ChronoFlow-Policy: Unifying Past-Current-Future Interaction Flow in Visuomotor Policy Learning
Pith reviewed 2026-07-01 05:45 UTC · model grok-4.3
The pith
ChronoFlow-Policy learns one representation of past-current-future interaction dynamics to improve diffusion-based visuomotor policies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
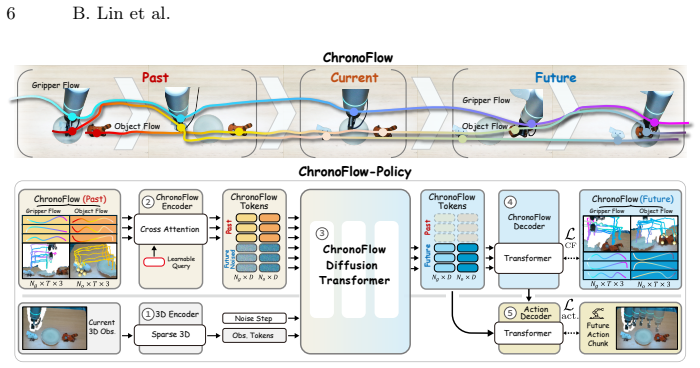
ChronoFlow is a temporally unified representation that captures past, current, and future interaction dynamics through sparse 3D keypoints of both objects and the gripper. ChronoFlow-Policy is a diffusion-based visuomotor policy that jointly learns ChronoFlow and action sequences through a co-training objective, producing policies that integrate historical context with future predictions rather than modeling them in isolation.
What carries the argument
ChronoFlow: a single representation of past-current-future interaction dynamics built from sparse 3D keypoints of objects and gripper, jointly trained with actions via co-training objective.
If this is right
- Policies gain robustness on long-horizon manipulation tasks by integrating historical context and future predictions in one model.
- Performance improves on non-Markovian scenarios where decisions depend on extended temporal context.
- The same representation and co-training approach yields gains across both simulated and real-world manipulation settings.
- Existing diffusion-policy baselines can be extended by adding the ChronoFlow component without changing the underlying diffusion architecture.
Where Pith is reading between the lines
- The ChronoFlow approach could be tested on policy architectures other than diffusion to check whether the benefit is tied to the diffusion formulation or to the unified representation itself.
- If the keypoint-based flow generalizes, similar sparse temporal representations might simplify policy learning in navigation or multi-agent settings where long-range timing matters.
- A direct test would measure whether removing the future-prediction part of ChronoFlow while keeping the past-current part erodes performance on the long-horizon tasks.
Load-bearing premise
Jointly learning the ChronoFlow representation and action sequences through the co-training objective produces a genuinely unified temporal model rather than simply adding capacity that could be achieved by other means.
What would settle it
A controlled comparison in which a diffusion policy with matched parameter count but without the ChronoFlow co-training objective achieves equal performance on the same 14 simulated and 5 real tasks.
Figures


read the original abstract
Visual signals play a crucial role in policy learning by enabling models to capture object motion and interaction dynamics. Just as humans reason about actions using both past experience and anticipated outcomes, effective policies should integrate past interactions with future predictions. However, existing visuomotor policies typically model either historical context or future dynamics in isolation, lacking a unified temporal representation of interaction dynamics. In this work, we introduce \textbf{ChronoFlow}, a temporally unified representation that captures \textbf{past, current, and future} interaction dynamics through sparse 3D keypoints of both objects and the gripper. Based on this representation, we propose \textbf{ChronoFlow-Policy}, a diffusion-based visuomotor policy that jointly learns ChronoFlow and action sequences through a co-training objective. Experiments on 14 simulated tasks and 5 real-world manipulation tasks demonstrate that ChronoFlow-Policy consistently outperforms strong diffusion-policy baselines and improves robustness in long-horizon and non-Markovian manipulation scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ChronoFlow, a sparse 3D keypoint representation that unifies past, current, and future interaction dynamics of objects and the gripper, and ChronoFlow-Policy, a diffusion-based visuomotor policy that jointly optimizes the ChronoFlow representation and action sequences via a co-training objective. It reports that this approach consistently outperforms strong diffusion-policy baselines on 14 simulated tasks and 5 real-world manipulation tasks while improving robustness in long-horizon and non-Markovian scenarios.
