Geometry-Preserving Orthonormal Initialization for Low-Rank Adaptation in RLVR
Pith reviewed 2026-07-01 06:42 UTC · model grok-4.3
The pith
Orthonormal initialization of LoRA matrices minimizes their gap to full fine-tuning outcomes under RLVR.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
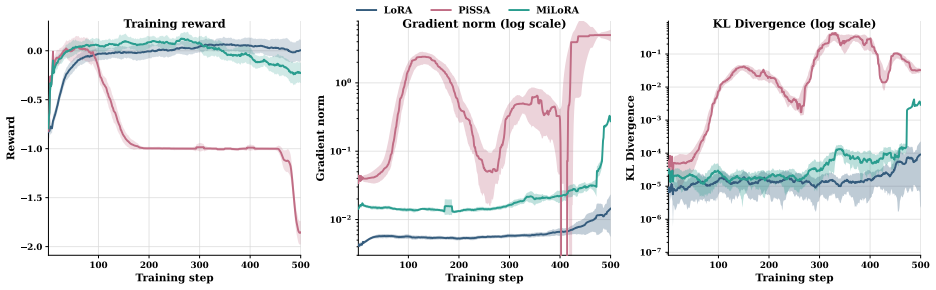
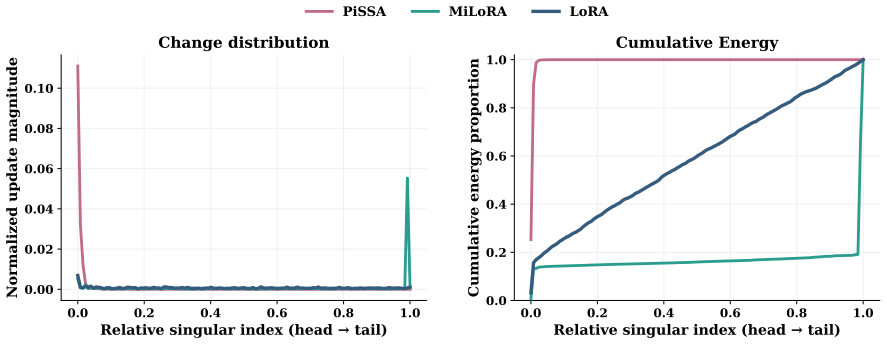
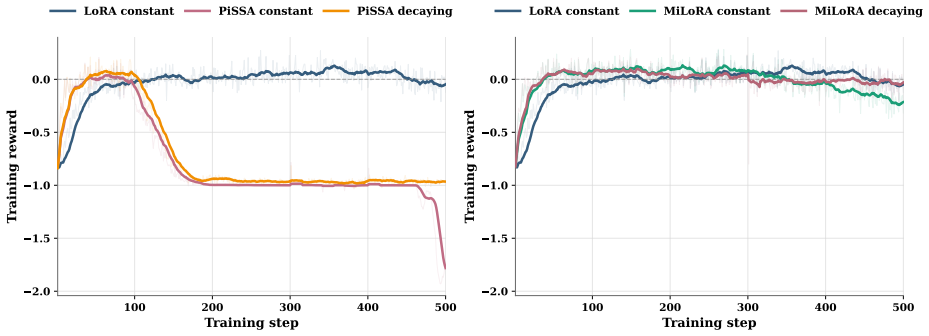
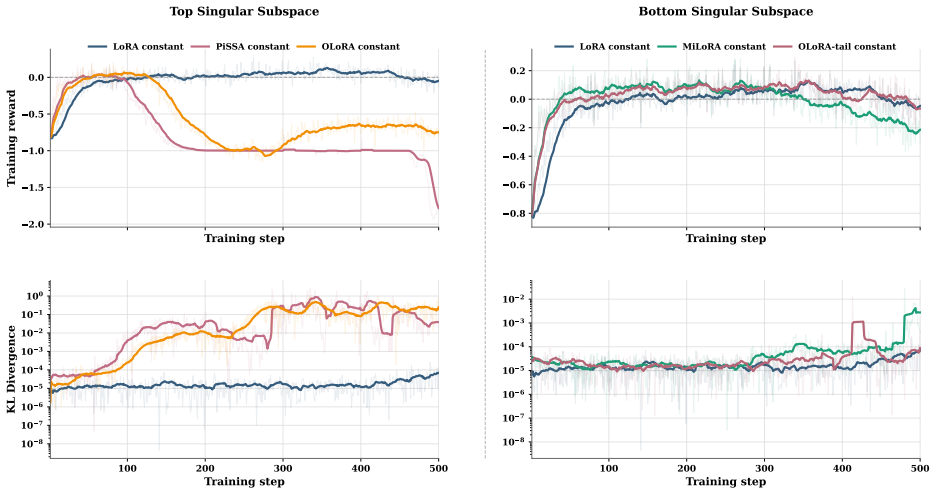
