Do Machines Struggle Where Humans Do? LLM and Human Comprehension of Obfuscated Code
Pith reviewed 2026-07-01 04:17 UTC · model grok-4.3
The pith
Reasoning-tuned LLMs align with human difficulty patterns on obfuscated code while instruction-tuned models do not.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
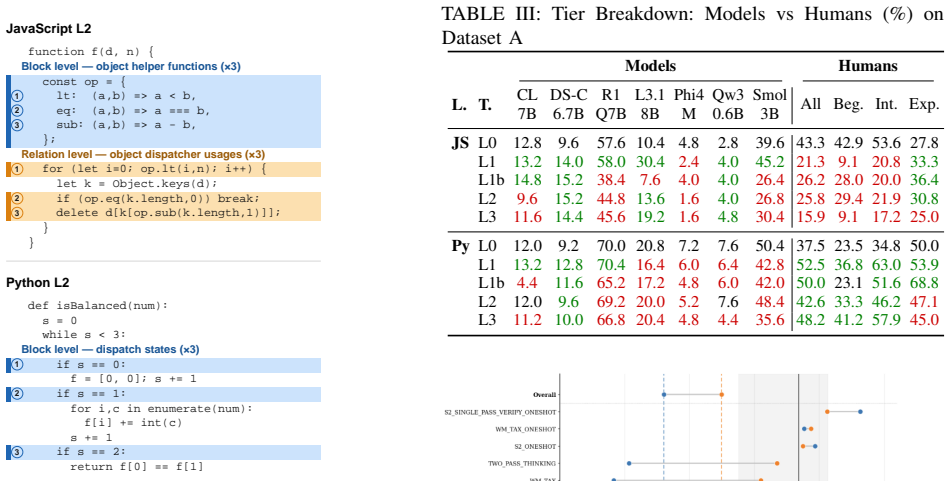
Reasoning-tuned models demonstrate significant alignment with human difficulty patterns across experience levels when comprehending obfuscated code, whereas instruction and coder-tuned models show near-zero correlation. Chain-of-Thought trace length tracks task difficulty across tasks. Performance under control-flow flattening degrades in proportion to state-space complexity, while adversarial identifier renaming disrupts comprehension through the interaction of semantic displacement and identifier-level interference.
What carries the argument
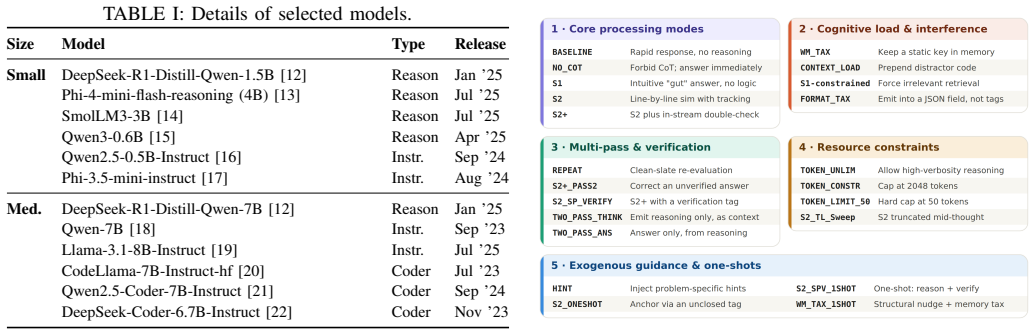
The Block Model, which localizes comprehension failures at the atom, block, relational, and macro levels of code and enables direct comparison to human data.
If this is right
- Reasoning-tuned models share human-like responses to different forms of code obfuscation.
- Instruction and coder-tuned models lack this alignment.
- Chain-of-Thought length serves as a measurable proxy for task difficulty in LLMs.
- Control-flow flattening affects performance in proportion to state-space complexity.
- Adversarial renaming disrupts comprehension through semantic displacement combined with identifier interference.
Where Pith is reading between the lines
- Training approach may influence human-like code understanding more than model size alone.