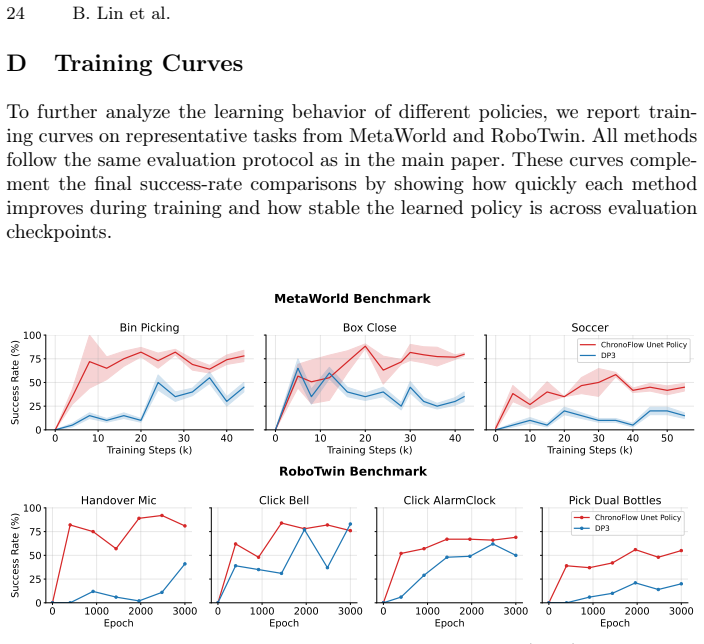
Significance. If the performance gains can be attributed to the unified temporal structure enforced by the co-training objective rather than generic increases in capacity, the work would provide a concrete mechanism for incorporating historical context and future prediction into visuomotor policies. The evaluation across 14 simulated and 5 real-world tasks supplies a reasonably broad testbed for long-horizon manipulation.
major comments (2)
- [Experiments] Experiments section: the central claim that ChronoFlow plus co-training produces a unified temporal model whose structure (rather than parameter count) explains robustness gains on long-horizon/non-Markovian tasks is not isolated by any capacity-matched control. No baseline is reported that augments a diffusion policy with an auxiliary head of identical size but lacking the past-current-future flow (e.g., static keypoint regression or independent future prediction).
- [Method] Method (co-training objective): the joint optimization is presented as enforcing unification, yet no ablation compares the full ChronoFlow co-training loss against an equivalent-capacity variant that predicts future keypoints independently of the past-current flow; without this, the attribution of gains to the claimed unification remains open.
minor comments (2)
- The abstract and introduction refer to 'strong diffusion-policy baselines' without naming the specific implementations or hyper-parameters used; these details should appear in the experimental setup for reproducibility.
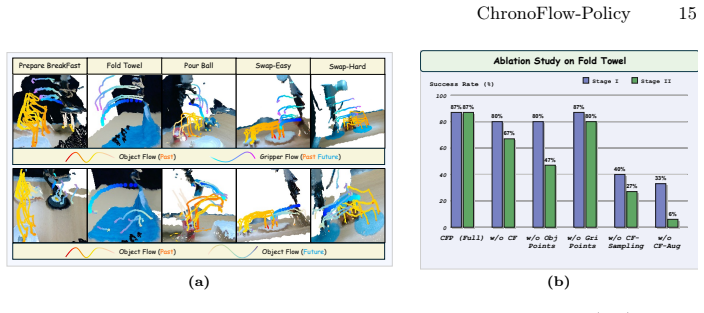
- Keypoint visualizations in the figures would benefit from explicit captions indicating which colors correspond to past, current, and future keypoints.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The points raised about isolating the contribution of the unified temporal structure are important for strengthening the attribution of gains. We address each major comment below and will incorporate the suggested controls and ablations into the revised manuscript.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the central claim that ChronoFlow plus co-training produces a unified temporal model whose structure (rather than parameter count) explains robustness gains on long-horizon/non-Markovian tasks is not isolated by any capacity-matched control. No baseline is reported that augments a diffusion policy with an auxiliary head of identical size but lacking the past-current-future flow (e.g., static keypoint regression or independent future prediction).