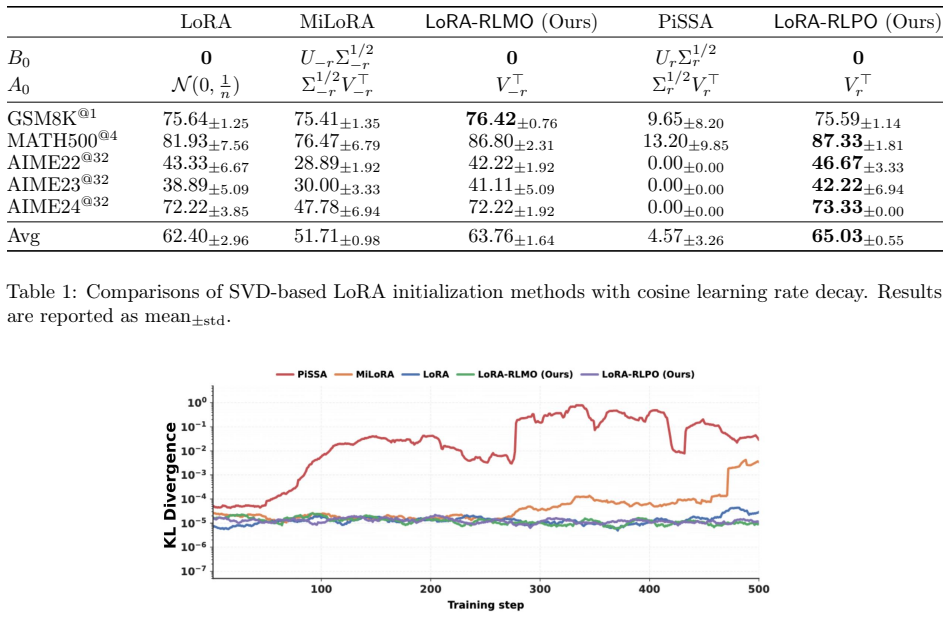
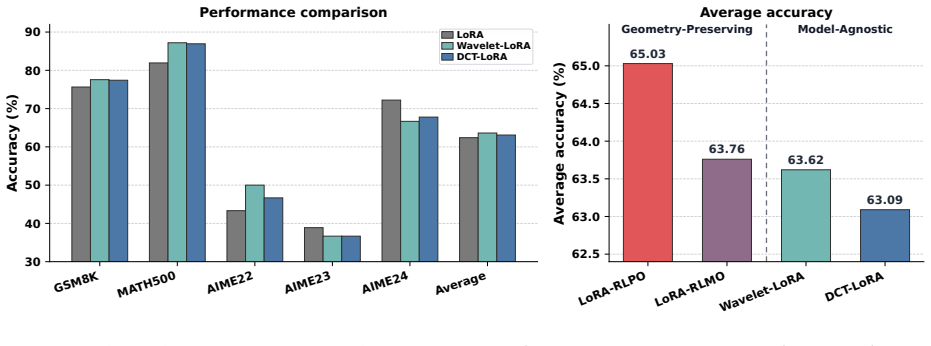
Orthonormal initialization achieves the minimal gap between the outcome of low-rank adaptation and that of full fine-tuning in the RLVR setting; new variants built on this principle stabilize training and raise accuracy on mathematical reasoning benchmarks, while the same analysis accounts for why PiSSA and MiLoRA can degrade under RLVR.
