CoMet: Context and Multiplicity Decomposition for Multimodal Uncertainty Estimation
Pith reviewed 2026-07-01 06:11 UTC · model grok-4.3
The pith
Decomposing uncertainty into context ambiguity and number of compatible answers enables efficient estimation in multimodal models without sampling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
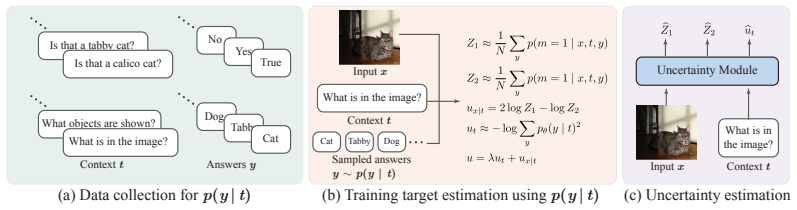
Uncertainty in MLLMs can be decomposed into a context-specific term, which captures ambiguity induced by the given context such as the task or prompt, and a multiplicity-specific term, which captures how many plausible answers determined by the context remain compatible with the given input. Training a lightweight post-hoc uncertainty module to estimate these two quantities produces efficient uncertainty estimates without autoregressive answer generation or repeated sampling.
What carries the argument
The decomposition of total uncertainty into independent context-specific and multiplicity-specific terms, each estimated by a trained lightweight post-hoc module that receives only the input.
If this is right
- Improved uncertainty scores on open-ended multimodal benchmarks compared with prior methods.
- Stronger performance on hallucination detection tasks.
- Better uncertainty estimates on multiple-choice visual question answering benchmarks.
- Uncertainty computation that avoids the cost of autoregressive generation or multiple forward passes.
Where Pith is reading between the lines
- The same split might be tested on purely textual models to see whether the two components remain separable outside the multimodal setting.
- If the lightweight module proves reliable, it could be inserted into deployed systems to flag uncertain outputs in real time.
- Future model training could incorporate a similar decomposition as an auxiliary objective so the base model itself produces the two uncertainty terms.
- The approach suggests checking whether other uncertainty sources, such as model parameter noise, can be isolated in the same additive way.
Load-bearing premise
That uncertainty can be split into two independent components that a module can predict accurately from the input alone, without needing to run the main model to generate answers.
What would settle it
An evaluation on open-ended multimodal or hallucination benchmarks where the method produces worse uncertainty metrics than repeated-sampling baselines while using comparable or greater compute.
Figures




read the original abstract
Uncertainty estimation has been a long-standing challenge in AI models; it amounts to "knowing what you don't know," and metacognition is notoriously difficult even for humans (cf. the Dunning-Kruger effect). Although it is still far from solved even in simpler classification systems, tackling it in multimodal large language models (MLLMs) is becoming increasingly important. Within MLLMs, uncertainty can stem from any of the diverse sources as well as from their relationships, and further can stem from the unbounded answers in the open-ended setting. To tackle the issues, we propose CoMet, an MLLM uncertainty estimation method by decomposing uncertainty into a context-specific term and a multiplicity-specific term. The former captures ambiguity induced by the given context (e.g., task or prompt), while the latter captures how many plausible answers determined by the context remain compatible with the given input. We train a lightweight post-hoc uncertainty module to estimate these quantities, which enables efficient uncertainty estimation without autoregressive answer generation or repeated sampling. Experiments on various open-ended multimodal benchmarks, hallucination detection, and multiple-choice visual question answering benchmarks show that CoMet consistently improves uncertainty estimation over existing baselines while remaining efficient in practice. Code is available at https://github.com/princetonvisualai/comet_uncertainty
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CoMet, a method for uncertainty estimation in multimodal large language models (MLLMs). It decomposes uncertainty into a context-specific term (capturing ambiguity from the prompt/task) and a multiplicity-specific term (capturing the number of plausible answers compatible with the input). A lightweight post-hoc module is trained to estimate these quantities, enabling efficient inference without autoregressive generation or repeated sampling. Experiments on open-ended multimodal benchmarks, hallucination detection, and multiple-choice VQA tasks claim consistent improvements over baselines.