Authors: We agree that the current set of experiments lacks a capacity-matched control to isolate the effect of the unified past-current-future flow from potential capacity increases. In the revised manuscript, we will add a new baseline that augments the diffusion policy with an auxiliary head of comparable parameter count but without the temporal unification (e.g., static keypoint regression or independent future prediction). This will provide a clearer attribution of the robustness gains on long-horizon and non-Markovian tasks to the co-training objective. revision: yes
-
Referee: [Method] Method (co-training objective): the joint optimization is presented as enforcing unification, yet no ablation compares the full ChronoFlow co-training loss against an equivalent-capacity variant that predicts future keypoints independently of the past-current flow; without this, the attribution of gains to the claimed unification remains open.
Authors: We concur that an ablation against an equivalent-capacity variant predicting future keypoints independently would better support the claim that the joint optimization enforces unification. We will include this ablation in the revised version, training a model variant with matched capacity that decouples future keypoint prediction from the past-current flow and comparing it directly to the full ChronoFlow co-training loss. revision: yes
Circularity Check
No circularity: empirical method with no self-referential derivations
full rationale
The paper defines ChronoFlow as a sparse 3D keypoint representation of past-current-future dynamics and proposes a diffusion policy trained via co-training objective. No equations, uniqueness theorems, or predictions are presented that reduce by construction to fitted parameters or self-citations. Outperformance is claimed via experiments on 14 simulated and 5 real tasks against diffusion baselines; the unification is an explicit design choice, not a derived result that loops back to inputs. This is a standard non-circular empirical contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: European Conference on Computer Vision
Bharadhwaj, H., Mottaghi, R., Gupta, A., Tulsiani, S.: Track2act: Predicting point tracks from internet videos enables generalizable robot manipulation. In: European Conference on Computer Vision. pp. 306–324. Springer (2024)
2024
-
[2]
In: NeurIPS
Chen, B., Monso, D.M., Du, Y., Simchowitz, M., Tedrake, R., Sitzmann, V.: Diffu- sion forcing: Next-token prediction meets full-sequence diffusion. In: NeurIPS. pp. 24081–24125 (2024)
2024
-
[3]
History-Aware Visuomotor Policy Learning via Point Tracking.arXiv preprint arXiv:2509.17141, 2025
Chen, J., Fang, H., Wang, C., Wang, S., Lu, C.: History-aware visuomotor policy learning via point tracking. arXiv preprint arXiv:2509.17141 (2025)
-
[4]
Chen, T., Chen, Z., Chen, B., Cai, Z., Liu, Y., Li, Z., Liang, Q., Lin, X., Ge, Y., Gu, Z., et al.: Robotwin 2.0: A scalable data generator and benchmark with strong domain randomization for robust bimanual robotic manipulation. arXiv preprint arXiv:2506.18088 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
In: Robotics: Science and Systems (2022)
Eisner, B., Zhang, H., Held, D.: Flowbot3d: Learning 3d articulation flow to ma- nipulate articulated objects. In: Robotics: Science and Systems (2022)
2022
-
[6]
