CoDex: Learning Compositional Dexterous Functional Manipulation without Demonstrations
Pith reviewed 2026-07-01 04:55 UTC · model grok-4.3
The pith
CoDex lets robots discover and execute complex functional manipulation tasks like spraying or gluing without any human demonstrations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
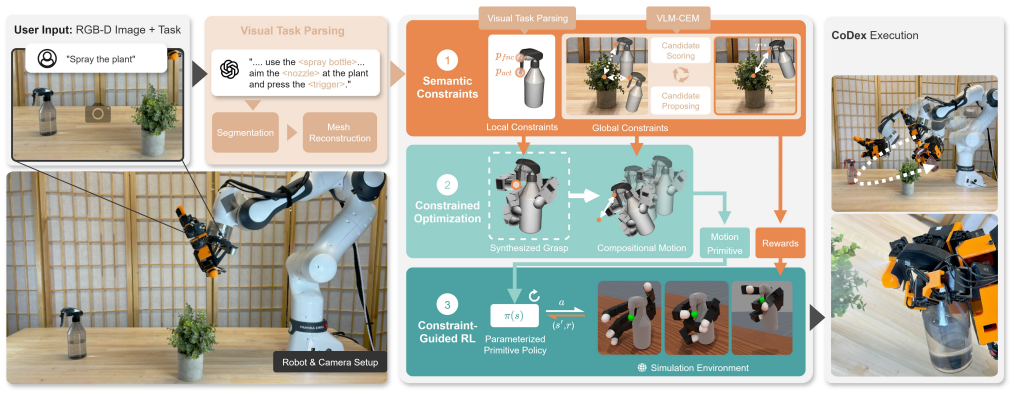
CoDex autonomously discovers CD-FOM manipulation strategies using VLMs to infer semantic constraints that guide analytic constrained optimization for functional grasp candidates, which are refined with RL to produce full grasp-move-actuate policies transferable from simulation to the real world, succeeding on six tasks with unseen objects without demonstrations.
What carries the argument
Vision-language model inference of semantic constraints that constrain analytic optimization of functional grasps, followed by reinforcement learning refinement into full policies.
If this is right
- Policies for grasping, moving, and actuating objects with internal mechanisms can be generated from task descriptions alone.
- The resulting behaviors transfer from simulation to a 7-DoF arm with 16-DoF hand across six distinct tasks.
- The same pipeline works on previously unseen objects and unseen target surfaces.
- No human demonstration data is required at any stage of policy discovery or refinement.
Where Pith is reading between the lines
- The method could extend to tasks where the functional goal is specified only in natural language rather than predefined templates.
- If the constraint-inference step generalizes, similar pipelines might apply to other domains that combine semantic understanding with physical dexterity.
- Success without demonstrations suggests that scaling the number of tasks would depend mainly on the breadth of the language model rather than on collecting new robot data.
Load-bearing premise
Vision-language models can reliably infer semantic constraints from task and scene descriptions that are accurate and complete enough to produce viable grasp candidates via analytic optimization.
What would settle it
Running the system on a new task where the vision-language model produces an incomplete or incorrect set of semantic constraints that causes the analytic optimizer to return no usable grasp candidates would falsify the central claim.
Figures







read the original abstract
In this work, we study Compositional Dexterous Functional Object Manipulation (CD-FOM): tasks such as aiming and actuating a spray bottle on a plant or a glue gun on wood, which require both actuating an object's internal mechanism and controlling its pose to apply the object's function to the environment. These tasks pose significant challenges for robots due to the demanding integration of semantic understanding of the object's function, actuation mode, and application area with intricate physical dexterity to manage grasp stability, movement trajectory, and actuation. We introduce CoDex, a zero-demonstration framework that autonomously discovers CD-FOM manipulation strategies. CoDex uses vision-language models (VLMs) to infer semantic constraints from the task and scene. These constraints guide analytic constrained optimization to generate a short list of functional grasp candidates that can be efficiently refined with reinforcement learning to generate full grasp-move-actuate policies transferable from simulation to the real world. We evaluate CoDex on a 7-DoF robot arm with a 16-DoF multi-fingered hand across six CD-FOM tasks involving previously unseen objects with internal mechanisms, including spray bottles, hot glue guns, air dusters, flashlights, and pepper grinders, and their application to unseen target objects, showcasing its ability to autonomously discover and execute complex, physically viable dexterous behaviors without human demonstrations. More information at https://robin-lab.cs.utexas.edu/CoDex/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CoDex, a zero-demonstration framework for Compositional Dexterous Functional Object Manipulation (CD-FOM) tasks such as actuating a spray bottle or glue gun while controlling its pose. CoDex uses vision-language models (VLMs) to infer semantic constraints (task function, actuation mode, application area) from task and scene descriptions; these guide analytic constrained optimization to produce functional grasp candidates that are refined via reinforcement learning into full grasp-move-actuate policies. The policies are claimed to transfer from simulation to a real 7-DoF arm with 16-DoF hand and succeed on six tasks with previously unseen objects (spray bottles, hot glue guns, air dusters, flashlights, pepper grinders) applied to unseen targets.