Significance. If the decomposition is valid and the empirical gains hold under scrutiny, the approach could offer a practical, efficient alternative to sampling-based uncertainty methods in MLLMs. The post-hoc design and code release are strengths for reproducibility and applicability. However, the central modeling assumption—that context and multiplicity terms can be independently estimated from input alone—requires detailed validation to assess broader impact.
minor comments (1)
- [Abstract] Abstract: The parenthetical reference to the Dunning-Kruger effect is illustrative but tangential to the technical contribution; it could be omitted without loss of clarity.
Simulated Author's Rebuttal
We thank the referee for their review and for highlighting the importance of validating the core modeling assumption in CoMet. Below we address this point directly with additional clarification on the decomposition and supporting evidence from the manuscript.
read point-by-point responses
-
Referee: The central modeling assumption—that context and multiplicity terms can be independently estimated from input alone—requires detailed validation to assess broader impact.
Authors: The decomposition follows from the distinct generative sources of uncertainty in open-ended MLLM outputs: context-specific uncertainty arises from prompt/task ambiguity (e.g., vague instructions or underspecified visual queries) and can be estimated from prompt embeddings alone, while multiplicity-specific uncertainty reflects the cardinality of the set of semantically distinct yet input-consistent answers and is estimated from the joint input representation. Because these factors are defined to be orthogonal by construction, a lightweight post-hoc network can be trained to regress both quantities separately using supervision derived from answer distributions (without requiring the terms to be entangled at inference). The manuscript already demonstrates that this yields measurable gains over non-decomposed baselines on three distinct evaluation regimes (open-ended generation, hallucination detection, and multiple-choice VQA), which would be unlikely if the independence assumption were badly violated. We can expand the supplementary material with an explicit ablation that isolates each term and reports their individual contributions to the final uncertainty score. revision: partial
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The provided abstract and description present CoMet as a decomposition of uncertainty into context-specific and multiplicity-specific terms, estimated by a separately trained lightweight post-hoc module. No equations, definitions, or claims are visible that define the target uncertainty quantities in terms of the module outputs, rename fitted parameters as predictions, or rely on self-citations for load-bearing uniqueness theorems. The modeling choice is presented explicitly as the proposed method rather than derived from prior self-referential results. This is the common case of an independent empirical proposal with no internal reduction to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Language Models (Mostly) Know What They Know
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, et al. Language models (mostly) know what they know.arXiv preprint arXiv:2207.05221, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
Teaching models to express their uncertainty in words
Stephanie Lin, Jacob Hilton, and Owain Evans. Teaching models to express their uncertainty in words. Transactions on Machine Learning Research, 2022. ISSN 2835-8856. URL https://openreview.net/ forum?id=8s8K2UZGTZ
2022
-
[3]
Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback
Katherine Tian, Eric Mitchell, Allan Zhou, Archit Sharma, Rafael Rafailov, Huaxiu Yao, Chelsea Finn, and Christopher D Manning. Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback. InConference on Empirical Methods in Natural Language Processing (EMNLP), pages 5433–5442, 2023
2023
-
[4]