- Obfuscation design could be adjusted to exploit differences between model types.
- Similar comparisons on non-obfuscated or larger codebases could test whether the alignment generalizes beyond the studied tiers.
Load-bearing premise
The prior human study and the Block Model provide a valid and comparable baseline for measuring LLM comprehension failures against human ones.
What would settle it
A new experiment with the same obfuscation tasks that finds no correlation between reasoning-tuned model accuracy and human difficulty ratings across experience levels would falsify the alignment result.
Figures










read the original abstract
While code obfuscation impairs human code comprehension, it remains unclear if large language models share these failure modes. Building directly on a recent human study of program comprehension under code obfuscation, we evaluate whether large language models share the failure modes that obfuscation induces in human programmers. Evaluating several LLMs with five obfuscation tiers using the Block Model, we localize comprehension failures at the atom, block, relational, and macro levels. We find that reasoning-tuned models demonstrate significant alignment with human difficulty patterns across experience levels, whereas instruction and coder-tuned models show near-zero correlation. Chain-of-Thought trace length tracks task difficulty across tasks. Results indicate that performance under control-flow flattening degrades in proportion to state-space complexity, while adversarial identifier renaming disrupts comprehension through the interaction of semantic displacement and identifier-level interference. These findings suggest that reasoning-tuned LLMs approximate human sensitivity to code complexity more effectively than instruction-tuned variants.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates several LLMs on code comprehension tasks under five tiers of obfuscation, directly replicating tasks and localization levels (atom, block, relational, macro) from a prior human study via the Block Model. It reports that reasoning-tuned models show significant alignment with human difficulty patterns across experience levels, while instruction-tuned and coder-tuned models exhibit near-zero correlation. Additional findings include CoT trace length tracking task difficulty, performance degradation under control-flow flattening proportional to state-space complexity, and disruption from adversarial identifier renaming via semantic displacement and identifier interference.
Significance. If the empirical results hold, the work offers a direct, non-circular comparison of LLM and human failure modes on obfuscated code, highlighting that reasoning-tuned models better approximate human sensitivity to code complexity. This has potential implications for selecting models in code comprehension tasks and for understanding LLM limitations. The replication of the human study's Block Model localization provides a concrete, falsifiable basis for the alignment claims.
major comments (1)
- [Methods] Methods section: the abstract and method description supply no details on prompt engineering, statistical tests for correlations, sample sizes per condition, exact model versions, or controls for prompt sensitivity. Without these, it is impossible to verify whether the reported significant alignment for reasoning-tuned models (versus near-zero for others) is supported by the data, which is load-bearing for the central claim.
minor comments (1)
- [Abstract] The abstract mentions 'five obfuscation tiers' but does not list them explicitly; adding a brief enumeration would improve clarity for readers unfamiliar with the prior human study.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for greater methodological transparency. We agree that the current Methods section lacks critical details required to evaluate the central claims and will revise accordingly.
read point-by-point responses
-
Referee: [Methods] Methods section: the abstract and method description supply no details on prompt engineering, statistical tests for correlations, sample sizes per condition, exact model versions, or controls for prompt sensitivity. Without these, it is impossible to verify whether the reported significant alignment for reasoning-tuned models (versus near-zero for others) is supported by the data, which is load-bearing for the central claim.
Authors: We agree that these details are essential for reproducibility and verification of the alignment results. In the revised manuscript we will expand the Methods section to include: (1) the complete prompt templates and any system instructions used for each model and task; (2) the exact statistical procedures (correlation coefficient type, significance testing, and correction for multiple comparisons) together with the resulting coefficients and p-values; (3) the number of code snippets evaluated per obfuscation tier, localization level, and model; (4) precise model identifiers and versions (including any fine-tuning or API snapshot dates); and (5) any prompt-sensitivity controls or ablation runs performed. These additions will directly support the reported differences between reasoning-tuned and instruction-tuned models. revision: yes
Circularity Check
No significant circularity; empirical comparison to external human data
full rationale
The paper conducts a direct empirical evaluation of LLMs on obfuscated code tasks, localizing failures via the Block Model and computing correlations against results from a prior human study. No mathematical derivations, equations, fitted parameters, or predictions are present that could reduce to inputs by construction. The central claims (alignment for reasoning-tuned models, near-zero for others) follow from straightforward statistical comparison of model outputs to independent human data. Self-citation, if any, is limited to the baseline study and is not load-bearing for the LLM-specific findings, which are externally falsifiable. This matches the default expectation for non-circular empirical work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The Block Model accurately partitions comprehension failures into atom, block, relational, and macro levels for both humans and LLMs.
