seeds, include statistical significance tests for key comparisons, and explicitly describe the data splits and prompt templates. We will also add an analysis quantifying sensitivity to the seeding path by evaluating performance variations across different seeding paths. revision: yes
Circularity Check
No circularity: purely empirical method with independent experimental validation
full rationale
The paper proposes an empirical heuristic (model confidence along one seeding path to select forking points) and validates it via direct experiments on three models and three benchmarks, reporting token/runtime reductions and accuracy comparisons. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text; the central claims rest on observable performance metrics rather than any derivation that reduces to its own inputs by construction. The work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Attention is All you Need , url =
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, ukasz and Polosukhin, Illia , booktitle =. Attention is All you Need , url =
-
[2]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Scalable Best-of-N Selection for Large Language Models via Self-Certainty , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[3]
International Conference on Learning Representations , year=
An Explanation of In-context Learning as Implicit Bayesian Inference , author=. International Conference on Learning Representations , year=
-
[4]
Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles , year=
Efficient Memory Management for Large Language Model Serving with PagedAttention , author=. Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles , year=
-
[5]
2024 , eprint=
SGLang: Efficient Execution of Structured Language Model Programs , author=. 2024 , eprint=
2024
-
[6]
2024 , url=
Maxim Khanov and Jirayu Burapacheep and Yixuan Li , booktitle=. 2024 , url=
2024
-
[7]
Second Conference on Language Modeling , year=
Weight ensembling improves reasoning in language models , author=. Second Conference on Language Modeling , year=
-
[8]
Rewarding the Unlikely: Lifting GRPO Beyond Distribution Sharpening
He, Andre Wang and Fried, Daniel and Welleck, Sean. Rewarding the Unlikely: Lifting GRPO Beyond Distribution Sharpening. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.1298
-
[9]
The Effect of Sampling Temperature on Problem Solving in Large Language Models
Renze, Matthew. The Effect of Sampling Temperature on Problem Solving in Large Language Models. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.432
-
[10]
2025 , eprint=
Reasoning with Sampling: Your Base Model is Smarter Than You Think , author=. 2025 , eprint=
2025
-
[11]
Making Language Models Better Reasoners with Step-Aware Verifier
Li, Yifei and Lin, Zeqi and Zhang, Shizhuo and Fu, Qiang and Chen, Bei and Lou, Jian-Guang and Chen, Weizhu. Making Language Models Better Reasoners with Step-Aware Verifier. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.291
-
[12]
Outcome-based Exploration for
Yuda Song and Julia Kempe and R. Outcome-based Exploration for. NeurIPS 2025 Workshop: Second Workshop on Aligning Reinforcement Learning Experimentalists and Theorists , year=
2025
-
[13]
The Twelfth International Conference on Learning Representations , year=
Quantifying Language Models' Sensitivity to Spurious Features in Prompt Design or: How I learned to start worrying about prompt formatting , author=. The Twelfth International Conference on Learning Representations , year=
-
[14]
Advances in neural information processing systems , volume=
Tree of thoughts: Deliberate problem solving with large language models , author=. Advances in neural information processing systems , volume=
-
[15]
Knowledge and Information Systems , volume=
Recent advances in document summarization , author=. Knowledge and Information Systems , volume=. 2017 , publisher=
2017
-
[16]
Fan, Yongqi and Wang, Yating and Wang, Guandong and Jie, Zhai and Liu, Jingping and Ye, Qi and Ruan, Tong. M inos E val: Distinguishing Factoid and Non-Factoid for Tailored Open-Ended QA Evaluation with LLM s. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.548
-
[17]
Reasoning with Language Model is Planning with World Model
Hao, Shibo and Gu, Yi and Ma, Haodi and Hong, Joshua and Wang, Zhen and Wang, Daisy and Hu, Zhiting. Reasoning with Language Model is Planning with World Model. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.507