What carries the argument
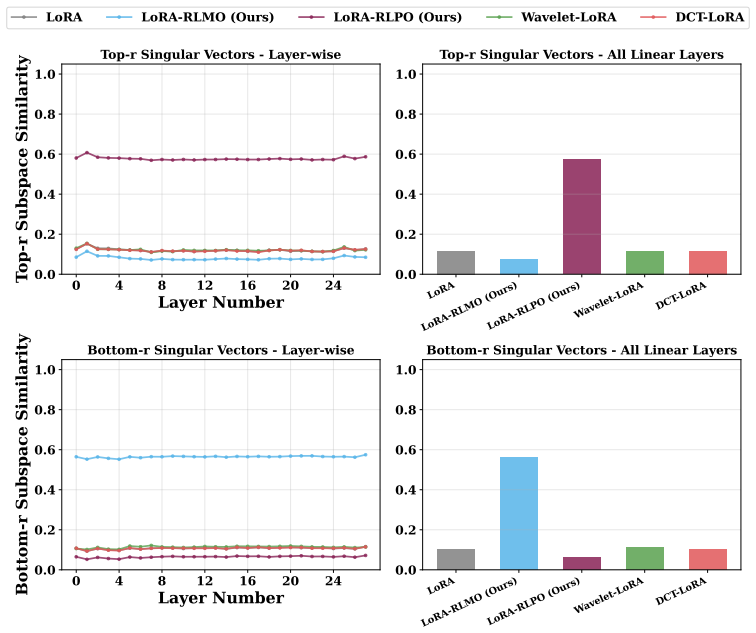
Geometry-preserving orthonormal initialization of the low-rank update matrices, which keeps their column and row spaces aligned so that the adaptation stays closest to a full-parameter update.
If this is right
- RLVR runs using LoRA become more stable when the low-rank matrices start with orthonormal bases.
- Performance on mathematical reasoning tasks improves relative to random or SVD-based initializations.
- The same geometric analysis explains the training failures of PiSSA and MiLoRA specifically under RLVR dynamics.
- A single initialization principle now covers both SFT and RLVR regimes for low-rank adaptation.
Where Pith is reading between the lines
- The same orthonormal principle could be tested in other reinforcement-learning fine-tuning settings that use verifiable but non-mathematical rewards.
- If the gap metric proves predictive, it could serve as a cheap diagnostic before running full RLVR training.
- The analysis may extend to other parameter-efficient methods whose updates are constrained to low-dimensional subspaces.
Load-bearing premise
The difference between LoRA and full fine-tuning is the main factor that determines whether RLVR training stays stable and reaches high performance.
What would settle it
Measure the parameter-space or output-space distance between a LoRA model trained with orthonormal initialization and the corresponding full fine-tuned model on the same RLVR run; check whether this distance is smaller than for standard or PiSSA-style initialization and whether the smaller distance predicts higher final benchmark scores.
Figures


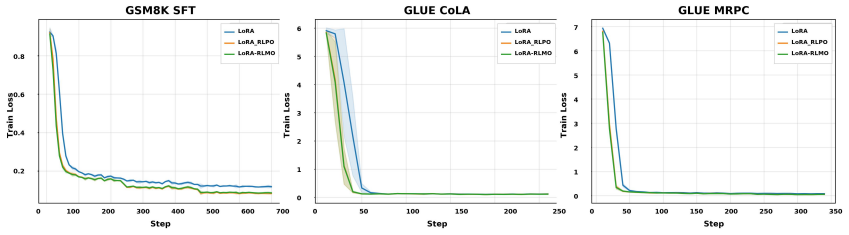
read the original abstract
Low-rank adaptation (LoRA) and its variants enable parameter-efficient fine-tuning of large language models under the supervised fine-tuning (SFT) paradigm. However, their efficacy and behavior under Reinforcement learning with verifiable rewards (RLVR) are less well understood. In particular, two structurally initialized LoRA variants, PiSSA and MiLoRA, which outperform standard LoRA under SFT, can underperform standard LoRA under RLVR and may even exhibit training instability. These observations suggest that how to initialize the low-rank matrices in RLVR remains unclear. In this work, we develop a theoretical analysis of LoRA in RLVR, showing that orthonormal initialization achieves the minimal gap between LoRA outcome and that of full fine-tuning. Guided by this insight, we propose geometry-preserving orthonormal initialization for low-rank adaptation in RLVR, leading to two new variants, RLPO and RLMO. Experiments on mathematical reasoning benchmarks show that the proposed orthonormal initialization stabilizes RLVR training and outperforms standard LoRA, contrasting with PiSSA and MiLoRA. Finally, our unified analysis for LoRA initialization also explains why PiSSA and MiLoRA can underperform in RLVR, which may be of independent interest. Code and checkpoints are publicly available at https://github.com/Richard-ZZZ/geometry-preserving-orthonormal-init-rlvr.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops a theoretical analysis of LoRA under RLVR showing that orthonormal initialization minimizes the gap to full fine-tuning outcomes. Guided by this, it proposes RLPO and RLMO variants using geometry-preserving orthonormal initialization. Experiments on mathematical reasoning benchmarks demonstrate that these stabilize RLVR training and outperform standard LoRA (in contrast to PiSSA and MiLoRA), while the unified analysis explains the underperformance of the latter two under RLVR. Code and checkpoints are released publicly.