Reference graph
Works this paper leans on
-
[1]
The effect of code obfuscation on human program comprehension,
A. H. N. Nguyen, J. Le, I. L. Coronado, and T. N. Nguyen, “The effect of code obfuscation on human program comprehension,” 2026. [Online]. Available: https://arxiv.org/abs/2603.07668
-
[2]
C. Schulte, “Block model: an educational model of program comprehension as a tool for a scholarly approach to teaching,” in Proceedings of the Fourth International Workshop on Computing Education Research, ser. ICER ’08. New York, NY , USA: Association for Computing Machinery, 2008, p. 149–160. [Online]. Available: https://doi.org/10.1145/1404520.1404535
-
[3]
A taxonomy of obfuscating transformations,
C. Collberg, C. Thomborson, and D. Low, “A taxonomy of obfuscating transformations,” University of Auckland, Tech. Rep. 148, 07 1997. [Online]. Available: https://researchspace.auckland.ac.nz/handle/2292/ 3491
1997
-
[4]
Towards experimental evaluation of code obfuscation techniques,
M. Ceccato, M. Di Penta, J. Nagra, P. Falcarin, F. Ricca, M. Torchiano, and P. Tonella, “Towards experimental evaluation of code obfuscation techniques,” inProceedings of the 4th ACM Workshop on Quality of Protection, ser. QoP ’08. New York, NY , USA: Association for Computing Machinery, 2008, pp. 39–46. [Online]. Available: https://doi.org/10.1145/145636...
-
[5]
Obfuscating c++ programs via control flow flattening,
T. Laszlo and A. Kiss, “Obfuscating c++ programs via control flow flattening,” vol. 30, 06 2007
2007
-
[6]
The cost of thinking is similar between large reasoning models and humans,
A. G. de Varda, F. P. D’Elia, H. Kean, A. Lampinen, and E. Fedorenko, “The cost of thinking is similar between large reasoning models and humans,”Proceedings of the National Academy of Sciences, vol. 122, no. 47, p. e2520077122, 2025
2025
-
[7]
Codegeex: A pre-trained model for code generation with multilingual benchmarking on humaneval- x,
Q. Zheng, X. Xia, X. Zou, Y . Dong, S. Wang, Y . Xue, Z. Wang, L. Shen, A. Wang, Y . Li, T. Su, Z. Yang, and J. Tang, “Codegeex: A pre-trained model for code generation with multilingual benchmarking on humaneval- x,” inProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2023, pp. 5673–5684
2023
-
[8]
Cruxeval-x: A benchmark for multilingual code reasoning, understanding and execution,
R. Xu, J. Cao, Y . Lu, H. Lin, X. Han, B. He, S.-C. Cheung, and L. Sun, “Cruxeval-x: A benchmark for multilingual code reasoning, understanding and execution,” 2024. [Online]. Available: https://arxiv.org/abs/2408.13001
-
[9]
Leetcodedataset: A temporal dataset for robust evaluation and efficient training of code llms,
Y . Xia, W. Shen, Y . Wang, J. K. Liu, H. Sun, S. Wu, J. Hu, and X. Xu, “Leetcodedataset: A temporal dataset for robust evaluation and efficient training of code llms,” 2025. [Online]. Available: https://arxiv.org/abs/2504.14655
-
[10]
Obfuxtreme,
spyboy productions, “Obfuxtreme,” gitHub repository, last accessed September 24, 2025. [Online]. Available: https: //github.com/spyboy-productions/ObfuXtreme
2025
-
[11]
javascript-obfuscator,
javascript-obfuscator contributors, “javascript-obfuscator,” 2025, javaScript obfuscation tool, package version 4.1.1, last accessed October 17, 2025. [Online]. Available: https://github.com/javascript-obfuscator/ javascript-obfuscator
2025
-
[12]
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning,
DeepSeek-AI, “Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning,” 2025