Significance. If the results hold, the work would be significant for demonstrating autonomous discovery of complex dexterous functional behaviors without human demonstrations by tightly coupling VLM-based semantic reasoning with analytic optimization and RL. This addresses a challenging integration of high-level functional understanding and low-level physical dexterity, with potential impact on sim-to-real transfer for manipulation tasks involving internal mechanisms. The zero-demonstration and compositional aspects would be notable strengths if supported by quantitative evidence on robustness.
major comments (2)
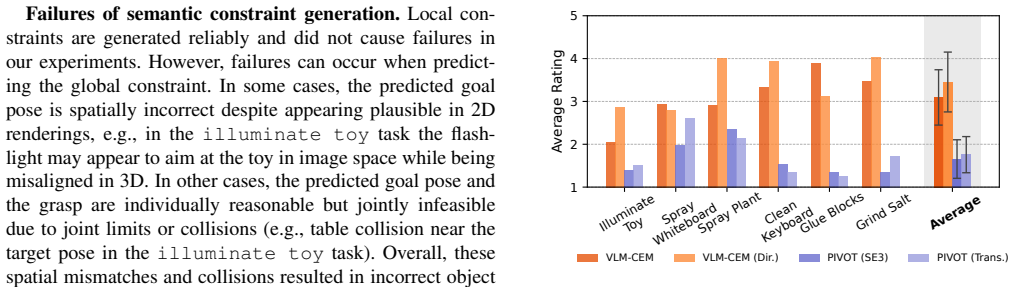
- [Abstract] Abstract: The pipeline's first non-trivial stage is VLM extraction of semantic constraints that are fed to analytic constrained optimization. The claim that this produces viable grasp candidates whose RL refinement yields functional policies on six tasks requires that the inferred constraints be both accurate and complete. No quantitative results on VLM output accuracy, variance across prompts, or failure modes (e.g., omitted kinematic constraints leading to empty candidate sets) are provided, leaving the load-bearing handoff unverified.
- [Abstract] Abstract (evaluation paragraph): The manuscript states that CoDex succeeds on six CD-FOM tasks with unseen objects and sim-to-real transfer, yet reports no success rates, ablation studies isolating the VLM/optimization/RL contributions, baseline comparisons, or error analysis. Without these, it is impossible to assess whether the analytic optimization step produces usable candidates or whether RL recovers from imperfect VLM outputs.
minor comments (1)
- [Abstract] The abstract mentions a project website but does not indicate whether code, prompts, or optimization formulations will be released, which would aid reproducibility of the VLM-to-optimization pipeline.
Simulated Author's Rebuttal
We thank the referee for the thoughtful review and constructive suggestions. We agree that additional quantitative analysis would strengthen the presentation of the VLM stage and overall results. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The pipeline's first non-trivial stage is VLM extraction of semantic constraints that are fed to analytic constrained optimization. The claim that this produces viable grasp candidates whose RL refinement yields functional policies on six tasks requires that the inferred constraints be both accurate and complete. No quantitative results on VLM output accuracy, variance across prompts, or failure modes (e.g., omitted kinematic constraints leading to empty candidate sets) are provided, leaving the load-bearing handoff unverified.