Significance. If the central result holds, the work supplies a principled initialization strategy for parameter-efficient RL fine-tuning of LLMs, addressing a practical gap between SFT and RLVR behavior. The public code release and the unified explanatory analysis for multiple initializations are explicit strengths that aid reproducibility and broader utility.
major comments (2)
- [§4] §4 (theoretical analysis): the derivation establishes that orthonormal initialization minimizes the LoRA–full-fine-tuning gap, yet the manuscript does not state the regime (e.g., reward variance, policy-update scale, or LoRA rank relative to gradient noise) under which this gap is the dominant factor controlling RLVR stability and performance. This assumption is load-bearing for interpreting both the theoretical claim and the experimental superiority.
- [§5] §5 (experiments): the comparisons of RLPO/RLMO against PiSSA/MiLoRA show stability and performance gains, but no ablation isolates whether the gains arise from the minimized gap versus secondary geometric properties preserved by the initialization; without this isolation the causal link to the theoretical result remains untested.
minor comments (2)
- [Abstract] Notation for the gap quantity is introduced without an explicit equation reference in the abstract; adding a parenthetical pointer to the defining equation would improve readability.
- [Figures] Figure captions for the training curves could explicitly label the y-axis quantity (e.g., reward or KL divergence) to avoid ambiguity when comparing stability across methods.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and will revise the manuscript to incorporate clarifications and additional experiments where appropriate.
read point-by-point responses
-
Referee: [§4] §4 (theoretical analysis): the derivation establishes that orthonormal initialization minimizes the LoRA–full-fine-tuning gap, yet the manuscript does not state the regime (e.g., reward variance, policy-update scale, or LoRA rank relative to gradient noise) under which this gap is the dominant factor controlling RLVR stability and performance. This assumption is load-bearing for interpreting both the theoretical claim and the experimental superiority.
Authors: We agree that explicitly delineating the operating regime is necessary for a complete interpretation. The derivation assumes moderate reward variance and policy updates that remain small relative to gradient noise, ensuring the initialization gap is the primary source of deviation from full fine-tuning. In the revised manuscript we will add a paragraph in §4 stating these conditions and their connection to the RLVR objective. revision: yes
-
Referee: [§5] §5 (experiments): the comparisons of RLPO/RLMO against PiSSA/MiLoRA show stability and performance gains, but no ablation isolates whether the gains arise from the minimized gap versus secondary geometric properties preserved by the initialization; without this isolation the causal link to the theoretical result remains untested.