2025
-
[13]
Decoder- hybrid-decoder architecture for efficient reasoning with long generation,
L. Ren, C. Chen, H. Xu, Y . J. Kim, A. Atkinsonet al., “Decoder- hybrid-decoder architecture for efficient reasoning with long generation,” 2025
2025
-
[14]
SmolLM3: smol, multilingual, long-context reasoner,
E. Bakouch, L. Ben Allal, A. Lozhkov, N. Tazi, L. Tunstall, C. M. Patiño, E. Beeching, A. Roucher, A. J. Reedi, Q. Gallouédec, K. Rasul, N. Habib, C. Fourrier, H. Kydlicek, G. Penedo, H. Larcher, M. Morlon, V . Srivastav, J. Lochner, X.-S. Nguyen, C. Raffel, L. von Werra, and T. Wolf, “SmolLM3: smol, multilingual, long-context reasoner,” https: //huggingf...
2025
-
[15]
Qwen3 technical report,
Q. Team, “Qwen3 technical report,” 2025
2025
-
[16]
Qwen2 technical report,
A. Yanget al., “Qwen2 technical report,” 2024
2024
-
[17]
Phi-3 technical report: A highly capable language model locally on your phone,
M. Abdinet al., “Phi-3 technical report: A highly capable language model locally on your phone,” 2024
2024
-
[18]
Qwen technical report,
J. Baiet al., “Qwen technical report,” 2023
2023
-
[19]
A. Grattafiori, A. Dubey, A. Jauhriet al., “The Llama 3 herd of models,” arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Code Llama: Open Foundation Models for Code
B. R. et al., “Code Llama: Open foundation models for code,”arXiv preprint arXiv:2308.12950, 2024, [Online]. Available: https://arxiv.org/ abs/2308.12950
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Qwen2.5-Coder Technical Report
B. H. et al., “Qwen2.5-coder technical report,”arXiv preprint arXiv:2409.12186, 2024, [Online]. Available: https://arxiv.org/abs/2409. 12186
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
DeepSeek-Coder: When the Large Language Model Meets Programming -- The Rise of Code Intelligence
D. G. et al., “DeepSeek-Coder: When the large language model meets programming – the rise of code intelligence,”arXiv preprint arXiv:2401.14196, 2024, [Online]. Available: https://arxiv.org/abs/2401. 14196
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Do machines struggle where humans do? llm and human comprehension of obfuscated code,
Anonymous, “Do machines struggle where humans do? llm and human comprehension of obfuscated code,” 2026. [Online]. Available: https://doi.org/10.5281/zenodo.19337381
-
[24]
Codexembed: A generalist embedding model family for multiligual and multi-task code retrieval,
Y . Liu, R. Meng, S. Jot, S. Savarese, C. Xiong, Y . Zhou, and S. Yavuz, “Codexembed: A generalist embedding model family for multiligual and multi-task code retrieval,” 2024. [Online]. Available: https://arxiv.org/abs/2411.12644
-
[25]
Unsupervised quality estimation for neural machine translation,
M. Fomicheva, S. Sun, L. Yankovskaya, F. Blain, F. Guzmán, M. Fishel, N. Aletras, V . Chaudhary, and L. Specia, “Unsupervised quality estimation for neural machine translation,”Transactions of the Association for Computational Linguistics, vol. 8, pp. 539–555, 2020. [Online]. Available: https://aclanthology.org/2020.tacl-1.35/
2020
-
[26]
Looking for a needle in a haystack: A comprehensive study of hallucinations in neural machine translation,
N. M. Guerreiro, E. V oita, and A. Martins, “Looking for a needle in a haystack: A comprehensive study of hallucinations in neural machine translation,” inProceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, A. Vlachos and I. Augenstein, Eds. Dubrovnik, Croatia: Association for Computational Linguist...