Can LLMs express their uncertainty? an empirical evaluation of confidence elicitation in LLMs
Miao Xiong, Zhiyuan Hu, Xinyang Lu, YIFEI LI, Jie Fu, Junxian He, and Bryan Hooi. Can LLMs express their uncertainty? an empirical evaluation of confidence elicitation in LLMs. InInternational Conference on Learning Representations (ICLR), 2024. URL https://openreview.net/forum?id=gjeQKFxFpZ
2024
-
[5]
Vl-calibration: Decoupled confidence calibration for large vision-language models reasoning
Wenyi Xiao, Xinchi Xu, and Leilei Gan. Vl-calibration: Decoupled confidence calibration for large vision-language models reasoning. InAssociation for Computational Linguistics (ACL), 2026
2026
-
[6]
Know what you don’t know: Unanswerable questions for squad
Pranav Rajpurkar, Robin Jia, and Percy Liang. Know what you don’t know: Unanswerable questions for squad. InAssociation for Computational Linguistics (ACL), pages 784–789, 2018
2018
-
[7]
Reliable visual question answering: Abstain rather than answer incorrectly
Spencer Whitehead, Suzanne Petryk, Vedaad Shakib, Joseph Gonzalez, Trevor Darrell, Anna Rohrbach, and Marcus Rohrbach. Reliable visual question answering: Abstain rather than answer incorrectly. In European Conference on Computer Vision (ECCV), pages 148–166. Springer, 2022
2022
-
[8]
R-tuning: Instructing large language models to say ‘i don’t know’
Hanning Zhang, Shizhe Diao, Yong Lin, Yi Fung, Qing Lian, Xingyao Wang, Yangyi Chen, Heng Ji, and Tong Zhang. R-tuning: Instructing large language models to say ‘i don’t know’. InAnnual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL), pages 7113–7139, 2024
2024
-
[9]
Know your limits: A survey of abstention in large language models.Transactions of the Association for Computational Linguistics (TACL), 13:529–556, 2025
Bingbing Wen, Jihan Yao, Shangbin Feng, Chenjun Xu, Yulia Tsvetkov, Bill Howe, and Lucy Lu Wang. Know your limits: A survey of abstention in large language models.Transactions of the Association for Computational Linguistics (TACL), 13:529–556, 2025
2025
-
[10]
Self-consistency improves chain of thought reasoning in language models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[11]
arXiv preprint arXiv:2411.11919 (2024) 2, 3, 4, 6, 10, 12, 13, 14, 18
Ruiyang Zhang, Hu Zhang, and Zhedong Zheng. VL-Uncertainty: Detecting hallucination in large vision-language model via uncertainty estimation.arXiv preprint arXiv:2411.11919, 2024
-
[12]
Detecting hallucinations in large language models using semantic entropy.Nature, 630(8017):625–630, 2024
Sebastian Farquhar, Jannik Kossen, Lorenz Kuhn, and Yarin Gal. Detecting hallucinations in large language models using semantic entropy.Nature, 630(8017):625–630, 2024
2024
-
[13]
Human uncertainty makes classification more robust
Joshua C Peterson, Ruairidh M Battleday, Thomas L Griffiths, and Olga Russakovsky. Human uncertainty makes classification more robust. InInternational Conference on Computer Vision (ICCV), pages 9617– 9626, 2019
2019
-
[14]
Probabilistic face embeddings
Yichun Shi and Anil K Jain. Probabilistic face embeddings. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 6902–6911, 2019
2019
-
[15]
Word representations via gaussian embedding
Luke Vilnis and Andrew McCallum. Word representations via gaussian embedding. InInternational Conference on Learning Representations (ICLR), 2015
2015
-
[16]
Position: Multiplicity is an inevitable and inherent challenge in multimodal learning
Sanghyuk Chun and Olga Russakovsky. Position: Multiplicity is an inevitable and inherent challenge in multimodal learning. InInternational Conference on Machine Learning (ICML), 2026. 10
2026
-
[17]
Probabilistic language-image pre-training
Sanghyuk Chun, Wonjae Kim, Song Park, and Sangdoo Yun. Probabilistic language-image pre-training. In International Conference on Learning Representations (ICLR), 2025
2025
-
[18]
What uncertainties do we need in bayesian deep learning for computer vision? Advances in Neural Information Processing Systems (NeurIPS), 30, 2017