Authors: The referee correctly identifies the absence of an isolating ablation. Although the unified analysis in §4 already attributes performance differences to gap minimization and explains the underperformance of PiSSA/MiLoRA, an explicit ablation would strengthen the causal claim. We will add such an ablation in the revision, comparing against a controlled initialization that retains secondary geometric properties but does not minimize the gap. revision: yes
Circularity Check
Theoretical analysis of minimal LoRA-full gap under orthonormal init is self-contained
full rationale
The paper's central result is a theoretical analysis deriving that orthonormal initialization minimizes the gap between LoRA and full fine-tuning outcomes in RLVR. No equations, self-citations, or fitted quantities are shown in the provided text that would make this gap-minimization property equivalent to its inputs by construction. The derivation is presented as independent first-principles work on LoRA dynamics, with experiments serving as validation rather than the source of the claim. This matches the default expectation of no significant circularity for a paper whose core contribution is a stated theoretical property rather than a renamed fit or self-referential definition.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
, author=
Lora: Low-rank adaptation of large language models. , author=. Iclr , volume=
-
[2]
Advances in Neural Information Processing Systems , volume=
Pissa: Principal singular values and singular vectors adaptation of large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[3]
Pan and Zhangyang Wang and Yuandong Tian and Kai Sheng Tai , year=
Hanqing Zhu and Zhenyu Zhang and Hanxian Huang and DiJia Su and Zechun Liu and Jiawei Zhao and Igor Fedorov and Hamed Pirsiavash and Zhizhou Sha and Jinwon Lee and David Z. Pan and Zhangyang Wang and Yuandong Tian and Kai Sheng Tai , year=. The Path Not Taken:. 2511.08567 , archivePrefix=
-
[4]
Mathematics of the USSR-Sbornik , volume=
Distribution of eigenvalues for some sets of random matrices , author=. Mathematics of the USSR-Sbornik , volume=. 1967 , publisher=
1967
-
[5]
Language Models are Few-Shot Learners , url =
Brown, Tom and Mann, Benjamin and Ryder, Nick and Subbiah, Melanie and Kaplan, Jared D and Dhariwal, Prafulla and Neelakantan, Arvind and Shyam, Pranav and Sastry, Girish and Askell, Amanda and Agarwal, Sandhini and Herbert-Voss, Ariel and Krueger, Gretchen and Henighan, Tom and Child, Rewon and Ramesh, Aditya and Ziegler, Daniel and Wu, Jeffrey and Winte...
-
[6]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[7]
2023 , eprint=
LLaMA: Open and Efficient Foundation Language Models , author=. 2023 , eprint=
2023
-
[8]
DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning
Guo, Daya and Yang, Dejian and Zhang, Haowei and Song, Junxiao and Wang, Peiyi and others , year=. DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning , volume=. Nature , publisher=. doi:10.1038/s41586-025-09422-z , number=
-
[9]
2023 , eprint=
Mistral 7B , author=. 2023 , eprint=
2023
-
[10]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Training a helpful and harmless assistant with reinforcement learning from human feedback , author=. arXiv preprint arXiv:2204.05862 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
International conference on machine learning , pages=
Parameter-efficient transfer learning for NLP , author=. International conference on machine learning , pages=. 2019 , organization=
2019
-
[12]
Proceedings of the 2021 conference on empirical methods in natural language processing , pages=
The power of scale for parameter-efficient prompt tuning , author=. Proceedings of the 2021 conference on empirical methods in natural language processing , pages=
2021
-
[13]
Towards a unified view of parameter-efficient transfer learning
Towards a unified view of parameter-efficient transfer learning , author=. arXiv preprint arXiv:2110.04366 , year=
-
[14]
2025 , eprint=
LIFT the Veil for the Truth: Principal Weights Emerge after Rank Reduction for Reasoning-Focused Supervised Fine-Tuning , author=. 2025 , eprint=
2025
-
[15]
International Conference on Learning Representations , volume=
Vera: Vector-based random matrix adaptation , author=. International Conference on Learning Representations , volume=
-
[16]
IEEE transactions on Computers , volume=
Discrete cosine transform , author=. IEEE transactions on Computers , volume=. 2006 , publisher=
2006
-
[17]
1999 , publisher=
A wavelet tour of signal processing , author=. 1999 , publisher=
1999
-
[18]
2026 , eprint=
The Invisible Leash: Why RLVR May or May Not Escape Its Origin , author=. 2026 , eprint=
2026
-
[19]