2023
-
[27]
Scalable best-of-n selection for large language models via self-certainty,
Z. Kang, X. Zhao, and D. Song, “Scalable best-of-n selection for large language models via self-certainty,” inThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. [Online]. Available: https://openreview.net/forum?id=29FRqmVQK8
2026
-
[28]
Adversarial examples for models of code,
N. Yefet, U. Alon, and E. Yahav, “Adversarial examples for models of code,”Proc. ACM Program. Lang., vol. 4, no. OOPSLA, Nov. 2020. [Online]. Available: https://doi.org/10.1145/3428230
-
[29]
Idbench: Evaluating semantic representations of identifier names in source code,
Y . Wainakh, M. Rauf, and M. Pradel, “Idbench: Evaluating semantic representations of identifier names in source code,” inProceedings of the 43rd International Conference on Software Engineering, ser. ICSE ’21. IEEE Press, 2021, p. 562–573. [Online]. Available: https://doi.org/10.1109/ICSE43902.2021.00059
-
[30]
Protecting software through obfuscation: Can it keep pace with progress in code analysis?
S. Schrittwieser, S. Katzenbeisser, J. Kinder, G. Merzdovnik, and E. Weippl, “Protecting software through obfuscation: Can it keep pace with progress in code analysis?”ACM Comput. Surv., vol. 49, no. 1, Apr. 2016. [Online]. Available: https://doi.org/10.1145/2886012
-
[31]
Predicting the resilience of obfuscated code against symbolic execution attacks via machine learning,
S. Banescu, C. Collberg, and A. Pretschner, “Predicting the resilience of obfuscated code against symbolic execution attacks via machine learning,” in26th USENIX Security Symposium (USENIX Security 17). Vancouver, BC: USENIX Association, Aug. 2017, pp. 661–678. [Online]. Available: https://www.usenix.org/conference/usenixsecurity17/ technical-sessions/pre...
2017
-
[32]
M. Ceccato, M. Penta, P. Falcarin, F. Ricca, M. Torchiano, and P. Tonella, “A family of experiments to assess the effectiveness and efficiency of source code obfuscation techniques,”Empirical Softw. Engg., vol. 19, no. 4, p. 1040–1074, Aug. 2014. [Online]. Available: https://doi.org/10.1007/s10664-013-9248-x
-
[33]
Understanding understanding source code with functional magnetic resonance imaging,
J. Siegmund, C. Kästner, S. Apel, C. Parnin, A. Bethmann, T. Leich, G. Saake, and A. Brechmann, “Understanding understanding source code with functional magnetic resonance imaging,” inProceedings of the 36th International Conference on Software Engineering, ser. ICSE 2014. New York, NY , USA: Association for Computing Machinery, 2014, p. 378–389. [Online]...
-
[34]
Measuring neural efficiency of program comprehension,
J. Siegmund, N. Peitek, C. Parnin, S. Apel, J. Hofmeister, C. Kästner, A. Begel, A. Bethmann, and A. Brechmann, “Measuring neural efficiency of program comprehension,” inProceedings of the 2017 11th Joint Meeting on Foundations of Software Engineering, ser. ESEC/FSE 2017. New York, NY , USA: Association for Computing Machinery, 2017, p. 140–150. [Online]....