Alex Kendall and Yarin Gal. What uncertainties do we need in bayesian deep learning for computer vision? Advances in Neural Information Processing Systems (NeurIPS), 30, 2017
2017
-
[19]
A baseline for detecting misclassified and out-of-distribution examples in neural networks
Dan Hendrycks and Kevin Gimpel. A baseline for detecting misclassified and out-of-distribution examples in neural networks. InInternational Conference on Learning Representations (ICLR), 2017
2017
-
[20]
Large language models must be taught to know what they don’t know.Advances in Neural Information Processing Systems, 37:85932–85972, 2024
Sanyam Kapoor, Nate Gruver, Manley Roberts, Katherine Collins, Arka Pal, Umang Bhatt, Adrian Weller, Samuel Dooley, Micah Goldblum, and Andrew G Wilson. Large language models must be taught to know what they don’t know.Advances in Neural Information Processing Systems, 37:85932–85972, 2024
2024
-
[21]
Beyond binary rewards: Training LMs to reason about their uncertainty
Mehul Damani, Isha Puri, Stewart Slocum, Idan Shenfeld, Leshem Choshen, Yoon Kim, and Jacob Andreas. Beyond binary rewards: Training LMs to reason about their uncertainty. InInternational Conference on Learning Representations (ICLR), 2026. URLhttps://openreview.net/forum?id=ASQ649zdHm
2026
-
[22]
Making the v in vqa matter: Elevating the role of image understanding in visual question answering
Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Batra, and Devi Parikh. Making the v in vqa matter: Elevating the role of image understanding in visual question answering. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 6904–6913, 2017
2017
-
[23]
Vizwiz grand challenge: Answering visual questions from blind people
Danna Gurari, Qing Li, Abigale J Stangl, Anhong Guo, Chi Lin, Kristen Grauman, Jiebo Luo, and Jeffrey P Bigham. Vizwiz grand challenge: Answering visual questions from blind people. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 3608–3617, 2018
2018
-
[24]
Ok-vqa: A visual question answering benchmark requiring external knowledge
Kenneth Marino, Mohammad Rastegari, Ali Farhadi, and Roozbeh Mottaghi. Ok-vqa: A visual question answering benchmark requiring external knowledge. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 3195–3204, 2019
2019
-
[25]
Hallusionbench: an advanced diagnostic suite for entangled language hallucination and visual illusion in large vision-language models
Tianrui Guan, Fuxiao Liu, Xiyang Wu, Ruiqi Xian, Zongxia Li, Xiaoyu Liu, Xijun Wang, Lichang Chen, Furong Huang, Yaser Yacoob, et al. Hallusionbench: an advanced diagnostic suite for entangled language hallucination and visual illusion in large vision-language models. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 14375–14385, 2024
2024
-
[26]
Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi
Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, et al. Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 9556–9567, 2024
2024
-
[27]
Mmmu-pro: a more robust multi-discipline multimodal understanding benchmark (2025)
Xiang Yue, Tianyu Zheng, Yuansheng Ni, Yubo Wang, Kai Zhang, Shengbang Tong, Yuxuan Sun, Botao Yu, Ge Zhang, Huan Sun, et al. Mmmu-pro: a more robust multi-discipline multimodal understanding benchmark (2025). InAssociation for Computational Linguistics (ACL), 2025
2025
-
[28]
Are we on the right way for evaluating large vision-language models? Advances in Neural Information Processing Systems (NeurIPS), 37:27056–27087, 2024
Lin Chen, Jinsong Li, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Zehui Chen, Haodong Duan, Jiaqi Wang, Yu Qiao, Dahua Lin, and Feng Zhao. Are we on the right way for evaluating large vision-language models? Advances in Neural Information Processing Systems (NeurIPS), 37:27056–27087, 2024
2024
-
[29]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-VL technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. InternVL3.5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Improving uncertainty estimation through semantically diverse language generation