Authors: We agree that quantitative verification of the VLM constraint inference would make the handoff more transparent. While end-to-end task success provides indirect evidence that the inferred constraints are usable, we will add an analysis of VLM output accuracy, prompt variance, and observed failure modes (including cases producing empty candidate sets) to the revised manuscript. revision: yes
-
Referee: [Abstract] Abstract (evaluation paragraph): The manuscript states that CoDex succeeds on six CD-FOM tasks with unseen objects and sim-to-real transfer, yet reports no success rates, ablation studies isolating the VLM/optimization/RL contributions, baseline comparisons, or error analysis. Without these, it is impossible to assess whether the analytic optimization step produces usable candidates or whether RL recovers from imperfect VLM outputs.
Authors: The current manuscript emphasizes qualitative demonstration of autonomous discovery and sim-to-real transfer across the six tasks. We acknowledge that quantitative metrics are needed to isolate component contributions and quantify robustness. In the revision we will report success rates, ablation studies, baseline comparisons, and error analysis. revision: yes
Circularity Check
No circularity: pipeline relies on external VLM + analytic optimizer + RL without self-referential reduction
full rationale
The provided abstract and description contain no equations, fitted parameters renamed as predictions, or load-bearing self-citations. The claimed chain (VLM semantic constraints → analytic grasp optimization → RL policy refinement) uses independent external components (VLMs, constrained optimization, RL) whose correctness is not asserted by definition or by prior self-citation within the paper. No step reduces the output to the input by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption VLMs can extract task-relevant semantic constraints from language and visual input that are sufficient to constrain grasp optimization for functional manipulation.
- domain assumption Policies refined in simulation transfer to the physical robot without additional real-world fine-tuning for the reported tasks.
Reference graph
Works this paper leans on
-
[1]
Functional object-oriented network for manipulation learning,
D. Paulius, Y . Huang, R. Milton, W. D. Buchanan, J. Sam, and Y . Sun, “Functional object-oriented network for manipulation learning,” in 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2016, pp. 2655–2662
2016
-
[2]
Dexmots: Learning contact-rich dexterous manipulation in an object-centric task space with differentiable simulation,
K. Srinivasan, E. Heiden, I. Ng, J. Bohg, and A. Garg, “Dexmots: Learning contact-rich dexterous manipulation in an object-centric task space with differentiable simulation,” in International Symposium on Robotics Research (ISRR), 2024
2024
-
[3]
Fungrasp: Functional grasping for diverse dexterous hands,
L. Huang, H. Zhang, Z. Wu, S. Christen, and J. Song, “Fungrasp: Functional grasping for diverse dexterous hands,” IEEE Robotics and Automation Letters, 2025
2025
-
[4]
Functional eigen- grasping using approach heatmaps,
M. Aburub, K. Higashi, W. Wan, and K. Harada, “Functional eigen- grasping using approach heatmaps,” arXiv preprint, 2024
2024
-
[5]
Dexterous functional grasping,
A. Agarwal, S. Uppal, K. Shaw, and D. Pathak, “Dexterous functional grasping,” in Conference on Robot Learning (CoRL), 2023
2023
-
[6]
Dexterous manipulation with multi-fingered robotic hands: A review,
M. Li, Z. Chen, C. Yang, and Q. Zhu, “Dexterous manipulation with multi-fingered robotic hands: A review,” Frontiers in Neurorobotics, vol. 16, p. 861825, 2022
2022
-
[7]
Dexterous manipulation through imitation learning: A survey,
S. An, Z. Meng, C. Tang, Y . Zhou, T. Liu, F. Ding, S. Zhang, Y . Mu, R. Song, W. Zhang, Z.-G. Hou, and H. Zhang, “Dexterous manipulation through imitation learning: A survey,” arXiv preprint arXiv:2504.03515, 2025