-
[18]
Proceedings of the 42nd International Conference on Machine Learning , pages =
Sample, Scrutinize and Scale: Effective Inference-Time Search by Scaling Verification , author =. Proceedings of the 42nd International Conference on Machine Learning , pages =. 2025 , editor =
2025
-
[19]
Wider or Deeper? Scaling
Yuichi Inoue and Kou Misaki and Yuki Imajuku and So Kuroki and Taishi Nakamura and Takuya Akiba , booktitle=. Wider or Deeper? Scaling. 2025 , url=
2025
-
[20]
Transactions on Machine Learning Research , issn=
From Decoding to Meta-Generation: Inference-time Algorithms for Large Language Models , author=. Transactions on Machine Learning Research , issn=. 2024 , url=
2024
-
[21]
Rewarding Progress: Scaling Automated Process Verifiers for
Amrith Setlur and Chirag Nagpal and Adam Fisch and Xinyang Geng and Jacob Eisenstein and Rishabh Agarwal and Alekh Agarwal and Jonathan Berant and Aviral Kumar , booktitle=. Rewarding Progress: Scaling Automated Process Verifiers for. 2025 , url=
2025
-
[22]
The Fourteenth International Conference on Learning Representations , year=
VeriCoT: Neuro-symbolic Chain-of-Thought Validation via Logical Consistency Checks , author=. The Fourteenth International Conference on Learning Representations , year=
-
[23]
Chain of Preference Optimization: Improving Chain-of-Thought Reasoning in LLMs , url =
Zhang, Xuan and Du, Chao and Pang, Tianyu and Liu, Qian and Gao, Wei and Lin, Min , booktitle =. Chain of Preference Optimization: Improving Chain-of-Thought Reasoning in LLMs , url =. doi:10.52202/079017-0011 , editor =
-
[24]
The Eleventh International Conference on Learning Representations , year=
Learning Math Reasoning from Self-Sampled Correct and Partially-Correct Solutions , author=. The Eleventh International Conference on Learning Representations , year=
-
[25]
Arian Hosseini and Xingdi Yuan and Nikolay Malkin and Aaron Courville and Alessandro Sordoni and Rishabh Agarwal , booktitle=. V-. 2024 , url=
2024
-
[26]
A Measure-Theoretic Characterization of Tight Language Models
Du, Li and Torroba Hennigen, Lucas and Pimentel, Tiago and Meister, Clara and Eisner, Jason and Cotterell, Ryan. A Measure-Theoretic Characterization of Tight Language Models. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.543
-
[27]
Nature , volume=
DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning , author=. Nature , volume=. 2025 , publisher=
2025
-
[28]
Zeng, Zhiyuan and Cheng, Qinyuan and Yin, Zhangyue and Zhou, Yunhua and Qiu, Xipeng. Revisiting the Test-Time Scaling of o1-like Models: Do they Truly Possess Test-Time Scaling Capabilities?. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.232
-
[29]
2024 , eprint=
OpenR: An Open Source Framework for Advanced Reasoning with Large Language Models , author=. 2024 , eprint=
2024
-
[30]
and Le, Quoc V
Wei, Jason and Wang, Xuezhi and Schuurmans, Dale and Bosma, Maarten and Ichter, Brian and Xia, Fei and Chi, Ed H. and Le, Quoc V. and Zhou, Denny , title =. Proceedings of the 36th International Conference on Neural Information Processing Systems , articleno =. 2022 , isbn =
2022
-
[31]
Proceedings of the 36th International Conference on Neural Information Processing Systems , articleno =
Kojima, Takeshi and Gu, Shixiang Shane and Reid, Machel and Matsuo, Yutaka and Iwasawa, Yusuke , title =. Proceedings of the 36th International Conference on Neural Information Processing Systems , articleno =. 2022 , isbn =
2022
-
[32]
2025 , eprint=
LLM Post-Training: A Deep Dive into Reasoning Large Language Models , author=. 2025 , eprint=
2025
-
[33]
Direct Preference Optimization: Your Language Model is Secretly a Reward Model , url =
Rafailov, Rafael and Sharma, Archit and Mitchell, Eric and Manning, Christopher D and Ermon, Stefano and Finn, Chelsea , booktitle =. Direct Preference Optimization: Your Language Model is Secretly a Reward Model , url =
-
[34]
and Dean, Jeff and Devlin, Jacob and Roberts, Adam and Zhou, Denny and Le, Quoc V
Chung, Hyung Won and Hou, Le and Longpre, Shayne and Zoph, Barret and Tai, Yi and Fedus, William and Li, Yunxuan and Wang, Xuezhi and Dehghani, Mostafa and Brahma, Siddhartha and Webson, Albert and Gu, Shixiang Shane and Dai, Zhuyun and Suzgun, Mirac and Chen, Xinyun and Chowdhery, Aakanksha and Castro-Ros, Alex and Pellat, Marie and Robinson, Kevin and V...
