AdaJEPA: An Adaptive Latent World Model
Pith reviewed 2026-07-01 05:59 UTC · model grok-4.3
The pith
AdaJEPA adapts a latent world model at test time inside model predictive control by treating observed next states as self-supervised signals for recalibration.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
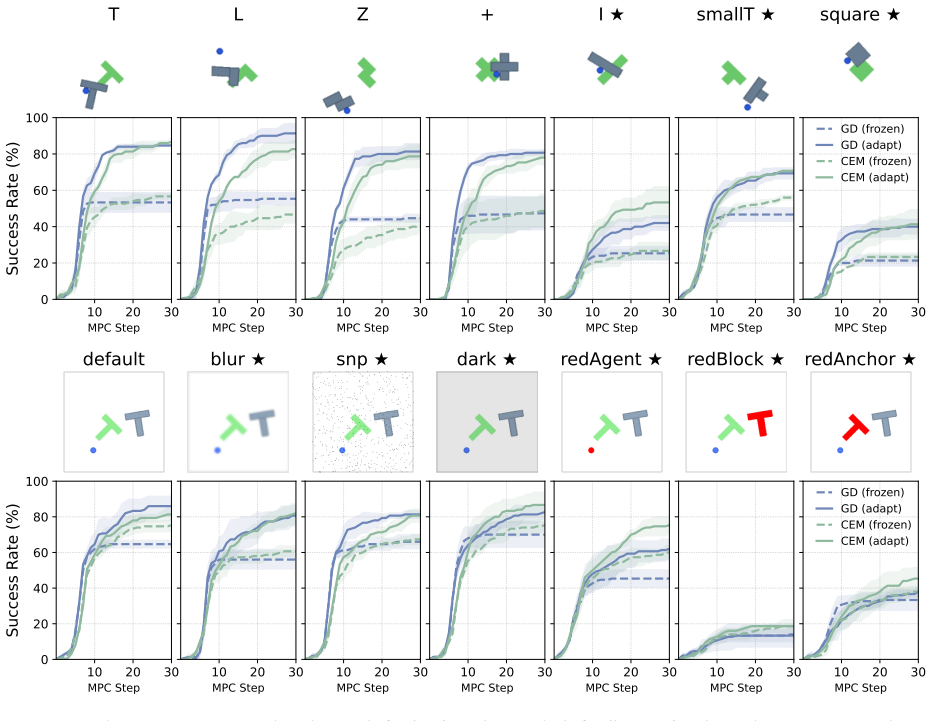
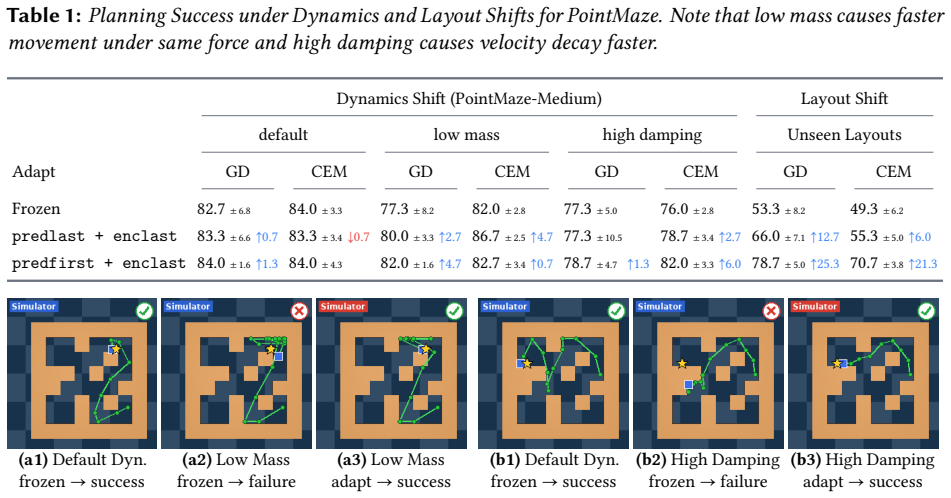
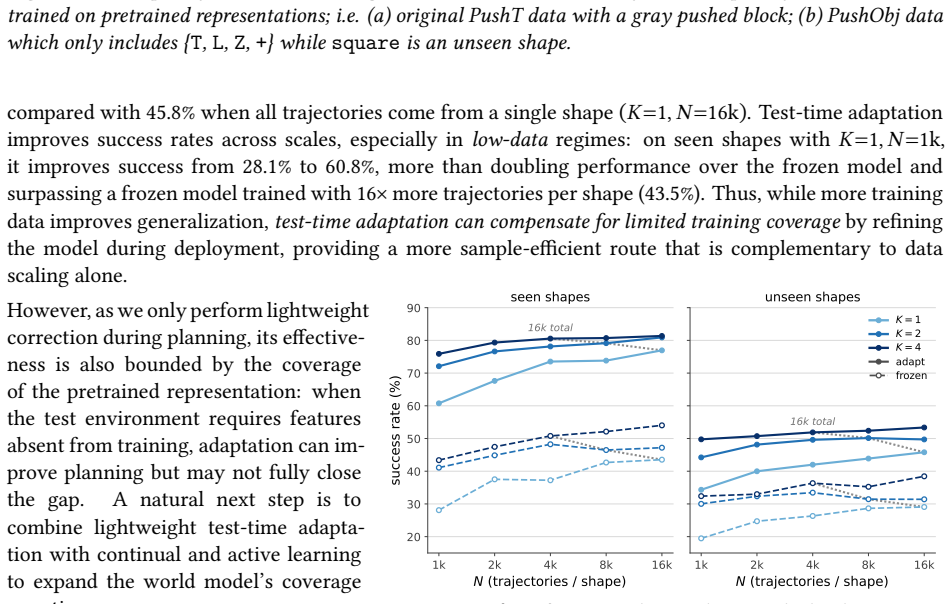
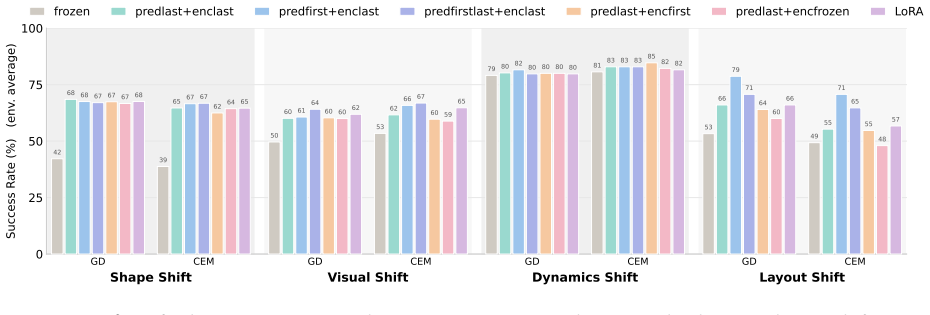
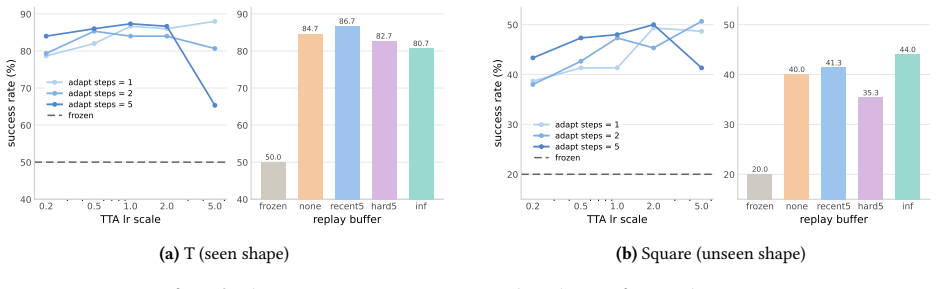
After training, AdaJEPA plans and executes the first action chunk, uses the observed next-state transition as a self-supervised adaptation signal, and replans with the updated model. This closed-loop update continuously recalibrates the world model without additional expert demonstrations. Across a range of goal-reaching tasks, AdaJEPA substantially improves planning success with as few as one gradient step per MPC replanning step.
What carries the argument
The closed-loop test-time adaptation step that recalibrates the latent world model from the observed next-state transition after each executed action chunk.
If this is right
- Planning success on goal-reaching tasks rises when the model is allowed to update from real observations inside the control loop.
- Effective recalibration occurs with only one gradient step per MPC replanning cycle.
- No extra expert demonstrations are required to maintain model accuracy at test time.
- The approach keeps the world model usable under test-time distribution shift without freezing parameters.
Where Pith is reading between the lines
- The same self-supervised update loop could be applied to other online control settings where a predictive model drifts over time.
- If the adaptation step proves stable across longer horizons, it might reduce the need for exhaustive offline data collection in robotics.
- Noise in the observed transition could limit reliability unless the method incorporates filtering or selective updates.
- Extending the single-step update to multi-step chunks might trade off speed for greater correction per cycle.
Load-bearing premise
The observed next-state transition after executing the first action chunk supplies a reliable self-supervised signal that permits useful model updates without causing instability.
What would settle it
Run the same goal-reaching tasks with distribution shift; if planning success rates remain unchanged or drop after the one-gradient-step updates, the adaptation benefit is absent.