In: IEEE International Conference on Robotics and Automation
Fang,H.S.,Fang,H.,Tang,Z.,Liu,J.,Wang,C.,Wang,J.,Zhu,H.,Lu,C.:RH20T: A comprehensive robotic dataset for learning diverse skills in one-shot. In: IEEE International Conference on Robotics and Automation. pp. 653–660. IEEE (2024)
2024
-
[7]
In: International Conference on Machine Learning (2025)
Fang, H., Grotz, M., Pumacay, W., Wang, Y.R., Fox, D., Krishna, R., Duan, J.: Sam2act: Integrating visual foundation model with a memory architecture for robotic manipulation. In: International Conference on Machine Learning (2025)
2025
-
[8]
Gkanatsios, N., Xu, J., Bronars, M., Mousavian, A., Ke, T.W., Fragkiadaki, K.: 3d flowmatch actor: Unified 3d policy for single-and dual-arm manipulation. arXiv preprint arXiv:2508.11002 (2025)
-
[9]
In: IEEE International Conference on Robotics and Automation
Hsu, C.C., Wen, B., Xu, J., Narang, Y., Wang, X., Zhu, Y., Biswas, J., Birchfield, S.: Spot: Se(3) pose trajectory diffusion for object-centric manipulation. In: IEEE International Conference on Robotics and Automation. pp. 4853–4860 (2025)
2025
-
[10]
In: International Conference on Machine Learning
Hu, Y., Guo, Y., Wang, P., Chen, X., Wang, Y.J., Zhang, J., Sreenath, K., Lu, C., Chen, J.: Video prediction policy: A generalist robot policy with predictive visual representations. In: International Conference on Machine Learning. pp. 24328– 24346 (2025)
2025
-
[11]
Huang, Y ., Zhang, J., Zou, S., Liu, X., Hu, R., and Xu, K
Huang, W., Chao, Y.W., Mousavian, A., Liu, M.Y., Fox, D., Mo, K., Fei-Fei, L.: Pointworld: Scaling 3d world models for in-the-wild robotic manipulation. arXiv preprint arXiv:2601.03782 (2026)
-
[12]
In: European conference on computer vision
Huang, Z., Shi, X., Zhang, C., Wang, Q., Cheung, K.C., Qin, H., Dai, J., Li, H.: Flowformer: A transformer architecture for optical flow. In: European conference on computer vision. pp. 668–685. Springer (2022)
2022
-
[13]
In: International Conference on Machine Learning
Jin, Y., Sun, Z., Xu, K., Chen, L., Jiang, H., Huang, Q., Song, C., Liu, Y., Zhang, D., Song, Y., et al.: Video-lavit: unified video-language pre-training with decoupled visual-motional tokenization. In: International Conference on Machine Learning. pp. 22185–22209 (2024)
2024
-
[14]
arXiv preprint arXiv:2506.19816 (2025)
Li, H., Yang, S., Chen, Y., Chen, X., Yang, X., Tian, Y., Wang, H., Wang, T., Lin, D., Zhao, F., et al.: Cronusvla: Towards efficient and robust manipulation via multi-frame vision-language-action modeling. arXiv preprint arXiv:2506.19816 (2025)
-
[15]
Causal World Modeling for Robot Control
Li, L., Zhang, Q., Luo, Y., Yang, S., Wang, R., Han, F., Yu, M., Gao, Z., Xue, N., Zhu, X., Shen, Y., Xu, Y.: Causal world modeling for robot control. arXiv preprint arXiv:2601.21998 (2026) ChronoFlow-Policy 17
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[16]
arXiv preprint arXiv:2509.18676 (2025)
Noh, S., Nam, D., Kim, K., Lee, G., Yu, Y., Kang, R., Lee, K.: 3d flow diffusion policy: Visuomotor policy learning via generating flow in 3d space. arXiv preprint arXiv:2509.18676 (2025)
-
[17]
mimic-video: Video-Action Models for Generalizable Robot Control Beyond VLAs
Pai, J., Achenbach, L., Montesinos, V., Forrai, B., Mees, O., Nava, E.: mimic-video: Video-action models for generalizable robot control beyond vlas. arXiv preprint arXiv:2512.15692 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Peebles,W.,Xie,S.:Scalablediffusionmodelswithtransformers.In:Proceedingsof the IEEE/CVF international conference on computer vision. pp. 4195–4205 (2023)