-
[35]
What’s in a name? a study of identifiers,
D. Lawrie, C. Morrell, H. Feild, and D. Binkley, “What’s in a name? a study of identifiers,” in14th IEEE International Conference on Program Comprehension (ICPC’06), 2006, pp. 3–12
2006
-
[36]
The impact of identifier style on effort and comprehension,
D. Binkley, M. Davis, D. Lawrie, J. Maletic, C. Morrell, and B. Sharif, “The impact of identifier style on effort and comprehension,”Empirical Software Engineering, vol. 18, 04 2013
2013
-
[37]
Chain-of-thought prompting elicits reasoning in large language models,
J. Wei, X. Wang, D. Schuurmans, M. Bosma, B. Ichter, F. Xia, E. H. Chi, Q. V . Le, and D. Zhou, “Chain-of-thought prompting elicits reasoning in large language models,” inProceedings of the 36th International Conference on Neural Information Processing Systems, ser. NIPS ’22. Red Hook, NY , USA: Curran Associates Inc., 2022
2022
-
[38]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
X. Wang, J. Wei, D. Schuurmans, Q. Le, E. H. Chi, S. Narang, A. Chowdhery, and D. Zhou, “Self-consistency improves chain of thought reasoning in language models,” inInternational Conference on Learning Representations (ICLR), 2023. [Online]. Available: https://arxiv.org/abs/2203.11171
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[39]
Large language models are zero-shot reasoners,
T. Kojima, S. S. Gu, M. Reid, Y . Matsuo, and Y . Iwasawa, “Large language models are zero-shot reasoners,” inProceedings of the 36th International Conference on Neural Information Processing Systems, ser. NIPS ’22. Red Hook, NY , USA: Curran Associates Inc., 2022
2022
-
[40]
A closer look at different difficulty levels code generation abilities of chatgpt,
D. Yan, Z. Gao, and Z. Liu, “A closer look at different difficulty levels code generation abilities of chatgpt,” inProceedings of the 38th IEEE/ACM International Conference on Automated Software Engineering, ser. ASE ’23. IEEE Press, 2024, p. 1887–1898. [Online]. Available: https://doi.org/10.1109/ASE56229.2023.00096
-
[41]
M. Turpin, J. Michael, E. Perez, and S. R. Bowman, “Language models don’t always say what they think: Unfaithful explanations in chain-of-thought prompting,” 2023. [Online]. Available: https: //arxiv.org/abs/2305.04388
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
Measuring Faithfulness in Chain-of-Thought Reasoning
T. Lanham, A. Chen, A. Radhakrishnan, B. Steiner, C. Denison, D. Hernandez, D. Li, E. Durmus, E. Hubinger, J. Kernion, K. Lukoši ¯ut˙e, K. Nguyen, N. Cheng, N. Joseph, N. Schiefer, O. Rausch, R. Larson, S. McCandlish, S. Kundu, S. Kadavath, S. Yang, T. Henighan, T. Maxwell, T. Telleen-Lawton, T. Hume, Z. Hatfield-Dodds, J. Kaplan, J. Brauner, S. R. Bowman...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[43]
How do humans and llms process confusing code?
Y . Abdelsalam, N. Peitek, A.-M. Maurer, M. Toneva, and S. Apel, “How do humans and llms process confusing code?” 2025. [Online]. Available: https://arxiv.org/abs/2508.18547
-
[44]
Towards modeling human attention from eye movements for neural source code summarization,
A. Bansal, B. Sharif, and C. McMillan, “Towards modeling human attention from eye movements for neural source code summarization,”Proceedings of the ACM on Human-Computer Interaction, vol. 7, no. ETRA, pp. 1–19, May 2023. [Online]. Available: http://dx.doi.org/10.1145/3591136
-
[45]
Eyetrans: Merging human and machine attention for neural code summarization,
Y . Zhang, J. Li, Z. Karas, A. Bansal, T. J.-J. Li, C. McMillan, K. Leach, and Y . Huang, “Eyetrans: Merging human and machine attention for neural code summarization,”Proc. ACM Softw. Eng., vol. 1, no. FSE, Jul. 2024. [Online]. Available: https://doi.org/10.1145/3643732
-
[46]
Enhancing code llm training with programmer attention,
Y . Zhang, C. Huang, Z. Karas, T. D. Nguyen, K. Leach, and Y . Huang, “Enhancing code llm training with programmer attention,” inProceedings of the 33rd ACM International Conference on the Foundations of Software Engineering, ser. FSE Companion ’25. ACM, Jun. 2025, pp. 616–620. [Online]. Available: http://dx.doi.org/10.1145/3696630.3728510