Figures








read the original abstract
Latent world models enable planning from high-dimensional observations by predicting future states in a compact latent space. However, these models are typically kept frozen at test time: when their predictions become inaccurate, planning can fail, especially under test-time distribution shift. To address this, we propose AdaJEPA, an adaptive latent world model that performs test-time adaptation within the closed loop of model predictive control (MPC). After training, AdaJEPA plans and executes the first action chunk, uses the observed next-state transition as a self-supervised adaptation signal, and replans with the updated model. This closed-loop update continuously recalibrates the world model without additional expert demonstrations. Across a range of goal-reaching tasks, AdaJEPA substantially improves planning success with as few as one gradient step per MPC replanning step.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes AdaJEPA, a latent world model that performs test-time adaptation inside the MPC loop: after executing the first action chunk it treats the observed next-state transition as a self-supervised signal, performs a single gradient step on the world model, and replans with the updated parameters. The central claim is that this closed-loop recalibration yields substantially higher planning success on goal-reaching tasks under distribution shift, without extra expert demonstrations.
Significance. If the empirical gains are reproducible and statistically robust, the approach would be a lightweight, practical extension of existing latent-world-model + MPC pipelines that directly mitigates test-time model mismatch. The restriction to a single gradient step per replan is attractive for real-time settings.
major comments (1)
- Abstract: the assertion that AdaJEPA 'substantially improves planning success' is presented without any quantitative results, success rates, baselines, error bars, or experimental protocol. Because the paper's contribution is framed as an empirical improvement, this omission is load-bearing for the central claim and prevents assessment of effect size or statistical reliability.
Simulated Author's Rebuttal
We thank the referee for the feedback. We agree that the abstract's central empirical claim requires quantitative support to be properly assessed, and we will revise it to include key results.
read point-by-point responses
-
Referee: [—] Abstract: the assertion that AdaJEPA 'substantially improves planning success' is presented without any quantitative results, success rates, baselines, error bars, or experimental protocol. Because the paper's contribution is framed as an empirical improvement, this omission is load-bearing for the central claim and prevents assessment of effect size or statistical reliability.
Authors: We accept this point. The current abstract states the improvement only qualitatively. In the revision we will add concrete numbers drawn from the experimental section (e.g., success rates on the goal-reaching tasks, comparison to the frozen JEPA baseline, and reference to the number of gradient steps and statistical variability). This change will make the abstract self-contained for evaluating the claimed effect size. revision: yes
Circularity Check
No significant circularity detected
full rationale
The manuscript describes a procedural test-time adaptation loop for latent world models using observed transitions as self-supervised signals within MPC. No equations, derivations, fitted parameters renamed as predictions, or load-bearing self-citations are present in the provided text that would reduce any claim to its own inputs by construction. The approach is a direct extension of standard latent dynamics + planning pipelines, with empirical claims left open to external validation rather than internal self-definition.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2025 , journal =
DINO-WM: World Models on Pre-trained Visual Features enable Zero-shot Planning , author=. 2025 , journal =
2025
-
[2]
NeurIPS , year=
Learning from Reward-Free Offline Data: A Case for Planning with Latent Dynamics Models , author=. NeurIPS , year=
-
[3]
2022 , journal =
VICReg: Variance-Invariance-Covariance Regularization for Self-Supervised Learning , author=. 2022 , journal =
2022
-
[4]
ICML , year=
Temporal difference learning for model predictive control , author=. ICML , year=
-
[5]
ICLR , year=
Td-mpc2: Scalable, robust world models for continuous control , author=. ICLR , year=
-
[6]
2021 , journal=
D4RL: Datasets for Deep Data-Driven Reinforcement Learning , author=. 2021 , journal=
2021
-
[7]
, title =
Sutton, Richard S. , title =. 1991 , publisher =
1991
-
[8]
IFAC Proceedings Volumes , year=
Self-adapting IDCOM , author=. IFAC Proceedings Volumes , year=
-
[9]
2025 , journal=
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning , author=. 2025 , journal=
2025
-
[10]
CVPR , year =
Xinlei Chen and Kaiming He , title =. CVPR , year =
-
[11]
IJRR , year =