2023
-
[19]
In: International Conference on Learning Representations (2025)
Ravi, N., Gabeur, V., Hu, Y.T., Hu, R., Ryali, C., Ma, T., Khedr, H., Rädle, R., Rolland, C., Gustafson, L., et al.: Sam 2: Segment anything in images and videos. In: International Conference on Learning Representations (2025)
2025
-
[20]
In: International Conference on Medical Image Computing and Computer-Assisted Intervention
Ronneberger, O., Fischer, P., Brox, T.: U-net: Convolutional networks for biomedi- cal image segmentation. In: International Conference on Medical Image Computing and Computer-Assisted Intervention. pp. 234–241. Springer (2015)
2015
-
[22]
MemoryVLA: Perceptual-Cognitive Memory in Vision-Language-Action Models for Robotic Manipulation
Shi, H., Xie, B., Liu, Y., Sun, L., Liu, F., Wang, T., Zhou, E., Fan, H., Zhang, X., Huang, G.: Memoryvla: Perceptual-cognitive memory in vision-language-action models for robotic manipulation. arXiv preprint arXiv:2508.19236 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Shi, X., Huang, Z., Li, D., Zhang, M., Cheung, K.C., See, S., Qin, H., Dai, J., Li, H.: Flowformer++: Masked cost volume autoencoding for pretraining optical flow estimation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 1599–1610 (2023)
2023
-
[24]
Freqpolicy: Efficient flow-based visuomotor policy via frequency consistency, 2025
Su, Y., Liu, N., Chen, D., Zhao, Z., Wu, K., Li, M., Xu, Z., Che, Z., Tang, J.: Freqpolicy: Efficient flow-based visuomotor policy via frequency consistency. arXiv preprint arXiv:2506.08822 (2025)
-
[25]
IEEE Robotics and Automation Letters 10(7), 7428–7435 (2025)
Su, Y., Zhan, X., Fang, H., Li, Y., Lu, C., Yang, L.: Motion before action: Diffusing object motion as manipulation condition. IEEE Robotics and Automation Letters 10(7), 7428–7435 (2025)
2025
-
[26]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Tang, X., Qiu, J., Xie, L., Tian, Y., Jiao, J., Ye, Q.: Adaptive keyframe sampling for long video understanding. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 29118–29128 (2025)
2025
-
[27]
Torne,M.,Pertsch,K.,Walke,H.,Vedder,K.,Nair,S.,Ichter,B.,Ren,A.Z.,Wang, H., Tang, J., Stachowicz, K., Dhabalia, K., Equi, M., Vuong, Q., Springenberg, J.T., Levine, S., Finn, C., Driess, D.: Mem: Multi-scale embodied memory for vision language action models (2026)
2026
-
[28]
In: CoRL (2025)
Torne, M., Tang, A., Liu, Y., Finn, C.: Learning long-context diffusion policies via past-token prediction. In: CoRL (2025)
2025
-
[29]
In: IEEE/RSJ International Conference on Intelligent Robots and Systems
Wang, C., Fang, H., Fang, H.S., Lu, C.: Rise: 3d perception makes real-world robot imitation simple and effective. In: IEEE/RSJ International Conference on Intelligent Robots and Systems. pp. 2870–2877 (2024)
2024
-
[30]
In: European Conference on Computer Vision (ECCV) (2026)
Wang, X., Wang, C., Xu, Y., Ye, M., Zhang, F., Tian, J., Zhan, X., Zhu, L., Lu, C., Yang, L.: LaMP: Learning vision-language-action policy with 3d scene flow as latent motion prior. In: European Conference on Computer Vision (ECCV) (2026)
2026
-
[31]
In: Robotics: Science and Systems (2024)