2024
-
[35]
The Eleventh International Conference on Learning Representations , year=
Self-Consistency Improves Chain of Thought Reasoning in Language Models , author=. The Eleventh International Conference on Learning Representations , year=
-
[36]
2024 , url=
Yubo Wang and Xueguang Ma and Ge Zhang and Yuansheng Ni and Abhranil Chandra and Shiguang Guo and Weiming Ren and Aaran Arulraj and Xuan He and Ziyan Jiang and Tianle Li and Max Ku and Kai Wang and Alex Zhuang and Rongqi Fan and Xiang Yue and Wenhu Chen , booktitle=. 2024 , url=
2024
-
[37]
Inference Scaling Laws: An Empirical Analysis of Compute-Optimal Inference for
Yangzhen Wu and Zhiqing Sun and Shanda Li and Sean Welleck and Yiming Yang , booktitle=. Inference Scaling Laws: An Empirical Analysis of Compute-Optimal Inference for. 2025 , url=
2025
-
[38]
2025 , url=
Yuxin Zuo and Kaiyan Zhang and Li Sheng and Shang Qu and Ganqu Cui and Xuekai Zhu and Haozhan Li and Yuchen Zhang and Xinwei Long and Ermo Hua and Biqing Qi and Youbang Sun and Zhiyuan Ma and Lifan Yuan and Ning Ding and Bowen Zhou , booktitle=. 2025 , url=
2025
-
[39]
arXiv preprint arXiv:2504.00294 , year=
Inference-time scaling for complex tasks: Where we stand and what lies ahead , author=. arXiv preprint arXiv:2504.00294 , year=
-
[40]
Adaptable Logical Control for Large Language Models , url =
Zhang, Honghua and Kung, Po-Nien and Yoshida, Masahiro and Van den Broeck, Guy and Peng, Nanyun , booktitle =. Adaptable Logical Control for Large Language Models , url =. doi:10.52202/079017-3670 , editor =
-
[41]
Nudging: Inference-time Alignment of LLM s via Guided Decoding
Fei, Yu and Razeghi, Yasaman and Singh, Sameer. Nudging: Inference-time Alignment of LLM s via Guided Decoding. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.623
-
[42]
Hierarchical Neural Story Generation
Fan, Angela and Lewis, Mike and Dauphin, Yann. Hierarchical Neural Story Generation. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2018. doi:10.18653/v1/P18-1082
-
[43]
International Conference on Learning Representations , year=
The Curious Case of Neural Text Degeneration , author=. International Conference on Learning Representations , year=
-
[44]
2024 , eprint=
Phi-4 Technical Report , author=. 2024 , eprint=
2024
-
[45]
The Fourteenth International Conference on Learning Representations , year=
Deep Think with Confidence , author=. The Fourteenth International Conference on Learning Representations , year=
-
[46]
Joshua Ong Jun Leang and Zheng Zhao and Aryo Pradipta Gema and Sohee Yang and Wai-Chung Kwan and Xuanli He and Wenda Li and Pasquale Minervini and Eleonora Giunchiglia and Shay B Cohen , year=. Pi
-
[47]
Beyond the 80/20 Rule: High-Entropy Minority Tokens Drive Effective Reinforcement Learning for
Shenzhi Wang and Le Yu and Chang Gao and Chujie Zheng and Shixuan Liu and Rui Lu and Kai Dang and Xiong-Hui Chen and Jianxin Yang and Zhenru Zhang and Yuqiong Liu and An Yang and Andrew Zhao and Yang Yue and Shiji Song and Bowen Yu and Gao Huang and Junyang Lin , booktitle=. Beyond the 80/20 Rule: High-Entropy Minority Tokens Drive Effective Reinforcement...