-
[8]
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn, “Learning fine-grained bimanual manipulation with low-cost hardware,” arXiv preprint arXiv:2304.13705, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
What matters in learning from offline human demonstrations for robot manipula- tion,
A. Mandlekar, D. Xu, J. Wong, S. Nasiriany, C. Wang, R. Kulkarni, L. Fei-Fei, S. Savarese, Y . Zhu, and R. Mart´ın-Mart´ın, “What matters in learning from offline human demonstrations for robot manipula- tion,” in Conference on Robot Learning, 2022, pp. 1678–1690
2022
-
[10]
A. Iyer, Z. Peng, Y . Dai, I. Guzey, S. Haldar, S. Chintala, and L. Pinto, “Open teach: A versatile teleoperation system for robotic manipulation,” arXiv preprint arXiv:2403.07870, 2024
-
[11]
C. Wang, H. Shi, W. Wang, R. Zhang, L. Fei-Fei, and C. K. Liu, “Dexcap: Scalable and portable mocap data collection system for dexterous manipulation,” arXiv preprint arXiv:2403.07788, 2024
-
[12]
Dexpilot: Vision-based tele- operation of dexterous robotic hand-arm system,
A. Handa, K. Van Wyk, W. Yang, J. Liang, Y .-W. Chao, Q. Wan, S. Birchfield, N. Ratliff, and D. Fox, “Dexpilot: Vision-based tele- operation of dexterous robotic hand-arm system,” in 2020 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2020, pp. 9164–9170
2020
-
[13]
Learning Dexterous Manipulation Policies from Experience and Imitation
V . Kumar, A. Gupta, E. Todorov, and S. Levine, “Learning dexterous manipulation policies from experience and imitation,” arXiv preprint arXiv:1611.05095, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[14]
Affordances from human videos as a versatile representation for robotics,
S. Bahl, R. Mendonca, L. Chen, U. Jain, and D. Pathak, “Affordances from human videos as a versatile representation for robotics,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 13 778–13 790
2023
-
[15]
Screwmimic: Bimanual imitation from human videos with screw space projection,
A. Bahety, P. Mandikal, B. Abbatematteo, and R. Mart ´ın-Mart´ın, “Screwmimic: Bimanual imitation from human videos with screw space projection,” in Robotics: Science and Systems, 2024
2024
-
[16]
Safemimic: Towards safe and autonomous human-to-robot imitation for mobile manipulation,
A. Bahety, A. Balaji, B. Abbatematteo, and R. Mart ´ın-Mart´ın, “Safemimic: Towards safe and autonomous human-to-robot imitation for mobile manipulation,” in Robotics: Science and Systems, 2025
2025
-
[17]
R. S. Sutton, A. G. Barto et al., Reinforcement learning: An introduction. MIT press Cambridge, 1998, vol. 1, no. 1
1998
-
[18]
Reinforcement learning: A survey,
L. P. Kaelbling, M. L. Littman, and A. W. Moore, “Reinforcement learning: A survey,” Journal of artificial intelligence research, vol. 4, pp. 237–285, 1996
1996
-
[19]
Robot grasp synthesis algorithms: A survey,
K. B. Shimoga, “Robot grasp synthesis algorithms: A survey,” The International Journal of Robotics Research, vol. 15, no. 3, pp. 230– 266, 1996
1996
-
[20]
Graspit!: A versatile simulator for grasp analysis,
A. T. Miller and P. K. Allen, “Graspit!: A versatile simulator for grasp analysis,” in ASME International Mechanical Engineering Congress and Exposition, vol. 26652. American Society of Mechanical Engineers, 2000, pp. 1251–1258
2000
-
[21]
Grasp synthesis in cluttered en- vironments for dexterous hands,
D. Berenson and S. S. Srinivasa, “Grasp synthesis in cluttered en- vironments for dexterous hands,” in Humanoids 2008-8th IEEE-RAS International Conference on Humanoid Robots. IEEE, 2008
2008
-
[22]
Closing the Loop for Robotic Grasping: A Real-time, Generative Grasp Synthesis Approach
D. Morrison, P. Corke, and J. Leitner, “Closing the loop for robotic grasping: A real-time, generative grasp synthesis approach,” arXiv preprint arXiv:1804.05172, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[23]