Wen, C., Lin, X., So, J.I.R., Chen, K., Dou, Q., Gao, Y., Abbeel, P.: Any-point trajectory modeling for policy learning. In: Robotics: Science and Systems (2024)
2024
-
[32]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Xiao, Y., Wang, J., Xue, N., Karaev, N., Makarov, Y., Kang, B., Zhu, X., Bao, H., Shen, Y., Zhou, X.: Spatialtrackerv2: Advancing 3d point tracking with explicit camera motion. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 6726–6737 (2025) 18 B. Lin et al
2025
-
[33]
In: Conference on Robot Learning
Xu, M., Xu, Z., Xu, Y., Chi, C., Wetzstein, G., Veloso, M., Song, S.: Flow as the cross-domain manipulation interface. In: Conference on Robot Learning. vol. 270, pp. 2475–2499. PMLR (2024)
2024
-
[34]
In: Conference on Language Modeling (2025)
Xu, M., Gao, M., Li, S., Lu, J., Gan, Z., Lai, Z., Cao, M., Kang, K., Yang, Y., Dehghan, A.: Slowfast-llava-1.5: A family of token-efficient video large language models for long-form video understanding. In: Conference on Language Modeling (2025)
2025
-
[35]
World Action Models are Zero-shot Policies
Ye, S., Ge, Y., Zheng, K., Gao, S., Yu, S., Kurian, G., Indupuru, S., Tan, Y.L., Zhu, C., Xiang, J., et al.: World action models are zero-shot policies. arXiv preprint arXiv:2602.15922 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[36]
In: International Conference on Learning Representations (2025)
Yu, S., Jin, C., Wang, H., Chen, Z., Jin, S., Zuo, Z., Xu, X., Sun, Z., Zhang, B., Wu, J., et al.: Frame-voyager: Learning to query frames for video large language models. In: International Conference on Learning Representations (2025)
2025
-
[37]
In: Conference on Robot Learning
Yu, T., Quillen, D., He, Z., Julian, R., Hausman, K., Finn, C., Levine, S.: Meta- world:Abenchmarkandevaluationformulti-taskandmetareinforcementlearning. In: Conference on Robot Learning. Proceedings of Machine Learning Research, vol. 100, pp. 1094–1100. PMLR (2019)
2019
-
[38]
In: Robotics: Science and Systems (2024)
Ze, Y., Zhang, G., Zhang, K., Hu, C., Wang, M., Xu, H.: 3d diffusion policy: Gen- eralizable visuomotor policy learning via simple 3d representations. In: Robotics: Science and Systems (2024)
2024
-
[39]
arXiv preprint arXiv:2504.14717 (2025)
Zhang, B., Ke, L., Harley, A.W., Fragkiadaki, K.: Tapip3d: Tracking any point in persistent 3d geometry. arXiv preprint arXiv:2504.14717 (2025)
-
[40]
In: CVPR (2026)
Zhang, C., Le Moing, G., Koppula, S., Rocco, I., Momeni, L., Xie, J., Sun, S., Sukthankar, R., Barral, J.K., Hadsell, R., Ghahramani, Z., Zisserman, A., Zhang, J., Sajjadi, M.S.M.: Efficiently reconstructing dynamic scenes one d4rt at a time. In: CVPR (2026)
2026
-
[41]
In: International Conference on Learning Represen- tations (2025)
Zheng, R., Liang, Y., Huang, S., Gao, J., Daumé III, H., Kolobov, A., Huang, F., Yang, J.: Tracevla: Visual trace prompting enhances spatial-temporal awareness for generalist robotic policies. In: International Conference on Learning Represen- tations (2025)
2025
-
[42]
Zhu, C., Yu, R., Feng, S., Burchfiel, B., Shah, P., Gupta, A.: Unified world models: Coupling video and action diffusion for pretraining on large robotic datasets. In: Proceedings of Robotics: Science and Systems (RSS) (2025) Appendix A ChronoFlow Implementation Details This section details the construction ofChronoFlow, including how gripper and object k...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.