2025
-
[48]
Control the Temperature: Selective Sampling for Diverse and High-Quality
Sergey Troshin and Wafaa Mohammed and Yan Meng and Christof Monz and Antske Fokkens and Vlad Niculae , booktitle=. Control the Temperature: Selective Sampling for Diverse and High-Quality. 2025 , url=
2025
-
[49]
A Theoretical Study on Bridging Internal Probability and Self-Consistency for
Zhi Zhou and Yuhao Tan and Zenan Li and Yuan Yao and Lan-Zhe Guo and Yu-Feng Li and Xiaoxing Ma , booktitle=. A Theoretical Study on Bridging Internal Probability and Self-Consistency for. 2025 , url=
2025
-
[50]
Workshop on Scaling Environments for Agents , year=
Revisiting Uncertainty Estimation and Calibration of Large Language Models , author=. Workshop on Scaling Environments for Agents , year=
-
[51]
MathArena: Evaluating LLMs on Uncontaminated Math Competitions , author =
-
[52]
The Twelfth International Conference on Learning Representations , year=
Let's Verify Step by Step , author=. The Twelfth International Conference on Learning Representations , year=
-
[53]
NeurIPS , year=
Measuring Mathematical Problem Solving With the MATH Dataset , author=. NeurIPS , year=
-
[54]
2026 , url=
Daniel Scalena and Leonidas Zotos and Elisabetta Fersini and Malvina Nissim and Ahmet. 2026 , url=
2026
-
[55]
2026 , eprint=
From Efficiency to Adaptivity: A Deeper Look at Adaptive Reasoning in Large Language Models , author=. 2026 , eprint=
2026
-
[56]
The Twelfth International Conference on Learning Representations , year=
Escape Sky-high Cost: Early-stopping Self-Consistency for Multi-step Reasoning , author=. The Twelfth International Conference on Learning Representations , year=
-
[57]
2026 , eprint=
Hidden States as Early Signals: Step-level Trace Evaluation and Pruning for Efficient Test-Time Scaling , author=. 2026 , eprint=
2026
-
[58]
2025 , eprint=
DeepPrune: Parallel Scaling without Inter-trace Redundancy , author=. 2025 , eprint=
2025
-
[59]
Confidence Improves Self-Consistency in LLM s
Taubenfeld, Amir and Sheffer, Tom and Ofek, Eran and Feder, Amir and Goldstein, Ariel and Gekhman, Zorik and Yona, Gal. Confidence Improves Self-Consistency in LLM s. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.1030
-
[60]
Furniturewala, Shaz and Jaidka, Kokil and Sharma, Yashvardhan , editor =. Impact of. Proceedings of the 14th. 2024 , pages =. doi:10.18653/v1/2024.wassa-1.22 , abstract =
-
[61]
Optimized
Qin, Zongyue and Hu, Ziniu and He, Zifan and Prakriya, Neha and Cong, Jason and Sun, Yizhou , month = oct, year =. Optimized
-
[62]
Yang, Haoran and Cai, Deng and Li, Huayang and Bi, Wei and Lam, Wai and Shi, Shuming , editor =. A. Proceedings of the 2024. 2024 , pages =
2024
-
[63]
Meister, Clara and Pimentel, Tiago and Wiher, Gian and Cotterell, Ryan , year =. Locally. Transactions of the Association for Computational Linguistics , publisher =. doi:10.1162/tacl_a_00536 , abstract =
-
[64]
Yang, Kevin and Klein, Dan , year =. Proceedings of the 2021. doi:10.18653/v1/2021.naacl-main.276 , abstract =
-
[65]
Lu, Ximing and Welleck, Sean and West, Peter and Jiang, Liwei and Kasai, Jungo and Khashabi, Daniel and Le Bras, Ronan and Qin, Lianhui and Yu, Youngjae and Zellers, Rowan and Smith, Noah A. and Choi, Yejin , editor =. Proceedings of the 2022. 2022 , pages =. doi:10.18653/v1/2022.naacl-main.57 , abstract =
-
[66]