Frogger: Fast robust grasp generation via the min-weight metric,
A. H. Li, P. Culbertson, J. W. Burdick, and A. D. Ames, “Frogger: Fast robust grasp generation via the min-weight metric,” in 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2023, pp. 6809–6816
2023
-
[24]
Solving challenging dexterous manipulation tasks with trajectory optimisation and reinforcement learning,
H. Charlesworth and G. Montana, “Solving challenging dexterous manipulation tasks with trajectory optimisation and reinforcement learning,” in Proceedings of the 3rd Workshop on Machine Learning for Autonomous Driving, PMLR, vol. 139, 2021
2021
-
[25]
Springgrasp: Synthesizing com- pliant, dexterous grasps under shape uncertainty,
S. Chen, J. Bohg, and C. K. Liu, “Springgrasp: Synthesizing com- pliant, dexterous grasps under shape uncertainty,” arXiv preprint arXiv:2404.13532, 2024
-
[26]
DexTOG: Learning Task-Oriented Dexterous Grasp with Language Condition,
J. Zhang, W. Xu, Z. Yu, P. Xie, T. Tang, and C. Lu, “DexTOG: Learning Task-Oriented Dexterous Grasp with Language Condition,” IEEE Robotics and Automation Letters, vol. 10, no. 2, 2025
2025
-
[27]
A Survey on Vision-Language-Action Models for Embodied AI
Y . Ma, Z. Song, Y . Zhuang, J. Hao, and I. King, “A survey on vision-language-action models for embodied ai,” arXiv preprint arXiv:2405.14093, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
DexVLA: Vision-Language Model with Plug-In Diffusion Expert for General Robot Control
J. Wen, Y . Zhu, J. Li, Z. Tang, C. Shen, and F. Feng, “Dexvla: Vision-language model with plug-in diffusion expert for general robot control,” arXiv preprint arXiv:2502.05855, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
J. Liu, M. Liu, Z. Wang, P. An, X. Li, K. Zhou, S. Yang, R. Zhang, Y . Guo, and S. Zhang, “Robomamba: Efficient vision-language- action model for robotic reasoning and manipulation,” arXiv preprint arXiv:2406.04339, 2024
-
[30]
Pivot: Iterative visual prompting elicits actionable knowledge for vlms,
S. Nasiriany, F. Xia, W. Yu, T. Xiao, J. Liang, I. Dasgupta, A. Xie, D. Driess, A. Wahid, Z. Xu, Q. Vuong, T. Zhang, T.-W. E. Lee, K.- H. Lee, P. Xu, S. Kirmani, Y . Zhu, A. Zeng, K. Hausman, N. Heess, C. Finn, S. Levine, and B. Ichter, “Pivot: Iterative visual prompting elicits actionable knowledge for vlms,” 2024
2024
-
[31]
Rekep: Spatio- temporal reasoning of relational keypoint constraints for robotic ma- nipulation,
W. Huang, C. Wang, Y . Li, R. Zhang, and F.-F. Li, “Rekep: Spatio- temporal reasoning of relational keypoint constraints for robotic ma- nipulation,” in Conference on Robot Learning (CoRL), 2024
2024
-
[32]
Robodexvlm: Visual language model-enabled task planning and motion control for dexterous robot manipulation,
H. Liu, S. Guo, P. Mai, J. Cao, H. Li, and J. Ma, “Robodexvlm: Visual language model-enabled task planning and motion control for dexterous robot manipulation,” arXiv preprint, 2025
2025
-
[33]
Language-guided dexterous functional grasping by llm generated grasp functionality and synergy for humanoid manipulation,
Z. Li, J. Liu, Z. Li, Z. Dong, T. Teng, Y . Ou, D. Caldwell, and F. Chen, “Language-guided dexterous functional grasping by llm generated grasp functionality and synergy for humanoid manipulation,” IEEE Transactions on Automation Science and Engineering, vol. 22, pp. 10 506–10 519, 2025
2025
-
[34]
Contactgrasp: Functional multi-finger grasp synthesis from contact,
S. Brahmbhatt, A. Handa, J. Hays, and D. Fox, “Contactgrasp: Functional multi-finger grasp synthesis from contact,” in IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2019, pp. 6396–6403
2019
-
[35]
Contact- graspnet: Efficient 6-dof grasp generation in cluttered scenes,