2023 , eprint=
BloombergGPT: A Large Language Model for Finance , author=. 2023 , eprint=
2023
-
[20]
2024 , eprint=
OLoRA: Orthonormal Low-Rank Adaptation of Large Language Models , author=. 2024 , eprint=
2024
-
[21]
International Conference on Learning Representations , volume=
Parameter-efficient orthogonal finetuning via butterfly factorization , author=. International Conference on Learning Representations , volume=
-
[22]
International Conference on Learning Representations , volume=
Flashattention-2: Faster attention with better parallelism and work partitioning , author=. International Conference on Learning Representations , volume=
-
[23]
Proceedings of the 29th symposium on operating systems principles , pages=
Efficient memory management for large language model serving with pagedattention , author=. Proceedings of the 29th symposium on operating systems principles , pages=
-
[24]
Yu, Qiying and Zhang, Zheng and Zhu, Ruofei and Yuan, Yufeng and Zuo, Xiaochen and Yue, Yu and Dai, Weinan and Fan, Tiantian and Liu, Gaohong and Liu, Lingjun and others , journal=
-
[25]
Proceedings of the Twentieth European Conference on Computer Systems , pages=
Hybridflow: A flexible and efficient rlhf framework , author=. Proceedings of the Twentieth European Conference on Computer Systems , pages=
-
[26]
2023 , eprint=
Efficient RLHF: Reducing the Memory Usage of PPO , author=. 2023 , eprint=
2023
-
[27]
Advances in Neural Information Processing Systems , volume=
Controlling text-to-image diffusion by orthogonal finetuning , author=. Advances in Neural Information Processing Systems , volume=
-
[28]
2024 , eprint=
Understanding and Alleviating Memory Consumption in RLHF for LLMs , author=. 2024 , eprint=
2024
-
[29]
2025 , eprint=
FinGPT: Open-Source Financial Large Language Models , author=. 2025 , eprint=
2025
-
[30]
2023 , eprint=
MEDITRON-70B: Scaling Medical Pretraining for Large Language Models , author=. 2023 , eprint=
2023
-
[31]
Nature , volume=
Large language models encode clinical knowledge , author=. Nature , volume=. 2023 , publisher=
2023
-
[32]
2024 , eprint=
Code Llama: Open Foundation Models for Code , author=. 2024 , eprint=
2024
-
[33]
International Conference on Learning Representations , volume=
Wizardcoder: Empowering code large language models with evol-instruct , author=. International Conference on Learning Representations , volume=
-
[34]
2024 , eprint=
Llemma: An Open Language Model For Mathematics , author=. 2024 , eprint=
2024
-
[35]
2025 , eprint=
WizardMath: Empowering Mathematical Reasoning for Large Language Models via Reinforced Evol-Instruct , author=. 2025 , eprint=
2025
-
[36]
Advances in neural information processing systems , volume=
Qlora: Efficient finetuning of quantized llms , author=. Advances in neural information processing systems , volume=
-
[37]
SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-training
Sft memorizes, rl generalizes: A comparative study of foundation model post-training , author=. arXiv preprint arXiv:2501.17161 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
2011 , eprint=
A Reduction of Imitation Learning and Structured Prediction to No-Regret Online Learning , author=. 2011 , eprint=
2011
-
[39]
2025 , eprint=
RL's Razor: Why Online Reinforcement Learning Forgets Less , author=. 2025 , eprint=
2025
-
[40]
2017 , eprint=
Proximal Policy Optimization Algorithms , author=. 2017 , eprint=
2017
-
[41]
2024 , editor =
Hayou, Soufiane and Ghosh, Nikhil and Yu, Bin , booktitle =. 2024 , editor =
2024
-
[42]
Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) , pages=
Bitfit: Simple parameter-efficient fine-tuning for transformer-based masked language-models , author=. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) , pages=
-
[43]
2023 , eprint=
A Rank Stabilization Scaling Factor for Fine-Tuning with LoRA , author=. 2023 , eprint=
2023
-
[44]
2024 , eprint=
Parameter-Efficient Fine-Tuning for Large Models: A Comprehensive Survey , author=. 2024 , eprint=
2024
-
[45]
Prefix-tuning: Optimizing continuous prompts for generation , author=. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) , pages=
-
[46]
2023 , eprint=
Camels in a Changing Climate: Enhancing LM Adaptation with Tulu 2 , author=. 2023 , eprint=
2023
-
[47]
2020 , eprint=
Fine-Tuning Language Models from Human Preferences , author=. 2020 , eprint=
2020
-
[48]
2024 , eprint=
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models , author=. 2024 , eprint=
2024
-
[49]
2021 , eprint=
Training Verifiers to Solve Math Word Problems , author=. 2021 , eprint=
2021
-
[50]
2021 , eprint=
Measuring Mathematical Problem Solving With the MATH Dataset , author=. 2021 , eprint=
2021
-
[51]