Deng, Haikang and Raffel, Colin , editor =. Reward-. Proceedings of the 2023. 2023 , pages =. doi:10.18653/v1/2023.emnlp-main.721 , abstract =
-
[67]
Inference-
Lu, Ximing and Brahman, Faeze and West, Peter and Jung, Jaehun and Chandu, Khyathi and Ravichander, Abhilasha and Ammanabrolu, Prithviraj and Jiang, Liwei and Ramnath, Sahana and Dziri, Nouha and Fisher, Jillian and Lin, Bill Yuchen and Hallinan, Skyler and Qin, Lianhui and Ren, Xiang and Welleck, Sean and Choi, Yejin , month = dec, year =. Inference-
-
[68]
Li, Xiang Lisa and Holtzman, Ari and Fried, Daniel and Liang, Percy and Eisner, Jason and Hashimoto, Tatsunori and Zettlemoyer, Luke and Lewis, Mike , year =. Contrastive. Proceedings of the 61st. doi:10.18653/v1/2023.acl-long.687 , language =
-
[69]
Decoding-time realignment of language models , volume =
Liu, Tianlin and Guo, Shangmin and Bianco, Leonardo and Calandriello, Daniele and Berthet, Quentin and Llinares, Felipe and Hoffmann, Jessica and Dixon, Lucas and Valko, Michal and Blondel, Mathieu , month = jul, year =. Decoding-time realignment of language models , volume =. Proceedings of the 41st
-
[70]
Chen, Ruizhe and Zhang, Xiaotian and Luo, Meng and Chai, Wenhao and Liu, Zuozhu , month = oct, year =
-
[71]
Huang, James Y. and Sengupta, Sailik and Bonadiman, Daniele and Lai, Yi-an and Gupta, Arshit and Pappas, Nikolaos and Mansour, Saab and Kirchhoff, Katrin and Roth, Dan , month = feb, year =. doi:10.48550/arXiv.2402.06147 , abstract =
-
[72]
doi:10.48550/arXiv.2504.18535 , abstract =
Weng, Gwen Yidou and Wang, Benjie and Broeck, Guy Van den , month = apr, year =. doi:10.48550/arXiv.2504.18535 , abstract =
-
[73]
Wu, Shiguang and Ren, Zhaochun and Xin, Xin and Yang, Jiyuan and Zhang, Mengqi and Chen, Zhumin and Rijke, Maarten de and Ren, Pengjie , month = apr, year =. Constrained. doi:10.1145/3726302.3729934 , abstract =
-
[74]
Ranked Voting based Self-Consistency of Large Language Models
Wang, Weiqin and Wang, Yile and Huang, Hui. Ranked Voting based Self-Consistency of Large Language Models. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.744
-
[75]
Shi, Chufan and Yang, Haoran and Cai, Deng and Zhang, Zhisong and Wang, Yifan and Yang, Yujiu and Lam, Wai , editor =. A. Proceedings of the 2024. 2024 , pages =. doi:10.18653/v1/2024.emnlp-main.489 , abstract =
-
[76]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[77]
Guo, Daya and Yang, Dejian and Zhang, Haowei and Song, Junxiao and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Zhang, Ruoyu and Ma, Shirong and Bi, Xiao and Zhang, Xiaokang and Yu, Xingkai and Wu, Yu and Wu, Z. F. and Gou, Zhibin and Shao, Zhihong and Li, Zhuoshu and Gao, Ziyi and Liu, Aixin and Xue, Bing and Wang, Bingxuan and Wu, Bochao and Feng, Bei ...
-
[78]
2025 , eprint=
gpt-oss-120b & gpt-oss-20b Model Card , author=. 2025 , eprint=
2025
-
[79]
Token-Budget-Aware LLM Reasoning
Han, Tingxu and Wang, Zhenting and Fang, Chunrong and Zhao, Shiyu and Ma, Shiqing and Chen, Zhenyu. Token-Budget-Aware LLM Reasoning. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.1274
-
[80]
Can C hat GPT Defend its Belief in Truth? Evaluating LLM Reasoning via Debate
Wang, Boshi and Yue, Xiang and Sun, Huan. Can C hat GPT Defend its Belief in Truth? Evaluating LLM Reasoning via Debate. Findings of the Association for Computational Linguistics: EMNLP 2023. 2023. doi:10.18653/v1/2023.findings-emnlp.795
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.