-
[47]
Thinking like a developer? comparing the attention of humans with neural models of code,
M. Paltenghi and M. Pradel, “Thinking like a developer? comparing the attention of humans with neural models of code,” in2021 36th IEEE/ACM International Conference on Automated Software Engineering (ASE). IEEE, Nov. 2021, pp. 867–879. [Online]. Available: http://dx.doi.org/10.1109/ASE51524.2021.9678712
-
[48]
Empirical studies of programming knowledge,
E. Soloway and K. Ehrlich, “Empirical studies of programming knowledge,”IEEE Trans. Softw. Eng., vol. 10, no. 5, p. 595–609, Sep
-
[49]
Available: https://doi.org/10.1109/TSE.1984.5010283
[Online]. Available: https://doi.org/10.1109/TSE.1984.5010283
-
[50]
Mental representations of programs by novices and experts,
V . Fix, S. Wiedenbeck, and J. Scholtz, “Mental representations of programs by novices and experts,” inProceedings of the INTERACT ’93 and CHI ’93 Conference on Human Factors in Computing Systems, 1993, pp. 74–79
1993
-
[51]
Stimulus structures and mental representations in expert comprehension of computer programs,
N. Pennington, “Stimulus structures and mental representations in expert comprehension of computer programs,”Cognitive Psychology, vol. 19, no. 3, pp. 295–341, 1987. [Online]. Available: https: //www.sciencedirect.com/science/article/pii/0010028587900077
-
[52]
An exploratory study of program comprehension strategies of procedural and object- oriented programmers,
C. L. CORRITORE and S. WIEDENBECK, “An exploratory study of program comprehension strategies of procedural and object- oriented programmers,”International Journal of Human-Computer Studies, vol. 54, no. 1, pp. 1–23, 2001. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S1071581900904233
2001
-
[53]
Suggesting accurate method and class names,
M. Allamanis, E. T. Barr, C. Bird, and C. Sutton, “Suggesting accurate method and class names,” inProceedings of the 2015 10th Joint Meeting on Foundations of Software Engineering, ser. ESEC/FSE 2015. New York, NY , USA: Association for Computing Machinery, 2015, p. 38–49. [Online]. Available: https://doi.org/10.1145/2786805.2786849
-
[54]
Learning to Represent Programs with Graphs
M. Allamanis, M. Brockschmidt, and M. Khademi, “Learning to represent programs with graphs,” 2018. [Online]. Available: https://arxiv.org/abs/1711.00740
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[55]
Generating adversarial examples for holding robustness of source code processing models,
H. Zhang, Z. Li, G. Li, L. Ma, Y . Liu, and Z. Jin, “Generating adversarial examples for holding robustness of source code processing models,”Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, no. 01, pp. 1169–1176, Apr. 2020. [Online]. Available: https://ojs.aaai.org/index.php/AAAI/article/view/5469
2020
-
[56]
Semantic robustness of models of source code,
J. Henkel, G. Ramakrishnan, Z. Wang, A. Albarghouthi, S. Jha, and T. Reps, “Semantic robustness of models of source code,” in2022 IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER), 2022, pp. 526–537
2022
-
[57]
On the generalizability of neural program models with respect to semantic-preserving program transformations,
M. R. I. Rabin, N. D. Bui, K. Wang, Y . Yu, L. Jiang, and M. A. Alipour, “On the generalizability of neural program models with respect to semantic-preserving program transformations,”Information and Software Technology, vol. 135, p. 106552, 2021. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S0950584921000379
2021
-
[58]
The code barrier: What llms actually understand?
S. L. Nikiema, J. Samhi, A. K. Kaboré, J. Klein, and T. F. Bissyandé, “The code barrier: What llms actually understand?” 2025. [Online]. Available: https://arxiv.org/abs/2504.10557
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.