American Invitational Mathematics Examination (AIME) 2024 , author=
2024
-
[52]
2023 , publisher =
Hemish Veeraboina , title =. 2023 , publisher =
2023
-
[53]
Thinking Machines Lab: Connectionism , year =
John Schulman and Thinking Machines Lab , title =. Thinking Machines Lab: Connectionism , year =
-
[54]
Advances in neural information processing systems , volume=
Judging llm-as-a-judge with mt-bench and chatbot arena , author=. Advances in neural information processing systems , volume=
-
[55]
Adaptive estimation of linear functionals by model selection , volume=
Laurent, Béatrice and Ludeña, Carenne and Prieur, Clémentine , year=. Adaptive estimation of linear functionals by model selection , volume=. Electronic Journal of Statistics , publisher=. doi:10.1214/07-ejs127 , number=
-
[56]
Training Verifiers to Solve Math Word Problems
Training Verifiers to Solve Math Word Problems , author=. arXiv preprint arXiv:2110.14168 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[57]
Proceedings of the 2018 EMNLP workshop BlackboxNLP: Analyzing and interpreting neural networks for NLP , pages=
GLUE: A multi-task benchmark and analysis platform for natural language understanding , author=. Proceedings of the 2018 EMNLP workshop BlackboxNLP: Analyzing and interpreting neural networks for NLP , pages=
2018
-
[58]
2023 , eprint=
AdaLoRA: Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning , author=. 2023 , eprint=
2023
-
[59]
Forty-first International Conference on Machine Learning , year=
Dora: Weight-decomposed low-rank adaptation , author=. Forty-first International Conference on Machine Learning , year=
-
[60]
Proceedings of the 32nd International Conference on Machine Learning , pages =
Trust Region Policy Optimization , author =. Proceedings of the 32nd International Conference on Machine Learning , pages =. 2015 , editor =
2015
-
[61]
Proceedings of the Nineteenth International Conference on Machine Learning , pages =
Kakade, Sham and Langford, John , title =. Proceedings of the Nineteenth International Conference on Machine Learning , pages =. 2002 , isbn =
2002
-
[62]
Advances in Neural Information Processing Systems , volume=
Implicit Regularization in Matrix Factorization , author=. Advances in Neural Information Processing Systems , volume=
-
[63]
2024 , eprint=
Asymmetry in Low-Rank Adapters of Foundation Models , author=. 2024 , eprint=
2024
-
[64]
Mathematische Annalen , volume=
Das asymptotische Verteilungsgesetz der Eigenwerte linearer partieller Differentialgleichungen , author=. Mathematische Annalen , volume=
-
[65]
BIT Numerical Mathematics , volume=
Perturbation bounds in connection with singular value decomposition , author=. BIT Numerical Mathematics , volume=
-
[66]
Fan, Chenghao and Lu, Zhenyi and Liu, Sichen and Gu, Chengfeng and Qu, Xiaoye and Wei, Wei and Cheng, Yu , booktitle =. Make. 2025 , editor =
2025
-
[67]
International Conference on Learning Representations , volume=
Kasa: Knowledge-aware singular-value adaptation of large language models , author=. International Conference on Learning Representations , volume=
-
[68]
2025 , eprint=
Evaluating Parameter Efficient Methods for RLVR , author=. 2025 , eprint=
2025
-
[69]
Milora: Harnessing minor singular components for parameter-efficient llm finetuning , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2025
-
[70]
2026 , eprint=
On the Scaling of PEFT: Towards Million Personal Models of Trillion Parameters , author=. 2026 , eprint=
2026
-
[71]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[72]
2026 , eprint=
Lessons from the Trenches on Reproducible Evaluation of Language Models , author=. 2026 , eprint=
2026
-
[73]
PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel
Pytorch fsdp: experiences on scaling fully sharded data parallel , author=. arXiv preprint arXiv:2304.11277 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[74]
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
Megatron-lm: Training multi-billion parameter language models using model parallelism , author=. arXiv preprint arXiv:1909.08053 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[75]
Training Deep Nets with Sublinear Memory Cost
Training deep nets with sublinear memory cost , author=. arXiv preprint arXiv:1604.06174 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[76]
2021 USENIX Annual Technical Conference (USENIX ATC 21) , pages=
\ Zero-offload \ : Democratizing \ billion-scale \ model training , author=. 2021 USENIX Annual Technical Conference (USENIX ATC 21) , pages=
2021
-
[77]
Program Synthesis with Large Language Models
Program synthesis with large language models , author=. arXiv preprint arXiv:2108.07732 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.