Cheng Chi and Zhenjia Xu and Siyuan Feng and Eric Cousineau and Yilun Du and Benjamin Burchfiel and Russ Tedrake and Shuran Song , title =. IJRR , year =
-
[12]
LeJEPA: Provable and Scalable Self-Supervised Learning Without the Heuristics
LeJEPA: Provable and Scalable Self-Supervised Learning Without the Heuristics , author=. arXiv preprint arXiv:2511.08544 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
World models can leverage human videos for dexterous manipulation.arXiv preprint arXiv:2512.13644,
World Models Can Leverage Human Videos for Dexterous Manipulation , author=. arXiv preprint arXiv:2512.13644 , year=
-
[14]
2022 , url=
A path towards autonomous machine intelligence , author=. 2022 , url=
2022
-
[15]
European Journal of Operational Research , year=
Optimization of computer simulation models with rare events , author=. European Journal of Operational Research , year=
-
[16]
ICML , year=
Temporal Straightening for Latent Planning , author=. ICML , year=
-
[17]
ICML , year =
Test-Time Training with Self-Supervision for Generalization under Distribution Shifts , author=. ICML , year =
-
[18]
2021 , journal =
Tent: Fully Test-time Adaptation by Entropy Minimization , author=. 2021 , journal =
2021
-
[19]
2022 , journal =
Memo: Test time robustness via adaptation and augmentation , author=. 2022 , journal =
2022
-
[20]
2022 , journal =
Efficient test-time model adaptation without forgetting , author=. 2022 , journal =
2022
-
[21]
CVPR , year =
Continual test-time domain adaptation , author=. CVPR , year =
-
[22]
arXiv preprint arXiv:2302.12400 (2023)
Towards Stable Test-Time Adaptation in Dynamic Wild World , author=. arXiv preprint arXiv:2302.12400 , year =
-
[23]
NeurIPS , year =
Test-time training with masked autoencoders , author=. NeurIPS , year =
-
[24]
ICLR , year=
C-tpt: Calibrated test-time prompt tuning for vision-language models via text feature dispersion , author=. ICLR , year=
-
[25]
JMLR , year=
Test-time training on video streams , author=. JMLR , year=
-
[26]
ICML , year =
The Surprising Effectiveness of Test-Time Training for Few-Shot Learning , author=. ICML , year =
-
[27]
ICLR , year =
AdaWM: Adaptive World Model based Planning for Autonomous Driving , author=. ICLR , year =
-
[28]
ICML , year =
AdaWorld: Learning Adaptable World Models with Latent Actions , author=. ICML , year =
-
[29]
arXiv preprint arXiv:2504.02252 , year =
Adapting World Models with Latent-State Dynamics Residuals , author=. arXiv preprint arXiv:2504.02252 , year =
-
[30]
arXiv preprint arXiv:2512.09929 , year=
Closing the Train-Test Gap in World Models for Gradient-Based Planning , author=. arXiv preprint arXiv:2512.09929 , year=
-
[31]
Learning from Trials and Errors: Reflective Test-Time Planning for Embodied LLMs
Learning from Trials and Errors: Reflective Test-Time Planning for Embodied LLMs , author=. arXiv preprint arXiv:2602.21198 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
NeurIPS , year=
Planning with an adaptive world model , author=. NeurIPS , year=
-
[33]
2026 , journal=
Self-Improving Loops for Visual Robotic Planning , author=. 2026 , journal=
2026
-
[34]
2016 , publisher=
Model Predictive Control: Classical, Robust and Stochastic , author=. 2016 , publisher=
2016
-
[35]
1989 , author =
Model predictive control: Theory and practice—A survey , journal =. 1989 , author =
1989
-
[36]
Trends in cognitive sciences , year=
Internal models in the cerebellum , author=. Trends in cognitive sciences , year=
-
[37]
Reza Shadmehr and F. A. Mussa-Ivaldi , year=. Adaptive representation of dynamics during learning of a motor task , journal=
-
[38]
Annual review of neuroscience , year=
Error correction, sensory prediction, and adaptation in motor control , author=. Annual review of neuroscience , year=
-
[39]
Current opinion in neurobiology , year=
Learning to predict the future: the cerebellum adapts feedforward movement control , author=. Current opinion in neurobiology , year=
-
[40]
Craik, Kenneth J. W. , title =. 1943 , publisher =
1943
-
[41]
Neuron , year=
Model-based influences on humans' choices and striatal prediction errors , author=. Neuron , year=
-
[42]
Neuron , year=
States versus Rewards: Dissociable neural prediction error signals underlying model-based and model-free reinforcement learning , author=. Neuron , year=
-
[43]
Journal of Neuroscience , year=
An approximately Bayesian delta-rule model explains the dynamics of belief updating in a changing environment , author=. Journal of Neuroscience , year=
-
[44]
LeWorldModel: Stable End-to-End Joint-Embedding Predictive Architecture from Pixels
Leworldmodel: Stable end-to-end joint-embedding predictive architecture from pixels , author=. arXiv preprint arXiv:2603.19312 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[45]
Hierarchical Planning with Latent World Models
Hierarchical planning with latent world models , author=. arXiv preprint arXiv:2604.03208 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[46]
Learning Invariant Visual Representations for Planning with Joint-Embedding Predictive World Models , author=. arXiv preprint arXiv:2602.18639 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.