M. Sundermeyer, A. Mousavian, R. Triebel, and D. Fox, “Contact- graspnet: Efficient 6-dof grasp generation in cluttered scenes,” inIEEE International Conference on Robotics and Automation (ICRA), 2021, pp. 4269–4276
2021
-
[36]
Planning optimal grasps,
C. Ferrari and J. F. Canny, “Planning optimal grasps,” in Proceedings., IEEE International Conference on Robotics and Automation. IEEE, 1992, pp. 2290–2295
1992
-
[37]
Manipulation trajectory optimization with online grasp synthesis and selection,
L. Wang, Y . Xiang, and D. Fox, “Manipulation trajectory optimization with online grasp synthesis and selection,” in Robotics: Science and Systems (RSS), 2020
2020
-
[38]
Neural grasp distance fields for robot manipulation,
T. Weng, D. Held, F. Meier, and M. Mukadam, “Neural grasp distance fields for robot manipulation,” in IEEE International Conference on Robotics and Automation (ICRA), 2023
2023
-
[39]
B. Sundaralingam, A. Lambert, C. Wang, Y . Li, F.-F. Li, and R. Zhang, “Multi-finger manipulation via trajectory optimization with differentiable rolling and geometric constraints,” arXiv preprint arXiv:2408.13229, 2024
-
[40]
B. Zhou, H. Yuan, Y . Fu, and Z. Lu, “Learning diverse bimanual dexterous manipulation skills from human demonstrations,” arXiv preprint arXiv:2410.02477, 2024
-
[41]
Learning dexterous in- hand manipulation with multifingered hands via visuomotor diffusion,
P. Koczy, M. C. Welle, and D. Kragic, “Learning dexterous in- hand manipulation with multifingered hands via visuomotor diffusion,” arXiv preprint arXiv:2503.02587, 2025
-
[42]
Kinesoft: Learning proprioceptive manipulation policies with soft robot hands,
C. Wang, R. Yang, J. Ichnowski, M. Danielczuk, Z. Xian, C. Gonzalez, R. H. Taylor, K. Goldberg, P. Abbeel, C. H. Rycroft, and Y . Ma, “Kinesoft: Learning proprioceptive manipulation policies with soft robot hands,” arXiv preprint arXiv:2503.01078, 2025
-
[43]
Learning visuotactile skills with two multifingered hands,
T. Lin, Y . Zhang, Q. Li, H. Qi, B. Yi, S. Levine, and J. Malik, “Learning visuotactile skills with two multifingered hands,” arXiv preprint arXiv:2404.16823, 2024
-
[44]
Learning task-oriented grasping for tool manipu- lation from simulated self-supervision,
K. Fang, Y . Zhu, A. Garg, A. Kurenkov, V . Mehta, L. Fei-Fei, and S. Savarese, “Learning task-oriented grasping for tool manipu- lation from simulated self-supervision,” The International Journal of Robotics Research, vol. 39, no. 2-3, pp. 202–216, 2020
2020
-
[45]
Triposr: Fast 3d object reconstruction from a single image,
D. Tochilkin, D. Pankratz, Z. Liu, Z. Huang, A. Letts, Y . Li, D. Liang, C. Laforte, V . Jampani, and Y .-P. Cao, “Triposr: Fast 3d object reconstruction from a single image,” arXiv preprint, 2024
2024
-
[46]
Molmo and pixmo: Open weights and open data for state-of-the-art vision-language models,
M. Deitke, C. Clark, S. Lee, R. Tripathi, Y . Yang, J. S. Park, M. Salehi, N. Muennighoff, K. Lo, L. Soldaini, J. Lu, T. Anderson, E. Bransom, K. Ehsani, H. Ngo, Y . Chen, A. Patel, M. Yatskar, C. Callison- Burch, A. Head, R. Hendrix, F. Bastani, E. VanderBilt, N. Lam- bert, Y . Chou, A. Chheda, J. Sparks, S. Skjonsberg, M. Schmitz, A. Sarnat, B. Bischoff...
2024
-
[47]
Foundationpose: Unified 6d pose estimation and tracking of novel objects,
B. Wen, W. Yang, J. Kautz, and S. Birchfield, “Foundationpose: Unified 6d pose estimation and tracking of novel objects,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 17 868–17 879
2024
-
[48]
Maniskill3: Gpu parallelized robotics simulation and rendering for generalizable embodied ai,
S. Tao, F. Xiang, A. Shukla, Y . Qin, X. Hinrichsen, X. Yuan, C. Bao, X. Lin, Y . Liu, T. kai Chan, Y . Gao, X. Li, T. Mu, N. Xiao, A. Gurha, V . N. Rajesh, Y . W. Choi, Y .-R. Chen, Z. Huang, R. Calandra, R. Chen, S. Luo, and H. Su, “Maniskill3: Gpu parallelized robotics simulation and rendering for generalizable embodied ai,” 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.