Lukas Aichberger, Kajetan Schweighofer, Mykyta Ielanskyi, and Sepp Hochreiter. Improving uncertainty estimation through semantically diverse language generation. InInternational Conference on Learning Representations (ICLR), 2025
2025
-
[32]
Cambrian-1: A fully open, vision-centric exploration of multimodal llms.Advances in Neural Information Processing Systems (NeurIPS), 37:87310–87356, 2024
Shengbang Tong, Ellis Brown, Penghao Wu, Sanghyun Woo, Manoj Middepogu, Sai C Akula, Jihan Yang, Shusheng Yang, Adithya Iyer, Xichen Pan, et al. Cambrian-1: A fully open, vision-centric exploration of multimodal llms.Advances in Neural Information Processing Systems (NeurIPS), 37:87310–87356, 2024
2024
-
[33]
On calibration of modern neural networks
Chuan Guo, Geoff Pleiss, Yu Sun, and Kilian Q Weinberger. On calibration of modern neural networks. In International Conference on Machine Learning (ICML), pages 1321–1330. PMLR, 2017
2017
-
[34]
Dropout as a bayesian approximation: Representing model uncertainty in deep learning
Yarin Gal and Zoubin Ghahramani. Dropout as a bayesian approximation: Representing model uncertainty in deep learning. InInternational Conference on Machine Learning (ICML), pages 1050–1059. PMLR, 2016. 11
2016
-
[35]
arXiv preprint arXiv:2002.07650 , year=
Andrey Malinin and Mark Gales. Uncertainty estimation in autoregressive structured prediction.arXiv preprint arXiv:2002.07650, 2020
-
[36]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
Align before fuse: Vision and language representation learning with momentum distillation.Advances in Neural Information Processing Systems (NeurIPS), 34:9694–9705, 2021
Junnan Li, Ramprasaath Selvaraju, Akhilesh Gotmare, Shafiq Joty, Caiming Xiong, and Steven Chu Hong Hoi. Align before fuse: Vision and language representation learning with momentum distillation.Advances in Neural Information Processing Systems (NeurIPS), 34:9694–9705, 2021
2021
-
[38]
BLIP: Bootstrapping language-image pre-training for unified vision-language understanding and generation, 2022
Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. BLIP: Bootstrapping language-image pre-training for unified vision-language understanding and generation, 2022
2022
-
[39]
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InInternational Conference on Machine Learning (ICML), pages 19730–19742. PMLR, 2023
2023
-
[40]
Probabilistic embeddings for cross-modal retrieval
Sanghyuk Chun, Seong Joon Oh, Rafael Sampaio De Rezende, Yannis Kalantidis, and Diane Larlus. Probabilistic embeddings for cross-modal retrieval. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021
2021
-
[41]
Improved probabilistic image-text representations
Sanghyuk Chun. Improved probabilistic image-text representations. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[42]
Don’t just assume; look and answer: Overcoming priors for visual question answering
Aishwarya Agrawal, Dhruv Batra, Devi Parikh, and Aniruddha Kembhavi. Don’t just assume; look and answer: Overcoming priors for visual question answering. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 4971–4980, 2018
2018
-
[43]
Rubi: Reducing unimodal biases for visual question answering
Remi Cadene, Corentin Dancette, Matthieu Cord, and Devi Parikh. Rubi: Reducing unimodal biases for visual question answering. InAdvances in Neural Information Processing Systems (NeurIPS), volume 32, 2019
2019
-
[44]
Don’t take the easy way out: Ensemble based methods for avoiding known dataset biases
Christopher Clark, Mark Yatskar, and Luke Zettlemoyer. Don’t take the easy way out: Ensemble based methods for avoiding known dataset biases. InProceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language Processing (EMNLP-IJCNLP), pages 4069–4082, 2019
2019
-
[45]
Learning de-biased representations with biased representations
Hyojin Bahng, Sanghyuk Chun, Sangdoo Yun, Jaegul Choo, and Seong Joon Oh. Learning de-biased representations with biased representations. InInternational Conference on Machine Learning (ICML), 2020
2020
-
[46]
Visual instruction tuning.Advances in Neural Information Processing Systems (NeurIPS), 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in Neural Information Processing Systems (NeurIPS), 36:34892–34916, 2023
2023
-
[47]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InInternational Conference on Machine Learning (ICML), pages 8748–8763. PMLR, 2021
2021
-
[48]
Attention is all you need
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neural Information Processing Systems (NeurIPS), pages 5998–6008, 2017
2017
-
[49]
AdamP: Slowing down the slowdown for momentum optimizers on scale-invariant weights
Byeongho Heo, Sanghyuk Chun, Seong Joon Oh, Dongyoon Han, Sangdoo Yun, Gyuwan Kim, Youngjung Uh, and Jung-Woo Ha. AdamP: Slowing down the slowdown for momentum optimizers on scale-invariant weights. InInternational Conference on Learning Representations (ICLR), 2021
2021
-
[50]
Dropout: a simple way to prevent neural networks from overfitting.Journal of machine learning research (JMLR), 15(1):1929–1958, 2014
Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov. Dropout: a simple way to prevent neural networks from overfitting.Journal of machine learning research (JMLR), 15(1):1929–1958, 2014
1929
-
[51]
Steerconf: Steering llms for confidence elicitation
Ziang Zhou, Tianyuan Jin, Jieming Shi, and Qing Li. Steerconf: Steering llms for confidence elicitation. arXiv preprint arXiv:2503.02863, 2025
-
[52]
LoRA: Low-rank adaptation of large language models
Edward J Hu, yelong shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. InInternational Conference on Learning Representations (ICLR), 2022. URLhttps://openreview.net/forum?id=nZeVKeeFYf9. 12
2022
-
[53]
Yibo Li, Miao Xiong, Jiaying Wu, and Bryan Hooi. Conftuner: Training large language models to express their confidence verbally.arXiv preprint arXiv:2508.18847, 2025
-
[54]
Prompt4trust: A reinforcement learning prompt augmentation framework for clinically-aligned confidence calibration in multimodal large language models
Anita Kriz, Elizabeth Laura Janes, Xing Shen, and Tal Arbel. Prompt4trust: A reinforcement learning prompt augmentation framework for clinically-aligned confidence calibration in multimodal large language models. InInternational Conference on Computer Vision Workshop (ICCVW), pages 1320–1329, 2025
2025
-
[55]
Chain-of-thought prompting elicits reasoning in large language models.Advances in Neural Information Processing Systems (NeurIPS), 35:24824–24837, 2022
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models.Advances in Neural Information Processing Systems (NeurIPS), 35:24824–24837, 2022
2022
-
[56]
Uncertainty quantification in llm agents: Foundations, emerging challenges, and opportunities
Changdae Oh, Seongheon Park, To Eun Kim, Jiatong Li, Wendi Li, Samuel Yeh, Xuefeng Du, Hamed Hassani, Paul Bogdan, Dawn Song, and Sharon Li. Uncertainty quantification in llm agents: Foundations, emerging challenges, and opportunities. InAssociation for Computational Linguistics (ACL), 2026. 13 Appendix A More Related Work Uncertainty estimation.Uncertain...
2026
-
[57]
Yes”|x, t) and p(y=“No
of the matching between x and y. For example, if we have more plausible answers compatible to the givenxundert, the uncertainty will be higher. B.3 Derivation of Shannon’s entropy in a discrete case Now, we assume that the answer space y is discrete and explictly enumeratable. In this case, we can derive the following equation from the definition of discr...
-
[58]
end of sentence (EOS)
with a hidden dimension of 768 and 8 attention heads. The outputs are pooled by an attention pooling, and then fed into a linear head to estimate the target value; FZ1(x, t) and F∆(x, t) share the Transformer backbone, but use different attention pooling modules and the linear projection. Since Z1 and Z2 are the first and second momentum of probability ∈[...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.